Best AI tools for< Build Datasets >
20 - AI tool Sites
Edge Impulse
Edge Impulse is a leading edge AI platform that enables users to build datasets, train models, and optimize libraries to run directly on any edge device. It offers sensor datasets, feature engineering, model optimization, algorithms, and NVIDIA integrations. The platform is designed for product leaders, AI practitioners, embedded engineers, and OEMs across various industries and applications. Edge Impulse helps users unlock sensor data value, build high-quality sensor datasets, advance algorithm development, optimize edge AI models, and achieve measurable results. It allows for future-proofing workflows by generating models and algorithms that perform efficiently on any edge hardware.

UseScraper
UseScraper is a web crawler and scraper API that allows users to extract data from websites for research, analysis, and AI applications. It offers features such as full browser rendering, markdown conversion, and automatic proxies to prevent rate limiting. UseScraper is designed to be fast, easy to use, and cost-effective, with plans starting at $0 per month.
Surge AI
Surge AI is a data labeling platform that provides human-generated data for training and evaluating large language models (LLMs). It offers a global workforce of annotators who can label data in over 40 languages. Surge AI's platform is designed to be easy to use and integrates with popular machine learning tools and frameworks. The company's customers include leading AI companies, research labs, and startups.

Sapien.io
Sapien.io is a decentralized data foundry that offers data labeling services powered by a decentralized workforce and gamified platform. The platform provides high-quality training data for large language models through a human-in-the-loop labeling process, enabling fine-tuning of datasets to build performant AI models. Sapien combines AI and human intelligence to collect and annotate various data types for any model, offering customized data collection and labeling models across industries.
Voxel51
Voxel51 is an AI tool that provides open-source computer vision tools for machine learning. It offers solutions for various industries such as agriculture, aviation, driving, healthcare, manufacturing, retail, robotics, and security. Voxel51's main product, FiftyOne, helps users explore, visualize, and curate visual data to improve model performance and accelerate the development of visual AI applications. The platform is trusted by thousands of users and companies, offering both open-source and enterprise-ready solutions to manage and refine data and models for visual AI.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
AI Alliance
The AI Alliance is a community dedicated to building and advancing open-source AI agents, data, models, evaluation, safety, applications, and advocacy to ensure everyone can benefit. They focus on various areas such as skills and education, trust and safety, applications and tools, hardware enablement, foundation models, and advocacy. The organization supports global AI skill-building, education, and exploratory research, creates benchmarks and tools for safe generative AI, builds capable tools for AI model builders and developers, fosters AI hardware accelerator ecosystem, enables open foundation models and datasets, and advocates for regulatory policies for healthy AI ecosystems.
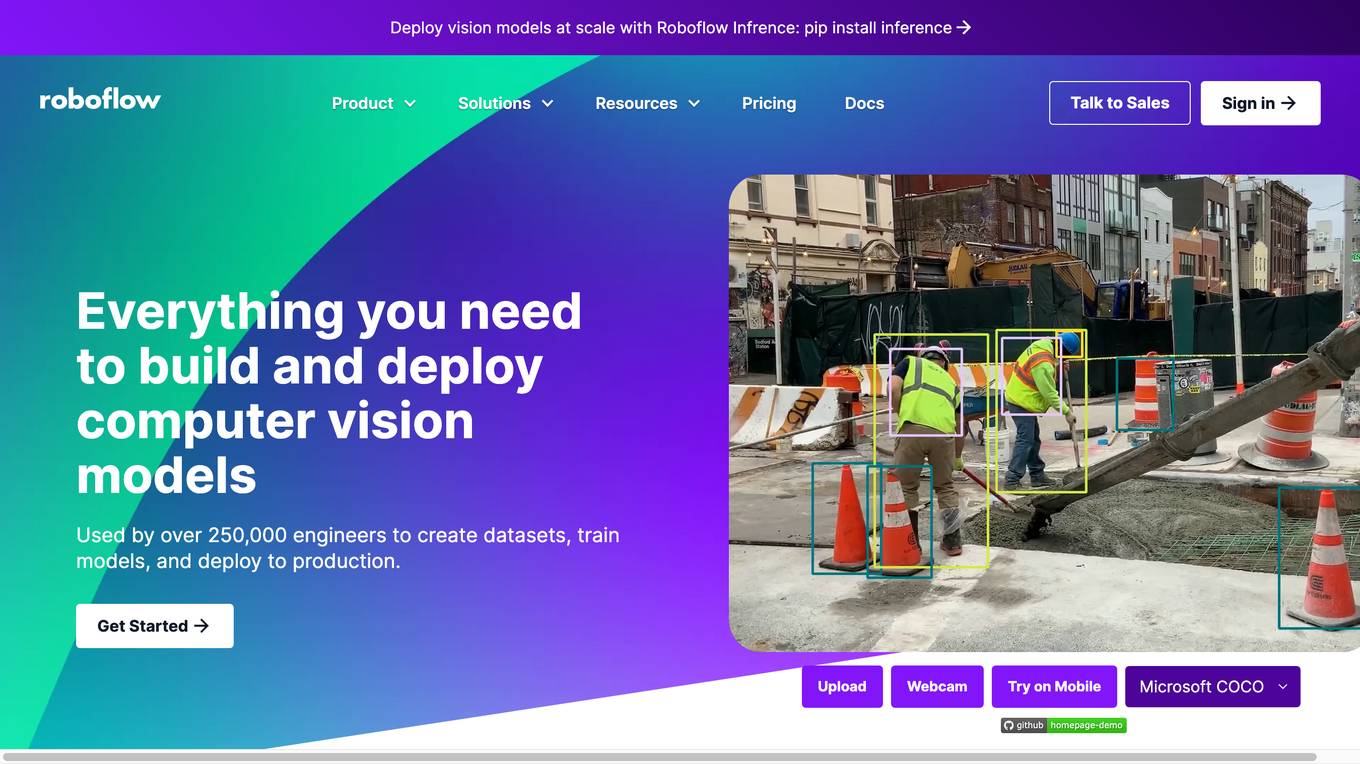
Roboflow
Roboflow is a platform that provides tools for building and deploying computer vision models. It offers a range of features, including data annotation, model training, and deployment. Roboflow is used by over 250,000 engineers to create datasets, train models, and deploy to production.
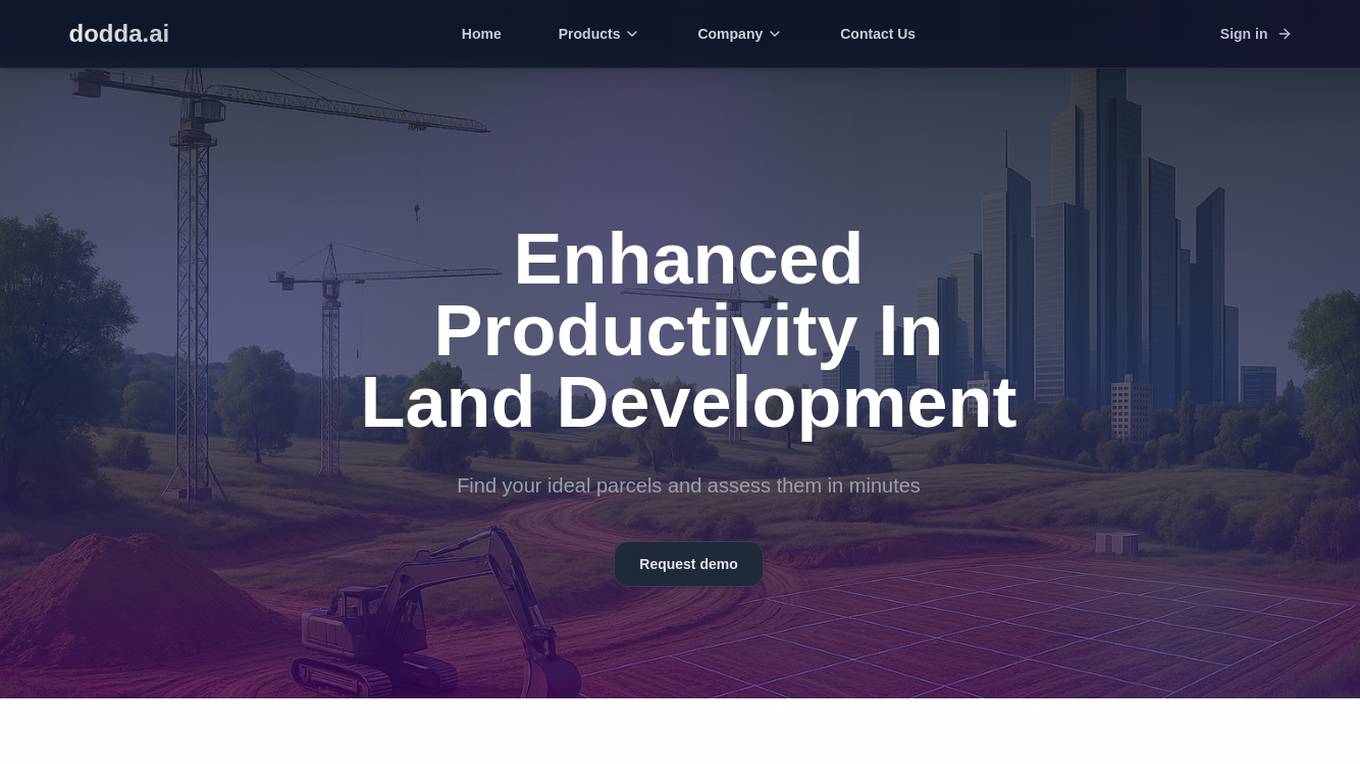
Dodda AI
Dodda AI (dodda.ai) is an AI application that automates site feasibility for Real Estate professionals, enabling quick decision-making by analyzing parcels in minutes. It offers a controlled environment focused on data accuracy, reliability, and scalability through a proprietary Land Use AI Model. Users can save up to 75% of their time compared to traditional methods, with features like instant ADU eligibility analysis, precise parking requirements calculation, feasibility determination, development options exploration, setback measurements, and more. The application is designed to enhance productivity in land development projects, providing verified results and unlocking opportunities with proprietary datasets.
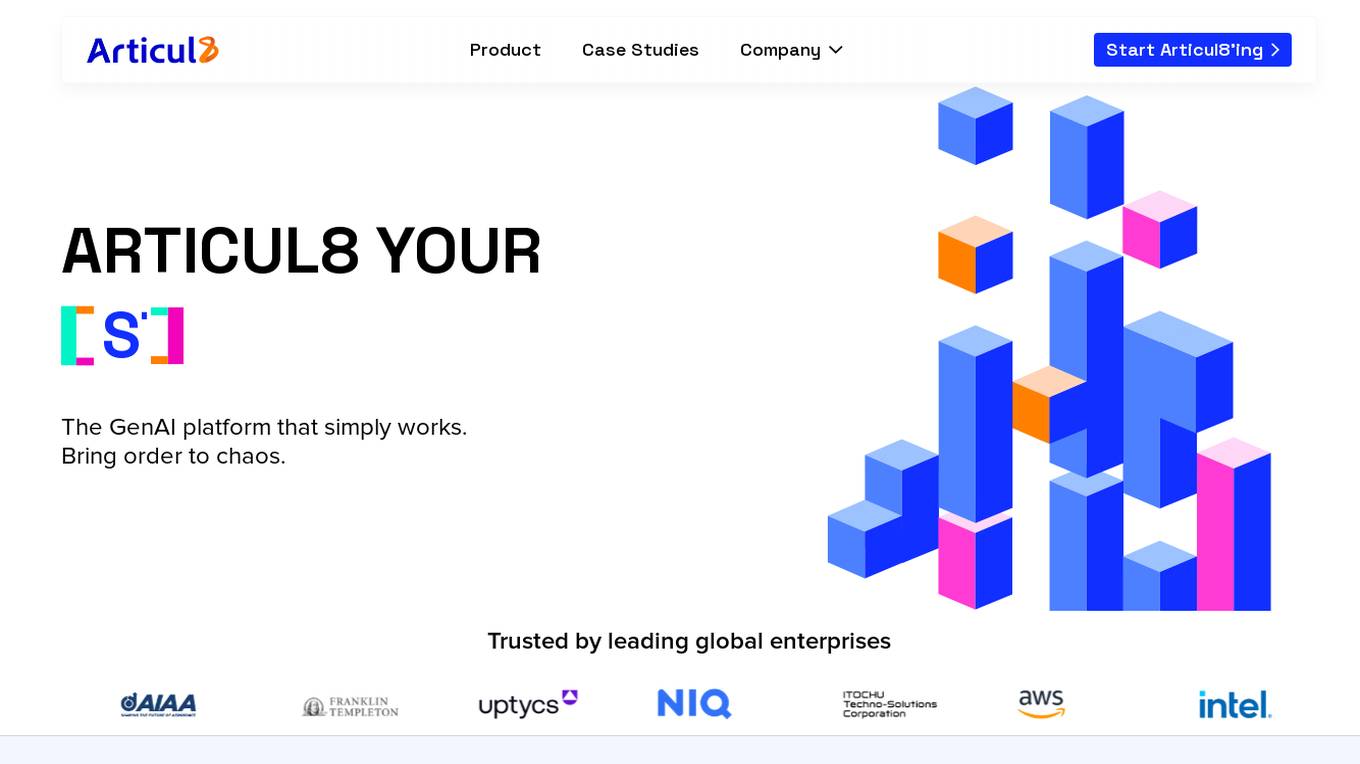
Articul8
Articul8 is a GenAI platform designed to bring order to chaos by enabling users to build sophisticated enterprise applications using their expertise. It offers features such as autonomous decision-making, automated data intelligence, and a library of specialized models. The platform aims to provide faster time to ROI, improved accuracy, and precision, along with rich semantic understanding of data. Articul8 is engineered for regulated industries and offers observability, traceability, and auditability at every step.

Mozilla.ai Lumigator Blueprints
Mozilla.ai Lumigator Blueprints is a developer-first hub for open-source AI workflows. It provides a platform for exploring and customizing AI blueprints, such as building timeline algorithms, fine-tuning models, and mapping features using computer vision. The site aims to empower users to create personalized AI solutions tailored to their specific needs and preferences.
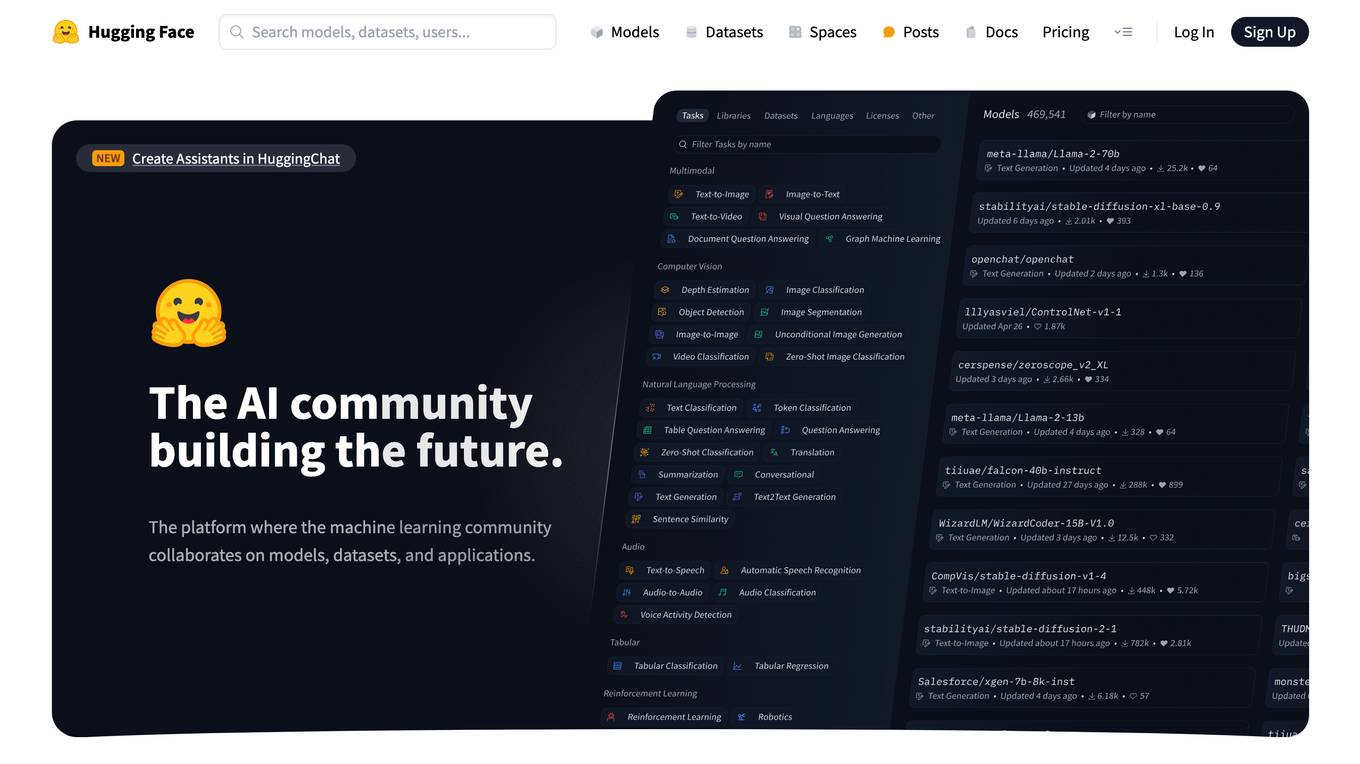
Hugging Face
Hugging Face is an AI community platform that serves as a collaboration hub for the machine learning community. It allows users to explore and contribute to models, datasets, and applications. The platform offers a wide range of features and tools to facilitate AI development and research.

3DFY.ai
3DFY.ai is a generative AI platform that enables users to create high-quality 3D models from text descriptions. The platform is designed to be accessible to both individual creators and businesses, and it offers a range of services including a text-to-3D web service, an API for enterprise integrations, and a massive 3D dataset generation service. 3DFY.ai's technology is based on a proprietary AI-powered 3D generation pipeline that produces models adhering to high quality standards. The platform is designed to be scalable and efficient, and it can be used to create a wide range of 3D models for a variety of applications.
Altamira
Altamira is an AI-driven software development company that offers a wide range of services including software discovery, ideation, audit, consulting, and development. They specialize in AI feasibility studies, AI development, dataOps pipelines, and pre-built AI/ML models. Altamira focuses on providing holistic care for digital solutions, with expertise in various industries such as fintech, retail, healthcare, and more. They aim to optimize software development processes for established businesses, startups, and spinoffs by offering tailored solutions that make a tangible impact on growth and productivity.
V7
V7 is an AI data engine for computer vision and generative AI. It provides a multimodal automation tool that helps users label data 10x faster, power AI products via API, build AI + human workflows, and reach 99% AI accuracy. V7's platform includes features such as automated annotation, DICOM annotation, dataset management, model management, image annotation, video annotation, document processing, and labeling services.

LAION
LAION is a non-profit organization that provides datasets, tools, and models to advance machine learning research. The organization's goal is to promote open public education and encourage the reuse of existing datasets and models to reduce the environmental impact of machine learning research.

Neural Network Playground
The website offers interactive tutorials on neural networks and deep learning, providing a comprehensive platform for mastering neural networks in an intuitive, natural, and cohesive manner. Users can access a visualized neural network lab with simplified datasets, a variety of 2D and 3D datasets for regression and classification, and interactive missions to deepen understanding. The platform also features intuitive tutorials, well-visualized neural network knowledge with charts and animations, and a visual deep learning model editor for efficient model building. Overall, it aims to enhance learning and understanding of neural networks through interactive and visual tools.
nventr
nventr is an AI platform for predictive automation, offering a suite of products and services powered by predictive analytics. The company focuses on applying new approaches to uncover patterns, extract valuable intelligence, and predict outcomes within vast datasets. nventr solutions support enterprise-grade AI acceleration, intelligent data processing, and digital transformation. The platform, nventr.ai, enables rapid building of AI models and software applications through collaborative tools and cloud-based infrastructure.
Appen
Appen is a leading provider of high-quality data for training AI models. The company's end-to-end platform, flexible services, and deep expertise ensure the delivery of high-quality, diverse data that is crucial for building foundation models and enterprise-ready AI applications. Appen has been providing high-quality datasets that power the world's leading AI models for decades. The company's services enable it to prepare data at scale, meeting the demands of even the most ambitious AI projects. Appen also provides enterprises with software to collect, curate, fine-tune, and monitor traditionally human-driven tasks, creating massive efficiencies through a trustworthy, traceable process.
Monkt
Monkt is a powerful document processing platform that transforms various document formats into AI-ready Markdown or structured JSON. It offers features like instant conversion of PDF, Word, PowerPoint, Excel, CSV, web pages, and raw HTML into clean markdown format optimized for AI/LLM systems. Monkt enables users to create intelligent applications, custom AI chatbots, knowledge bases, and training datasets. It supports batch processing, image understanding, LLM optimization, and API integration for seamless document processing. The platform is designed to handle document transformation at scale, with support for multiple file formats and custom JSON schemas.
4 - Open Source AI Tools

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.

RD-Agent
RD-Agent is a tool designed to automate critical aspects of industrial R&D processes, focusing on data-driven scenarios to streamline model and data development. It aims to propose new ideas ('R') and implement them ('D') automatically, leading to solutions of significant industrial value. The tool supports scenarios like Automated Quantitative Trading, Data Mining Agent, Research Copilot, and more, with a framework to push the boundaries of research in data science. Users can create a Conda environment, install the RDAgent package from PyPI, configure GPT model, and run various applications for tasks like quantitative trading, model evolution, medical prediction, and more. The tool is intended to enhance R&D processes and boost productivity in industrial settings.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.
20 - OpenAI Gpts

ResourceFinder
Assists in identifying and utilizing APIs and files effectively to enhance user-designed GPTs.
Dr. Classify
Just upload a numerical dataset for classification task, will apply data analysis and machine learning steps to make a best model possible.
![VitalsGPT [V0.0.2.2] Screenshot](/screenshots_gpts/g-cL1rJdm11.jpg)
VitalsGPT [V0.0.2.2]
Simple CustomGPT built on Vitals Inquiry Case in Malta, aimed to help journalists and citizens navigate the inquiry's large dataset in a neutral, informative fashion. Always cross-reference replies to actual data. Do not rely solely on this LLM for verification of facts.



Build a Brand
Unique custom images based on your input. Just type ideas and the brand image is created.
Beam Eye Tracker Extension Copilot
Build extensions using the Eyeware Beam eye tracking SDK


Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model

League Champion Builder GPT
Build your own League of Legends Style Champion with Abilities, Back Story and Splash Art
RenovaTecno
Your tech buddy helping you refurbish or build a PC from scratch, tailored to your needs, budget, and language.

Gradle Expert
Your expert in Gradle build configuration, offering clear, practical advice.

