
vocode-python
🤖 Build voice-based LLM agents. Modular + open source.
Stars: 2370
Vocode is an open source library that enables users to easily build voice-based LLM (Large Language Model) apps. With Vocode, users can create real-time streaming conversations with LLMs and deploy them for phone calls, Zoom meetings, and more. The library offers abstractions and integrations for transcription services, LLMs, and synthesis services, making it a comprehensive tool for voice-based applications.
README:




Vocode is an open source library that makes it easy to build voice-based LLM apps. Using Vocode, you can build real-time streaming conversations with LLMs and deploy them to phone calls, Zoom meetings, and more. You can also build personal assistants or apps like voice-based chess. Vocode provides easy abstractions and integrations so that everything you need is in a single library.
We're actively looking for community maintainers, so please reach out if interested!
- 🗣 Spin up a conversation with your system audio
- ➡️ 📞 Set up a phone number that responds with a LLM-based agent
- 📞 ➡️ Send out phone calls from your phone number managed by an LLM-based agent
- 🧑💻 Dial into a Zoom call
- 🤖 Use an outbound call to a real phone number in a Langchain agent
- Out of the box integrations with:
-
Transcription services, including:
-
LLMs, including:
-
Synthesis services, including:
-
Check out our React SDK here!
We're an open source project and are extremely open to contributors adding new features, integrations, and documentation! Please don't hesitate to reach out and get started building with us.
For more information on contributing, see our Contribution Guide.
And check out our Roadmap.
We'd love to talk to you on Discord about new ideas and contributing!
pip install 'vocode'import asyncio
import logging
import signal
from vocode.streaming.streaming_conversation import StreamingConversation
from vocode.helpers import create_streaming_microphone_input_and_speaker_output
from vocode.streaming.transcriber import *
from vocode.streaming.agent import *
from vocode.streaming.synthesizer import *
from vocode.streaming.models.transcriber import *
from vocode.streaming.models.agent import *
from vocode.streaming.models.synthesizer import *
from vocode.streaming.models.message import BaseMessage
import vocode
# these can also be set as environment variables
vocode.setenv(
OPENAI_API_KEY="<your OpenAI key>",
DEEPGRAM_API_KEY="<your Deepgram key>",
AZURE_SPEECH_KEY="<your Azure key>",
AZURE_SPEECH_REGION="<your Azure region>",
)
logging.basicConfig()
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
async def main():
(
microphone_input,
speaker_output,
) = create_streaming_microphone_input_and_speaker_output(
use_default_devices=False,
logger=logger,
use_blocking_speaker_output=True
)
conversation = StreamingConversation(
output_device=speaker_output,
transcriber=DeepgramTranscriber(
DeepgramTranscriberConfig.from_input_device(
microphone_input,
endpointing_config=PunctuationEndpointingConfig(),
)
),
agent=ChatGPTAgent(
ChatGPTAgentConfig(
initial_message=BaseMessage(text="What up"),
prompt_preamble="""The AI is having a pleasant conversation about life""",
)
),
synthesizer=AzureSynthesizer(
AzureSynthesizerConfig.from_output_device(speaker_output)
),
logger=logger,
)
await conversation.start()
print("Conversation started, press Ctrl+C to end")
signal.signal(
signal.SIGINT, lambda _0, _1: asyncio.create_task(conversation.terminate())
)
while conversation.is_active():
chunk = await microphone_input.get_audio()
conversation.receive_audio(chunk)
if __name__ == "__main__":
asyncio.run(main())For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for vocode-python
Similar Open Source Tools
vocode-python
Vocode is an open source library that enables users to easily build voice-based LLM (Large Language Model) apps. With Vocode, users can create real-time streaming conversations with LLMs and deploy them for phone calls, Zoom meetings, and more. The library offers abstractions and integrations for transcription services, LLMs, and synthesis services, making it a comprehensive tool for voice-based applications.
vocode-core
Vocode is an open source library that enables users to build voice-based LLM (Large Language Model) applications quickly and easily. With Vocode, users can create real-time streaming conversations with LLMs and deploy them for phone calls, Zoom meetings, and more. The library offers abstractions and integrations for transcription services, LLMs, and synthesis services, making it a comprehensive tool for voice-based app development. Vocode also provides out-of-the-box integrations with various services like AssemblyAI, OpenAI, Microsoft Azure, and more, allowing users to leverage these services seamlessly in their applications.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.
unify
The Unify Python Package provides access to the Unify REST API, allowing users to query Large Language Models (LLMs) from any Python 3.7.1+ application. It includes Synchronous and Asynchronous clients with Streaming responses support. Users can easily use any endpoint with a single key, route to the best endpoint for optimal throughput, cost, or latency, and customize prompts to interact with the models. The package also supports dynamic routing to automatically direct requests to the top-performing provider. Additionally, users can enable streaming responses and interact with the models asynchronously for handling multiple user requests simultaneously.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

GPTSwarm
GPTSwarm is a graph-based framework for LLM-based agents that enables the creation of LLM-based agents from graphs and facilitates the customized and automatic self-organization of agent swarms with self-improvement capabilities. The library includes components for domain-specific operations, graph-related functions, LLM backend selection, memory management, and optimization algorithms to enhance agent performance and swarm efficiency. Users can quickly run predefined swarms or utilize tools like the file analyzer. GPTSwarm supports local LM inference via LM Studio, allowing users to run with a local LLM model. The framework has been accepted by ICML2024 and offers advanced features for experimentation and customization.
Kori
Kori is a unified note-taking app with AI capabilities, providing a consistent experience across Android, iOS, Windows, macOS, and Linux. It supports various formats like Drawing, Markdown, TXT, LaTeX, Mermaid diagrams, and Todo.txt lists. Users can benefit from AI co-writing features, note outline generation, find and replace, note templates, local media support, and export options. The app follows Material Design 3 guidelines, offers comprehensive mouse and keyboard support, and is optimized for different screen sizes and orientations.
mobius
Mobius is an AI infra platform including realtime computing and training. It is built on Ray, a distributed computing framework, and provides a number of features that make it well-suited for online machine learning tasks. These features include: * **Cross Language**: Mobius can run in multiple languages (only Python and Java are supported currently) with high efficiency. You can implement your operator in different languages and run them in one job. * **Single Node Failover**: Mobius has a special failover mechanism that only needs to rollback the failed node itself, in most cases, to recover the job. This is a huge benefit if your job is sensitive about failure recovery time. * **AutoScaling**: Mobius can generate a new graph with different configurations in runtime without stopping the job. * **Fusion Training**: Mobius can combine TensorFlow/Pytorch and streaming, then building an e2e online machine learning pipeline. Mobius is still under development, but it has already been used to power a number of real-world applications, including: * A real-time recommendation system for a major e-commerce company * A fraud detection system for a large financial institution * A personalized news feed for a major news organization If you are interested in using Mobius for your own online machine learning projects, you can find more information in the documentation.
bee-agent-framework
The Bee Agent Framework is an open-source tool for building, deploying, and serving powerful agentic workflows at scale. It provides AI agents, tools for creating workflows in Javascript/Python, a code interpreter, memory optimization strategies, serialization for pausing/resuming workflows, traceability features, production-level control, and upcoming features like model-agnostic support and a chat UI. The framework offers various modules for agents, llms, memory, tools, caching, errors, adapters, logging, serialization, and more, with a roadmap including MLFlow integration, JSON support, structured outputs, chat client, base agent improvements, guardrails, and evaluation.
mem0
Mem0 is a tool that provides a smart, self-improving memory layer for Large Language Models, enabling personalized AI experiences across applications. It offers persistent memory for users, sessions, and agents, self-improving personalization, a simple API for easy integration, and cross-platform consistency. Users can store memories, retrieve memories, search for related memories, update memories, get the history of a memory, and delete memories using Mem0. It is designed to enhance AI experiences by enabling long-term memory storage and retrieval.
esp-ai
ESP-AI provides a complete AI conversation solution for your development board, including IAT+LLM+TTS integration solutions for ESP32 series development boards. It can be injected into projects without affecting existing ones. By providing keys from platforms like iFlytek, Jiling, and local services, you can run the services without worrying about interactions between services or between development boards and services. The project's server-side code is based on Node.js, and the hardware code is based on Arduino IDE.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
deepchecks
Deepchecks is a holistic open-source solution for AI & ML validation needs, enabling thorough testing of data and models from research to production. It includes components for testing, CI & testing management, and monitoring. Users can install and use Deepchecks for testing and monitoring their AI models, with customizable checks and suites for tabular, NLP, and computer vision data. The tool provides visual reports, pythonic/json output for processing, and a dynamic UI for collaboration and monitoring. Deepchecks is open source, with premium features available under a commercial license for monitoring components.
MarkFlowy
MarkFlowy is a lightweight and feature-rich Markdown editor with built-in AI capabilities. It supports one-click export of conversations, translation of articles, and obtaining article abstracts. Users can leverage large AI models like DeepSeek and Chatgpt as intelligent assistants. The editor provides high availability with multiple editing modes and custom themes. Available for Linux, macOS, and Windows, MarkFlowy aims to offer an efficient, beautiful, and data-safe Markdown editing experience for users.
agentica
Agentica is a specialized Agentic AI library focused on LLM Function Calling. Users can provide Swagger/OpenAPI documents or TypeScript class types to Agentica for seamless functionality. The library simplifies AI development by handling various tasks effortlessly.
superagentx
SuperAgentX is a lightweight open-source AI framework designed for multi-agent applications with Artificial General Intelligence (AGI) capabilities. It offers goal-oriented multi-agents with retry mechanisms, easy deployment through WebSocket, RESTful API, and IO console interfaces, streamlined architecture with no major dependencies, contextual memory using SQL + Vector databases, flexible LLM configuration supporting various Gen AI models, and extendable handlers for integration with diverse APIs and data sources. It aims to accelerate the development of AGI by providing a powerful platform for building autonomous AI agents capable of executing complex tasks with minimal human intervention.
For similar tasks
vocode-python
Vocode is an open source library that enables users to easily build voice-based LLM (Large Language Model) apps. With Vocode, users can create real-time streaming conversations with LLMs and deploy them for phone calls, Zoom meetings, and more. The library offers abstractions and integrations for transcription services, LLMs, and synthesis services, making it a comprehensive tool for voice-based applications.
Awesome-Audio-LLM
Awesome-Audio-LLM is a repository dedicated to various models and methods related to audio and language processing. It includes a wide range of research papers and models developed by different institutions and authors. The repository covers topics such as bridging audio and language, speech emotion recognition, voice assistants, and more. It serves as a comprehensive resource for those interested in the intersection of audio and language processing.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

deepgram-js-sdk
Deepgram JavaScript SDK. Power your apps with world-class speech and Language AI models.
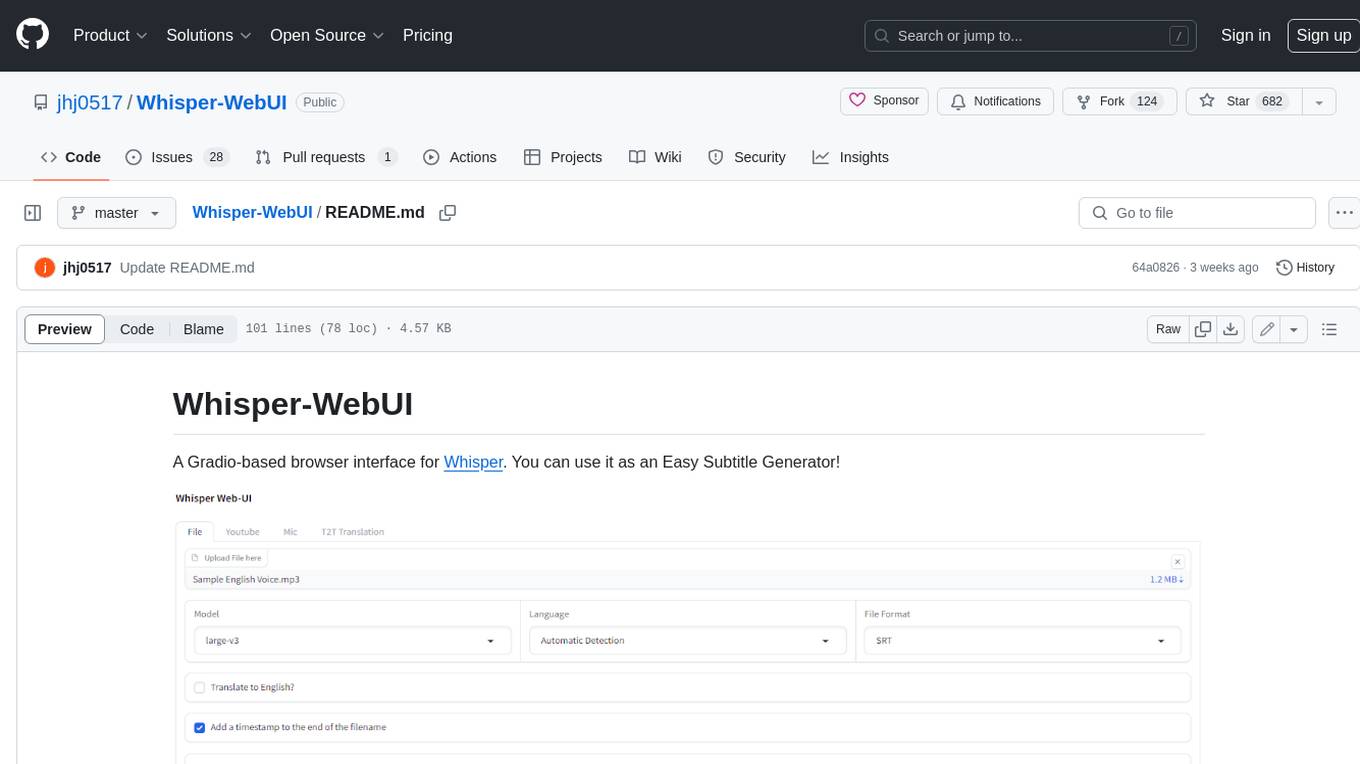
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.