
uqlm
UQLM: Uncertainty Quantification for Language Models, is a Python package for UQ-based LLM hallucination detection
Stars: 1042
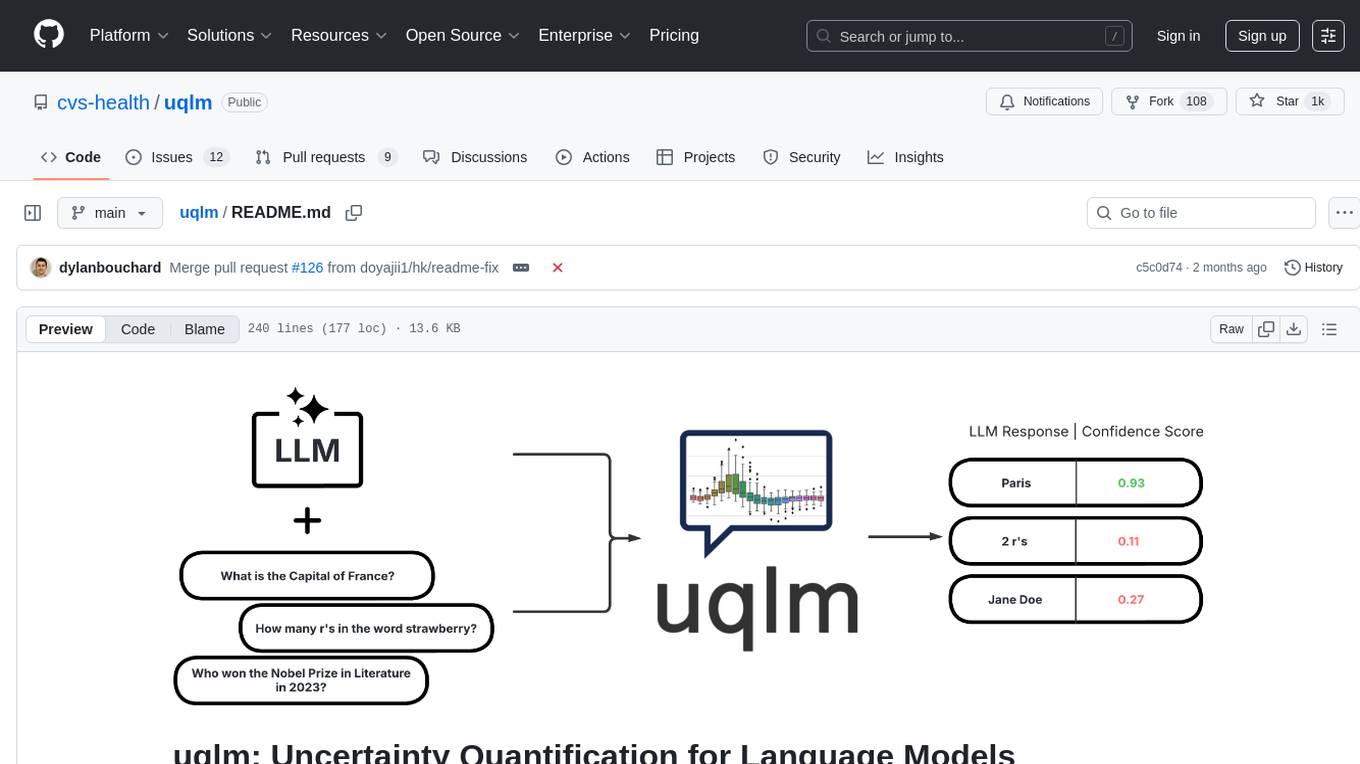
UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques. It provides response-level scorers for quantifying uncertainty of LLM outputs, categorized into four main types: Black-Box Scorers, White-Box Scorers, LLM-as-a-Judge Scorers, and Ensemble Scorers. Users can leverage different scorers to assess uncertainty in generated responses, with options for off-the-shelf usage or customization. The library offers illustrative code snippets and detailed information on available scorers for each type, along with example usage for conducting hallucination detection. Additionally, UQLM includes documentation, example notebooks, and associated research for further exploration and understanding.
README:

![]()
UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques.
The latest version can be installed from PyPI:
pip install uqlmUQLM provides a suite of response-level scorers for quantifying the uncertainty of Large Language Model (LLM) outputs. Each scorer returns a confidence score between 0 and 1, where higher scores indicate a lower likelihood of errors or hallucinations. We categorize these scorers into four main types:
| Scorer Type | Added Latency | Added Cost | Compatibility | Off-the-Shelf / Effort |
|---|---|---|---|---|
| Black-Box Scorers | ⏱️ Medium-High (multiple generations & comparisons) | 💸 High (multiple LLM calls) | 🌍 Universal (works with any LLM) | ✅ Off-the-shelf |
| White-Box Scorers | ⚡ Minimal (token probabilities already returned) | ✔️ None (no extra LLM calls) | 🔒 Limited (requires access to token probabilities) | ✅ Off-the-shelf |
| LLM-as-a-Judge Scorers | ⏳ Low-Medium (additional judge calls add latency) | 💵 Low-High (depends on number of judges) | 🌍 Universal (any LLM can serve as judge) | ✅ Off-the-shelf |
| Ensemble Scorers | 🔀 Flexible (combines various scorers) | 🔀 Flexible (combines various scorers) | 🔀 Flexible (combines various scorers) | ✅ Off-the-shelf (beginner-friendly); 🛠️ Can be tuned (best for advanced users) |
Below we provide illustrative code snippets and details about available scorers for each type.
These scorers assess uncertainty by measuring the consistency of multiple responses generated from the same prompt. They are compatible with any LLM, intuitive to use, and don't require access to internal model states or token probabilities.

Example Usage:
Below is a sample of code illustrating how to use the BlackBoxUQ class to conduct hallucination detection.
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(model='gemini-pro')
from uqlm import BlackBoxUQ
bbuq = BlackBoxUQ(llm=llm, scorers=["semantic_negentropy"], use_best=True)
results = await bbuq.generate_and_score(prompts=prompts, num_responses=5)
results.to_df()
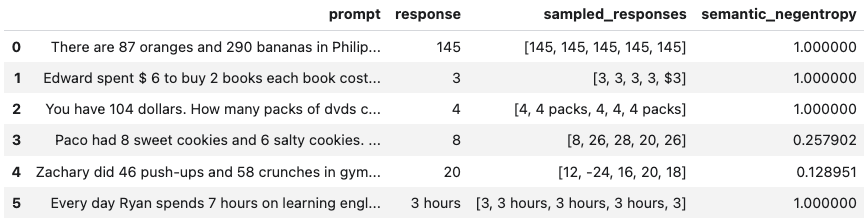
Above, use_best=True implements mitigation so that the uncertainty-minimized responses is selected. Note that although we use ChatVertexAI in this example, any LangChain Chat Model may be used. For a more detailed demo, refer to our Black-Box UQ Demo.
Available Scorers:
- Non-Contradiction Probability (Chen & Mueller, 2023; Lin et al., 2024; Manakul et al., 2023)
- Discrete Semantic Entropy (Farquhar et al., 2024; Bouchard & Chauhan, 2025)
- Exact Match (Cole et al., 2023; Chen & Mueller, 2023)
- BERT-score (Manakul et al., 2023; Zheng et al., 2020)
- Cosine Similarity (Shorinwa et al., 2024; HuggingFace)
- BLUERT (Sellam et al., 2020; Deprecated as of
v0.2.0)
These scorers leverage token probabilities to estimate uncertainty. They are significantly faster and cheaper than black-box methods, but require access to the LLM's internal probabilities, meaning they are not necessarily compatible with all LLMs/APIs.

Example Usage:
Below is a sample of code illustrating how to use the WhiteBoxUQ class to conduct hallucination detection.
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(model='gemini-pro')
from uqlm import WhiteBoxUQ
wbuq = WhiteBoxUQ(llm=llm, scorers=["min_probability"])
results = await wbuq.generate_and_score(prompts=prompts)
results.to_df()

Again, any LangChain Chat Model may be used in place of ChatVertexAI. For a more detailed demo, refer to our White-Box UQ Demo.
Available Scorers:
- Minimum token probability (Manakul et al., 2023)
- Length-Normalized Joint Token Probability (Malinin & Gales, 2021)
These scorers use one or more LLMs to evaluate the reliability of the original LLM's response. They offer high customizability through prompt engineering and the choice of judge LLM(s).

Example Usage:
Below is a sample of code illustrating how to use the LLMPanel class to conduct hallucination detection using a panel of LLM judges.
from langchain_google_vertexai import ChatVertexAI
llm1 = ChatVertexAI(model='gemini-1.0-pro')
llm2 = ChatVertexAI(model='gemini-1.5-flash-001')
llm3 = ChatVertexAI(model='gemini-1.5-pro-001')
from uqlm import LLMPanel
panel = LLMPanel(llm=llm1, judges=[llm1, llm2, llm3])
results = await panel.generate_and_score(prompts=prompts)
results.to_df()

Note that although we use ChatVertexAI in this example, we can use any LangChain Chat Model as judges. For a more detailed demo illustrating how to customize a panel of LLM judges, refer to our LLM-as-a-Judge Demo.
Available Scorers:
- Categorical LLM-as-a-Judge (Manakul et al., 2023; Chen & Mueller, 2023; Luo et al., 2023)
- Continuous LLM-as-a-Judge (Xiong et al., 2024)
- Panel of LLM Judges (Verga et al., 2024)
- Likert Scale Scoring (Bai et al., 2023)
These scorers leverage a weighted average of multiple individual scorers to provide a more robust uncertainty/confidence estimate. They offer high flexibility and customizability, allowing you to tailor the ensemble to specific use cases.

Example Usage:
Below is a sample of code illustrating how to use the UQEnsemble class to conduct hallucination detection.
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(model='gemini-pro')
from uqlm import UQEnsemble
## ---Option 1: Off-the-Shelf Ensemble---
# uqe = UQEnsemble(llm=llm)
# results = await uqe.generate_and_score(prompts=prompts, num_responses=5)
## ---Option 2: Tuned Ensemble---
scorers = [ # specify which scorers to include
"exact_match", "noncontradiction", # black-box scorers
"min_probability", # white-box scorer
llm # use same LLM as a judge
]
uqe = UQEnsemble(llm=llm, scorers=scorers)
# Tune on tuning prompts with provided ground truth answers
tune_results = await uqe.tune(
prompts=tuning_prompts, ground_truth_answers=ground_truth_answers
)
# ensemble is now tuned - generate responses on new prompts
results = await uqe.generate_and_score(prompts=prompts)
results.to_df()

As with the other examples, any LangChain Chat Model may be used in place of ChatVertexAI. For more detailed demos, refer to our Off-the-Shelf Ensemble Demo (quick start) or our Ensemble Tuning Demo (advanced).
Available Scorers:
- BS Detector (Chen & Mueller, 2023)
- Generalized UQ Ensemble (Bouchard & Chauhan, 2025)
Check out our documentation site for detailed instructions on using this package, including API reference and more.
Explore the following demo notebooks to see how to use UQLM for various hallucination detection methods:
- Black-Box Uncertainty Quantification: A notebook demonstrating hallucination detection with black-box (consistency) scorers.
- White-Box Uncertainty Quantification: A notebook demonstrating hallucination detection with white-box (token probability-based) scorers.
- LLM-as-a-Judge: A notebook demonstrating hallucination detection with LLM-as-a-Judge.
- Tunable UQ Ensemble: A notebook demonstrating hallucination detection with a tunable ensemble of UQ scorers (Bouchard & Chauhan, 2025).
- Off-the-Shelf UQ Ensemble: A notebook demonstrating hallucination detection using BS Detector (Chen & Mueller, 2023) off-the-shelf ensemble.
- Semantic Entropy: A notebook demonstrating token-probability-based semantic entropy (Farquhar et al., 2024; Kuhn et al., 2023), which combines elements of black-box UQ and white-box UQ to compute confidence scores.
A technical description of the uqlm scorers and extensive experiment results are contained in this this paper. If you use our framework or toolkit, we would appreciate citations to the following paper:
@misc{bouchard2025uncertaintyquantificationlanguagemodels,
title={Uncertainty Quantification for Language Models: A Suite of Black-Box, White-Box, LLM Judge, and Ensemble Scorers},
author={Dylan Bouchard and Mohit Singh Chauhan},
year={2025},
eprint={2504.19254},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.19254},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for uqlm
Similar Open Source Tools
uqlm
UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques. It provides response-level scorers for quantifying uncertainty of LLM outputs, categorized into four main types: Black-Box Scorers, White-Box Scorers, LLM-as-a-Judge Scorers, and Ensemble Scorers. Users can leverage different scorers to assess uncertainty in generated responses, with options for off-the-shelf usage or customization. The library offers illustrative code snippets and detailed information on available scorers for each type, along with example usage for conducting hallucination detection. Additionally, UQLM includes documentation, example notebooks, and associated research for further exploration and understanding.

FlashRank
FlashRank is an ultra-lite and super-fast Python library designed to add re-ranking capabilities to existing search and retrieval pipelines. It is based on state-of-the-art Language Models (LLMs) and cross-encoders, offering support for pairwise/pointwise rerankers and listwise LLM-based rerankers. The library boasts the tiniest reranking model in the world (~4MB) and runs on CPU without the need for Torch or Transformers. FlashRank is cost-conscious, with a focus on low cost per invocation and smaller package size for efficient serverless deployments. It supports various models like ms-marco-TinyBERT, ms-marco-MiniLM, rank-T5-flan, ms-marco-MultiBERT, and more, with plans for future model additions. The tool is ideal for enhancing search precision and speed in scenarios where lightweight models with competitive performance are preferred.
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.

transformers
Transformers is a state-of-the-art pretrained models library that acts as the model-definition framework for machine learning models in text, computer vision, audio, video, and multimodal tasks. It centralizes model definition for compatibility across various training frameworks, inference engines, and modeling libraries. The library simplifies the usage of new models by providing simple, customizable, and efficient model definitions. With over 1M+ Transformers model checkpoints available, users can easily find and utilize models for their tasks.
chronos-forecasting
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.
Eco2AI
Eco2AI is a python library for CO2 emission tracking that monitors energy consumption of CPU & GPU devices and estimates equivalent carbon emissions based on regional emission coefficients. Users can easily integrate Eco2AI into their Python scripts by adding a few lines of code. The library records emissions data and device information in a local file, providing detailed session logs with project names, experiment descriptions, start times, durations, power consumption, CO2 emissions, CPU and GPU names, operating systems, and countries.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.


MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.

interpreto
Interpreto is an interpretability toolkit for large language models (LLMs) that provides a modular framework encompassing attribution methods, concept-based methods, and evaluation metrics. It includes various inference-based and gradient-based attribution methods for both classification and generation tasks. The toolkit also offers concept-based explanations to provide high-level interpretations of latent model representations through steps like concept discovery, interpretation, and concept-to-output attribution. Interpreto aims to enhance model interpretability and facilitate understanding of model decisions and outputs.
For similar tasks
uqlm
UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques. It provides response-level scorers for quantifying uncertainty of LLM outputs, categorized into four main types: Black-Box Scorers, White-Box Scorers, LLM-as-a-Judge Scorers, and Ensemble Scorers. Users can leverage different scorers to assess uncertainty in generated responses, with options for off-the-shelf usage or customization. The library offers illustrative code snippets and detailed information on available scorers for each type, along with example usage for conducting hallucination detection. Additionally, UQLM includes documentation, example notebooks, and associated research for further exploration and understanding.
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

llama3_interpretability_sae
This project focuses on implementing Sparse Autoencoders (SAEs) for mechanistic interpretability in Large Language Models (LLMs) like Llama 3.2-3B. The SAEs aim to untangle superimposed representations in LLMs into separate, interpretable features for each neuron activation. The project provides an end-to-end pipeline for capturing training data, training the SAEs, analyzing learned features, and verifying results experimentally. It includes comprehensive logging, visualization, and checkpointing of SAE training, interpretability analysis tools, and a pure PyTorch implementation of Llama 3.1/3.2 chat and text completion. The project is designed for scalability, efficiency, and maintainability.
mystic
The `mystic` framework provides a collection of optimization algorithms and tools that allow the user to robustly solve hard optimization problems. It offers fine-grained power to monitor and steer optimizations during the fit processes. Optimizers can advance one iteration or run to completion, with customizable stop conditions. `mystic` optimizers share a common interface for easy swapping without writing new code. The framework supports parameter constraints, including soft and hard constraints, and provides tools for scientific machine learning, uncertainty quantification, adaptive sampling, nonlinear interpolation, and artificial intelligence. `mystic` is actively developed and welcomes user feedback and contributions.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.