
AiTextDetectionBypass
Bypass Ai detection using undetectable.ai
Stars: 57
ParaGenie is a script designed to automate the process of paraphrasing articles using the undetectable.ai platform. It allows users to convert lengthy content into unique paraphrased versions by splitting the input text into manageable chunks and processing each chunk individually. The script offers features such as automated paraphrasing, multi-file support for TXT, DOCX, and PDF formats, customizable chunk splitting methods, Gmail-based registration for seamless paraphrasing, purpose-specific writing support, readability level customization, anonymity features for user privacy, error handling and recovery, and output management for easy access and organization of paraphrased content.
README:
ParaGenie is a script that automates the process of paraphrasing articles using the undetectable.ai platform. It enables users to transform long-form content into unique paraphrased versions by splitting the input text into manageable chunks and processing each chunk individually. The script is designed with flexibility, automation, and user anonymity in mind, making it an efficient tool for paraphrasing lengthy documents.
You can Try the Other tool as well https://github.com/obaskly/AiDetectionBypass
This script automates text paraphrasing but is NOT responsible for the quality or accuracy of the output. Please review and verify results independently.
- Automated Paraphrasing: Automatically paraphrase long articles by breaking them into chunks.
- Multi-File Support: Handles text extraction and processing for TXT, DOCX, and PDF file formats. (NEW!)
- Customizable Chunk Splitting: Choose between the default word-based splitting method or a more advanced NLTK-powered sentence-preserving approach. (NEW!)
- Gmail-Based Registration: Automates Gmail registration and verification for seamless paraphrasing. (NEW!)
- Smart Email Management: Saves generated Gmail variations in a JSON file to avoid redundancy. (NEW!)
- API Extraction: The script now retrieves API keys stored in the Gmail variations JSON file. It iterates through the entries and extracts each API key, storing them in an apis.json file for easy access. (NEW!)
- AI Detection Percentage: The script now scans a given text and returns the percentage likelihood of the content being generated by AI. (NEW!) Put your API in line 280 in gui.py
- Purpose-Specific Writing: Supports a variety of writing purposes such as essays, articles, marketing material, and more.
- Readability Options: Tailor the readability level of the output, from high school to professional marketing standards.
- Tone selection: Support three different kinds of tones.
- Anonymity Features: Leverages Chrome's incognito mode and a random user agent to protect your identity.
- Error Handling and Recovery: Automatically retries chunks if any errors occur during the paraphrasing process.
- Output Management: Saves paraphrased content into a file for easy access and organization.
- Clone this repository to your local machine.
git clone https://github.com/obaskly/AiTextDetectionBypass.git
cd AiTextDetectionBypass- Install the required Python packages.
pip install -r requirements.txt- GMAIL Setup.
-
create new project
-
click on 'api and services'
-
type "Gmail API" and select it from the results.
-
Click the Enable button.
-
In the left-hand menu, go to APIs & Services > OAuth consent screen.
-
Choose External
-
Add the necessary scopes: https://www.googleapis.com/auth/gmail.readonly
-
Go to the Test users section.
-
Add the Gmail address you want to use for paraphrasing.
-
Click Save and Continue.
-
Go to APIs & Services > Credentials.
-
Click Create Credentials > OAuth 2.0 Client IDs.
-
Choose Desktop App as the application type.
-
Download the credentials.json file once it’s created and put it in the json_files folder.
- Run the script.
python gui.py- Python 3.x
- Google Chrome installed (chromedriver is used by Selenium)
- [x]
Handles text extraction and processing for TXT, DOCX, and PDF file formats. - [x]
Choose between the default word-based splitting method or a more advanced NLTK-powered sentence-preserving approach. - [x]
Automates Gmail registration and verification for seamless paraphrasing. - [x]
Saves generated Gmail variations in a JSON file to avoid redundancy. - [x]
Extract API keys from Gmail variations JSON and store inapis.json - [x]
Implement AI detection percentage feature - [ ] Automatically retrieve API keys from apis.json file and integrate them for AI scanning functionality.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AiTextDetectionBypass
Similar Open Source Tools
AiTextDetectionBypass
ParaGenie is a script designed to automate the process of paraphrasing articles using the undetectable.ai platform. It allows users to convert lengthy content into unique paraphrased versions by splitting the input text into manageable chunks and processing each chunk individually. The script offers features such as automated paraphrasing, multi-file support for TXT, DOCX, and PDF formats, customizable chunk splitting methods, Gmail-based registration for seamless paraphrasing, purpose-specific writing support, readability level customization, anonymity features for user privacy, error handling and recovery, and output management for easy access and organization of paraphrased content.
your-source-to-prompt.html
Your Source to Prompt is a single HTML file tool that allows users to easily select code files and combine them into a single text output. It runs entirely in the browser, ensuring local and secure operation without any external dependencies. The tool offers features like preset management, efficient file selection, context size awareness, hierarchical structure preview, minification, and user-friendly UI with dark mode. It aims to simplify the process of preparing code for Large Language Models (LLMs) by providing a well-structured prompt context.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
code2prompt
code2prompt is a command-line tool that converts your codebase into a single LLM prompt with a source tree, prompt templating, and token counting. It automates generating LLM prompts from codebases of any size, customizing prompt generation with Handlebars templates, respecting .gitignore, filtering and excluding files using glob patterns, displaying token count, including Git diff output, copying prompt to clipboard, saving prompt to an output file, excluding files and folders, adding line numbers to source code blocks, and more. It helps streamline the process of creating LLM prompts for code analysis, generation, and other tasks.
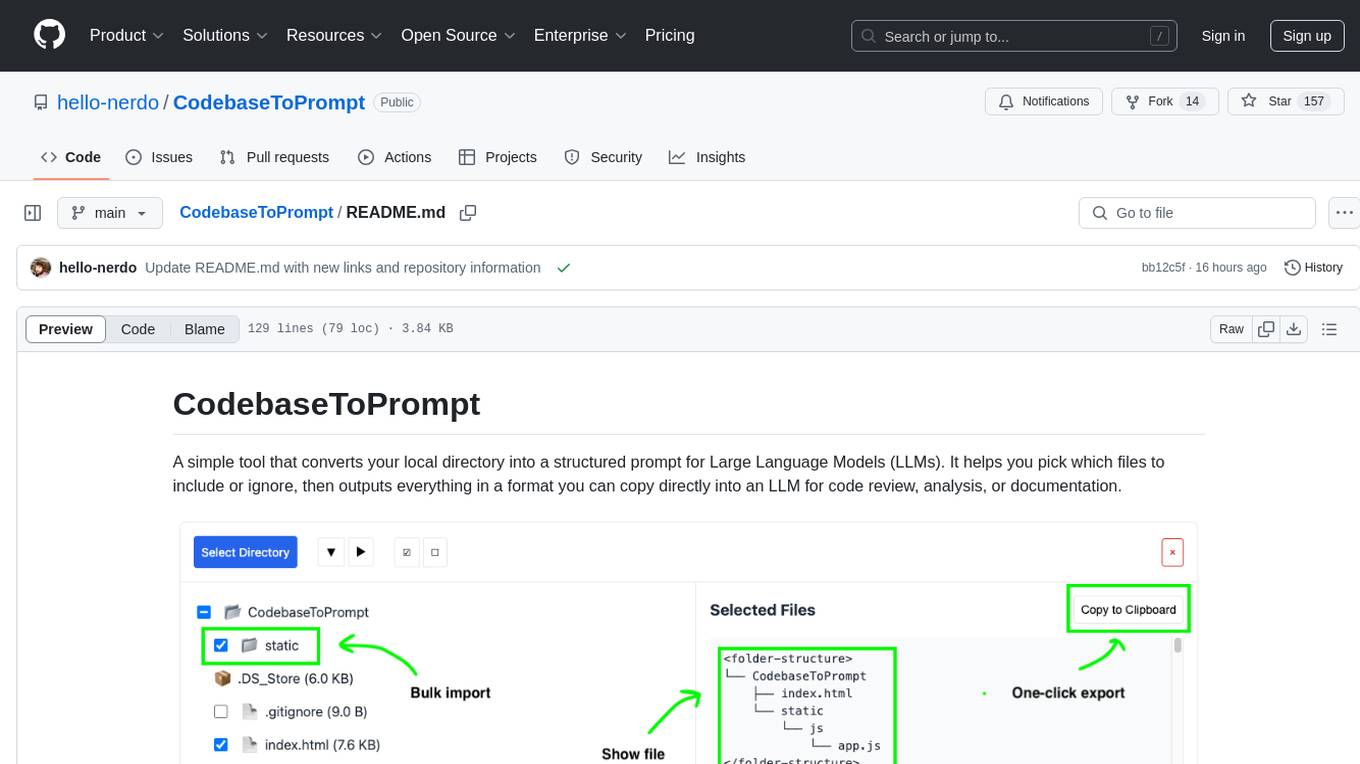
CodebaseToPrompt
CodebaseToPrompt is a tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in an interactive interface. The tool generates a formatted output that can be directly used with LLMs, estimates token count, and supports flexible text selection. Users can deploy the tool using Docker for self-contained usage and can contribute to the project by opening issues or submitting pull requests.
multimodal-chat
Yet Another Chatbot is a sophisticated multimodal chat interface powered by advanced AI models and equipped with a variety of tools. This chatbot can search and browse the web in real-time, query Wikipedia for information, perform news and map searches, execute Python code, compose long-form articles mixing text and images, generate, search, and compare images, analyze documents and images, search and download arXiv papers, save conversations as text and audio files, manage checklists, and track personal improvements. It offers tools for web interaction, Wikipedia search, Python scripting, content management, image handling, arXiv integration, conversation generation, file management, personal improvement, and checklist management.
Local-Multimodal-AI-Chat
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. It offers local model processing with Ollama for data privacy, integration with OpenAI API for broader AI capabilities, audio chatting with Whisper AI for accurate voice interpretation, and PDF chatting with Chroma DB for efficient PDF interactions. The application is designed for AI enthusiasts and developers seeking a comprehensive solution for multimodal AI technologies.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.

DevDocs
DevDocs is a platform designed to simplify the process of digesting technical documentation for software engineers and developers. It automates the extraction and conversion of web content into markdown format, making it easier for users to access and understand the information. By crawling through child pages of a given URL, DevDocs provides a streamlined approach to gathering relevant data and integrating it into various tools for software development. The tool aims to save time and effort by eliminating the need for manual research and content extraction, ultimately enhancing productivity and efficiency in the development process.
ComfyUI-Tara-LLM-Integration
Tara is a powerful node for ComfyUI that integrates Large Language Models (LLMs) to enhance and automate workflow processes. With Tara, you can create complex, intelligent workflows that refine and generate content, manage API keys, and seamlessly integrate various LLMs into your projects. It comprises nodes for handling OpenAI-compatible APIs, saving and loading API keys, composing multiple texts, and using predefined templates for OpenAI and Groq. Tara supports OpenAI and Grok models with plans to expand support to together.ai and Replicate. Users can install Tara via Git URL or ComfyUI Manager and utilize it for tasks like input guidance, saving and loading API keys, and generating text suitable for chaining in workflows.
burpference
Burpference is an open-source extension designed to capture in-scope HTTP requests and responses from Burp's proxy history and send them to a remote LLM API in JSON format. It automates response capture, integrates with APIs, optimizes resource usage, provides color-coded findings visualization, offers comprehensive logging, supports native Burp reporting, and allows flexible configuration. Users can customize system prompts, API keys, and remote hosts, and host models locally to prevent high inference costs. The tool is ideal for offensive web application engagements to surface findings and vulnerabilities.


cline-based-code-generator
HAI Code Generator is a cutting-edge tool designed to simplify and automate task execution while enhancing code generation workflows. Leveraging Specif AI, it streamlines processes like task execution, file identification, and code documentation through intelligent automation and AI-driven capabilities. Built on Cline's powerful foundation for AI-assisted development, HAI Code Generator boosts productivity and precision by automating task execution and integrating file management capabilities. It combines intelligent file indexing, context generation, and LLM-driven automation to minimize manual effort and ensure task accuracy. Perfect for developers and teams aiming to enhance their workflows.

PrivateDocBot
PrivateDocBot is a local LLM-powered chatbot designed for secure document interactions. It seamlessly merges Chainlit user-friendly interface with localized language models, tailored for sensitive data. The project streamlines data access by deciphering intricate user guides and extracting vital insights from complex PDF reports. Equipped with advanced technology, it offers an engaging conversational experience, redefining data interaction and empowering users with control.
prompty
Prompty is an asset class and format for LLM prompts designed to enhance observability, understandability, and portability for developers. The primary goal is to accelerate the developer inner loop. This repository contains the Prompty Language Specification and a documentation site. The Visual Studio Code extension offers a prompt playground to streamline the prompt engineering process.

poml
POML (Prompt Orchestration Markup Language) is a novel markup language designed to bring structure, maintainability, and versatility to advanced prompt engineering for Large Language Models (LLMs). It addresses common challenges in prompt development, such as lack of structure, complex data integration, format sensitivity, and inadequate tooling. POML provides a systematic way to organize prompt components, integrate diverse data types seamlessly, and manage presentation variations, empowering developers to create more sophisticated and reliable LLM applications.
For similar tasks
AiTextDetectionBypass
ParaGenie is a script designed to automate the process of paraphrasing articles using the undetectable.ai platform. It allows users to convert lengthy content into unique paraphrased versions by splitting the input text into manageable chunks and processing each chunk individually. The script offers features such as automated paraphrasing, multi-file support for TXT, DOCX, and PDF formats, customizable chunk splitting methods, Gmail-based registration for seamless paraphrasing, purpose-specific writing support, readability level customization, anonymity features for user privacy, error handling and recovery, and output management for easy access and organization of paraphrased content.
For similar jobs

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.