
NSMusicS
NSMusicS,Multi platform Multi mode Music Software ,Electron(Vue3+Vite+TypeScript)+.net core+AI
Stars: 713

NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.
README:
A local music software that is expected to support multiple platforms with AI capabilities and multimodal features.
The current development phase is to develop an Elecetron cross platform music software that is compatible with Navichrome and has a beautiful UI, and to simultaneously develop music artificial intelligence and streaming services as cloud services for NSMusicS
The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.
| Project | Development status | Technology Framework | Author/Copyright Owner | Operating systems | LICENSE | Software positioning |
|---|---|---|---|---|---|---|
| NSMusicS (Now) | updateing | electron,docker,vue,nodejs,ts,vite,sqlite |
Xiang Cheng | (Windows,Linux(ubuntu+,Docker),MacOS,Android11++,IOS) Based on the Chrome kernel | A-GPL 3.0 | Open source + Commercial |
| NSMusicS_WPF (Old) | complete | dotnet8(wpf),cs,window,sqlite |
Xiang Cheng | (Windows10++) | A-GPL 3.0 | Open source + Commercial |
| NSMusicS_For_PythonApp_Of_AudioProcessing | will developed | pytorch,py |
Xiang Cheng | python | Apache License 2.0 | Open source |
| NSMusicS_For_Knowledge_Graph | Not started | NebulaGraph / Neo4j |
Xiang Cheng | (Windows10++/Linux) | A-GPL 3.0 | Open source + Commercial |
| NSMusicS_For_Flutter | Not started | flutter,dart |
Xiang Cheng | (Windows10++,Linux(ubuntu+,群晖Nas+Docker),MacOS,Android11++,IOS) | A-GPL 3.0 | Open source + Commercial |
| MZMusic | Not started | electron,docker,vue,nodejs,ts,vite |
MZMusic Team | (win,linux,macos...) | Apache License 2.0 | Open source |
- NSMusicS(Electron):Under development
.png) |
.png) |
- NSMusicS_WPF (Old):Development completed
.png) |
.png) |
- If you haven't installed Navidrome, please install and start its service, and then add your computer's music to Navidrome.
- Copy and replace the navidrome.db file located in the resources folder of the folder where NSMusicS Electron is installed with the navidrome installation location \ navidrome installation version \ navidrome.db.
- Because the library management module has not been written yet, Navidrome is temporarily borrowed to achieve this. After the official version is released, users can choose whether to be compatible with Navidrome (if compatibility is needed, Navidrome service must exist on your host).
cd NSMusicS
# node -v 20.15.0
# npm -v 10.4.0
npm install
# Install MPV in the Windows environment (requires its executable file compressed file)
# https://mpv.io/installation/
# unzip its contents to (NSMusicS\resources\mpv-x86_64-20240623)# You need to recompile the native module better sqlite3 to allow the sqlite database to read normally
cd NSMusicS/node_modules/better-sqlite3
npm install electron-rebuild -D
# 1.open better-sqlite3/package.json
# 2.scripts addline: "rebuild": "electron-rebuild -f -w better-sqlite3"
npm run rebuild cd NSMusicS
npm run dev # Direct operation NSmusicScd NSMusicS
npm run build-only # Package into the current system_configs's software package (such as exe)- NSMusicS Web Of Thanks:
- NSMusicS Web ImageResource Thanks:
- NSMusicS WPF Of Thanks:
- As this project is currently independently developed by Xiang Cheng(myself), programming standards are a personal habit of the Xiang Cheng(myself), and coding standards are not yet standardized enough. However, this project will continue to undergo self refactoring and reverse development. It can be affirmed that in the future, NSMusicS will form a standard coding specification, which will be beneficial for the community to develop third-party NSMusicS plugins, Enable NSMusicS to meet the diverse needs of more potential customers,Most importantly, NSMusicS will always be open source and continuously updated
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for NSMusicS
Similar Open Source Tools
NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.
ovos-buildroot
OVOS - Buildroot OS is a minimalistic Linux OS designed to bring the open source voice assistant ovos-core to embedded, low-spec headless, and small touchscreen devices. It includes a full 64-bit distribution with Linux kernel 6.1.x, Buildroot 2023.02.x, and OVOS framework utilizing ovos-docker containers. The supported hardware includes Raspberry Pi 3, 3b, 3b+, Raspberry Pi 4, x86_64 Intel-based computers, and Open Virtual Appliance. The project is inspired by Mycroft AI, Buildroot, and HassOS, offering a platform for building voice assistant solutions on various devices.
Vision-Agents
Vision Agents is an open-source project by Stream that provides building blocks for creating intelligent, low-latency video experiences powered by custom models and infrastructure. It offers multi-modal AI agents that watch, listen, and understand video in real-time. The project includes SDKs for various platforms and integrates with popular AI services like Gemini and OpenAI. Vision Agents can be used for tasks such as sports coaching, security camera systems with package theft detection, and building invisible assistants for various applications. The project aims to simplify the development of real-time vision AI applications by providing a range of processors, integrations, and out-of-the-box features.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

vllm-ascend
vLLM Ascend plugin is a backend plugin designed to run vLLM on the Ascend NPU. It provides a hardware-pluggable interface that allows popular open-source models to run seamlessly on the Ascend NPU. The plugin is recommended within the vLLM community and adheres to the principles of hardware pluggability outlined in the RFC. Users can set up their environment with specific hardware and software prerequisites to utilize this plugin effectively.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.
Open-Interface
Open Interface is a self-driving software that automates computer tasks by sending user requests to a language model backend (e.g., GPT-4V) and simulating keyboard and mouse inputs to execute the steps. It course-corrects by sending current screenshots to the language models. The tool supports MacOS, Linux, and Windows, and requires setting up the OpenAI API key for access to GPT-4V. It can automate tasks like creating meal plans, setting up custom language model backends, and more. Open Interface is currently not efficient in accurate spatial reasoning, tracking itself in tabular contexts, and navigating complex GUI-rich applications. Future improvements aim to enhance the tool's capabilities with better models trained on video walkthroughs. The tool is cost-effective, with user requests priced between $0.05 - $0.20, and offers features like interrupting the app and primary display visibility in multi-monitor setups.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.

FFAIVideo
FFAIVideo is a lightweight node.js project that utilizes popular AI LLM to intelligently generate short videos. It supports multiple AI LLM models such as OpenAI, Moonshot, Azure, g4f, Google Gemini, etc. Users can input text to automatically synthesize exciting video content with subtitles, background music, and customizable settings. The project integrates Microsoft Edge's online text-to-speech service for voice options and uses Pexels website for video resources. Installation of FFmpeg is essential for smooth operation. Inspired by MoneyPrinterTurbo, MoneyPrinter, and MsEdgeTTS, FFAIVideo is designed for front-end developers with minimal dependencies and simple usage.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.

CuMo
CuMo is a project focused on scaling multimodal Large Language Models (LLMs) with Co-Upcycled Mixture-of-Experts. It introduces CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into the vision encoder and the MLP connector, enhancing the capabilities of multimodal LLMs. The project adopts a three-stage training approach with auxiliary losses to stabilize the training process and maintain a balanced loading of experts. CuMo achieves comparable performance to other state-of-the-art multimodal LLMs on various Visual Question Answering (VQA) and visual-instruction-following benchmarks.

outspeed
Outspeed is a PyTorch-inspired SDK for building real-time AI applications on voice and video input. It offers low-latency processing of streaming audio and video, an intuitive API familiar to PyTorch users, flexible integration of custom AI models, and tools for data preprocessing and model deployment. Ideal for developing voice assistants, video analytics, and other real-time AI applications processing audio-visual data.
keras-llm-robot
The Keras-llm-robot Web UI project is an open-source tool designed for offline deployment and testing of various open-source models from the Hugging Face website. It allows users to combine multiple models through configuration to achieve functionalities like multimodal, RAG, Agent, and more. The project consists of three main interfaces: chat interface for language models, configuration interface for loading models, and tools & agent interface for auxiliary models. Users can interact with the language model through text, voice, and image inputs, and the tool supports features like model loading, quantization, fine-tuning, role-playing, code interpretation, speech recognition, image recognition, network search engine, and function calling.

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.
For similar tasks
Awesome-AITools
This repo collects AI-related utilities. ## All Categories * All Categories * ChatGPT and other closed-source LLMs * AI Search engine * Open Source LLMs * GPT/LLMs Applications * LLM training platform * Applications that integrate multiple LLMs * AI Agent * Writing * Programming Development * Translation * AI Conversation or AI Voice Conversation * Image Creation * Speech Recognition * Text To Speech * Voice Processing * AI generated music or sound effects * Speech translation * Video Creation * Video Content Summary * OCR(Optical Character Recognition)
NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.
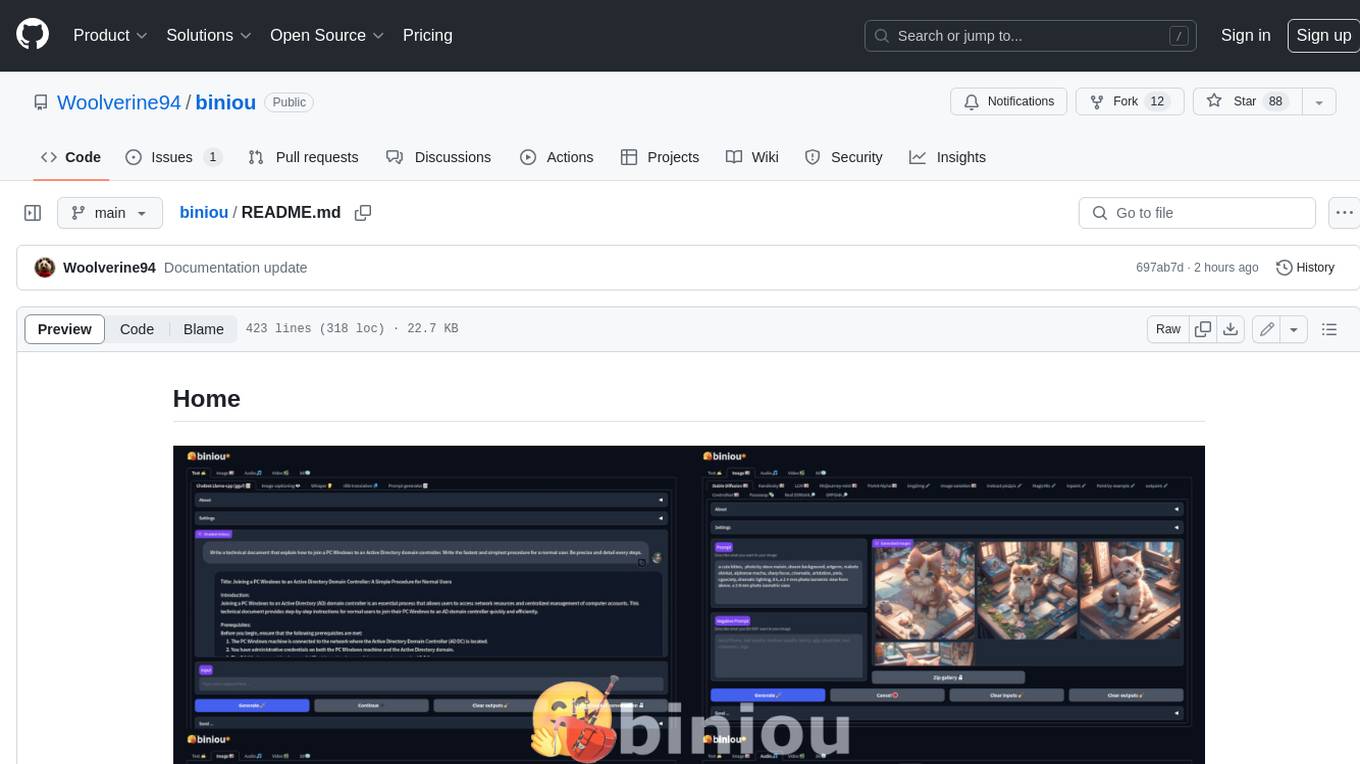
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
generative-ai-js
Generative AI JS is a JavaScript library that provides tools for creating generative art and music using artificial intelligence techniques. It allows users to generate unique and creative content by leveraging machine learning models. The library includes functions for generating images, music, and text based on user input and preferences. With Generative AI JS, users can explore the intersection of art and technology, experiment with different creative processes, and create dynamic and interactive content for various applications.
pictureChange
The 'pictureChange' repository is a plugin that supports image processing using Baidu AI, stable diffusion webui, and suno music composition AI. It also allows for file summarization and image summarization using AI. The plugin supports various stable diffusion models, administrator control over group chat features, concurrent control, and custom templates for image and text generation. It can be deployed on WeChat enterprise accounts, personal accounts, and public accounts.
Generative-AI-Indepth-Basic-to-Advance
Generative AI Indepth Basic to Advance is a repository focused on providing tutorials and resources related to generative artificial intelligence. The repository covers a wide range of topics from basic concepts to advanced techniques in the field of generative AI. Users can find detailed explanations, code examples, and practical demonstrations to help them understand and implement generative AI algorithms. The goal of this repository is to help beginners get started with generative AI and to provide valuable insights for more experienced practitioners.
nodetool
NodeTool is a platform designed for AI enthusiasts, developers, and creators, providing a visual interface to access a variety of AI tools and models. It simplifies access to advanced AI technologies, offering resources for content creation, data analysis, automation, and more. With features like a visual editor, seamless integration with leading AI platforms, model manager, and API integration, NodeTool caters to both newcomers and experienced users in the AI field.
ai-enhanced-audio-book
The ai-enhanced-audio-book repository contains AI-enhanced audio plugins developed using C++, JUCE, libtorch, RTNeural, and other libraries. It showcases neural networks learning to emulate guitar amplifiers through waveforms. Users can visit the official website for more information and obtain a copy of the book from the publisher Taylor and Francis/ Routledge/ Focal.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.
NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.