
chronos-forecasting
Chronos: Pretrained Models for Time Series Forecasting
Stars: 4818
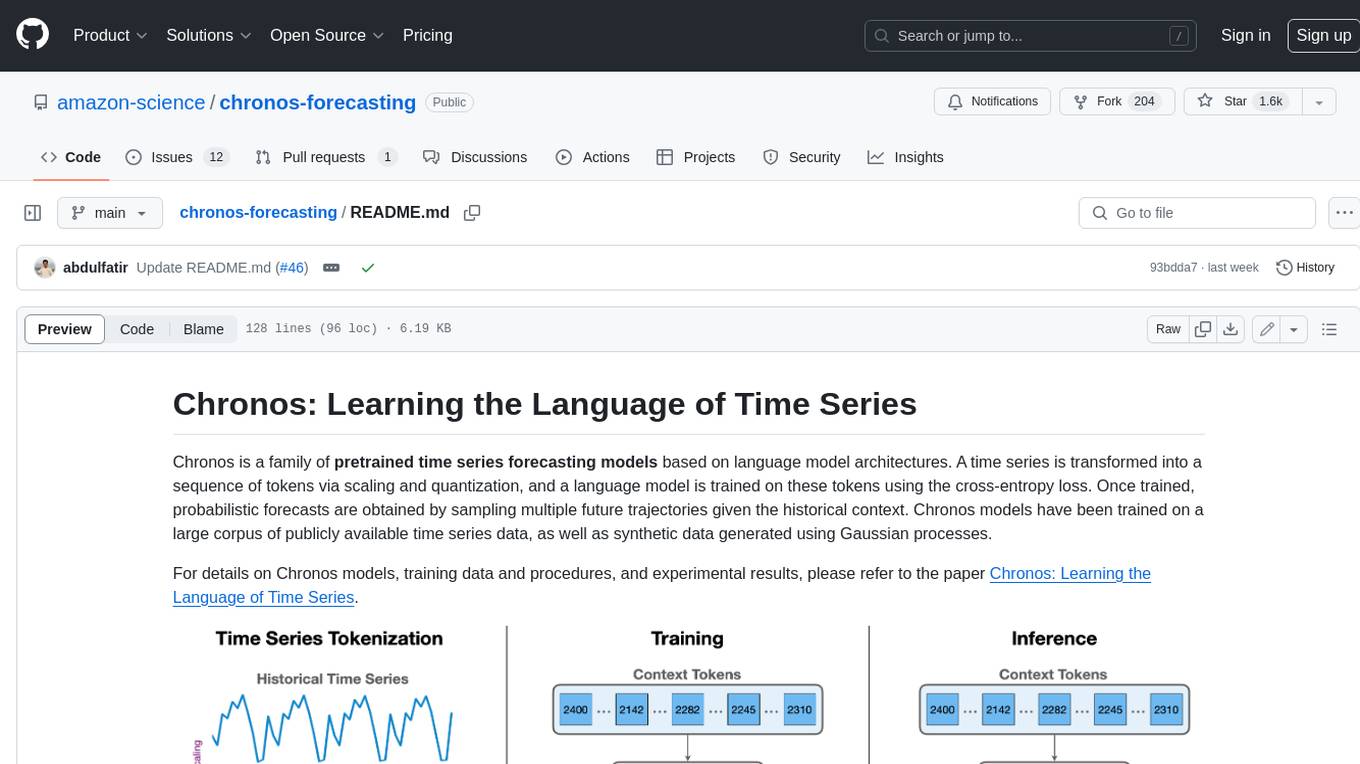
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.
README:




- 30 Dec 2025: ☁️ Deploy Chronos-2 to AWS with Amazon SageMaker: new guide covers real-time inference (GPU/CPU), serverless endpoints with automatic scaling, and batch transform for large-scale forecasting. See the deployment tutorial.
- 20 Oct 2025: 🚀 Chronos-2 released. It offers zero-shot support for univariate, multivariate, and covariate-informed forecasting tasks. Chronos-2 achieves the best performance on fev-bench, GIFT-Eval and Chronos Benchmark II amongst pretrained models. Check out this notebook to get started with Chronos-2.
-
12 Dec 2024: 📊 We released
fev, a lightweight package for benchmarking time series forecasting models based on the Hugging Facedatasetslibrary. - 26 Nov 2024: ⚡️ Chronos-Bolt models released on HuggingFace. Chronos-Bolt models are more accurate (5% lower error), up to 250x faster and 20x more memory efficient than the original Chronos models of the same size!
- 13 Mar 2024: 🚀 Chronos paper and inference code released.
This package provides an interface to the Chronos family of pretrained time series forecasting models. The following model types are supported.
- Chronos-2: Our latest model with significantly enhanced capabilities. It offers zero-shot support for univariate, multivariate, and covariate-informed forecasting tasks. Chronos-2 delivers state-of-the-art zero-shot performance across multiple benchmarks (including fev-bench and GIFT-Eval), with the largest improvements observed on tasks that include exogenous features. It also achieves a win rate of over 90% against Chronos-Bolt in head-to-head comparisons. To learn more about Chronos, check out the technical report.
- Chronos-Bolt: A patch-based variant of Chronos. It chunks the historical time series context into patches of multiple observations, which are then input into the encoder. The decoder then uses these representations to directly generate quantile forecasts across multiple future steps—a method known as direct multi-step forecasting. Chronos-Bolt models are up to 250 times faster and 20 times more memory-efficient than the original Chronos models of the same size. To learn more about Chronos-Bolt, check out this blog post.
- Chronos: The original Chronos family which is based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. To learn more about Chronos, check out the publication.
| Model ID | Parameters |
|---|---|
amazon/chronos-2 |
120M |
autogluon/chronos-2-synth |
120M |
autogluon/chronos-2-small |
28M |
amazon/chronos-bolt-tiny |
9M |
amazon/chronos-bolt-mini |
21M |
amazon/chronos-bolt-small |
48M |
amazon/chronos-bolt-base |
205M |
amazon/chronos-t5-tiny |
8M |
amazon/chronos-t5-mini |
20M |
amazon/chronos-t5-small |
46M |
amazon/chronos-t5-base |
200M |
amazon/chronos-t5-large |
710M |
To perform inference with Chronos, the easiest way is to install this package through pip:
pip install chronos-forecasting
[!TIP] For reliable production use, we recommend using Chronos-2 models through Amazon SageMaker JumpStart. Check out this tutorial to learn how to deploy Chronos-2 inference endpoints to AWS with just a few lines of code.
A minimal example showing how to perform forecasting using Chronos-2:
import pandas as pd # requires: pip install 'pandas[pyarrow]'
from chronos import Chronos2Pipeline
pipeline = Chronos2Pipeline.from_pretrained("amazon/chronos-2", device_map="cuda")
# Load historical target values and past values of covariates
context_df = pd.read_parquet("https://autogluon.s3.amazonaws.com/datasets/timeseries/electricity_price/train.parquet")
# (Optional) Load future values of covariates
test_df = pd.read_parquet("https://autogluon.s3.amazonaws.com/datasets/timeseries/electricity_price/test.parquet")
future_df = test_df.drop(columns="target")
# Generate predictions with covariates
pred_df = pipeline.predict_df(
context_df,
future_df=future_df,
prediction_length=24, # Number of steps to forecast
quantile_levels=[0.1, 0.5, 0.9], # Quantile for probabilistic forecast
id_column="id", # Column identifying different time series
timestamp_column="timestamp", # Column with datetime information
target="target", # Column(s) with time series values to predict
)
We can now visualize the forecast:
import matplotlib.pyplot as plt # requires: pip install matplotlib
ts_context = context_df.set_index("timestamp")["target"].tail(256)
ts_pred = pred_df.set_index("timestamp")
ts_ground_truth = test_df.set_index("timestamp")["target"]
ts_context.plot(label="historical data", color="xkcd:azure", figsize=(12, 3))
ts_ground_truth.plot(label="future data (ground truth)", color="xkcd:grass green")
ts_pred["predictions"].plot(label="forecast", color="xkcd:violet")
plt.fill_between(
ts_pred.index,
ts_pred["0.1"],
ts_pred["0.9"],
alpha=0.7,
label="prediction interval",
color="xkcd:light lavender",
)
plt.legend()
If you find Chronos models useful for your research, please consider citing the associated papers:
@article{ansari2024chronos,
title={Chronos: Learning the Language of Time Series},
author={Ansari, Abdul Fatir and Stella, Lorenzo and Turkmen, Caner and Zhang, Xiyuan, and Mercado, Pedro and Shen, Huibin and Shchur, Oleksandr and Rangapuram, Syama Syndar and Pineda Arango, Sebastian and Kapoor, Shubham and Zschiegner, Jasper and Maddix, Danielle C. and Mahoney, Michael W. and Torkkola, Kari and Gordon Wilson, Andrew and Bohlke-Schneider, Michael and Wang, Yuyang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=gerNCVqqtR}
}
@article{ansari2025chronos2,
title = {Chronos-2: From Univariate to Universal Forecasting},
author = {Abdul Fatir Ansari and Oleksandr Shchur and Jaris Küken and Andreas Auer and Boran Han and Pedro Mercado and Syama Sundar Rangapuram and Huibin Shen and Lorenzo Stella and Xiyuan Zhang and Mononito Goswami and Shubham Kapoor and Danielle C. Maddix and Pablo Guerron and Tony Hu and Junming Yin and Nick Erickson and Prateek Mutalik Desai and Hao Wang and Huzefa Rangwala and George Karypis and Yuyang Wang and Michael Bohlke-Schneider},
journal = {arXiv preprint arXiv:2510.15821},
year = {2025},
url = {https://arxiv.org/abs/2510.15821}
}
See CONTRIBUTING for more information.
This project is licensed under the Apache-2.0 License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chronos-forecasting
Similar Open Source Tools
chronos-forecasting
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.

VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
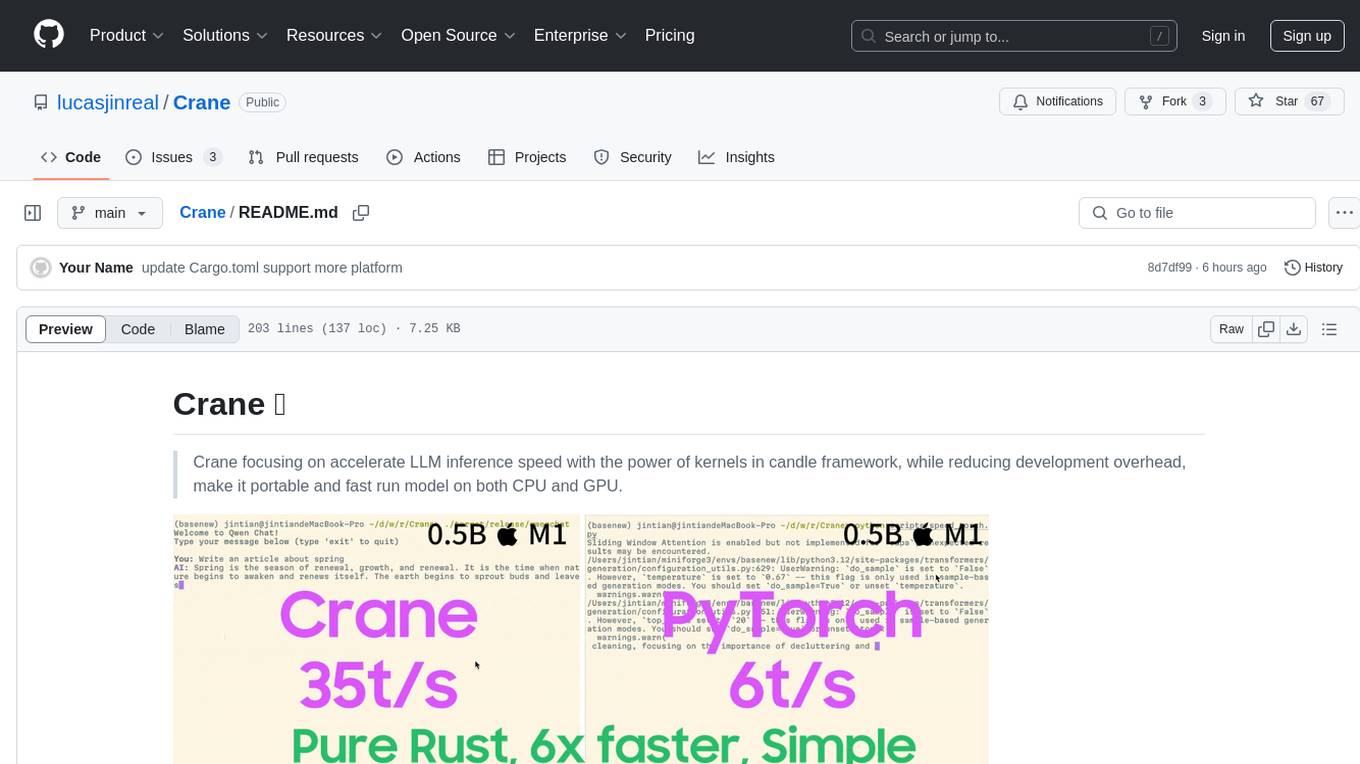
Crane
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.

OpenResearcher
OpenResearcher is a fully open agentic large language model designed for long-horizon deep research scenarios. It achieves an impressive 54.8% accuracy on BrowseComp-Plus, surpassing performance of GPT-4.1, Claude-Opus-4, Gemini-2.5-Pro, DeepSeek-R1, and Tongyi-DeepResearch. The tool is fully open-source, providing the training and evaluation recipe—including data, model, training methodology, and evaluation framework for everyone to progress deep research. It offers features like a fully open-source recipe, highly scalable and low-cost generation of deep research trajectories, and remarkable performance on deep research benchmarks.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.
RLHF-Reward-Modeling
This repository, RLHF-Reward-Modeling, is dedicated to training reward models for DRL-based RLHF (PPO), Iterative SFT, and iterative DPO. It provides state-of-the-art performance in reward models with a base model size of up to 13B. The installation instructions involve setting up the environment and aligning the handbook. Dataset preparation requires preprocessing conversations into a standard format. The code can be run with Gemma-2b-it, and evaluation results can be obtained using provided datasets. The to-do list includes various reward models like Bradley-Terry, preference model, regression-based reward model, and multi-objective reward model. The repository is part of iterative rejection sampling fine-tuning and iterative DPO.

BitBLAS
BitBLAS is a library for mixed-precision BLAS operations on GPUs, for example, the $W_{wdtype}A_{adtype}$ mixed-precision matrix multiplication where $C_{cdtype}[M, N] = A_{adtype}[M, K] \times W_{wdtype}[N, K]$. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the $W_{wdtype}A_{adtype}$ quantization in large language models (LLMs), for example, the $W_{UINT4}A_{FP16}$ in GPTQ, the $W_{INT2}A_{FP16}$ in BitDistiller, the $W_{INT2}A_{INT8}$ in BitNet-b1.58. BitBLAS is based on techniques from our accepted submission at OSDI'24.

cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.

ColossalAI
Colossal-AI is a deep learning system for large-scale parallel training. It provides a unified interface to scale sequential code of model training to distributed environments. Colossal-AI supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

pytorch-lightning
PyTorch Lightning is a framework for training and deploying AI models. It provides a high-level API that abstracts away the low-level details of PyTorch, making it easier to write and maintain complex models. Lightning also includes a number of features that make it easy to train and deploy models on multiple GPUs or TPUs, and to track and visualize training progress. PyTorch Lightning is used by a wide range of organizations, including Google, Facebook, and Microsoft. It is also used by researchers at top universities around the world. Here are some of the benefits of using PyTorch Lightning: * **Increased productivity:** Lightning's high-level API makes it easy to write and maintain complex models. This can save you time and effort, and allow you to focus on the research or business problem you're trying to solve. * **Improved performance:** Lightning's optimized training loops and data loading pipelines can help you train models faster and with better performance. * **Easier deployment:** Lightning makes it easy to deploy models to a variety of platforms, including the cloud, on-premises servers, and mobile devices. * **Better reproducibility:** Lightning's logging and visualization tools make it easy to track and reproduce training results.
ShapeLLM
ShapeLLM is the first 3D Multimodal Large Language Model designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. It supports single-view colored point cloud input and introduces a robust 3D QA benchmark, 3D MM-Vet, encompassing various variants. The model extends the powerful point encoder architecture, ReCon++, achieving state-of-the-art performance across a range of representation learning tasks. ShapeLLM can be used for tasks such as training, zero-shot understanding, visual grounding, few-shot learning, and zero-shot learning on 3D MM-Vet.
For similar tasks
chronos-forecasting
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.

mlcourse.ai
mlcourse.ai is an open Machine Learning course by OpenDataScience (ods.ai), led by Yury Kashnitsky (yorko). The course offers a perfect balance between theory and practice, with math formulae in lectures and practical assignments including Kaggle Inclass competitions. It is currently in a self-paced mode, guiding users through 10 weeks of content covering topics from Pandas to Gradient Boosting. The course provides articles, lectures, and assignments to enhance understanding and application of machine learning concepts.
For similar jobs
chronos-forecasting
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.