
Local-Multimodal-AI-Chat
None
Stars: 124
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. It offers local model processing with Ollama for data privacy, integration with OpenAI API for broader AI capabilities, audio chatting with Whisper AI for accurate voice interpretation, and PDF chatting with Chroma DB for efficient PDF interactions. The application is designed for AI enthusiasts and developers seeking a comprehensive solution for multimodal AI technologies.
README:
To get started with Local Multimodal AI Chat, clone the repository and follow these simple steps:
-
Set model save path: Line 21 in the docker-compose.yml file
-
Enter command in terminal:
docker compose upNote: If you don't have a GPU, you can remove the deploy section from the docker compose file.
-
Optional:
- Check the config.yaml file and change accordingly to your needs.
- Place your user_image.png and/or bot_image.png inside the chat_icons folder and remove the old ones.
-
Open the app: Open 0.0.0.0:8501 in the Browser
-
Pull Models: Go to https://ollama.com/library and choose the models you want to use. Enter
/pull MODEL_NAMEin the chat bar. You need one embedding model e.g. nomic-embed-text to embed pdf files (change embedding model in config if you choose another). You also need a model which undertands images e.g. llava -
Optional:
- Check the config.yaml file and change accordingly to your needs.
- Place your user_image.png and/or bot_image.png inside the chat_icons folder and remove the old ones.
Using ollama docker container results in very slow loading times for the models due to system calls being translated between two kernels. Installing Ollama locally works best here.
-
Install Ollama desktop
-
Change Docker Compose file: remove docker-compose.yml and rename docker-compose_without_ollama.yml to docker-compose.yml
-
Change Ollama Base URL in config.yaml: Use line 4 in the config.yaml file and remove line 3
-
Enter command in terminal:
docker compose up -
Open the app: Open 0.0.0.0:8501 in the Browser
-
Pull Models: Go to https://ollama.com/library and choose the models you want to use. Enter
/pull MODEL_NAMEin the chat bar. You need one embedding model e.g. nomic-embed-text to embed pdf files (change embedding model in config if you choose another). You also need a model which undertands images e.g. llava -
Optional:
- Check the config.yaml file and change accordingly to your needs.
- Place your user_image.png and/or bot_image.png inside the chat_icons folder and remove the old ones.
-
Install Ollama
-
Create a Virtual Environment: I am using Python 3.10.12
-
Install Requirements:
pip install --upgrade pippip install -r requirements.txtpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
-
Enter commands in terminal:
-
python3 database_operations.pyThis will initialize the sqlite database for the chat sessions. streamlit run app.py
-
-
Pull Models: Go to https://ollama.com/library and choose the models you want to use. Enter
/pull MODEL_NAMEin the chat bar. You need one embedding model e.g. nomic-embed-text to embed pdf files and one model which undertands images e.g. llava -
Optional:
- Check the config.yaml file and change accordingly to your needs.
- Place your user_image.png and/or bot_image.png inside the chat_icons folder and remove the old ones.
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. This application is ideal for those passionate about AI and software development, offering a comprehensive solution that employs Whisper AI for audio processing, LLaVA for image management, and Chroma DB for handling PDFs.
The application has been enhanced with the Ollama server and the OpenAI API, boosting its functionality and performance. You can find a detailed tutorial on the development of this repository on my youtube channel. While significant advancements have been made, the project is still open to further development and refinement.
I welcome contributions of all forms. Whether you’re introducing new features, optimizing the code, or correcting bugs, your participation is valued. This project thrives on community collaboration and aims to serve as a robust resource for those interested in the practical application of multimodal AI technologies.
-
Local Model Processing with Ollama: This app utilizes the Ollama server for running local instances of models, providing a powerful and customizable AI experience without the need for external cloud dependencies. This setup is ideal for maintaining data privacy and improving response times.
-
Integration with OpenAI API: For broader AI capabilities, this application also connects to the OpenAI API, enabling access to a wide range of cutting-edge AI models hosted externally. This feature ensures the app remains versatile and capable of handling a variety of tasks and queries efficiently.
-
Audio Chatting with Whisper AI: Leveraging Whisper AI's robust transcription capabilities, this app offers a sophisticated audio messaging experience. The integration of Whisper AI allows for accurate interpretation and response to voice inputs, enhancing the natural flow of conversations. Whisper models
-
PDF Chatting with Chroma DB: The app is tailored for both professional and academic uses, integrating Chroma DB as a vector database for efficient PDF interactions. This feature allows users to engage with their own PDF files locally on their device. This makes it a valuable tool for personal use, where one can extract insights, summaries, and engage in a unique form of dialogue with the text in their PDF files. Chroma website
- Big Update: Model Serving based on Ollama API now. Added Openai API.
Click to see more!
- Docker Compose Added
- Input Widget Update: Replaced st.text_input with st.chat_input to enhance interaction by leveraging a more chat-oriented UI, facilitating user engagement.
- Sidebar Adjustment: Relocated the audio recording button to the sidebar for a cleaner and more organized user interface, improving accessibility and user experience.
- License Added: Implemented the GNU General Public License v3.0 to ensure the project is freely available for use, modification, and distribution under the terms of this license. A comprehensive copyright and license notice has been included in the main file (app.py) to clearly communicate the terms under which the project is offered. This addition aims to protect both the contributors' and users' rights, fostering an open and collaborative development environment. For full license details, refer to the LICENSE file in the project repository.
- Caching for Chat Model: Introduced caching for the chat model to prevent it from being reloaded with every script execution. This optimization significantly improves performance by reducing load times
- Config File Expansion: Expanded the configuration file to accommodate new settings and features, providing greater flexibility and customization options for the chat application.
- SQLite Database for Chat History: Implemented a SQLite database to store the chat history.
- Displaying Images and Audio Files in Chat: Chat history now supports displaying images and audio files.
- Added Button to delete Chat History
- Updated langchain: Runs now with the current langchain version 0.1.6
-
Windows User DateTime Format Issue: Windows users seemed to have problems with the datetime format of the saved JSON chat histories. I changed the format in the
ultis.pyfile to"%Y_%m_%d_%H_%M_%S", which should solve the issue. Feel free to change it to your liking. - UI Adjustment for Chat Scrolling: Scrolling down in the chat annoyed me, so the text input box and the latest message are at the top now.
- Issue with Message Sending: After writing in the text field and pressing the send button, the LLM would not generate a response.
-
Cause of the Issue: This happened because the
clear_input_fieldcallback from the button changes the text field value to an empty string after saving the user question. However, changing the text field value triggers the callback from the text field widget, setting theuser_questionto an empty string again. As a result, the LLM is not called. -
Implemented Workaround: As a workaround, I added a check before changing the
user_questionvalue.
Add Model Caching.Add Images and Audio to Chat History Saving and Loading.Use a Database to Save the Chat History.- Integrate
Ollama, OpenAI,Gemini, or Other Model Providers. - Add Image Generator Model.
- Authentication Mechanism.
- Change Theme.
Separate Frontend and Backend Code for Better Deployment.
For any questions, please contact me at:
- Email: [email protected]
- Twitter: @leonsanderai
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Local-Multimodal-AI-Chat
Similar Open Source Tools
Local-Multimodal-AI-Chat
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. It offers local model processing with Ollama for data privacy, integration with OpenAI API for broader AI capabilities, audio chatting with Whisper AI for accurate voice interpretation, and PDF chatting with Chroma DB for efficient PDF interactions. The application is designed for AI enthusiasts and developers seeking a comprehensive solution for multimodal AI technologies.
Ollama-Colab-Integration
Ollama Colab Integration V4 is a tool designed to enhance the interaction and management of large language models. It allows users to quantize models within their notebook environment, access a variety of models through a user-friendly interface, and manage public endpoints efficiently. The tool also provides features like LiteLLM proxy control, model insights, and customizable model file templating. Users can troubleshoot model loading issues, CPU fallback strategies, and manage VRAM and RAM effectively. Additionally, the tool offers functionalities for downloading model files from Hugging Face, model conversion with high precision, model quantization using Q and Kquants, and securely uploading converted models to Hugging Face.
aiCoder
aiCoder is an AI-powered tool designed to streamline the coding process by automating repetitive tasks, providing intelligent code suggestions, and facilitating the integration of new features into existing codebases. It offers a chat interface for natural language interactions, methods and stubs lists for code modification, and settings customization for project-specific prompts. Users can leverage aiCoder to enhance code quality, focus on higher-level design, and save time during development.
burpference
Burpference is an open-source extension designed to capture in-scope HTTP requests and responses from Burp's proxy history and send them to a remote LLM API in JSON format. It automates response capture, integrates with APIs, optimizes resource usage, provides color-coded findings visualization, offers comprehensive logging, supports native Burp reporting, and allows flexible configuration. Users can customize system prompts, API keys, and remote hosts, and host models locally to prevent high inference costs. The tool is ideal for offensive web application engagements to surface findings and vulnerabilities.
MyDeviceAI
MyDeviceAI is a personal AI assistant app for iPhone that brings the power of artificial intelligence directly to the device. It focuses on privacy, performance, and personalization by running AI models locally and integrating with privacy-focused web services. The app offers seamless user experience, web search integration, advanced reasoning capabilities, personalization features, chat history access, and broad device support. It requires macOS, Xcode, CocoaPods, Node.js, and a React Native development environment for installation. The technical stack includes React Native framework, AI models like Qwen 3 and BGE Small, SearXNG integration, Redux for state management, AsyncStorage for storage, Lucide for UI components, and tools like ESLint and Prettier for code quality.

AntSK
AntSK is an AI knowledge base/agent built with .Net8+Blazor+SemanticKernel. It features a semantic kernel for accurate natural language processing, a memory kernel for continuous learning and knowledge storage, a knowledge base for importing and querying knowledge from various document formats, a text-to-image generator integrated with StableDiffusion, GPTs generation for creating personalized GPT models, API interfaces for integrating AntSK into other applications, an open API plugin system for extending functionality, a .Net plugin system for integrating business functions, real-time information retrieval from the internet, model management for adapting and managing different models from different vendors, support for domestic models and databases for operation in a trusted environment, and planned model fine-tuning based on llamafactory.

kairon
Kairon is an open-source conversational digital transformation platform that helps build LLM-based digital assistants at scale. It provides a no-coding web interface for adapting, training, testing, and maintaining AI assistants. Kairon focuses on pre-processing data for chatbots, including question augmentation, knowledge graph generation, and post-processing metrics. It offers end-to-end lifecycle management, low-code/no-code interface, secure script injection, telemetry monitoring, chat client designer, analytics module, and real-time struggle analytics. Kairon is suitable for teams and individuals looking for an easy interface to create, train, test, and deploy digital assistants.
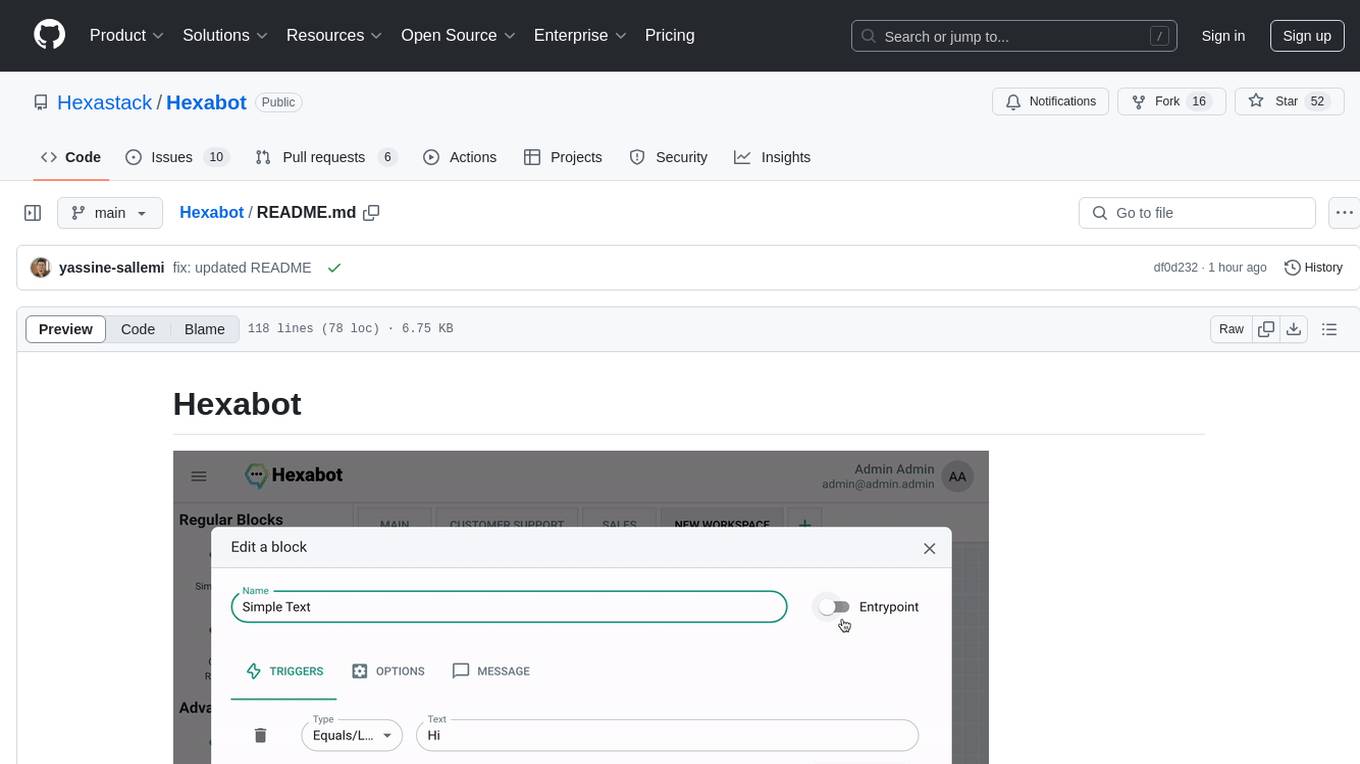
Hexabot
Hexabot Community Edition is an open-source chatbot solution designed for flexibility and customization, offering powerful text-to-action capabilities. It allows users to create and manage AI-powered, multi-channel, and multilingual chatbots with ease. The platform features an analytics dashboard, multi-channel support, visual editor, plugin system, NLP/NLU management, multi-lingual support, CMS integration, user roles & permissions, contextual data, subscribers & labels, and inbox & handover functionalities. The directory structure includes frontend, API, widget, NLU, and docker components. Prerequisites for running Hexabot include Docker and Node.js. The installation process involves cloning the repository, setting up the environment, and running the application. Users can access the UI admin panel and live chat widget for interaction. Various commands are available for managing the Docker services. Detailed documentation and contribution guidelines are provided for users interested in contributing to the project.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.
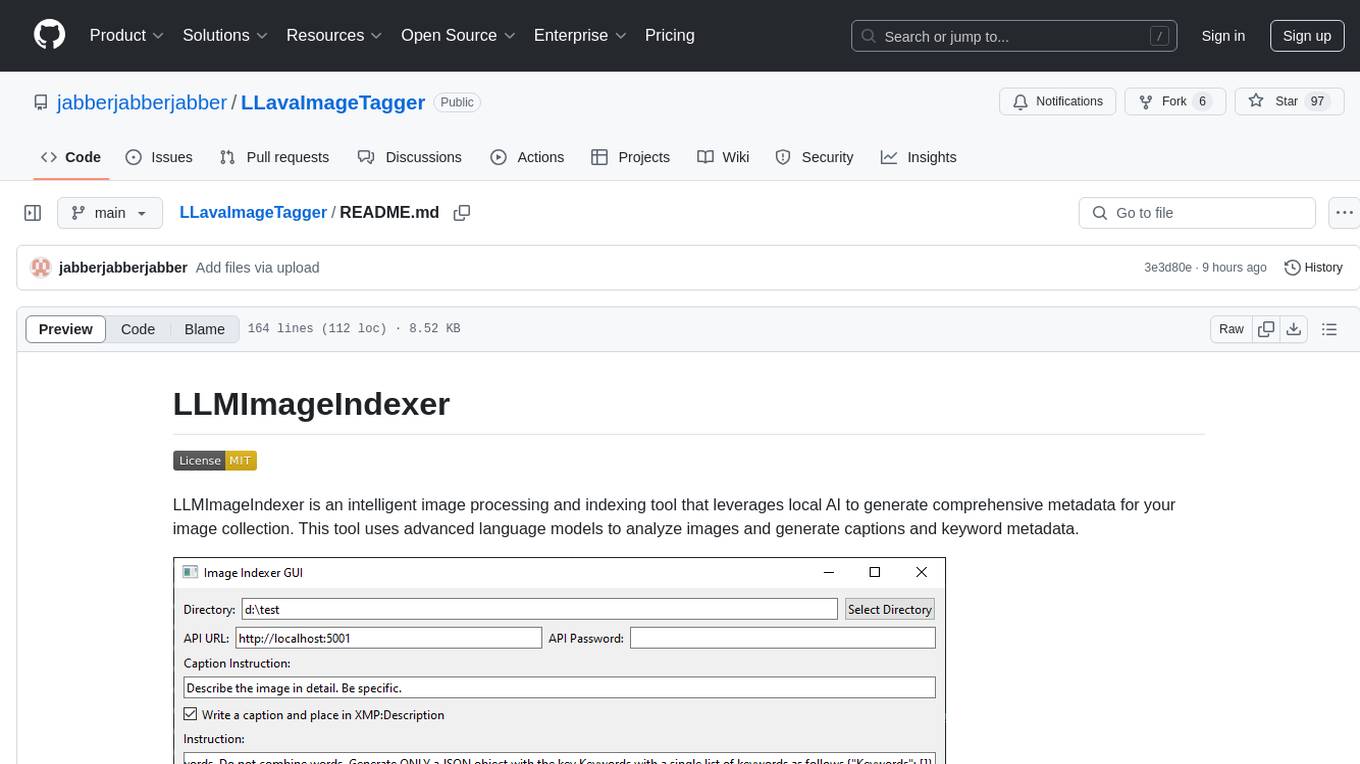
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
DistiLlama
DistiLlama is a Chrome extension that leverages a locally running Large Language Model (LLM) to perform various tasks, including text summarization, chat, and document analysis. It utilizes Ollama as the locally running LLM instance and LangChain for text summarization. DistiLlama provides a user-friendly interface for interacting with the LLM, allowing users to summarize web pages, chat with documents (including PDFs), and engage in text-based conversations. The extension is easy to install and use, requiring only the installation of Ollama and a few simple steps to set up the environment. DistiLlama offers a range of customization options, including the choice of LLM model and the ability to configure the summarization chain. It also supports multimodal capabilities, allowing users to interact with the LLM through text, voice, and images. DistiLlama is a valuable tool for researchers, students, and professionals who seek to leverage the power of LLMs for various tasks without compromising data privacy.
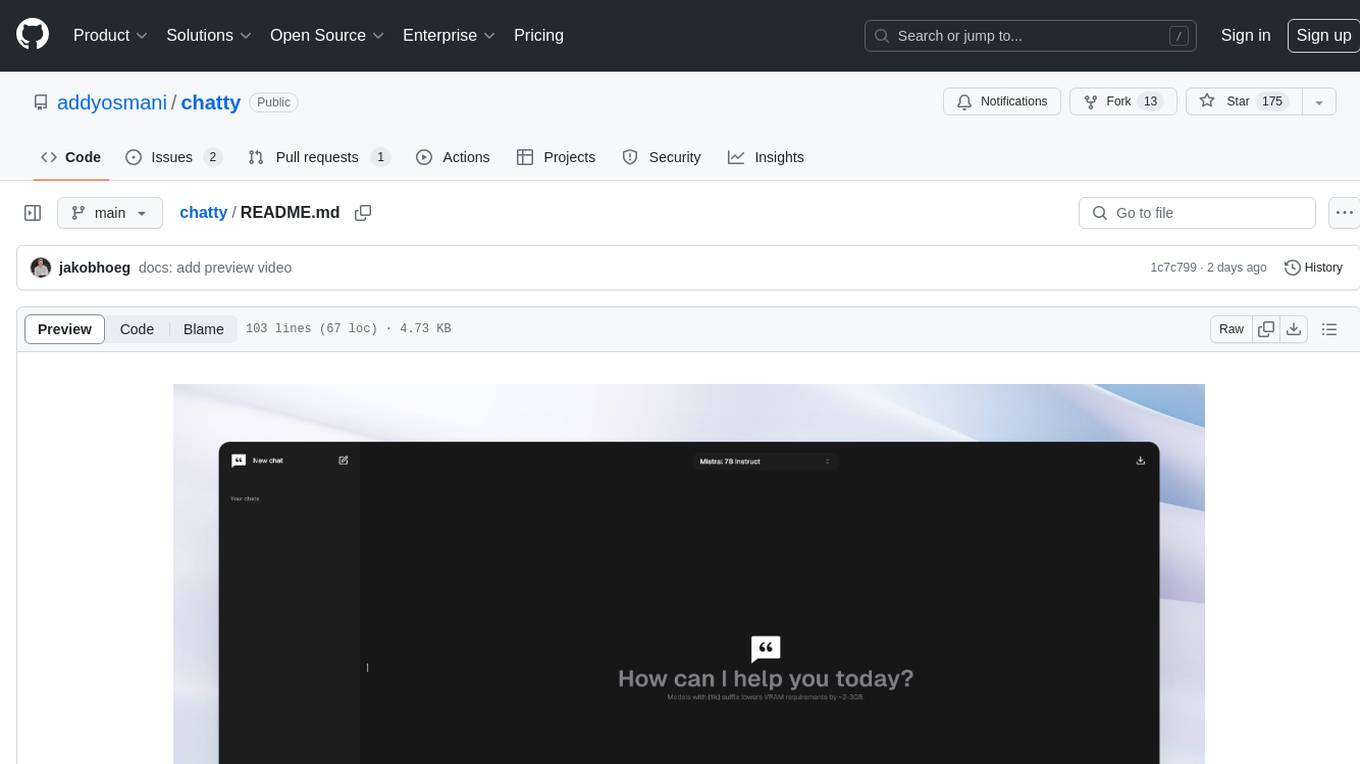
chatty
Chatty is a private AI tool that runs large language models natively and privately in the browser, ensuring in-browser privacy and offline usability. It supports chat history management, open-source models like Gemma and Llama2, responsive design, intuitive UI, markdown & code highlight, chat with files locally, custom memory support, export chat messages, voice input support, response regeneration, and light & dark mode. It aims to bring popular AI interfaces like ChatGPT and Gemini into an in-browser experience.
hf-llm.rs
HF-LLM.rs is a CLI tool for accessing Large Language Models (LLMs) like Llama 3.1, Mistral, Gemma 2, Cohere and more hosted on Hugging Face. It allows interaction with various models, providing input and receiving responses in a terminal environment. Users can select models, input prompts, receive streaming output, and engage in chat mode. The tool supports a variety of models available on Hugging Face infrastructure, with the list continuously updated. Some models may require a Pro subscription for access.
ComfyUI-Tara-LLM-Integration
Tara is a powerful node for ComfyUI that integrates Large Language Models (LLMs) to enhance and automate workflow processes. With Tara, you can create complex, intelligent workflows that refine and generate content, manage API keys, and seamlessly integrate various LLMs into your projects. It comprises nodes for handling OpenAI-compatible APIs, saving and loading API keys, composing multiple texts, and using predefined templates for OpenAI and Groq. Tara supports OpenAI and Grok models with plans to expand support to together.ai and Replicate. Users can install Tara via Git URL or ComfyUI Manager and utilize it for tasks like input guidance, saving and loading API keys, and generating text suitable for chaining in workflows.
stride-gpt
STRIDE GPT is an AI-powered threat modelling tool that leverages Large Language Models (LLMs) to generate threat models and attack trees for a given application based on the STRIDE methodology. Users provide application details, such as the application type, authentication methods, and whether the application is internet-facing or processes sensitive data. The model then generates its output based on the provided information. It features a simple and user-friendly interface, supports multi-modal threat modelling, generates attack trees, suggests possible mitigations for identified threats, and does not store application details. STRIDE GPT can be accessed via OpenAI API, Azure OpenAI Service, Google AI API, or Mistral API. It is available as a Docker container image for easy deployment.
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.
For similar tasks
Local-Multimodal-AI-Chat
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. It offers local model processing with Ollama for data privacy, integration with OpenAI API for broader AI capabilities, audio chatting with Whisper AI for accurate voice interpretation, and PDF chatting with Chroma DB for efficient PDF interactions. The application is designed for AI enthusiasts and developers seeking a comprehensive solution for multimodal AI technologies.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.