
CodeGeeX4
CodeGeeX4-ALL-9B, a versatile model for all AI software development scenarios, including code completion, code interpreter, web search, function calling, repository-level Q&A and much more.
Stars: 1034

CodeGeeX4-ALL-9B is an open-source multilingual code generation model based on GLM-4-9B, offering enhanced code generation capabilities. It supports functions like code completion, code interpreter, web search, function call, and repository-level code Q&A. The model has competitive performance on benchmarks like BigCodeBench and NaturalCodeBench, outperforming larger models in terms of speed and performance.
README:
![]()
🏠 Homepage|🛠 Extensions VS Code, Jetbrains|🤗 HF Repo | 🪧 HF DEMO
We introduce CodeGeeX4-ALL-9B, the open-source version of the latest CodeGeeX4 model series. It is a multilingual code generation model continually trained on the GLM-4-9B, significantly enhancing its code generation capabilities. Using a single CodeGeeX4-ALL-9B model, it can support comprehensive functions such as code completion and generation, code interpreter, web search, function call, repository-level code Q&A, covering various scenarios of software development. CodeGeeX4-ALL-9B has achieved highly competitive performance on public benchmarks, such as BigCodeBench and NaturalCodeBench. It is currently the most powerful code generation model with less than 10B parameters, even surpassing much larger general-purpose models, achieving the best balance in terms of inference speed and model performance.
| Model | Type | Seq Length | Download |
|---|---|---|---|
| codegeex4-all-9b | Chat | 128K | 🤗 Huggingface 🤖 ModelScope 🟣 WiseModel |
CodeGeeX4 is now available on Ollama! Please install Ollama 0.2 or later and run the following command:
ollama run codegeex4To connect the local model to our VS Code / Jetbrains extensions, please check Local Mode Guideline.
Use 4.39.0<=transformers<=4.40.2 to quickly launch codegeex4-all-9b:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("THUDM/codegeex4-all-9b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/codegeex4-all-9b",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
inputs = tokenizer.apply_chat_template([{"role": "user", "content": "write a quick sort"}], add_generation_prompt=True, tokenize=True, return_tensors="pt", return_dict=True ).to(device)
with torch.no_grad():
outputs = model.generate(**inputs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Use vllm==0.5.1 to quickly launch codegeex4-all-9b:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# CodeGeeX4-ALL-9B
# max_model_len, tp_size = 1048576, 4
# If OOM,please reduce max_model_len,or increase tp_size
max_model_len, tp_size = 131072, 1
model_name = "codegeex4-all-9b"
prompt = [{"role": "user", "content": "Hello"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# If OOM,try using follong parameters
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
Set up OpenAI Compatible Server via vllm, detailed please check OpenAI Compatible Server
python -m vllm.entrypoints.openai.api_server \
--model THUDM/codegeex4-all-9b \
--trust_remote_code
Codegeex4 now suport Candle framwork Repo
Use Rust to launch codegeex4-all-9b:
cd candle_demo
cargo build -p codegeex4-cli --release --features cuda # for Cuda
cargo build -p codegeex4-cli --release # for cpu
./target/release/codegeex4-cli --sample-len 512CodeGeeX4-ALL-9B provides three user guides to help users quickly understand and use the model:

-
System Prompt Guideline: This guide introduces how to use system prompts in CodeGeeX4-ALL-9B, including the VSCode extension official system prompt, customized system prompts, and some tips for maintaining multi-turn dialogue history.
-
Infilling Guideline: This guide explains the VSCode extension official infilling format, covering general infilling, cross-file infilling, and generating a new file in a repository.
-
Repository Tasks Guideline: This guide demonstrates how to use repository tasks in CodeGeeX4-ALL-9B, including QA tasks at the repository level and how to trigger the aicommiter capability of CodeGeeX4-ALL-9B to perform deletions, additions, and changes to files at the repository level.
-
Local Mode Guideline:This guide introduces how to deploy CodeGeeX4-ALL-9B locally and connect it to Visual Studio Code / Jetbrains extensions.
These guides aim to provide a comprehensive understanding and facilitate efficient use of the model.
CodeGeeX4-ALL-9B is ranked as the most powerful model under 10 billion parameters, even surpassing general models several times its size, achieving the best balance between inference performance and model effectiveness.
| Model | Seq Length | HumanEval | MBPP | NCB | LCB | HumanEvalFIM | CRUXEval-O |
|---|---|---|---|---|---|---|---|
| Llama3-70B-intruct | 8K | 77.4 | 82.3 | 37.0 | 27.4 | - | - |
| DeepSeek Coder 33B Instruct | 16K | 81.1 | 80.4 | 39.3 | 29.3 | 78.2 | 49.9 |
| Codestral-22B | 32K | 81.1 | 78.2 | 46.0 | 35.3 | 91.6 | 51.3 |
| CodeGeeX4-All-9B | 128K | 82.3 | 75.7 | 40.4 | 28.5 | 85.0 | 47.1 |
CodeGeeX4-ALL-9B scored 48.9 and 40.4 for the complete and instruct tasks of BigCodeBench, which are the highest scores among models with less than 20 billion parameters.
 In CRUXEval, a benchmark for testing code reasoning, understanding, and execution capabilities, CodeGeeX4-ALL-9B presented remarkable results with its COT (chain-of-thought) abilities. From easy code generation tasks in HumanEval and MBPP, to very challenging tasks in NaturalCodeBench, CodeGeeX4-ALL-9B also achieved outstanding performance at its scale. It is currently the only code model that supports Function Call capabilities and even achieves a better execution success rate than GPT-4.
In CRUXEval, a benchmark for testing code reasoning, understanding, and execution capabilities, CodeGeeX4-ALL-9B presented remarkable results with its COT (chain-of-thought) abilities. From easy code generation tasks in HumanEval and MBPP, to very challenging tasks in NaturalCodeBench, CodeGeeX4-ALL-9B also achieved outstanding performance at its scale. It is currently the only code model that supports Function Call capabilities and even achieves a better execution success rate than GPT-4.
 Furthermore, in the "Code Needle In A Haystack" (NIAH) evaluation, the CodeGeeX4-ALL-9B model demonstrated its ability to retrieve code within contexts up to 128K, achieving a 100% retrieval accuracy in all python scripts.
Furthermore, in the "Code Needle In A Haystack" (NIAH) evaluation, the CodeGeeX4-ALL-9B model demonstrated its ability to retrieve code within contexts up to 128K, achieving a 100% retrieval accuracy in all python scripts.


Details of the evaluation results can be found in the Evaluation.
The code in this repository is open source under the Apache-2.0 license. The model weights are licensed under the Model License. CodeGeeX4-9B weights are open for academic research. For users who wish to use the models for commercial purposes, please fill in the registration form.
If you find our work helpful, please feel free to cite the following paper:
@inproceedings{zheng2023codegeex,
title={CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Benchmarking on HumanEval-X},
author={Qinkai Zheng and Xiao Xia and Xu Zou and Yuxiao Dong and Shan Wang and Yufei Xue and Zihan Wang and Lei Shen and Andi Wang and Yang Li and Teng Su and Zhilin Yang and Jie Tang},
booktitle={Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages={5673--5684},
year={2023}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for CodeGeeX4
Similar Open Source Tools
CodeGeeX4
CodeGeeX4-ALL-9B is an open-source multilingual code generation model based on GLM-4-9B, offering enhanced code generation capabilities. It supports functions like code completion, code interpreter, web search, function call, and repository-level code Q&A. The model has competitive performance on benchmarks like BigCodeBench and NaturalCodeBench, outperforming larger models in terms of speed and performance.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.

vision-parse
Vision Parse is a tool that leverages Vision Language Models to parse PDF documents into beautifully formatted markdown content. It offers smart content extraction, content formatting, multi-LLM support, PDF document support, and local model hosting using Ollama. Users can easily convert PDFs to markdown with high precision and preserve document hierarchy and styling. The tool supports multiple Vision LLM providers like OpenAI, LLama, and Gemini for accuracy and speed, making document processing efficient and effortless.

evalverse
Evalverse is an open-source project designed to support Large Language Model (LLM) evaluation needs. It provides a standardized and user-friendly solution for processing and managing LLM evaluations, catering to AI research engineers and scientists. Evalverse supports various evaluation methods, insightful reports, and no-code evaluation processes. Users can access unified evaluation with submodules, request evaluations without code via Slack bot, and obtain comprehensive reports with scores, rankings, and visuals. The tool allows for easy comparison of scores across different models and swift addition of new evaluation tools.
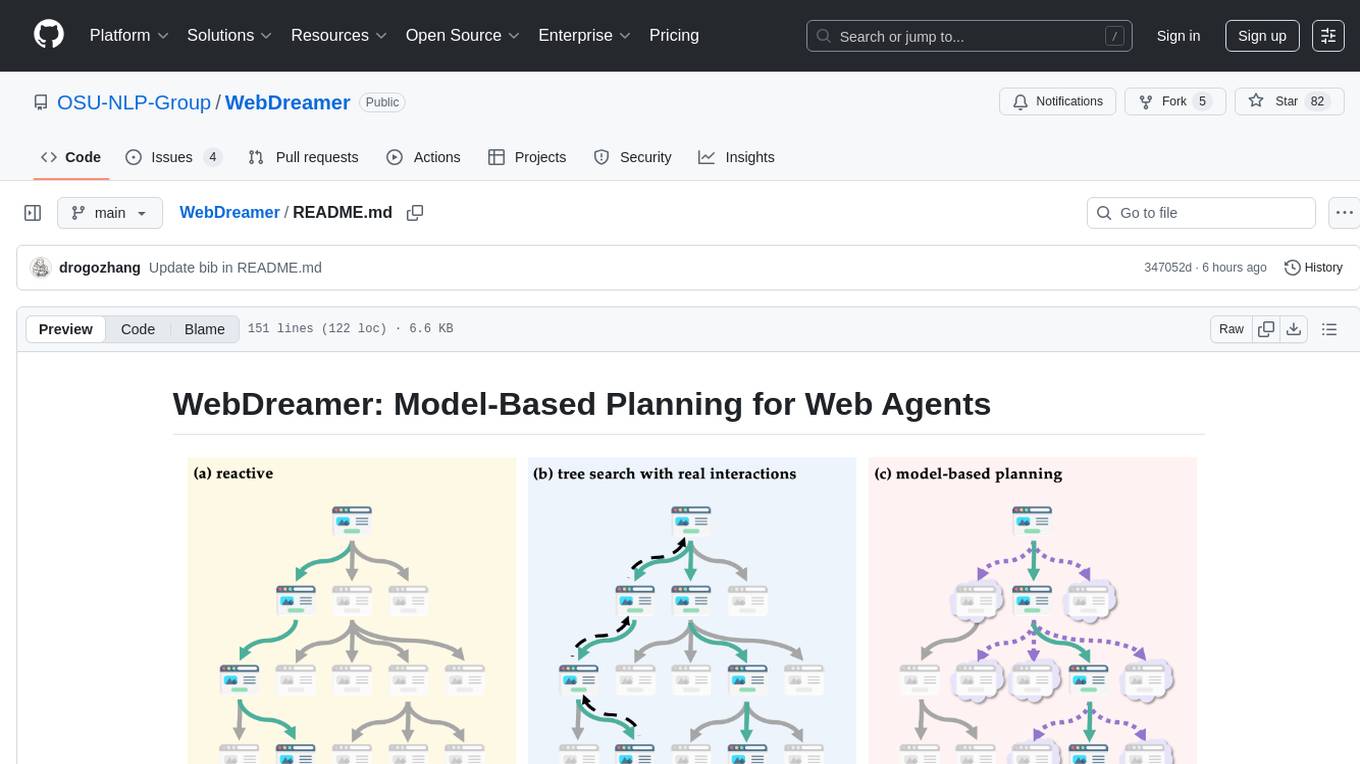
WebDreamer
WebDreamer is a model-based planning tool for web agents that uses large language models (LLMs) as a world model of the internet to predict outcomes of actions on websites. It employs LLM-based simulation for speculative planning on the web, offering greater safety and flexibility compared to traditional tree search methods. The tool provides modules for world model prediction, simulation scoring, and controller actions, enabling users to interact with web pages and achieve specific goals through simulated actions.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.
SynapseML
SynapseML (previously known as MMLSpark) is an open-source library that simplifies the creation of massively scalable machine learning (ML) pipelines. It provides simple, composable, and distributed APIs for various machine learning tasks such as text analytics, vision, anomaly detection, and more. Built on Apache Spark, SynapseML allows seamless integration of models into existing workflows. It supports training and evaluation on single-node, multi-node, and resizable clusters, enabling scalability without resource wastage. Compatible with Python, R, Scala, Java, and .NET, SynapseML abstracts over different data sources for easy experimentation. Requires Scala 2.12, Spark 3.4+, and Python 3.8+.

EasySteer
EasySteer is a unified framework built on vLLM for high-performance LLM steering. It offers fast, flexible, and easy-to-use steering capabilities with features like high performance, modular design, fine-grained control, pre-computed steering vectors, and an interactive demo. Users can interactively configure models, adjust steering parameters, and test interventions without writing code. The tool supports OpenAI-compatible APIs and provides modules for hidden states extraction, analysis-based steering, learning-based steering, and a frontend web interface for interactive steering and ReFT interventions.

BitBLAS
BitBLAS is a library for mixed-precision BLAS operations on GPUs, for example, the $W_{wdtype}A_{adtype}$ mixed-precision matrix multiplication where $C_{cdtype}[M, N] = A_{adtype}[M, K] \times W_{wdtype}[N, K]$. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the $W_{wdtype}A_{adtype}$ quantization in large language models (LLMs), for example, the $W_{UINT4}A_{FP16}$ in GPTQ, the $W_{INT2}A_{FP16}$ in BitDistiller, the $W_{INT2}A_{INT8}$ in BitNet-b1.58. BitBLAS is based on techniques from our accepted submission at OSDI'24.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.
For similar tasks
awesome-code-ai
A curated list of AI coding tools, including code completion, refactoring, and assistants. This list includes both open-source and commercial tools, as well as tools that are still in development. Some of the most popular AI coding tools include GitHub Copilot, CodiumAI, Codeium, Tabnine, and Replit Ghostwriter.
companion-vscode
Quack Companion is a VSCode extension that provides smart linting, code chat, and coding guideline curation for developers. It aims to enhance the coding experience by offering a new tab with features like curating software insights with the team, code chat similar to ChatGPT, smart linting, and upcoming code completion. The extension focuses on creating a smooth contribution experience for developers by turning contribution guidelines into a live pair coding experience, helping developers find starter contribution opportunities, and ensuring alignment between contribution goals and project priorities. Quack collects limited telemetry data to improve its services and products for developers, with options for anonymization and disabling telemetry available to users.
CodeGeeX4
CodeGeeX4-ALL-9B is an open-source multilingual code generation model based on GLM-4-9B, offering enhanced code generation capabilities. It supports functions like code completion, code interpreter, web search, function call, and repository-level code Q&A. The model has competitive performance on benchmarks like BigCodeBench and NaturalCodeBench, outperforming larger models in terms of speed and performance.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

are-copilots-local-yet
Current trends and state of the art for using open & local LLM models as copilots to complete code, generate projects, act as shell assistants, automatically fix bugs, and more. This document is a curated list of local Copilots, shell assistants, and related projects, intended to be a resource for those interested in a survey of the existing tools and to help developers discover the state of the art for projects like these.
chatgpt
The ChatGPT R package provides a set of features to assist in R coding. It includes addins like Ask ChatGPT, Comment selected code, Complete selected code, Create unit tests, Create variable name, Document code, Explain selected code, Find issues in the selected code, Optimize selected code, and Refactor selected code. Users can interact with ChatGPT to get code suggestions, explanations, and optimizations. The package helps in improving coding efficiency and quality by providing AI-powered assistance within the RStudio environment.
minuet-ai.nvim
Minuet AI is a Neovim plugin that integrates with nvim-cmp to provide AI-powered code completion using multiple AI providers such as OpenAI, Claude, Gemini, Codestral, and Huggingface. It offers customizable configuration options and streaming support for completion delivery. Users can manually invoke completion or use cost-effective models for auto-completion. The plugin requires API keys for supported AI providers and allows customization of system prompts. Minuet AI also supports changing providers, toggling auto-completion, and provides solutions for input delay issues. Integration with lazyvim is possible, and future plans include implementing RAG on the codebase and virtual text UI support.
vim-ollama
The 'vim-ollama' plugin for Vim adds Copilot-like code completion support using Ollama as a backend, enabling intelligent AI-based code completion and integrated chat support for code reviews. It does not rely on cloud services, preserving user privacy. The plugin communicates with Ollama via Python scripts for code completion and interactive chat, supporting Vim only. Users can configure LLM models for code completion tasks and interactive conversations, with detailed installation and usage instructions provided in the README.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.