
starwhale
an MLOps/LLMOps platform
Stars: 196

Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
README:



![]()
![]()
![]()
![]()


English | 中文
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development liftcycle, enabling teams to optimize their workflows around key areas like model building, evaluation, release and fine-tuning.
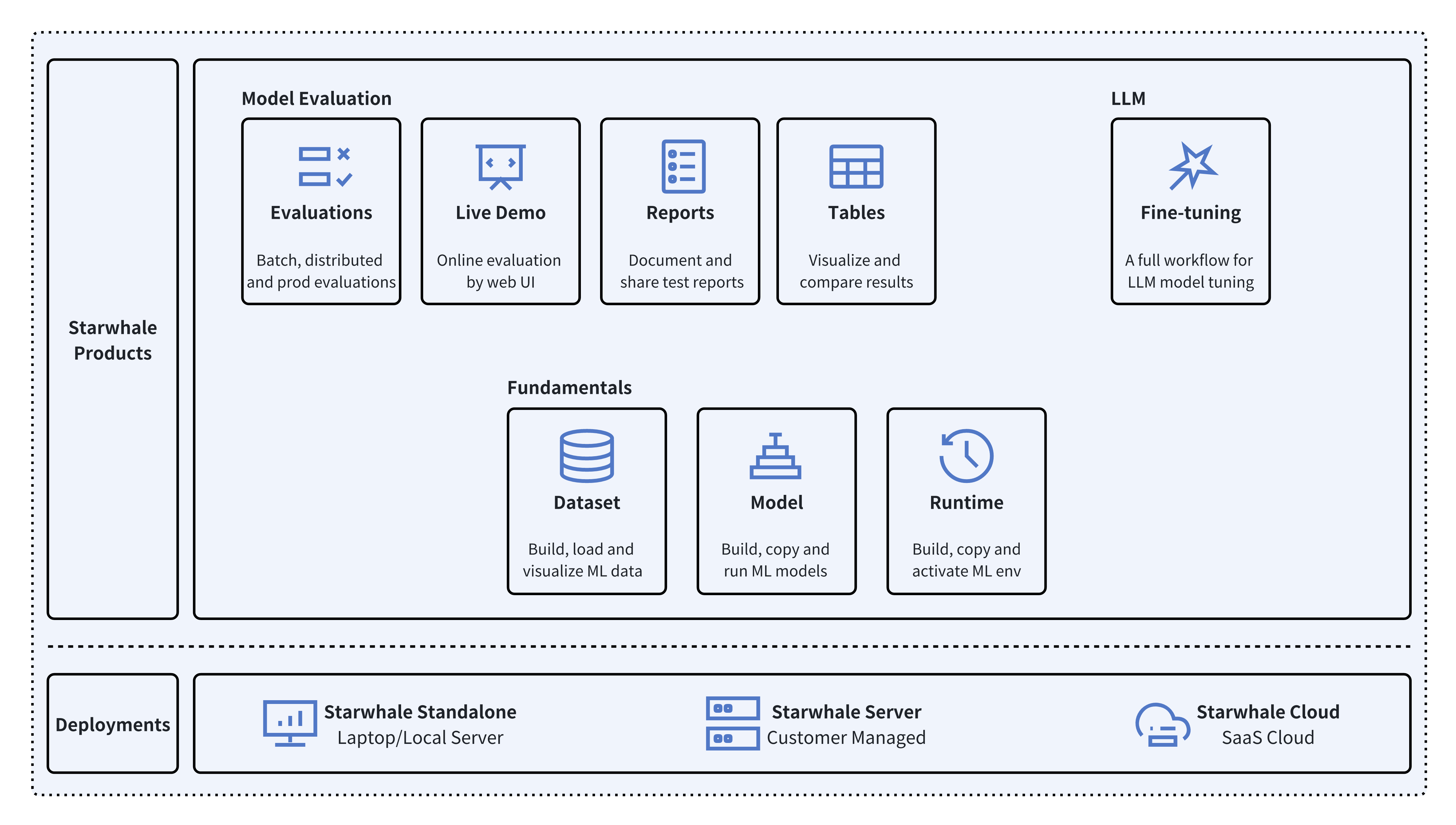
Starwhale meets diverse deployment needs with three flexible configurations:
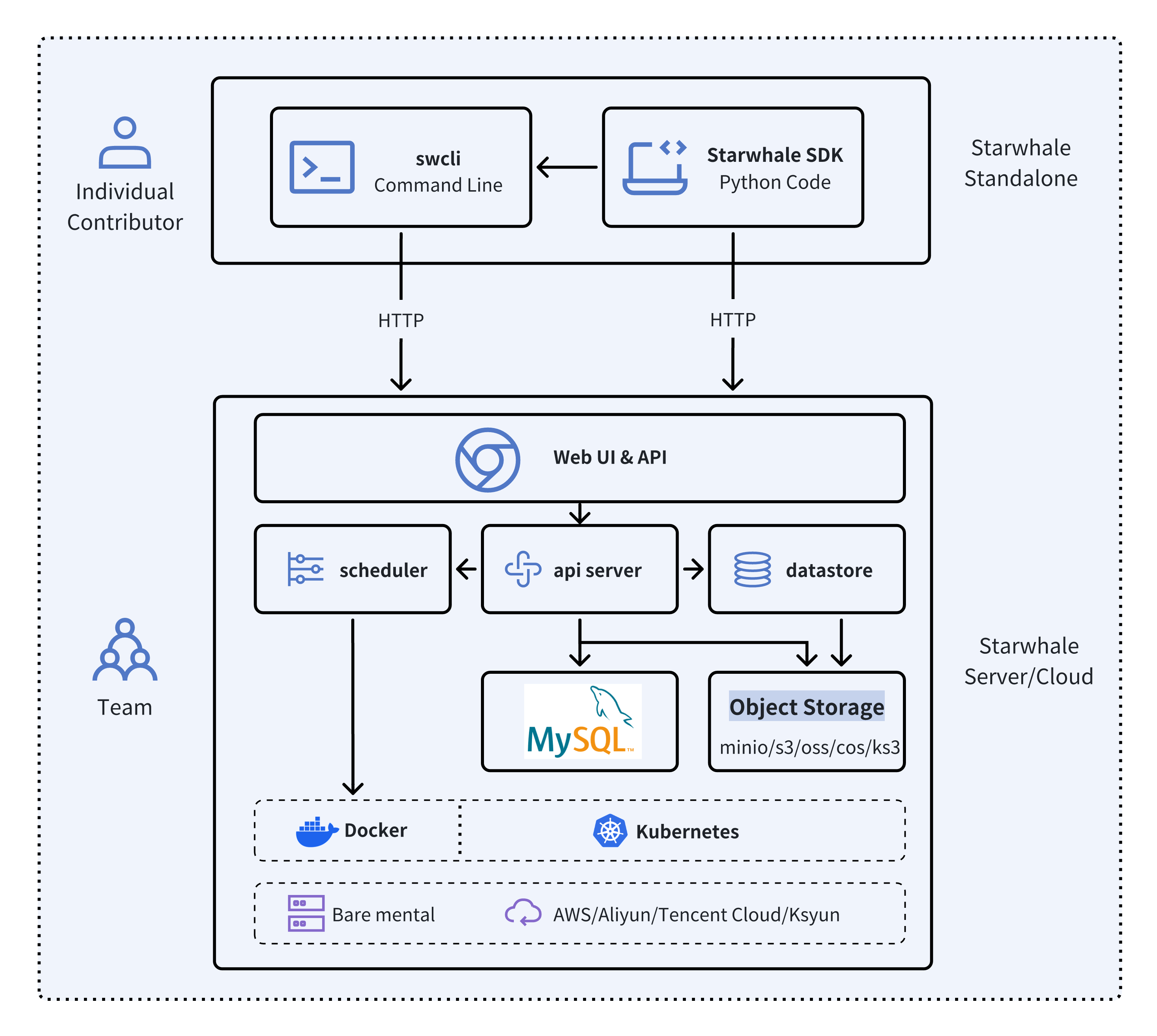
- 🐥 Standalone - Deployed in a local development environment, managed by the
swclicommand-line tool, meeting development and debugging needs. - 🦅 Server - Deployed in a private data center, relying on a Kubernetes cluster, providing centralized, web-based, and secure services.
- 🦉 Cloud - Hosted on a public cloud, with the access address https://cloud.starwhale.cn. The Starwhale team is responsible for maintenance, and no installation is required. You can start using it after registering an account.
As its core, Starwhale abstracts Model, Runtime and Dataset as first-class citizens - providing the fundamentals for streamlined operations. Starwhale further delivers tailored capabilities for common workflow scenarios including:
- 🔥 Models Evaluation - Implement robust, production-scale evaluations with minimal coding through the Python SDK.
- 🌟 Live Demo - Interactively assess model performance through user-friendly web interfaces.
- 🌊 LLM Fine-tuning - End-to-end toolchain from efficient fine-tuning to comparative benchmarking and publishing.
Starwhale is also an open source platform, using the Apache-2.0 license. The Starwhale framework is designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
Starwhale Dataset offers efficient data storage, loading, and visualization capabilities, making it a dedicated data management tool tailored for the field of machine learning and deep learning

import torch
from starwhale import dataset, Image
# build dataset for starwhale cloud instance
with dataset("https://cloud.starwhale.cn/project/starwhale:public/dataset/test-image", create="empty") as ds:
for i in range(100):
ds.append({"image": Image(f"{i}.png"), "label": i})
ds.commit()
# load dataset
ds = dataset("https://cloud.starwhale.cn/project/starwhale:public/dataset/test-image")
print(len(ds))
print(ds[0].features.image.to_pil())
print(ds[0].features.label)
torch_ds = ds.to_pytorch()
torch_loader = torch.utils.data.DataLoader(torch_ds, batch_size=5)
print(next(iter(torch_loader)))Starwhale Model is a standard format for packaging machine learning models that can be used for various purposes, like model fine-tuning, model evaluation, and online serving. A Starwhale Model contains the model file, inference codes, configuration files, and any other files required to run the model.

# model build
swcli model build . --module mnist.evaluate --runtime pytorch/version/v1 --name mnist
# model copy from standalone to cloud
swcli model cp mnist https://cloud.starwhale.cn/project/starwhale:public
# model run
swcli model run --uri mnist --runtime pytorch --dataset mnist
swcli model run --workdir . --module mnist.evaluator --handler mnist.evaluator:MNISTInference.cmpStarwhale Runtime aims to provide a reproducible and sharable running environment for python programs. You can easily share your working environment with your teammates or outsiders, and vice versa. Furthermore, you can run your programs on Starwhale Server or Starwhale Cloud without bothering with the dependencies.

# build from runtime.yaml, conda env, docker image or shell
swcli runtime build --yaml runtime.yaml
swcli runtime build --conda pytorch --name pytorch-runtime --cuda 11.4
swcli runtime build --docker pytorch/pytorch:1.9.0-cuda11.1-cudnn8-runtime
swcli runtime build --shell --name pytorch-runtime
# runtime activate
swcli runtime activate pytorch
# integrated with model and dataset
swcli model run --uri test --runtime pytorch
swcli model build . --runtime pytorch
swcli dataset build --runtime pytorchStarwhale Evaluation enables users to evaluate sophisticated, production-ready distributed models by writing just a few lines of code with Starwhale Python SDK.
import typing as t
import gradio
from starwhale import evaluation
from starwhale.api.service import api
def model_generate(image):
...
return predict_value, probability_matrix
@evaluation.predict(
resources={"nvidia.com/gpu": 1},
replicas=4,
)
def predict_image(data: dict, external: dict) -> None:
return model_generate(data["image"])
@evaluation.evaluate(use_predict_auto_log=True, needs=[predict_image])
def evaluate_results(predict_result_iter: t.Iterator):
for _data in predict_result_iter:
...
evaluation.log_summary({"accuracy": 0.95, "benchmark": "test"})
@api(gradio.File(), gradio.Label())
def predict_view(file: t.Any) -> t.Any:
with open(file.name, "rb") as f:
data = Image(f.read(), shape=(28, 28, 1))
_, prob = predict_image({"image": data})
return {i: p for i, p in enumerate(prob)}Starwhale Fine-tuning provides a full workflow for Large Language Model(LLM) tuning, including batch model evaluation, live demo and model release capabilities. Starwhale Fine-tuning Python SDK is very simple.
import typing as t
from starwhale import finetune, Dataset
from transformers import Trainer
@finetune(
resources={"nvidia.com/gpu":4, "memory": "32G"},
require_train_datasets=True,
require_validation_datasets=True,
model_modules=["evaluation", "finetune"],
)
def lora_finetune(train_datasets: t.List[Dataset], val_datasets: t.List[Dataset]) -> None:
# init model and tokenizer
trainer = Trainer(
model=model, tokenizer=tokenizer,
train_dataset=train_datasets[0].to_pytorch(), # convert Starwhale Dataset into Pytorch Dataset
eval_dataset=val_datasets[0].to_pytorch())
trainer.train()
trainer.save_state()
trainer.save_model()
# save weights, then Starwhale SDK will package them into Starwhale ModelRequirements: Python 3.7~3.11 in the Linux or macOS os.
python3 -m pip install starwhaleStarwhale Server is delivered as a Docker image, which can be run with Docker directly or deployed to a Kubernetes cluster. For the laptop environment, using swcli server start command is a appropriate choice that depends on Docker and Docker-Compose.
swcli server startWe use MNIST as the hello world example to show the basic Starwhale Model workflow.
- Use your own Python environment, follow the Standalone quickstart doc.
- Use Google Colab environment, follow the Jupyter notebook example.
- Run it in the your private Starwhale Server instance, please read Server installation(minikube) and Server quickstart docs.
- Run it in the Starwhale Cloud, please read Cloud quickstart doc.
-
🚀 LLM:
- 🐊 OpenSource LLMs Leaderboard: Evaluation, Code
- 🐢 Llama2: Run llama2 chat in five minutes, Code
- 🦎 Stable Diffusion: Cloud Demo, Code
- 🦙 LLAMA evaluation and fine-tune
- 🎹 Text-to-Music: Cloud Demo, Code
- 🍏 Code Generation: Cloud Demo, Code
-
🌋 Fine-tuning:
- 🐏 Baichuan2: Cloud Demo, Code
- 🐫 ChatGLM3: Cloud Demo, Code
- 🦏 Stable Diffusion: Cloud Demo, Code
-
🦦 Image Classification:
- 🐻❄️ MNIST: Cloud Demo, Code.
- 🦫 CIFAR10
- 🦓 Vision Transformer(ViT): Cloud Demo, Code
-
🐃 Image Segmentation:
- Segment Anything(SAM): Cloud Demo, Code
-
🐦 Object Detection:
- 🦊 YOLO: Cloud Demo, Code
- 🐯 Pedestrian Detection
-
📽️ Video Recognition: UCF101
-
🦋 Machine Translation: Neural machine translation
-
🐜 Text Classification: AG News
-
🎙️ Speech Recognition: Speech Command
-
Visit Starwhale HomePage.
-
More information in the official documentation.
-
For general questions and support, join the Slack.
-
For bug reports and feature requests, please use Github Issue.
-
To get community updates, follow @starwhaleai on Twitter.
-
For Starwhale artifacts, please visit:
- Python Package on Pypi.
- Helm Charts on Artifacthub.
- Docker Images on Docker Hub, Github Packages and Starwhale Registry.
-
Additionally, you can always find us at [email protected].
🌼👏PRs are always welcomed 👍🍺. See Contribution to Starwhale for more details.
Starwhale is licensed under the Apache License 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for starwhale
Similar Open Source Tools
starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
inferable
Inferable is an open source platform that helps users build reliable LLM-powered agentic automations at scale. It offers a managed agent runtime, durable tool calling, zero network configuration, multiple language support, and is fully open source under the MIT license. Users can define functions, register them with Inferable, and create runs that utilize these functions to automate tasks. The platform supports Node.js/TypeScript, Go, .NET, and React, and provides SDKs, core services, and bootstrap templates for various languages.
sophia
Sophia is an open-source TypeScript platform designed for autonomous AI agents and LLM based workflows. It aims to automate processes, review code, assist with refactorings, and support various integrations. The platform offers features like advanced autonomous agents, reasoning/planning inspired by Google's Self-Discover paper, memory and function call history, adaptive iterative planning, and more. Sophia supports multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It provides a flexible platform for the TypeScript community to expand and support various use cases and integrations.
typedai
TypedAI is a TypeScript-first AI platform designed for developers to create and run autonomous AI agents, LLM based workflows, and chatbots. It offers advanced autonomous agents, software developer agents, pull request code review agent, AI chat interface, Slack chatbot, and supports various LLM services. The platform features configurable Human-in-the-loop settings, functional callable tools/integrations, CLI and Web UI interface, and can be run locally or deployed on the cloud with multi-user/SSO support. It leverages the Python AI ecosystem through executing Python scripts/packages and provides flexible run/deploy options like single user mode, Firestore & Cloud Run deployment, and multi-user SSO enterprise deployment. TypedAI also includes UI examples, code examples, and automated LLM function schemas for seamless development and execution of AI workflows.
sdk-python
Strands Agents is a lightweight and flexible SDK that takes a model-driven approach to building and running AI agents. It supports various model providers, offers advanced capabilities like multi-agent systems and streaming support, and comes with built-in MCP server support. Users can easily create tools using Python decorators, integrate MCP servers seamlessly, and leverage multiple model providers for different AI tasks. The SDK is designed to scale from simple conversational assistants to complex autonomous workflows, making it suitable for a wide range of AI development needs.
llm-interface
LLM Interface is an npm module that streamlines interactions with various Large Language Model (LLM) providers in Node.js applications. It offers a unified interface for switching between providers and models, supporting 36 providers and hundreds of models. Features include chat completion, streaming, error handling, extensibility, response caching, retries, JSON output, and repair. The package relies on npm packages like axios, @google/generative-ai, dotenv, jsonrepair, and loglevel. Installation is done via npm, and usage involves sending prompts to LLM providers. Tests can be run using npm test. Contributions are welcome under the MIT License.

superlinked
Superlinked is a compute framework for information retrieval and feature engineering systems, focusing on converting complex data into vector embeddings for RAG, Search, RecSys, and Analytics stack integration. It enables custom model performance in machine learning with pre-trained model convenience. The tool allows users to build multimodal vectors, define weights at query time, and avoid postprocessing & rerank requirements. Users can explore the computational model through simple scripts and python notebooks, with a future release planned for production usage with built-in data infra and vector database integrations.
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.
zo2
ZO2 (Zeroth-Order Offloading) is an innovative framework designed to enhance the fine-tuning of large language models (LLMs) using zeroth-order (ZO) optimization techniques and advanced offloading technologies. It is tailored for setups with limited GPU memory, enabling the fine-tuning of models with over 175 billion parameters on single GPUs with as little as 18GB of memory. ZO2 optimizes CPU offloading, incorporates dynamic scheduling, and has the capability to handle very large models efficiently without extra time costs or accuracy losses.
vocode-python
Vocode is an open source library that enables users to easily build voice-based LLM (Large Language Model) apps. With Vocode, users can create real-time streaming conversations with LLMs and deploy them for phone calls, Zoom meetings, and more. The library offers abstractions and integrations for transcription services, LLMs, and synthesis services, making it a comprehensive tool for voice-based applications.
Mindolph
Mindolph is an open source personal knowledge management software for all desktop platforms. It allows users to create and manage their own files in separate workspaces with saving in their local storage, organize their files as a tree in their workspaces, and have multiple tabs for opening files instead of a single file window. Mindolph supports Mind Map, Markdown, PlantUML, CSV sheet, and plain text file formats. It also has features such as quickly navigating to files and searching text in files under a specific folder, editing mind maps easily and quickly with key shortcuts, supporting themes and providing some pre-defined themes, importing from other mind map formats, and exporting to other file formats.
rss-can
RSS Can is a tool designed to simplify and improve RSS feed management. It supports various systems and architectures, including Linux and macOS. Users can download the binary from the GitHub release page or use the Docker image for easy deployment. The tool provides CLI parameters and environment variables for customization. It offers features such as memory and Redis cache services, web service configuration, and rule directory settings. The project aims to support RSS pipeline flow, NLP tasks, integration with open-source software rules, and tools like a quick RSS rules generator.
bagofwords
Bag of words is an open-source AI platform that helps data teams deploy and manage chat-with-your-data agents in a controlled, reliable, and self-learning environment. It enables users to create charts, tables, and dashboards by chatting with their data, capture AI decisions and user feedback, automatically improve AI quality, integrate with various data sources and APIs, and ensure governance and integrations. The platform supports self-hosting in VPC via VMs, Docker/Compose, or Kubernetes, and offers additional integrations for AI Analyst in Slack, Excel, Google Sheets, and more. Users can start in minutes and scale to org-wide analytics.
catai
CatAI is a tool that allows users to run GGUF models on their computer with a chat UI. It serves as a local AI assistant inspired by Node-Llama-Cpp and Llama.cpp. The tool provides features such as auto-detecting programming language, showing original messages by clicking on user icons, real-time text streaming, and fast model downloads. Users can interact with the tool through a CLI that supports commands for installing, listing, setting, serving, updating, and removing models. CatAI is cross-platform and supports Windows, Linux, and Mac. It utilizes node-llama-cpp and offers a simple API for asking model questions. Additionally, developers can integrate the tool with node-llama-cpp@beta for model management and chatting. The configuration can be edited via the web UI, and contributions to the project are welcome. The tool is licensed under Llama.cpp's license.
Windows-Use
Windows-Use is a powerful automation agent that interacts directly with the Windows OS at the GUI layer. It bridges the gap between AI agents and Windows to perform tasks such as opening apps, clicking buttons, typing, executing shell commands, and capturing UI state without relying on traditional computer vision models. It enables any large language model (LLM) to perform computer automation instead of relying on specific models for it.
For similar tasks
starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.

RD-Agent
RD-Agent is a tool designed to automate critical aspects of industrial R&D processes, focusing on data-driven scenarios to streamline model and data development. It aims to propose new ideas ('R') and implement them ('D') automatically, leading to solutions of significant industrial value. The tool supports scenarios like Automated Quantitative Trading, Data Mining Agent, Research Copilot, and more, with a framework to push the boundaries of research in data science. Users can create a Conda environment, install the RDAgent package from PyPI, configure GPT model, and run various applications for tasks like quantitative trading, model evolution, medical prediction, and more. The tool is intended to enhance R&D processes and boost productivity in industrial settings.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.