
ai-toolkit
The ultimate training toolkit for finetuning diffusion models
Stars: 6384
The AI Toolkit by Ostris is a collection of tools for machine learning, specifically designed for image generation, LoRA (latent representations of attributes) extraction and manipulation, and model training. It provides a user-friendly interface and extensive documentation to make it accessible to both developers and non-developers. The toolkit is actively under development, with new features and improvements being added regularly. Some of the key features of the AI Toolkit include: - Batch Image Generation: Allows users to generate a batch of images based on prompts or text files, using a configuration file to specify the desired settings. - LoRA (lierla), LoCON (LyCORIS) Extractor: Facilitates the extraction of LoRA and LoCON representations from pre-trained models, enabling users to modify and manipulate these representations for various purposes. - LoRA Rescale: Provides a tool to rescale LoRA weights, allowing users to adjust the influence of specific attributes in the generated images. - LoRA Slider Trainer: Enables the training of LoRA sliders, which can be used to control and adjust specific attributes in the generated images, offering a powerful tool for fine-tuning and customization. - Extensions: Supports the creation and sharing of custom extensions, allowing users to extend the functionality of the toolkit with their own tools and scripts. - VAE (Variational Auto Encoder) Trainer: Facilitates the training of VAEs for image generation, providing users with a tool to explore and improve the quality of generated images. The AI Toolkit is a valuable resource for anyone interested in exploring and utilizing machine learning for image generation and manipulation. Its user-friendly interface, extensive documentation, and active development make it an accessible and powerful tool for both beginners and experienced users.
README:
AI Toolkit is an all in one training suite for diffusion models. I try to support all the latest models on consumer grade hardware. Image and video models. It can be run as a GUI or CLI. It is designed to be easy to use but still have every feature imaginable.
If you enjoy my projects or use them commercially, please consider sponsoring me. Every bit helps! 💖
Sponsor on GitHub | Support on Patreon | Donate on PayPal
All of these people / organizations are the ones who selflessly make this project possible. Thank you!!
Last updated: 2025-08-23 14:55 UTC





































































Requirements:
- python >3.10
- Nvidia GPU with enough ram to do what you need
- python venv
- git
Linux:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
python3 -m venv venv
source venv/bin/activate
# install torch first
pip3 install --no-cache-dir torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu126
pip3 install -r requirements.txtWindows:
If you are having issues with Windows. I recommend using the easy install script at https://github.com/Tavris1/AI-Toolkit-Easy-Install
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
python -m venv venv
.\venv\Scripts\activate
pip install --no-cache-dir torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu126
pip install -r requirements.txt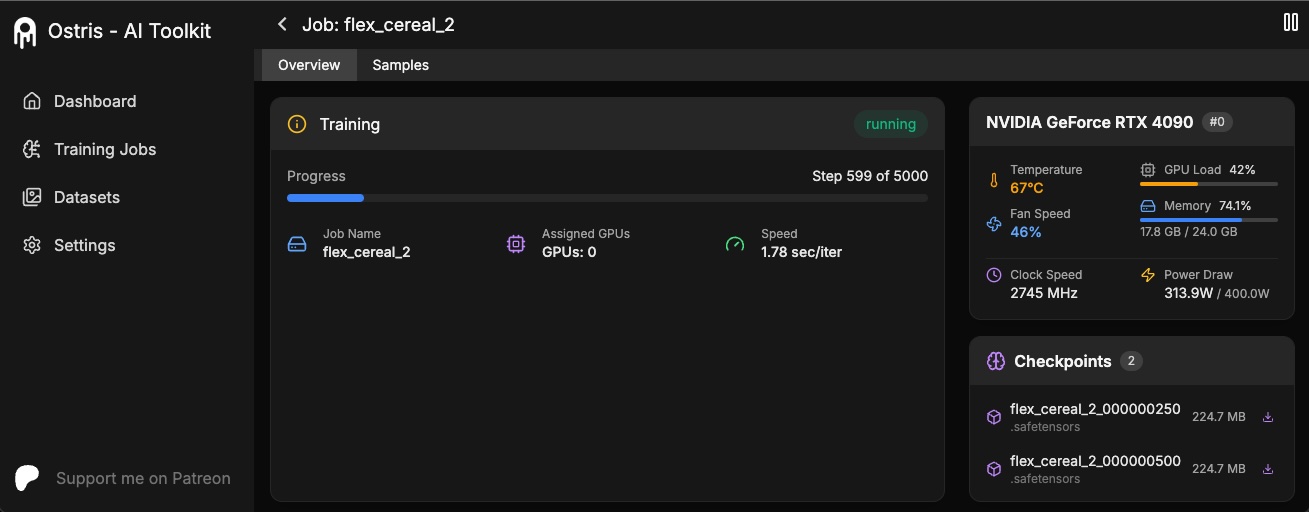
The AI Toolkit UI is a web interface for the AI Toolkit. It allows you to easily start, stop, and monitor jobs. It also allows you to easily train models with a few clicks. It also allows you to set a token for the UI to prevent unauthorized access so it is mostly safe to run on an exposed server.
Requirements:
- Node.js > 18
The UI does not need to be kept running for the jobs to run. It is only needed to start/stop/monitor jobs. The commands below will install / update the UI and it's dependencies and start the UI.
cd ui
npm run build_and_startYou can now access the UI at http://localhost:8675 or http://<your-ip>:8675 if you are running it on a server.
If you are hosting the UI on a cloud provider or any network that is not secure, I highly recommend securing it with an auth token.
You can do this by setting the environment variable AI_TOOLKIT_AUTH to super secure password. This token will be required to access
the UI. You can set this when starting the UI like so:
# Linux
AI_TOOLKIT_AUTH=super_secure_password npm run build_and_start
# Windows
set AI_TOOLKIT_AUTH=super_secure_password && npm run build_and_start
# Windows Powershell
$env:AI_TOOLKIT_AUTH="super_secure_password"; npm run build_and_startTo get started quickly, check out @araminta_k tutorial on Finetuning Flux Dev on a 3090 with 24GB VRAM.
You currently need a GPU with at least 24GB of VRAM to train FLUX.1. If you are using it as your GPU to control
your monitors, you probably need to set the flag low_vram: true in the config file under model:. This will quantize
the model on CPU and should allow it to train with monitors attached. Users have gotten it to work on Windows with WSL,
but there are some reports of a bug when running on windows natively.
I have only tested on linux for now. This is still extremely experimental
and a lot of quantizing and tricks had to happen to get it to fit on 24GB at all.
FLUX.1-dev has a non-commercial license. Which means anything you train will inherit the non-commercial license. It is also a gated model, so you need to accept the license on HF before using it. Otherwise, this will fail. Here are the required steps to setup a license.
- Sign into HF and accept the model access here black-forest-labs/FLUX.1-dev
- Make a file named
.envin the root on this folder -
Get a READ key from huggingface and add it to the
.envfile like soHF_TOKEN=your_key_here
FLUX.1-schnell is Apache 2.0. Anything trained on it can be licensed however you want and it does not require a HF_TOKEN to train. However, it does require a special adapter to train with it, ostris/FLUX.1-schnell-training-adapter. It is also highly experimental. For best overall quality, training on FLUX.1-dev is recommended.
To use it, You just need to add the assistant to the model section of your config file like so:
model:
name_or_path: "black-forest-labs/FLUX.1-schnell"
assistant_lora_path: "ostris/FLUX.1-schnell-training-adapter"
is_flux: true
quantize: trueYou also need to adjust your sample steps since schnell does not require as many
sample:
guidance_scale: 1 # schnell does not do guidance
sample_steps: 4 # 1 - 4 works well- Copy the example config file located at
config/examples/train_lora_flux_24gb.yaml(config/examples/train_lora_flux_schnell_24gb.yamlfor schnell) to theconfigfolder and rename it towhatever_you_want.yml - Edit the file following the comments in the file
- Run the file like so
python run.py config/whatever_you_want.yml
A folder with the name and the training folder from the config file will be created when you start. It will have all checkpoints and images in it. You can stop the training at any time using ctrl+c and when you resume, it will pick back up from the last checkpoint.
IMPORTANT. If you press crtl+c while it is saving, it will likely corrupt that checkpoint. So wait until it is done saving
Please do not open a bug report unless it is a bug in the code. You are welcome to Join my Discord and ask for help there. However, please refrain from PMing me directly with general question or support. Ask in the discord and I will answer when I can.
To get started training locally with a with a custom UI, once you followed the steps above and ai-toolkit is installed:
cd ai-toolkit #in case you are not yet in the ai-toolkit folder
huggingface-cli login #provide a `write` token to publish your LoRA at the end
python flux_train_ui.pyYou will instantiate a UI that will let you upload your images, caption them, train and publish your LoRA

If you would like to use Runpod, but have not signed up yet, please consider using my Runpod affiliate link to help support this project.
I maintain an official Runpod Pod template here which can be accessed here.
I have also created a short video showing how to get started using AI Toolkit with Runpod here.
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
- Run
pip install modalto install the modal Python package. - Run
modal setupto authenticate (if this doesn’t work, trypython -m modal setup).
- Get a READ token from here and request access to Flux.1-dev model from here.
- Run
huggingface-cli loginand paste your token.
- Drag and drop your dataset folder containing the .jpg, .jpeg, or .png images and .txt files in
ai-toolkit.
- Copy an example config file located at
config/examples/modalto theconfigfolder and rename it towhatever_you_want.yml. - Edit the config following the comments in the file, be careful and follow the example
/root/ai-toolkitpaths.
-
Set your entire local
ai-toolkitpath atcode_mount = modal.Mount.from_local_dirlike:code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit") -
Choose a
GPUandTimeoutin@app.function(default is A100 40GB and 2 hour timeout).
- Run the config file in your terminal:
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.yml. - You can monitor your training in your local terminal, or on modal.com.
- Models, samples and optimizer will be stored in
Storage > flux-lora-models.
- Check contents of the volume by running
modal volume ls flux-lora-models. - Download the content by running
modal volume get flux-lora-models your-model-name. - Example:
modal volume get flux-lora-models my_first_flux_lora_v1.
Datasets generally need to be a folder containing images and associated text files. Currently, the only supported
formats are jpg, jpeg, and png. Webp currently has issues. The text files should be named the same as the images
but with a .txt extension. For example image2.jpg and image2.txt. The text file should contain only the caption.
You can add the word [trigger] in the caption file and if you have trigger_word in your config, it will be automatically
replaced.
Images are never upscaled but they are downscaled and placed in buckets for batching. You do not need to crop/resize your images. The loader will automatically resize them and can handle varying aspect ratios.
To train specific layers with LoRA, you can use the only_if_contains network kwargs. For instance, if you want to train only the 2 layers
used by The Last Ben, mentioned in this post, you can adjust your
network kwargs like so:
network:
type: "lora"
linear: 128
linear_alpha: 128
network_kwargs:
only_if_contains:
- "transformer.single_transformer_blocks.7.proj_out"
- "transformer.single_transformer_blocks.20.proj_out"The naming conventions of the layers are in diffusers format, so checking the state dict of a model will reveal
the suffix of the name of the layers you want to train. You can also use this method to only train specific groups of weights.
For instance to only train the single_transformer for FLUX.1, you can use the following:
network:
type: "lora"
linear: 128
linear_alpha: 128
network_kwargs:
only_if_contains:
- "transformer.single_transformer_blocks."You can also exclude layers by their names by using ignore_if_contains network kwarg. So to exclude all the single transformer blocks,
network:
type: "lora"
linear: 128
linear_alpha: 128
network_kwargs:
ignore_if_contains:
- "transformer.single_transformer_blocks."ignore_if_contains takes priority over only_if_contains. So if a weight is covered by both,
if will be ignored.
To learn more about LoKr, read more about it at KohakuBlueleaf/LyCORIS. To train a LoKr model, you can adjust the network type in the config file like so:
network:
type: "lokr"
lokr_full_rank: true
lokr_factor: 8Everything else should work the same including layer targeting.
Only larger updates are listed here. There are usually smaller daily updated that are omitted.
- Make it easy to add control images to the samples in the ui
- Added better video config settings to the UI for video models.
- Added Wan I2V training to the UI
- Fixed issue where Kontext forced sizes on sampling
- Added support for FLUX.1 Kontext training
- added support for instruction dataset training
- Added support for OmniGen2 training
- Performance optimizations for batch preparation
- Added some docs via a popup for items in the simple ui explaining what settings do. Still a WIP
- Hide control images in the UI when viewing datasets
- WIP on mean flow loss
- Fixed issue that resulted in blank captions in the dataloader
- Decided to keep track up updates in the readme
- Added support for SDXL in the UI
- Added support for SD 1.5 in the UI
- Fixed UI Wan 2.1 14b name bug
- Added support for for conv training in the UI for models that support it
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-toolkit
Similar Open Source Tools
ai-toolkit
The AI Toolkit by Ostris is a collection of tools for machine learning, specifically designed for image generation, LoRA (latent representations of attributes) extraction and manipulation, and model training. It provides a user-friendly interface and extensive documentation to make it accessible to both developers and non-developers. The toolkit is actively under development, with new features and improvements being added regularly. Some of the key features of the AI Toolkit include: - Batch Image Generation: Allows users to generate a batch of images based on prompts or text files, using a configuration file to specify the desired settings. - LoRA (lierla), LoCON (LyCORIS) Extractor: Facilitates the extraction of LoRA and LoCON representations from pre-trained models, enabling users to modify and manipulate these representations for various purposes. - LoRA Rescale: Provides a tool to rescale LoRA weights, allowing users to adjust the influence of specific attributes in the generated images. - LoRA Slider Trainer: Enables the training of LoRA sliders, which can be used to control and adjust specific attributes in the generated images, offering a powerful tool for fine-tuning and customization. - Extensions: Supports the creation and sharing of custom extensions, allowing users to extend the functionality of the toolkit with their own tools and scripts. - VAE (Variational Auto Encoder) Trainer: Facilitates the training of VAEs for image generation, providing users with a tool to explore and improve the quality of generated images. The AI Toolkit is a valuable resource for anyone interested in exploring and utilizing machine learning for image generation and manipulation. Its user-friendly interface, extensive documentation, and active development make it an accessible and powerful tool for both beginners and experienced users.
quickvid
QuickVid is an open-source video summarization tool that uses AI to generate summaries of YouTube videos. It is built with Whisper, GPT, LangChain, and Supabase. QuickVid can be used to save time and get the essence of any YouTube video with intelligent summarization.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.
OutofFocus
Out of Focus v1.0 is a flexible tool in Gradio for image manipulation through prompt manipulation by reconstruction via diffusion inversion process. Users can modify images using this tool, which is the first version of the Image modification tool by Out of AI.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.
yolo-flutter-app
Ultralytics YOLO for Flutter is a Flutter plugin that allows you to integrate Ultralytics YOLO computer vision models into your mobile apps. It supports both Android and iOS platforms, providing APIs for object detection and image classification. The plugin leverages Flutter Platform Channels for seamless communication between the client and host, handling all processing natively. Before using the plugin, you need to export the required models in `.tflite` and `.mlmodel` formats. The plugin provides support for tasks like detection and classification, with specific instructions for Android and iOS platforms. It also includes features like camera preview and methods for object detection and image classification on images. Ultralytics YOLO thrives on community collaboration and offers different licensing paths for open-source and commercial use cases.

PySpur
PySpur is a graph-based editor designed for LLM workflows, offering modular building blocks for easy workflow creation and debugging at node level. It allows users to evaluate final performance and promises self-improvement features in the future. PySpur is easy-to-hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies, making it a versatile tool for workflow management in the field of AI and machine learning.
modelscope-agent
ModelScope-Agent is a customizable and scalable Agent framework. A single agent has abilities such as role-playing, LLM calling, tool usage, planning, and memory. It mainly has the following characteristics: - **Simple Agent Implementation Process**: Simply specify the role instruction, LLM name, and tool name list to implement an Agent application. The framework automatically arranges workflows for tool usage, planning, and memory. - **Rich models and tools**: The framework is equipped with rich LLM interfaces, such as Dashscope and Modelscope model interfaces, OpenAI model interfaces, etc. Built in rich tools, such as **code interpreter**, **weather query**, **text to image**, **web browsing**, etc., make it easy to customize exclusive agents. - **Unified interface and high scalability**: The framework has clear tools and LLM registration mechanism, making it convenient for users to expand more diverse Agent applications. - **Low coupling**: Developers can easily use built-in tools, LLM, memory, and other components without the need to bind higher-level agents.
air
Air is a new web framework for Python web development, built with FastAPI, Starlette, and Pydantic. It provides intuitive shortcuts and optimizations to expedite coding HTML with FastAPI, easy HTML content generation using Python classes, and seamless integration with Jinja templates. Air also offers utilities for using HTMX, HTML form validation powered by pydantic, and well-documented features. It aims to combine sophisticated HTML pages and a REST API into one app, making it easy to use FastAPI and Air together.
lingoose
LinGoose is a modular Go framework designed for building AI/LLM applications. It offers the flexibility to import only the necessary modules, abstracts features for customization, and provides a comprehensive solution for developing AI/LLM applications from scratch. The framework simplifies the process of creating intelligent applications by allowing users to choose preferred implementations or create their own. LinGoose empowers developers to leverage its capabilities to streamline the development of cutting-edge AI and LLM projects.
Sunshine-AIO
Sunshine-AIO is an all-in-one step-by-step guide to set up Sunshine with all necessary tools for Windows users. It provides a dedicated display for game streaming, virtual monitor switching, automatic resolution adjustment, resource-saving features, game launcher integration, and stream management. The project aims to evolve into an AIO tool as it progresses, welcoming contributions from users.
gemini-next-chat
Gemini Next Chat is an open-source, extensible high-performance Gemini chatbot framework that supports one-click free deployment of private Gemini web applications. It provides a simple interface with image recognition and voice conversation, supports multi-modal models, talk mode, visual recognition, assistant market, support plugins, conversation list, full Markdown support, privacy and security, PWA support, well-designed UI, fast loading speed, static deployment, and multi-language support.
vertex-ai-mlops
Vertex AI is a platform for end-to-end model development. It consist of core components that make the processes of MLOps possible for design patterns of all types.

screenpipe
24/7 Screen & Audio Capture Library to build personalized AI powered by what you've seen, said, or heard. Works with Ollama. Alternative to Rewind.ai. Open. Secure. You own your data. Rust. We are shipping daily, make suggestions, post bugs, give feedback. Building a reliable stream of audio and screenshot data, simplifying life for developers by solving non-trivial problems. Multiple installation options available. Experimental tool with various integrations and features for screen and audio capture, OCR, STT, and more. Open source project focused on enabling tooling & infrastructure for a wide range of applications.
incubator-kie-optaplanner
A fast, easy-to-use, open source AI constraint solver for software developers. OptaPlanner is a powerful tool that helps developers solve complex optimization problems by providing a constraint satisfaction solver. It allows users to model and solve planning and scheduling problems efficiently, improving decision-making processes and resource allocation. With OptaPlanner, developers can easily integrate optimization capabilities into their applications, leading to better performance and cost-effectiveness.
gpt-translate
Markdown Translation BOT is a GitHub action that translates markdown files into multiple languages using various AI models. It supports markdown, markdown-jsx, and json files only. The action can be executed by individuals with write permissions to the repository, preventing API abuse by non-trusted parties. Users can set up the action by providing their API key and configuring the workflow settings. The tool allows users to create comments with specific commands to trigger translations and automatically generate pull requests or add translated files to existing pull requests. It supports multiple file translations and can interpret any language supported by GPT-4 or GPT-3.5.
For similar tasks

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.

ap-plugin
AP-PLUGIN is an AI drawing plugin for the Yunzai series robot framework, allowing you to have a convenient AI drawing experience in the input box. It uses the open source Stable Diffusion web UI as the backend, deploys it for free, and generates a variety of images with richer functions.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
midjourney-proxy
Midjourney-proxy is a proxy for the Discord channel of MidJourney, enabling API-based calls for AI drawing. It supports Imagine instructions, adding image base64 as a placeholder, Blend and Describe commands, real-time progress tracking, Chinese prompt translation, prompt sensitive word pre-detection, user-token connection to WSS, multi-account configuration, and more. For more advanced features, consider using midjourney-proxy-plus, which includes Shorten, focus shifting, image zooming, local redrawing, nearly all associated button actions, Remix mode, seed value retrieval, account pool persistence, dynamic maintenance, /info and /settings retrieval, account settings configuration, Niji bot robot, InsightFace face replacement robot, and an embedded management dashboard.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
cog-comfyui
Cog-comfyui allows users to run ComfyUI workflows on Replicate. ComfyUI is a visual programming tool for creating and sharing generative art workflows. With cog-comfyui, users can access a variety of pre-trained models and custom nodes to create their own unique artworks. The tool is easy to use and does not require any coding experience. Users simply need to upload their API JSON file and any necessary input files, and then click the "Run" button. Cog-comfyui will then generate the output image or video file.
For similar jobs
StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.
ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
ai-toolkit
The AI Toolkit by Ostris is a collection of tools for machine learning, specifically designed for image generation, LoRA (latent representations of attributes) extraction and manipulation, and model training. It provides a user-friendly interface and extensive documentation to make it accessible to both developers and non-developers. The toolkit is actively under development, with new features and improvements being added regularly. Some of the key features of the AI Toolkit include: - Batch Image Generation: Allows users to generate a batch of images based on prompts or text files, using a configuration file to specify the desired settings. - LoRA (lierla), LoCON (LyCORIS) Extractor: Facilitates the extraction of LoRA and LoCON representations from pre-trained models, enabling users to modify and manipulate these representations for various purposes. - LoRA Rescale: Provides a tool to rescale LoRA weights, allowing users to adjust the influence of specific attributes in the generated images. - LoRA Slider Trainer: Enables the training of LoRA sliders, which can be used to control and adjust specific attributes in the generated images, offering a powerful tool for fine-tuning and customization. - Extensions: Supports the creation and sharing of custom extensions, allowing users to extend the functionality of the toolkit with their own tools and scripts. - VAE (Variational Auto Encoder) Trainer: Facilitates the training of VAEs for image generation, providing users with a tool to explore and improve the quality of generated images. The AI Toolkit is a valuable resource for anyone interested in exploring and utilizing machine learning for image generation and manipulation. Its user-friendly interface, extensive documentation, and active development make it an accessible and powerful tool for both beginners and experienced users.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.