
lhotse
Tools for handling speech data in machine learning projects.
Stars: 999

Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.
README:

Lhotse is a Python library aiming to make speech and audio data preparation flexible and accessible to a wider community. Alongside k2, it is a part of the next generation Kaldi speech processing library.
- (Interspeech 2023) Tutorial notebook
- (Interspeech 2023) Tutorial slides
- (Interspeech 2021) Recorded lecture (3h)
- Attract a wider community to speech processing tasks with a Python-centric design.
- Accommodate experienced Kaldi users with an expressive command-line interface.
- Provide standard data preparation recipes for commonly used corpora.
- Provide PyTorch Dataset classes for speech and audio related tasks.
- Flexible data preparation for model training with the notion of audio cuts.
- Efficiency, especially in terms of I/O bandwidth and storage capacity.
We currently have the following tutorials available in examples directory:
- Basic complete Lhotse workflow
- Transforming data with Cuts
- WebDataset integration
- How to combine multiple datasets
- Lhotse Shar: storage format optimized for sequential I/O and modularity
Check out the following links to see how Lhotse is being put to use:
- Icefall recipes: where k2 and Lhotse meet.
- Minimal ESPnet+Lhotse example:
Like Kaldi, Lhotse provides standard data preparation recipes, but extends that with a seamless PyTorch integration through task-specific Dataset classes. The data and meta-data are represented in human-readable text manifests and exposed to the user through convenient Python classes.
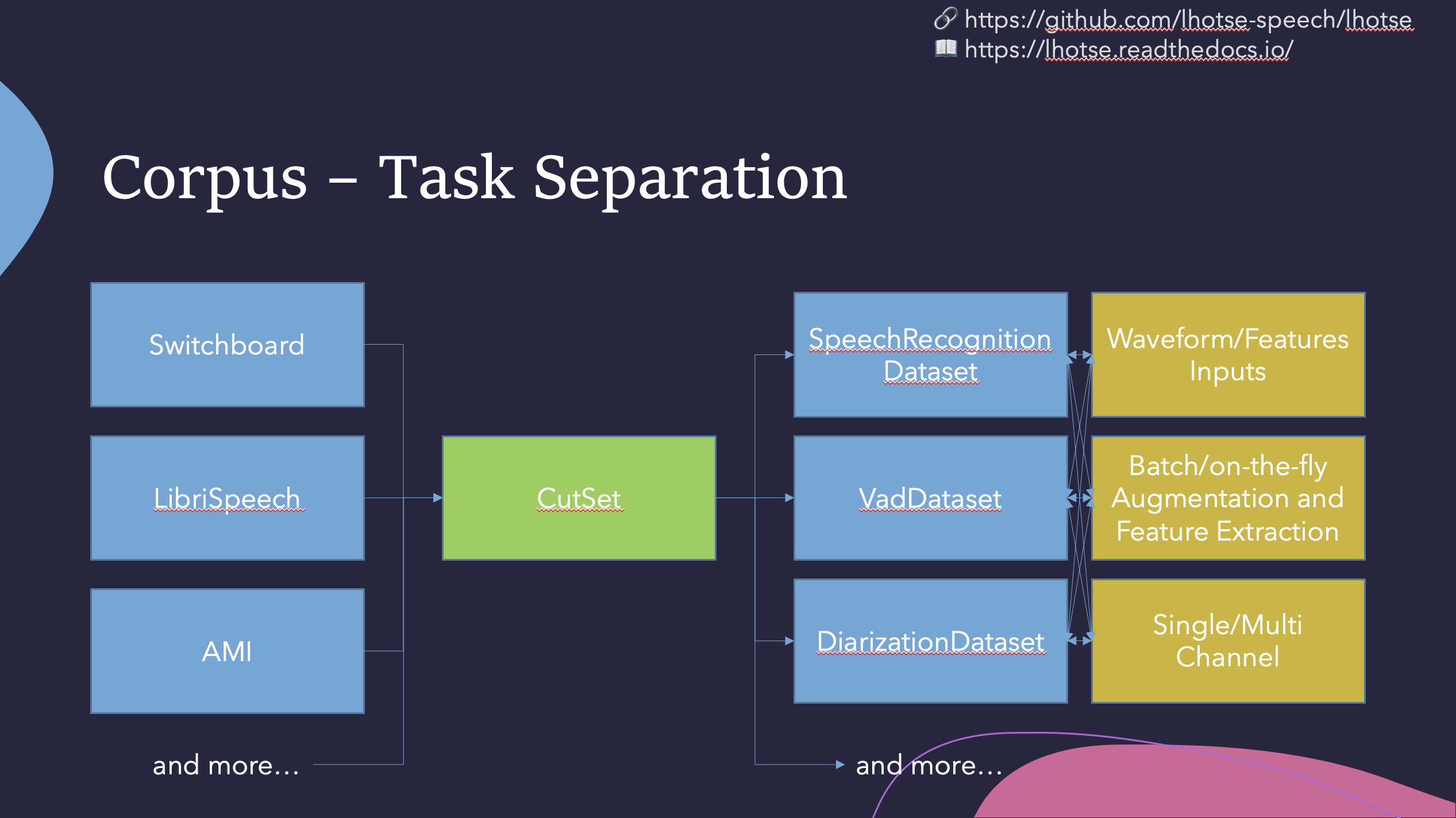
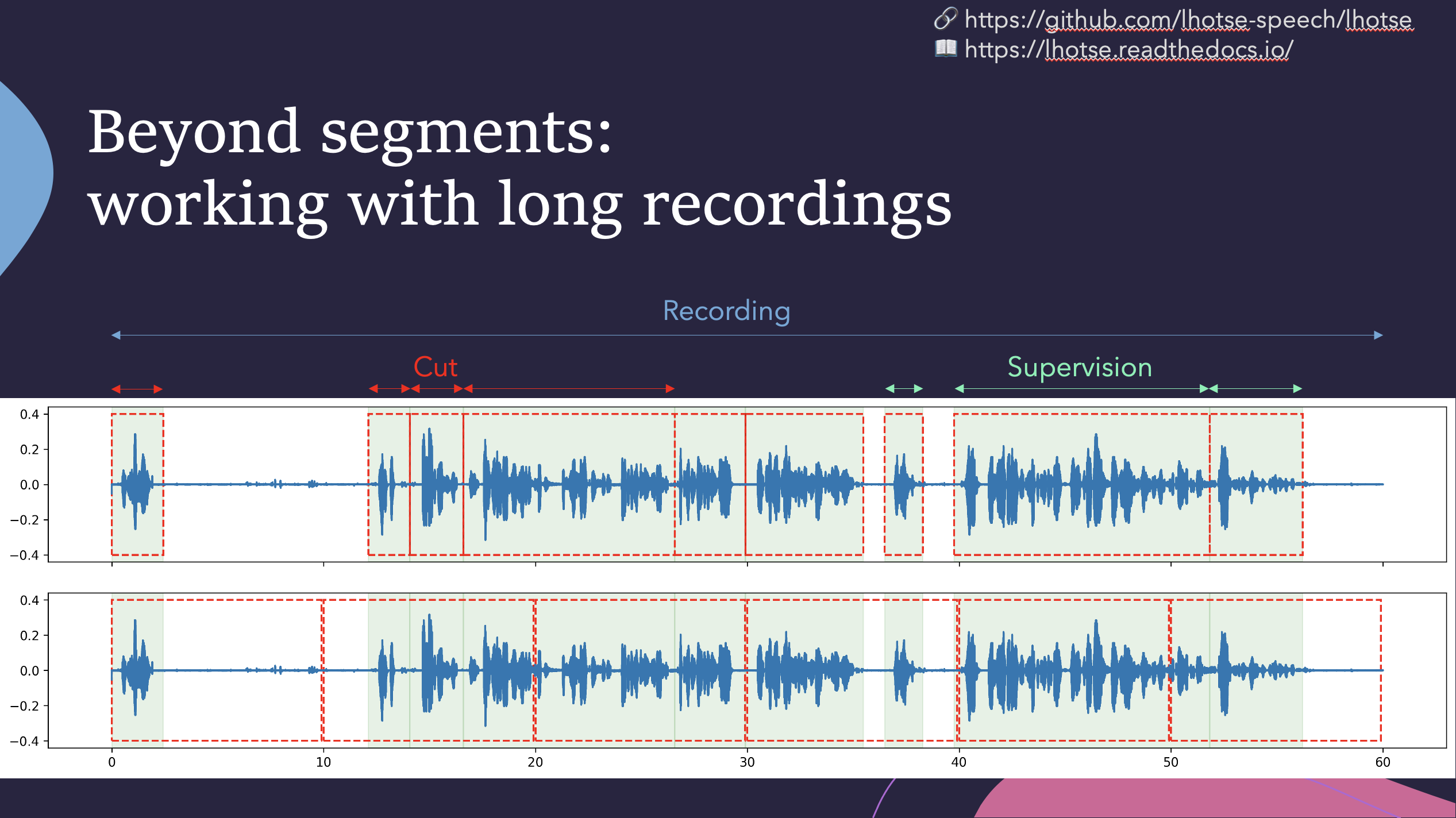
Lhotse introduces the notion of audio cuts, designed to ease the training data construction with operations such as mixing, truncation and padding that are performed on-the-fly to minimize the amount of storage required. Data augmentation and feature extraction are supported both in pre-computed mode, with highly-compressed feature matrices stored on disk, and on-the-fly mode that computes the transformations upon request. Additionally, Lhotse introduces feature-space cut mixing to make the best of both worlds.
Lhotse supports Python version 3.7 and later.
Lhotse is available on PyPI:
pip install lhotse
To install the latest, unreleased version, do:
pip install git+https://github.com/lhotse-speech/lhotse
For development installation, you can fork/clone the GitHub repo and install with pip:
git clone https://github.com/lhotse-speech/lhotse
cd lhotse
pip install -e '.[dev]'
pre-commit install # installs pre-commit hooks with style checks
# Running unit tests
pytest test
# Running linter checks
pre-commit run
This is an editable installation (-e option), meaning that your changes to the source code are automatically
reflected when importing lhotse (no re-install needed). The [dev] part means you're installing extra dependencies
that are used to run tests, build documentation or launch jupyter notebooks.
Lhotse uses several environment variables to customize it's behavior. They are as follows:
-
LHOTSE_REQUIRE_TORCHAUDIO- when it's set and not any of1|True|true|yes, we'll not check for torchaudio being installed and remove it from the requirements. It will disable many functionalities of Lhotse but the basic capabilities will remain (including reading audio withsoundfile). -
LHOTSE_AUDIO_DURATION_MISMATCH_TOLERANCE- used when we load audio from a file and receive a different number of samples than declared inRecording.num_samples. This is sometimes necessary because different codecs (or even different versions of the same codec) may use different padding when decoding compressed audio. Typically values up to 0.1, or even 0.3 (second) are still reasonable, and anything beyond that indicates a serious issue. -
LHOTSE_AUDIO_BACKEND- may be set to any of the values returned from CLIlhotse list-audio-backendsto override the default behavior of trial-and-error and always use a specific audio backend. -
LHOTSE_AUDIO_LOADING_EXCEPTION_VERBOSE- when set to1we'll emit full exception stack traces when every available audio backend fails to load a given file (they might be very large). -
LHOTSE_DILL_ENABLED- when it's set to1|True|true|yes, we will enabledill-based serialization ofCutSetandSampleracross processes (it's disabled by default even whendillis installed). -
LHOTSE_LEGACY_OPUS_LOADING- (=1) reverts to a legacy OPUS loading mechanism that triggered a new ffmpeg subprocess for each OPUS file. -
LHOTSE_PREPARING_RELEASE- used internally by developers when releasing a new version of Lhotse. -
TORCHAUDIO_USE_BACKEND_DISPATCHER- when set to1and torchaudio version is below 2.1, we'll enable the experimental ffmpeg backend of torchaudio. -
AIS_ENDPOINTis read by AIStore client to determine AIStore endpoint URL. Required for AIStore dataloading. -
RANK,WORLD_SIZE,WORKER, andNUM_WORKERSare internally used to inform Lhotse Shar dataloading subprocesses. -
READTHEDOCSis internally used for documentation builds. -
LHOTSE_MSC_OVERRIDE_PROTOCOLS- when set, it will override your input protocols before feeding to MSCIOBackend. Useful when you don't want to change your existing url format but want to use MSCIOBackend. For example, if you haves3://s3-bucket/path/to/my/objectandgs://gs-bucket/path/to/my/object, you can setLHOTSE_MSC_OVERRIDE_PROTOCOLS=s3,gsto override the urls tomsc://s3-bucket/path/to/my/objectandmsc://gs-bucket/path/to/my/object. -
LHOTSE_MSC_PROFILE- when set, it will override the your bucket name before feeding to MSCIOBackend. Useful when your msc profile is not the same as your bucket name. For example, if you haves3://s3-bucket/path/to/my/object, you can setLHOTSE_MSC_OVERRIDE_PROTOCOLS=s3andLHOTSE_MSC_PROFILE=msc-s3-profileto override the url tomsc://msc-s3-profile/path/to/my/object.
Other pip packages. You can leverage optional features of Lhotse by installing the relevant supporting package:
-
torchaudioused to be a core dependency in Lhotse, but is now optional. Refer to official PyTorch documentation for installation. -
pip install lhotse[kaldi]for a maximal feature set related to Kaldi compatibility. It includes libraries such askaldi_native_io(a more efficient variant ofkaldi_io) andkaldifeatthat port some of Kaldi functionality into Python. -
pip install lhotse[orjson]for up to 50% faster reading of JSONL manifests. -
pip install lhotse[webdataset]. We support "compiling" your data into WebDataset tarball format for more effective IO. You can still interact with the data as if it was a regular lazy CutSet. To learn more, check out the following tutorial: -
pip install h5pyif you want to extract speech features and store them as HDF5 arrays. -
pip install dill. Whendillis installed, we'll use it to pickle CutSet that uses a lambda function in calls such as.mapor.filter. This is helpful in PyTorch DataLoader withnum_jobs>0. Withoutdill, depending on your environment, you'll see an exception or a hanging script. -
pip install aistoreto read manifests, tar fles, and other data from AIStore using AIStore-supported URLs (setAIS_ENDPOINTenvironment variable to activate it). See AIStore documentation for more details. -
pip install smart_opento read and write manifests and data in any location supported bysmart_open(e.g. cloud, http). -
pip install opensmilefor feature extraction using the OpenSmile toolkit's Python wrapper. -
pip install multi-storage-clientfor read and write manifests and data in different storage backends. See multi-storage-client for more details.
sph2pipe. For reading older LDC SPHERE (.sph) audio files that are compressed with codecs unsupported by ffmpeg and sox, please run:
# CLI
lhotse install-sph2pipe
# Python
from lhotse.tools import install_sph2pipe
install_sph2pipe()
It will download it to ~/.lhotse/tools, compile it, and auto-register in PATH. The program should be automatically detected and used by Lhotse.
We have example recipes showing how to prepare data and load it in Python as a PyTorch Dataset.
They are located in the examples directory.
A short snippet to show how Lhotse can make audio data preparation quick and easy:
from torch.utils.data import DataLoader
from lhotse import CutSet, Fbank
from lhotse.dataset import VadDataset, SimpleCutSampler
from lhotse.recipes import prepare_switchboard
# Prepare data manifests from a raw corpus distribution.
# The RecordingSet describes the metadata about audio recordings;
# the sampling rate, number of channels, duration, etc.
# The SupervisionSet describes metadata about supervision segments:
# the transcript, speaker, language, and so on.
swbd = prepare_switchboard('/export/corpora3/LDC/LDC97S62')
# CutSet is the workhorse of Lhotse, allowing for flexible data manipulation.
# We create 5-second cuts by traversing SWBD recordings in windows.
# No audio data is actually loaded into memory or stored to disk at this point.
cuts = CutSet.from_manifests(
recordings=swbd['recordings'],
supervisions=swbd['supervisions']
).cut_into_windows(duration=5)
# We compute the log-Mel filter energies and store them on disk;
# Then, we pad the cuts to 5 seconds to ensure all cuts are of equal length,
# as the last window in each recording might have a shorter duration.
# The padding will be performed once the features are loaded into memory.
cuts = cuts.compute_and_store_features(
extractor=Fbank(),
storage_path='feats',
num_jobs=8
).pad(duration=5.0)
# Construct a Pytorch Dataset class for Voice Activity Detection task:
dataset = VadDataset()
sampler = SimpleCutSampler(cuts, max_duration=300)
dataloader = DataLoader(dataset, sampler=sampler, batch_size=None)
batch = next(iter(dataloader))The VadDataset will yield a batch with pairs of feature and supervision tensors such as the following - the speech
starts roughly at the first second (100 frames):

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for lhotse
Similar Open Source Tools
lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.
lantern
Lantern is an open-source PostgreSQL database extension designed to store vector data, generate embeddings, and handle vector search operations efficiently. It introduces a new index type called 'lantern_hnsw' for vector columns, which speeds up 'ORDER BY ... LIMIT' queries. Lantern utilizes the state-of-the-art HNSW implementation called usearch. Users can easily install Lantern using Docker, Homebrew, or precompiled binaries. The tool supports various distance functions, index construction parameters, and operator classes for efficient querying. Lantern offers features like embedding generation, interoperability with pgvector, parallel index creation, and external index graph generation. It aims to provide superior performance metrics compared to other similar tools and has a roadmap for future enhancements such as cloud-hosted version, hardware-accelerated distance metrics, industry-specific application templates, and support for version control and A/B testing of embeddings.
obs-cleanstream
CleanStream is an OBS plugin that utilizes AI to clean live audio streams by removing unwanted words and utterances, such as 'uh's and 'um's, and configurable words like profanity. It uses a neural network (OpenAI Whisper) in real-time to predict speech and eliminate unwanted words. The plugin is still experimental and not recommended for live production use, but it is functional for testing purposes. Users can adjust settings and configure the plugin to enhance audio quality during live streams.

obs-cleanstream
CleanStream is an OBS plugin that utilizes real-time local AI to clean live audio streams by removing unwanted words and utterances, such as 'uh' and 'um', and configurable words like profanity. It employs a neural network (OpenAI Whisper) to predict speech in real-time and eliminate undesired words. The plugin runs efficiently using the Whisper.cpp project from ggerganov. CleanStream offers users the ability to adjust settings and add the plugin to any audio-generating source in OBS, providing a seamless experience for content creators looking to enhance the quality of their live audio streams.

rtdl-num-embeddings
This repository provides the official implementation of the paper 'On Embeddings for Numerical Features in Tabular Deep Learning'. It focuses on transforming scalar continuous features into vectors before integrating them into the main backbone of tabular neural networks, showcasing improved performance. The embeddings for continuous features are shown to enhance the performance of tabular DL models and are applicable to various conventional backbones, offering efficiency comparable to Transformer-based models. The repository includes Python packages for practical usage, exploration of metrics and hyperparameters, and reproducing reported results for different algorithms and datasets.

HuggingFaceGuidedTourForMac
HuggingFaceGuidedTourForMac is a guided tour on how to install optimized pytorch and optionally Apple's new MLX, JAX, and TensorFlow on Apple Silicon Macs. The repository provides steps to install homebrew, pytorch with MPS support, MLX, JAX, TensorFlow, and Jupyter lab. It also includes instructions on running large language models using HuggingFace transformers. The repository aims to help users set up their Macs for deep learning experiments with optimized performance.

llm-memorization
The 'llm-memorization' project is a tool designed to index, archive, and search conversations with a local LLM using a SQLite database enriched with automatically extracted keywords. It aims to provide personalized context at the start of a conversation by adding memory information to the initial prompt. The tool automates queries from local LLM conversational management libraries, offers a hybrid search function, enhances prompts based on posed questions, and provides an all-in-one graphical user interface for data visualization. It supports both French and English conversations and prompts for bilingual use.
qsv
qsv is a command line program for querying, slicing, indexing, analyzing, filtering, enriching, transforming, sorting, validating, joining, formatting & converting tabular data (CSV, spreadsheets, DBs, parquet, etc). Commands are simple, composable & 'blazing fast'. It is a blazing-fast data-wrangling toolkit with a focus on speed, processing very large files, and being a complete data-wrangling toolkit. It is designed to be portable, easy to use, secure, and easy to contribute to. qsv follows the RFC 4180 CSV standard, requires UTF-8 encoding, and supports various file formats. It has extensive shell completion support, automatic compression/decompression using Snappy, and supports environment variables and dotenv files. qsv has a comprehensive test suite and is dual-licensed under MIT or the UNLICENSE.
stable-diffusion-discord-bot
A discord bot built to interface with the InvokeAI fork of stable-diffusion. It is a work in progress for a major rewrite of the arty project, compatible with `invokeai 5.1.1`. The bot supports various functionalities like building node graphs from job requests, refreshing renders using png metadata, removing backgrounds, job progress tracking, and LLM integration. Users can install custom invokeai nodes for advanced functionality and launch the bot natively or with docker. Patches and pull requests are welcomed.
EuroEval
EuroEval is a robust European language model benchmark tool, formerly known as ScandEval. It provides a platform to benchmark pretrained models on various tasks across different languages. Users can evaluate models, datasets, and metrics both online and offline. The tool supports benchmarking from the command line, script, and Docker. Additionally, users can reproduce datasets used in the project using provided scripts. EuroEval welcomes contributions and offers guidelines for general contributions and adding new datasets.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.
linkedin-api
The Linkedin API for Python allows users to programmatically search profiles, send messages, and find jobs using a regular Linkedin user account. It does not require 'official' API access, just a valid Linkedin account. However, it is important to note that this library is not officially supported by LinkedIn and using it may violate LinkedIn's Terms of Service. Users can authenticate using any Linkedin account credentials and access features like getting profiles, profile contact info, and connections. The library also provides commercial alternatives for extracting data, scraping public profiles, and accessing a full LinkedIn API. It is not endorsed or supported by LinkedIn and is intended for educational purposes and personal use only.
ai-cli-lib
The ai-cli-lib is a library designed to enhance interactive command-line editing programs by integrating with GPT large language model servers. It allows users to obtain AI help from servers like Anthropic's or OpenAI's, or a llama.cpp server. The library acts as a command line copilot, providing natural language prompts and responses to enhance user experience and productivity. It supports various platforms such as Debian GNU/Linux, macOS, and Cygwin, and requires specific packages for installation and operation. Users can configure the library to activate during shell startup and interact with command-line programs like bash, mysql, psql, gdb, sqlite3, and bc. Additionally, the library provides options for configuring API keys, setting up llama.cpp servers, and ensuring data privacy by managing context settings.
mark
Mark is a CLI tool that allows users to interact with large language models (LLMs) using Markdown format. It enables users to seamlessly integrate GPT responses into Markdown files, supports image recognition, scraping of local and remote links, and image generation. Mark focuses on using Markdown as both a prompt and response medium for LLMs, offering a unique and flexible way to interact with language models for various use cases in development and documentation processes.
For similar tasks
lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.

langtest
LangTest is a comprehensive evaluation library for custom LLM and NLP models. It aims to deliver safe and effective language models by providing tools to test model quality, augment training data, and support popular NLP frameworks. LangTest comes with benchmark datasets to challenge and enhance language models, ensuring peak performance in various linguistic tasks. The tool offers more than 60 distinct types of tests with just one line of code, covering aspects like robustness, bias, representation, fairness, and accuracy. It supports testing LLMS for question answering, toxicity, clinical tests, legal support, factuality, sycophancy, and summarization.
awesome-object-detection-datasets
This repository is a curated list of awesome public object detection and recognition datasets. It includes a wide range of datasets related to object detection and recognition tasks, such as general detection and recognition datasets, autonomous driving datasets, adverse weather datasets, person detection datasets, anti-UAV datasets, optical aerial imagery datasets, low-light image datasets, infrared image datasets, SAR image datasets, multispectral image datasets, 3D object detection datasets, vehicle-to-everything field datasets, super-resolution field datasets, and face detection and recognition datasets. The repository also provides information on tools for data annotation, data augmentation, and data management related to object detection tasks.
bittensor
Bittensor is an internet-scale neural network that incentivizes computers to provide access to machine learning models in a decentralized and censorship-resistant manner. It operates through a token-based mechanism where miners host, train, and procure machine learning systems to fulfill verification problems defined by validators. The network rewards miners and validators for their contributions, ensuring continuous improvement in knowledge output. Bittensor allows anyone to participate, extract value, and govern the network without centralized control. It supports tasks such as generating text, audio, images, and extracting numerical representations.
smile
Smile (Statistical Machine Intelligence and Learning Engine) is a comprehensive machine learning, NLP, linear algebra, graph, interpolation, and visualization system in Java and Scala. It covers every aspect of machine learning, including classification, regression, clustering, association rule mining, feature selection, manifold learning, multidimensional scaling, genetic algorithms, missing value imputation, efficient nearest neighbor search, etc. Smile implements major machine learning algorithms and provides interactive shells for Java, Scala, and Kotlin. It supports model serialization, data visualization using SmilePlot and declarative approach, and offers a gallery showcasing various algorithms and visualizations.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.
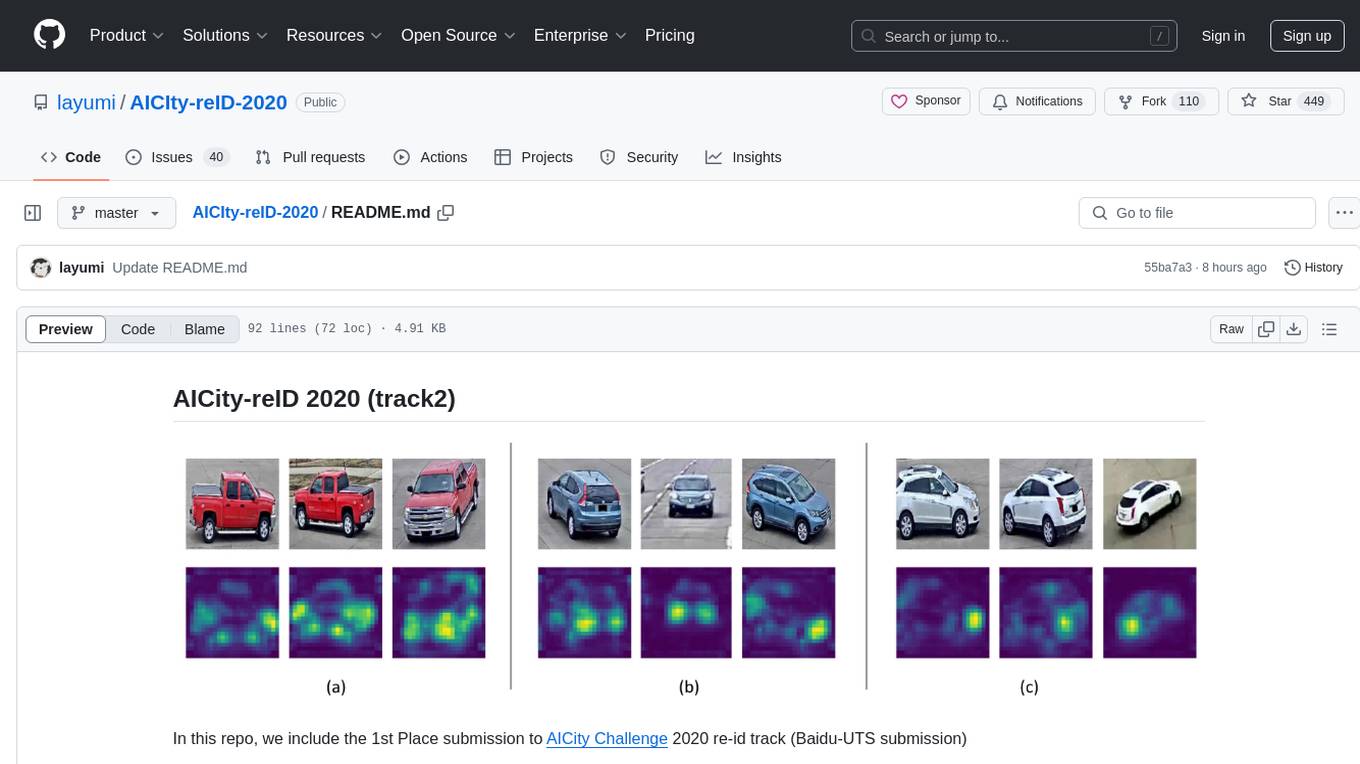
AICIty-reID-2020
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.
VideoTree
VideoTree is an official implementation for a query-adaptive and hierarchical framework for understanding long videos with LLMs. It dynamically extracts query-related information from input videos and builds a tree-based video representation for LLM reasoning. The tool requires Python 3.8 or above and leverages models like LaViLa and EVA-CLIP-8B for feature extraction. It also provides scripts for tasks like Adaptive Breath Expansion, Relevance-based Depth Expansion, and LLM Reasoning. The codebase is being updated to incorporate scripts/captions for NeXT-QA and IntentQA in the future.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.