
openrl
Unified Reinforcement Learning Framework
Stars: 577

OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, offline RL, self-play, and natural language. Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable platform for the reinforcement learning research community. It supports a universal interface for all tasks/environments, single-agent and multi-agent tasks, offline RL training with expert dataset, self-play training, reinforcement learning training for natural language tasks, DeepSpeed, Arena for evaluation, importing models and datasets from Hugging Face, user-defined environments, models, and datasets, gymnasium environments, callbacks, visualization tools, unit testing, and code coverage testing. It also supports various algorithms like PPO, DQN, SAC, and environments like Gymnasium, MuJoCo, Atari, and more.
README:















OpenRL-v0.2.1 is updated on Dec 20, 2023
The main branch is the latest version of OpenRL, which is under active development. If you just want to have a try with OpenRL, you can switch to the stable branch.
Documentation | 中文介绍 | 中文文档
OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, offline RL, self-play, and natural language. Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable platform for the reinforcement learning research community.
Currently, the features supported by OpenRL include:
-
A simple-to-use universal interface that supports training for all tasks/environments
-
Support for both single-agent and multi-agent tasks
-
Support for offline RL training with expert dataset
-
Support self-play training
-
Reinforcement learning training support for natural language tasks (such as dialogue)
-
Support DeepSpeed
-
Support Arena , which allows convenient evaluation of various agents (even submissions for JiDi) in a competitive environment.
-
Importing models and datasets from Hugging Face. Supports loading Stable-baselines3 models from Hugging Face for testing and training.
-
Tutorial on how to integrate user-defined environments into OpenRL.
-
Support for models such as LSTM, GRU, Transformer etc.
-
Multiple training acceleration methods including automatic mixed precision training and data collecting wth half precision policy network
-
User-defined training models, reward models, training data and environment support
-
Support for gymnasium environments
-
Support for Callbacks, which can be used to implement various functions such as logging, saving, and early stopping
-
Dictionary observation space support
-
Popular visualization tools such as wandb, tensorboardX are supported
-
Serial or parallel environment training while ensuring consistent results in both modes
-
Chinese and English documentation
-
Provides unit testing and code coverage testing
-
Compliant with Black Code Style guidelines and type checking
Algorithms currently supported by OpenRL (for more details, please refer to Gallery):
- Proximal Policy Optimization (PPO)
- Dual-clip PPO
- Multi-agent PPO (MAPPO)
- Joint-ratio Policy Optimization (JRPO)
- Generative Adversarial Imitation Learning (GAIL)
- Behavior Cloning (BC)
- Advantage Actor-Critic (A2C)
- Self-Play
- Deep Q-Network (DQN)
- Multi-Agent Transformer (MAT)
- Value-Decomposition Network (VDN)
- Soft Actor Critic (SAC)
- Deep Deterministic Policy Gradient (DDPG)
Environments currently supported by OpenRL (for more details, please refer to Gallery):
- Gymnasium
- MuJoCo
- PettingZoo
- MPE
- Chat Bot
- Atari
- StarCraft II
- SMACv2
- Omniverse Isaac Gym
- DeepMind Control
- Snake
- gym-pybullet-drones
- EnvPool
- GridWorld
- Super Mario Bros
- Gym Retro
- Crafter
This framework has undergone multiple iterations by the OpenRL-Lab team which has applied it in academic research. It has now become a mature reinforcement learning framework.
OpenRL-Lab will continue to maintain and update OpenRL, and we welcome everyone to join our open-source community to contribute towards the development of reinforcement learning.
For more information about OpenRL, please refer to the documentation.
- Welcome to OpenRL
- Outline
- Why OpenRL?
- Installation
- Use Docker
- Quick Start
- Gallery
- Projects Using OpenRL
- Feedback and Contribution
- Maintainers
- Supporters
- Citing OpenRL
- License
- Acknowledgments
Here we provide a table for the comparison of OpenRL and existing popular RL libraries. OpenRL employs a modular design and high-level abstraction, allowing users to accomplish training for various tasks through a unified and user-friendly interface.
| Library | NLP/RLHF | Multi-agent | Self-Play Training | Offline RL | DeepSpeed |
|---|---|---|---|---|---|
| OpenRL | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Stable Baselines3 | ❌ | ❌ | ❌ | ❌ | ❌ |
| Ray/RLlib | ❌ | ✔️ | ✔️ | ✔️ | ❌ |
| DI-engine | ❌ | ✔️ | not fullly supported | ✔️ | ❌ |
| Tianshou | ❌ | not fullly supported | not fullly supported | ✔️ | ❌ |
| MARLlib | ❌ | ✔️ | not fullly supported | ❌ | ❌ |
| MAPPO Benchmark | ❌ | ✔️ | ❌ | ❌ | ❌ |
| RL4LMs | ✔️ | ❌ | ❌ | ❌ | ❌ |
| trlx | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| trl | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| TimeChamber | ❌ | ❌ | ✔️ | ❌ | ❌ |
Users can directly install OpenRL via pip:
pip install openrlIf users are using Anaconda or Miniconda, they can also install OpenRL via conda:
conda install -c openrl openrlUsers who want to modify the source code can also install OpenRL from the source code:
git clone https://github.com/OpenRL-Lab/openrl.git && cd openrl
pip install -e .After installation, users can check the version of OpenRL through command line:
openrl --versionTips: No installation required, try OpenRL online through
Colab:
OpenRL currently provides Docker images with and without GPU support. If the user's computer does not have an NVIDIA GPU, they can obtain an image without the GPU plugin using the following command:
sudo docker pull openrllab/openrl-cpuIf the user wants to accelerate training with a GPU, they can obtain it using the following command:
sudo docker pull openrllab/openrlAfter successfully pulling the image, users can run OpenRL's Docker image using the following commands:
# Without GPU acceleration
sudo docker run -it openrllab/openrl-cpu
# With GPU acceleration
sudo docker run -it --gpus all --net host openrllab/openrlOnce inside the Docker container, users can check OpenRL's version and then run test cases using these commands:
# Check OpenRL version in Docker container
openrl --version
# Run test case
openrl --mode train --env CartPole-v1 OpenRL provides a simple and easy-to-use interface for beginners in reinforcement learning.
Below is an example of using the PPO algorithm to train the CartPole environment:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
env = make("CartPole-v1", env_num=9) # Create an environment and set the environment parallelism to 9.
net = Net(env) # Create neural network.
agent = Agent(net) # Initialize the agent.
agent.train(
total_time_steps=20000) # Start training and set the total number of steps to 20,000 for the running environment.Training an agent using OpenRL only requires four simple steps: Create Environment => Initialize Model => Initialize Agent => Start Training!
For a well-trained agent, users can also easily test the agent:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
agent = Agent(Net(make("CartPole-v1", env_num=9))) # Initialize trainer.
agent.train(total_time_steps=20000)
# Create an environment for test, set the parallelism of the environment to 9, and set the rendering mode to group_human.
env = make("CartPole-v1", env_num=9, render_mode="group_human")
agent.set_env(env) # The agent requires an interactive environment.
obs, info = env.reset() # Initialize the environment to obtain initial observations and environmental information.
while True:
action, _ = agent.act(obs) # The agent predicts the next action based on environmental observations.
# The environment takes one step according to the action, obtains the next observation, reward, whether it ends and environmental information.
obs, r, done, info = env.step(action)
if any(done): break
env.close() # Close test environmentExecuting the above code on a regular laptop only takes a few seconds to complete the training. Below shows the visualization of the agent:

Tips: Users can also quickly train the CartPole environment by executing a command line in the terminal.
openrl --mode train --env CartPole-v1For training tasks such as multi-agent and natural language processing, OpenRL also provides a similarly simple and easy-to-use interface.
For information on how to perform multi-agent training, set hyperparameters for training, load training configurations, use wandb, save GIF animations, etc., please refer to:
For information on natural language task training, loading models/datasets on Hugging Face, customizing training models/reward models, etc., please refer to:
For more information about OpenRL, please refer to the documentation.
In order to facilitate users' familiarity with the framework, we provide more examples and demos of using OpenRL in Gallery. Users are also welcome to contribute their own training examples and demos to the Gallery.
We have listed research projects that use OpenRL in the OpenRL Project. If you are using OpenRL in your research project, you are also welcome to join this list.
- If you have any questions or find bugs, you can check or ask in the Issues.
- Join the QQ group: OpenRL Official Communication Group

- Join the slack group to discuss OpenRL usage and development with us.
- Join the Discord group to discuss OpenRL usage and development with us.
- Send an E-mail to: [email protected]
- Join the GitHub Discussion.
The OpenRL framework is still under continuous development and documentation. We welcome you to join us in making this project better:
- How to contribute code: Read the Contributors' Guide
- OpenRL Roadmap
At present, OpenRL is maintained by the following maintainers:
- Shiyu Huang(@huangshiyu13)
- Wenze Chen(@WentseChen)
- Yiwen Sun(@YiwenAI)
Welcome more contributors to join our maintenance team (send an E-mail to [email protected] to apply for joining the OpenRL team).
If our work has been helpful to you, please feel free to cite us:
@article{huang2023openrl,
title={OpenRL: A Unified Reinforcement Learning Framework},
author={Huang, Shiyu and Chen, Wentse and Sun, Yiwen and Bie, Fuqing and Tu, Wei-Wei},
journal={arXiv preprint arXiv:2312.16189},
year={2023}
}OpenRL under the Apache 2.0 license.
The development of the OpenRL framework has drawn on the strengths of other reinforcement learning frameworks:
- Stable-baselines3: https://github.com/DLR-RM/stable-baselines3
- pytorch-a2c-ppo-acktr-gail: https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail
- MAPPO: https://github.com/marlbenchmark/on-policy
- Gymnasium: https://github.com/Farama-Foundation/Gymnasium
- DI-engine: https://github.com/opendilab/DI-engine/
- Tianshou: https://github.com/thu-ml/tianshou
- RL4LMs: https://github.com/allenai/RL4LMs
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for openrl
Similar Open Source Tools
openrl
OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, offline RL, self-play, and natural language. Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable platform for the reinforcement learning research community. It supports a universal interface for all tasks/environments, single-agent and multi-agent tasks, offline RL training with expert dataset, self-play training, reinforcement learning training for natural language tasks, DeepSpeed, Arena for evaluation, importing models and datasets from Hugging Face, user-defined environments, models, and datasets, gymnasium environments, callbacks, visualization tools, unit testing, and code coverage testing. It also supports various algorithms like PPO, DQN, SAC, and environments like Gymnasium, MuJoCo, Atari, and more.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.

OmAgent
OmAgent is an open-source agent framework designed to streamline the development of on-device multimodal agents. It enables agents to empower various hardware devices, integrates speed-optimized SOTA multimodal models, provides SOTA multimodal agent algorithms, and focuses on optimizing the end-to-end computing pipeline for real-time user interaction experience. Key features include easy connection to diverse devices, scalability, flexibility, and workflow orchestration. The architecture emphasizes graph-based workflow orchestration, native multimodality, and device-centricity, allowing developers to create bespoke intelligent agent programs.

RD-Agent
RD-Agent is a tool designed to automate critical aspects of industrial R&D processes, focusing on data-driven scenarios to streamline model and data development. It aims to propose new ideas ('R') and implement them ('D') automatically, leading to solutions of significant industrial value. The tool supports scenarios like Automated Quantitative Trading, Data Mining Agent, Research Copilot, and more, with a framework to push the boundaries of research in data science. Users can create a Conda environment, install the RDAgent package from PyPI, configure GPT model, and run various applications for tasks like quantitative trading, model evolution, medical prediction, and more. The tool is intended to enhance R&D processes and boost productivity in industrial settings.
daydreams
Daydreams is a generative agent library designed for playing onchain games by injecting context. It is chain agnostic and allows users to perform onchain tasks, including playing any onchain game. The tool is lightweight and powerful, enabling users to define game context, register actions, set goals, monitor progress, and integrate with external agents. Daydreams aims to be 'lite' and 'composable', dynamically generating code needed to play games. It is currently in pre-alpha stage, seeking feedback and collaboration for further development.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
SynapseML
SynapseML (previously known as MMLSpark) is an open-source library that simplifies the creation of massively scalable machine learning (ML) pipelines. It provides simple, composable, and distributed APIs for various machine learning tasks such as text analytics, vision, anomaly detection, and more. Built on Apache Spark, SynapseML allows seamless integration of models into existing workflows. It supports training and evaluation on single-node, multi-node, and resizable clusters, enabling scalability without resource wastage. Compatible with Python, R, Scala, Java, and .NET, SynapseML abstracts over different data sources for easy experimentation. Requires Scala 2.12, Spark 3.4+, and Python 3.8+.
fAIr
fAIr is an open AI-assisted mapping service developed by the Humanitarian OpenStreetMap Team (HOT) to improve mapping efficiency and accuracy for humanitarian purposes. It uses AI models, specifically computer vision techniques, to detect objects like buildings, roads, waterways, and trees from satellite and UAV imagery. The service allows OSM community members to create and train their own AI models for mapping in their region of interest and ensures models are relevant to local communities. Constant feedback loop with local communities helps eliminate model biases and improve model accuracy.
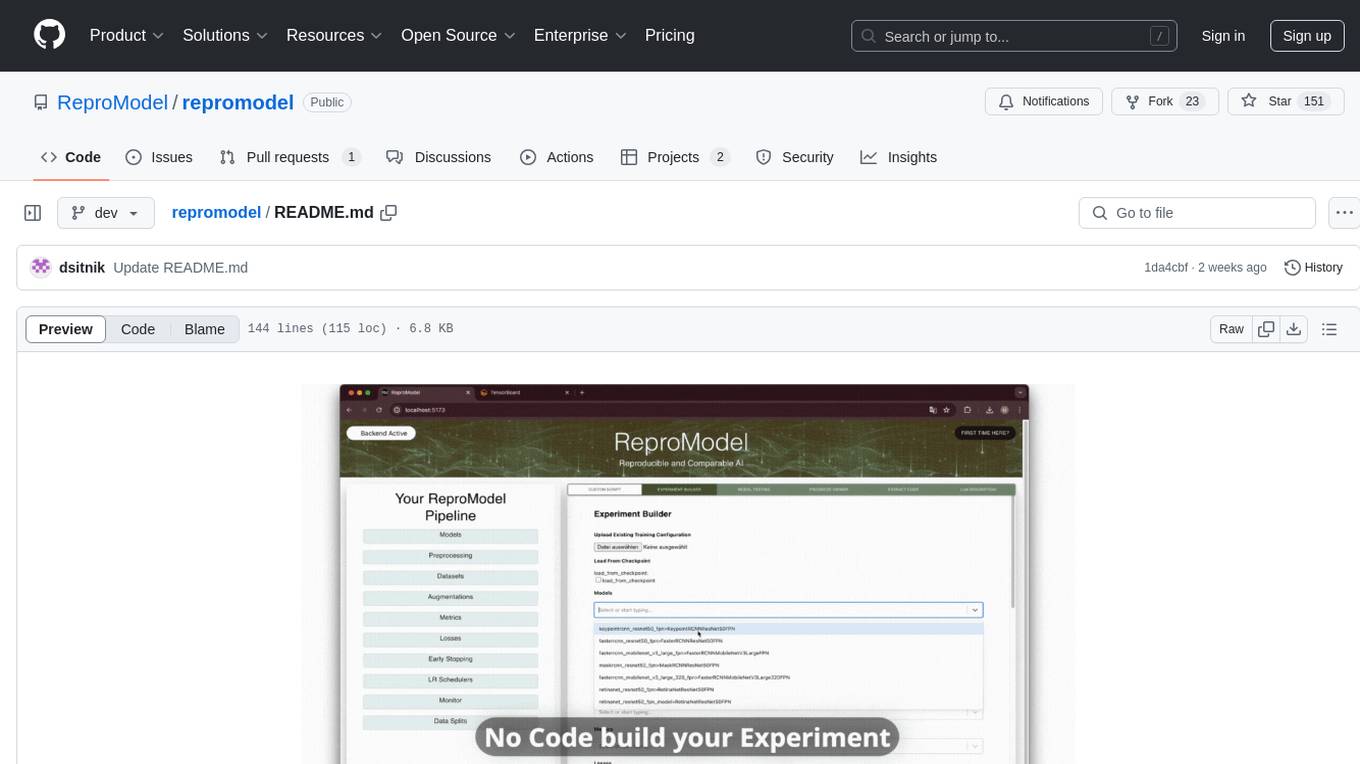
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
MLE-agent
MLE-Agent is an intelligent companion designed for machine learning engineers and researchers. It features autonomous baseline creation, integration with Arxiv and Papers with Code, smart debugging, file system organization, comprehensive tools integration, and an interactive CLI chat interface for seamless AI engineering and research workflows.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.

lobe-chat
Lobe Chat is an open-source, modern-design ChatGPT/LLMs UI/Framework. Supports speech-synthesis, multi-modal, and extensible ([function call][docs-functionc-call]) plugin system. One-click **FREE** deployment of your private OpenAI ChatGPT/Claude/Gemini/Groq/Ollama chat application.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
agentgateway
Agentgateway is an open source data plane optimized for agentic AI connectivity within or across any agent framework or environment. It provides drop-in security, observability, and governance for agent-to-agent and agent-to-tool communication, supporting leading interoperable protocols like Agent2Agent (A2A) and Model Context Protocol (MCP). Highly performant, security-first, multi-tenant, dynamic, and supporting legacy API transformation, agentgateway is designed to handle any scale and run anywhere with any agent framework.
For similar tasks
openrl
OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, offline RL, self-play, and natural language. Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable platform for the reinforcement learning research community. It supports a universal interface for all tasks/environments, single-agent and multi-agent tasks, offline RL training with expert dataset, self-play training, reinforcement learning training for natural language tasks, DeepSpeed, Arena for evaluation, importing models and datasets from Hugging Face, user-defined environments, models, and datasets, gymnasium environments, callbacks, visualization tools, unit testing, and code coverage testing. It also supports various algorithms like PPO, DQN, SAC, and environments like Gymnasium, MuJoCo, Atari, and more.
AgentGym
AgentGym is a framework designed to help the AI community evaluate and develop generally-capable Large Language Model-based agents. It features diverse interactive environments and tasks with real-time feedback and concurrency. The platform supports 14 environments across various domains like web navigating, text games, house-holding tasks, digital games, and more. AgentGym includes a trajectory set (AgentTraj) and a benchmark suite (AgentEval) to facilitate agent exploration and evaluation. The framework allows for agent self-evolution beyond existing data, showcasing comparable results to state-of-the-art models.
synthora
Synthora is a lightweight and extensible framework for LLM-driven Agents and ALM research. It aims to simplify the process of building, testing, and evaluating agents by providing essential components. The framework allows for easy agent assembly with a single config, reducing the effort required for tuning and sharing agents. Although in early development stages with unstable APIs, Synthora welcomes feedback and contributions to enhance its stability and functionality.
adk-java
Agent Development Kit (ADK) for Java is an open-source toolkit designed for developers to build, evaluate, and deploy sophisticated AI agents with flexibility and control. It allows defining agent behavior, orchestration, and tool use directly in code, enabling robust debugging, versioning, and deployment anywhere. The toolkit offers a rich tool ecosystem, code-first development approach, and support for modular multi-agent systems, making it ideal for creating advanced AI agents integrated with Google Cloud services.
Agentic-ADK
Agentic ADK is an Agent application development framework launched by Alibaba International AI Business, based on Google-ADK and Ali-LangEngine. It is used for developing, constructing, evaluating, and deploying powerful, flexible, and controllable complex AI Agents. ADK aims to make Agent development simpler and more user-friendly, enabling developers to more easily build, deploy, and orchestrate various Agent applications ranging from simple tasks to complex collaborations.
adk-docs
Agent Development Kit (ADK) is an open-source, code-first toolkit for building, evaluating, and deploying sophisticated AI agents with flexibility and control. It is a flexible and modular framework optimized for Gemini and the Google ecosystem, model-agnostic, deployment-agnostic, and compatible with other frameworks. ADK simplifies agent development by making it feel more like software development, enabling developers to create, deploy, and orchestrate agentic architectures from simple tasks to complex workflows.
adk-python
Agent Development Kit (ADK) is an open-source, code-first Python toolkit for building, evaluating, and deploying sophisticated AI agents with flexibility and control. It is a flexible and modular framework optimized for Gemini and the Google ecosystem, but also compatible with other frameworks. ADK aims to make agent development feel more like software development, enabling developers to create, deploy, and orchestrate agentic architectures ranging from simple tasks to complex workflows.

OpenSandbox
OpenSandbox is a general-purpose sandbox platform for AI applications, offering multi-language SDKs, unified sandbox APIs, and Docker/Kubernetes runtimes for scenarios like Coding Agents, GUI Agents, Agent Evaluation, AI Code Execution, and RL Training. It provides features such as multi-language SDKs, sandbox protocol, sandbox runtime, sandbox environments, and network policy. Users can perform basic sandbox operations like installing and configuring the sandbox server, starting the sandbox server, creating a code interpreter, and executing commands. The platform also offers examples for coding agent integrations, browser and desktop environments, and ML and training tasks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.