
EmbodiedScan
[CVPR 2024] EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied AI
Stars: 412

EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.
README:
This repository contains EmbodiedScan-series works for holistic multi-modal 3D perception, currently including EmbodiedScan & MMScan.
🤖 Demo


- [2024-08] We preliminarily release the sample data of MMScan and the full release will be ready with ARKitScenes' annotations this month, which will be announced via emails to the community. Please stay tuned!
- [2024-06] The report of our follow-up work with the most-ever hierarchical grounded language annotations, MMScan, has been released. Welcome to talk with us about EmbodiedScan and MMScan at Seattle, CVPR 2024!
- [2024-04] We release all the baselines with pretrained models and logs. Welcome to try and play with them on our demo data! Note that we rename some keys in the multi-view 3D detection and visual grounding model. Please re-download the pretrained models if you just use our code for inference.
- [2024-03] The challenge test server is also online here. Looking forward to your strong submissions!
- [2024-03] We first release the data and baselines for the challenge. Please fill in the form to apply for downloading the data and try our baselines. Welcome any feedback!
- [2024-02] We will co-organize Autonomous Grand Challenge in CVPR 2024. Welcome to try the Multi-View 3D Visual Grounding track! We will release more details about the challenge with the baseline after the Chinese New Year.
- [2023-12] We release the paper of EmbodiedScan. Please check the webpage and view our demos!
We test our codes under the following environment:
- Ubuntu 20.04
- NVIDIA Driver: 525.147.05
- CUDA 12.0
- Python 3.8.18
- PyTorch 1.11.0+cu113
- PyTorch3D 0.7.2
- Clone this repository.
git clone https://github.com/OpenRobotLab/EmbodiedScan.git
cd EmbodiedScan- Create an environment and install PyTorch.
conda create -n embodiedscan python=3.8 -y # pytorch3d needs python>3.7
conda activate embodiedscan
# Install PyTorch, for example, install PyTorch 1.11.0 for CUDA 11.3
# For more information, please refer to https://pytorch.org/get-started/locally/
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch- Install EmbodiedScan.
# We plan to make EmbodiedScan easier to install by "pip install EmbodiedScan".
# Please stay tuned for the future official release.
# Make sure you are under ./EmbodiedScan/
# This script will install the dependencies and EmbodiedScan package automatically.
# use [python install.py run] to install only the execution dependencies
# use [python install.py visual] to install only the visualization dependencies
python install.py all # install all the dependenciesNote: The automatic installation script make each step a subprocess and the related messages are only printed when the subprocess is finished or killed. Therefore, it is normal to seemingly hang when installing heavier packages, such as Mink Engine and PyTorch3D.
BTW, from our experience, it is easier to encounter problems when installing these two packages. Feel free to post your questions or suggestions during the installation procedure.
Please refer to the guide for downloading and organization.
We provide a simple tutorial here as a guideline for the basic analysis and visualization of our dataset. Welcome to try and post your suggestions!
We provide a demo for running EmbodiedScan's model on a sample scan. Please download the raw data from Google Drive or BaiduYun and refer to the notebook for more details.

We provide configs for different tasks here and you can run the train and test script in the tools folder for training and inference. For example, to train a multi-view 3D detection model with pytorch, just run:
# Single GPU training
python tools/train.py configs/detection/mv-det3d_8xb4_embodiedscan-3d-284class-9dof.py --work-dir=work_dirs/mv-3ddet
# Multiple GPU training
python tools/train.py configs/detection/mv-det3d_8xb4_embodiedscan-3d-284class-9dof.py --work-dir=work_dirs/mv-3ddet --launcher="pytorch"Or on the cluster with multiple machines, run the script with the slurm launcher following the sample script provided here.
NOTE: To run the multi-view 3D grounding experiments, please first download the 3D detection pretrained model to accelerate its training procedure. After downloading the detection checkpoint, please check the path used in the config, for example, the load_from here, is correct.
To inference and evaluate the model (e.g., the checkpoint work_dirs/mv-3ddet/epoch_12.pth), just run the test script:
# Single GPU testing
python tools/test.py configs/detection/mv-det3d_8xb4_embodiedscan-3d-284class-9dof.py work_dirs/mv-3ddet/epoch_12.pth
# Multiple GPU testing
python tools/test.py configs/detection/mv-det3d_8xb4_embodiedscan-3d-284class-9dof.py work_dirs/mv-3ddet/epoch_12.pth --launcher="pytorch"We provide EmbodiedScanBaseVisualizer to visualize the output of models during inference. Please refer to the guide for detail.
We preliminarily support format-only inference for multi-view 3D visual grounding. To achieve format-only inference during test, just set format_only=True in test_evaluator in the corresponding config like here. Then just run the test script like:
python tools/test.py configs/grounding/mv-grounding_8xb12_embodiedscan-vg-9dof.py work_dirs/mv-grounding/epoch_12.pth --launcher="pytorch"The prediction file will be saved to ./test_results.json in the current directory.
You can also set the result_dir in test_evaluator to specify the directory to save the result file.
Finally, to pack the prediction file into the submission format, please modify the script tools/submit_results.py according to your team information and saving paths, and run:
python tools/submit_results.pyThen you can submit the resulting pkl file to the test server and wait for the lottery :)
We also provide a sample script tools/eval_script.py for evaluating the submission file and you can check it by yourself to ensure your submitted file has the correct format.
We preliminarily provide several baseline results here with their logs and pretrained models.
Note that the performance is a little different from the results provided in the paper because we re-split the training set as the released training and validation set while keeping the original validation set as the test set for the public benchmark.
| Method | Input | [email protected] | [email protected] | [email protected] | [email protected] | Download |
|---|---|---|---|---|---|---|
| Baseline | RGB-D | 15.22 | 52.23 | 8.13 | 26.66 | Model, Log |
| Method | Input | [email protected] | [email protected] | [email protected] | [email protected] | Download |
|---|---|---|---|---|---|---|
| Baseline | RGB-D | 17.83 | 47.53 | 9.04 | 23.04 | Model, Log |
| Method | [email protected] | [email protected] | Download |
|---|---|---|---|
| Baseline-Mini | 33.59 | 14.40 | Model, Log |
| Baseline-Mini (w/ FCAF box coder) | - | - | - |
| Baseline-Full | 36.78 | 15.97 | Model, Log |
Note: As mentioned in the paper, due to much more instances annotated with our new tools and pipelines, we concatenate several simple prompts as more complex ones to ensure those prompts to be more accurate without potential ambiguity. The above table is the benchmark without complex prompts using the initial version of visual grounding data.
We found such data is much less than the main part though, it can boost the multi-modal model's performance a lot. Meanwhile, whether to include these data in the validation set is not much important. We provide the updated benchmark as below and update a version of visual grounding data via emails to the community.
| Method | train | val | [email protected] | [email protected] | Download |
|---|---|---|---|---|---|
| Baseline-Full | w/o complex | w/o complex | 36.78 | 15.97 | Model, Log |
| Baseline-Full | w/ complex | w/o complex | 39.26 | 18.86 | Model, Log |
| Baseline-Full | w/ complex | w/ complex | 39.21 | 18.84 | Model, Log |
| Method | Input | mIoU | Download |
|---|---|---|---|
| Baseline | RGB-D | 21.28 | Log |
| Method | Input | mIoU | Download |
|---|---|---|---|
| Baseline | RGB-D | 22.92 | Log |
Because the occupancy prediction models are a little large, we save them via OpenXLab and do not provide direct download links here. To download these checkpoints on OpenXLab, please run the following commands:
# If you did not install LFS before
git lfs install
# git clone EmbodiedScan model repo via
git clone https://code.openxlab.org.cn/wangtai/EmbodiedScan.git
# Then you can cd EmbodiedScan to get all the pretrained modelsPlease see the paper for more details of our benchmarks. This dataset is still scaling up and the benchmark is being polished and extended. Please stay tuned for our recent updates.
- [x] Release the paper and partial codes for datasets.
- [x] Release EmbodiedScan annotation files.
- [x] Release partial codes for models and evaluation.
- [ ] Polish dataset APIs and related codes.
- [x] Release Embodied Perceptron pretrained models.
- [x] Release multi-modal datasets and codes.
- [x] Release codes for our baselines and benchmarks.
- [ ] Release codes for all the other methods.
- [ ] Full release and further updates.
- [ ] Release MMScan data and codes.
If you find our work helpful, please cite:
@inproceedings{embodiedscan,
title={EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied AI},
author={Wang, Tai and Mao, Xiaohan and Zhu, Chenming and Xu, Runsen and Lyu, Ruiyuan and Li, Peisen and Chen, Xiao and Zhang, Wenwei and Chen, Kai and Xue, Tianfan and Liu, Xihui and Lu, Cewu and Lin, Dahua and Pang, Jiangmiao},
year={2024},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
}
@inproceedings{mmscan,
title={MMScan: A Multi-Modal 3D Scene Dataset with Hierarchical Grounded Language Annotations},
author={Lyu, Ruiyuan and Wang, Tai and Lin, Jingli and Yang, Shuai and Mao, Xiaohan and Chen, Yilun and Xu, Runsen and Huang, Haifeng and Zhu, Chenming and Lin, Dahua and Pang, Jiangmiao},
year={2024},
booktitle={arXiv},
}If you use our dataset and benchmark, please kindly cite the original datasets involved in our work. BibTex entries are provided below.
Dataset BibTex
@inproceedings{dai2017scannet,
title={ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes},
author={Dai, Angela and Chang, Angel X. and Savva, Manolis and Halber, Maciej and Funkhouser, Thomas and Nie{\ss}ner, Matthias},
booktitle = {Proceedings IEEE Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}@inproceedings{Wald2019RIO,
title={RIO: 3D Object Instance Re-Localization in Changing Indoor Environments},
author={Johanna Wald, Armen Avetisyan, Nassir Navab, Federico Tombari, Matthias Niessner},
booktitle={Proceedings IEEE International Conference on Computer Vision (ICCV)},
year = {2019}
}@article{Matterport3D,
title={{Matterport3D}: Learning from {RGB-D} Data in Indoor Environments},
author={Chang, Angel and Dai, Angela and Funkhouser, Thomas and Halber, Maciej and Niessner, Matthias and Savva, Manolis and Song, Shuran and Zeng, Andy and Zhang, Yinda},
journal={International Conference on 3D Vision (3DV)},
year={2017}
}
This work is under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
- OpenMMLab: Our dataset code uses MMEngine and our model is built upon MMDetection3D.
- PyTorch3D: We use some functions supported in PyTorch3D for efficient computations on fundamental 3D data structures.
- ScanNet, 3RScan, Matterport3D: Our dataset uses the raw data from these datasets.
- ReferIt3D: We refer to the SR3D's approach to obtaining the language prompt annotations.
- SUSTechPOINTS: Our annotation tool is developed based on the open-source framework used by SUSTechPOINTS.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for EmbodiedScan
Similar Open Source Tools
EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.

transformers
Transformers is a state-of-the-art pretrained models library that acts as the model-definition framework for machine learning models in text, computer vision, audio, video, and multimodal tasks. It centralizes model definition for compatibility across various training frameworks, inference engines, and modeling libraries. The library simplifies the usage of new models by providing simple, customizable, and efficient model definitions. With over 1M+ Transformers model checkpoints available, users can easily find and utilize models for their tasks.

RD-Agent
RD-Agent is a tool designed to automate critical aspects of industrial R&D processes, focusing on data-driven scenarios to streamline model and data development. It aims to propose new ideas ('R') and implement them ('D') automatically, leading to solutions of significant industrial value. The tool supports scenarios like Automated Quantitative Trading, Data Mining Agent, Research Copilot, and more, with a framework to push the boundaries of research in data science. Users can create a Conda environment, install the RDAgent package from PyPI, configure GPT model, and run various applications for tasks like quantitative trading, model evolution, medical prediction, and more. The tool is intended to enhance R&D processes and boost productivity in industrial settings.

evalverse
Evalverse is an open-source project designed to support Large Language Model (LLM) evaluation needs. It provides a standardized and user-friendly solution for processing and managing LLM evaluations, catering to AI research engineers and scientists. Evalverse supports various evaluation methods, insightful reports, and no-code evaluation processes. Users can access unified evaluation with submodules, request evaluations without code via Slack bot, and obtain comprehensive reports with scores, rankings, and visuals. The tool allows for easy comparison of scores across different models and swift addition of new evaluation tools.

CuMo
CuMo is a project focused on scaling multimodal Large Language Models (LLMs) with Co-Upcycled Mixture-of-Experts. It introduces CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into the vision encoder and the MLP connector, enhancing the capabilities of multimodal LLMs. The project adopts a three-stage training approach with auxiliary losses to stabilize the training process and maintain a balanced loading of experts. CuMo achieves comparable performance to other state-of-the-art multimodal LLMs on various Visual Question Answering (VQA) and visual-instruction-following benchmarks.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.

LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.
VideoTuna
VideoTuna is a codebase for text-to-video applications that integrates multiple AI video generation models for text-to-video, image-to-video, and text-to-image generation. It provides comprehensive pipelines in video generation, including pre-training, continuous training, post-training, and fine-tuning. The models in VideoTuna include U-Net and DiT architectures for visual generation tasks, with upcoming releases of a new 3D video VAE and a controllable facial video generation model.

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.
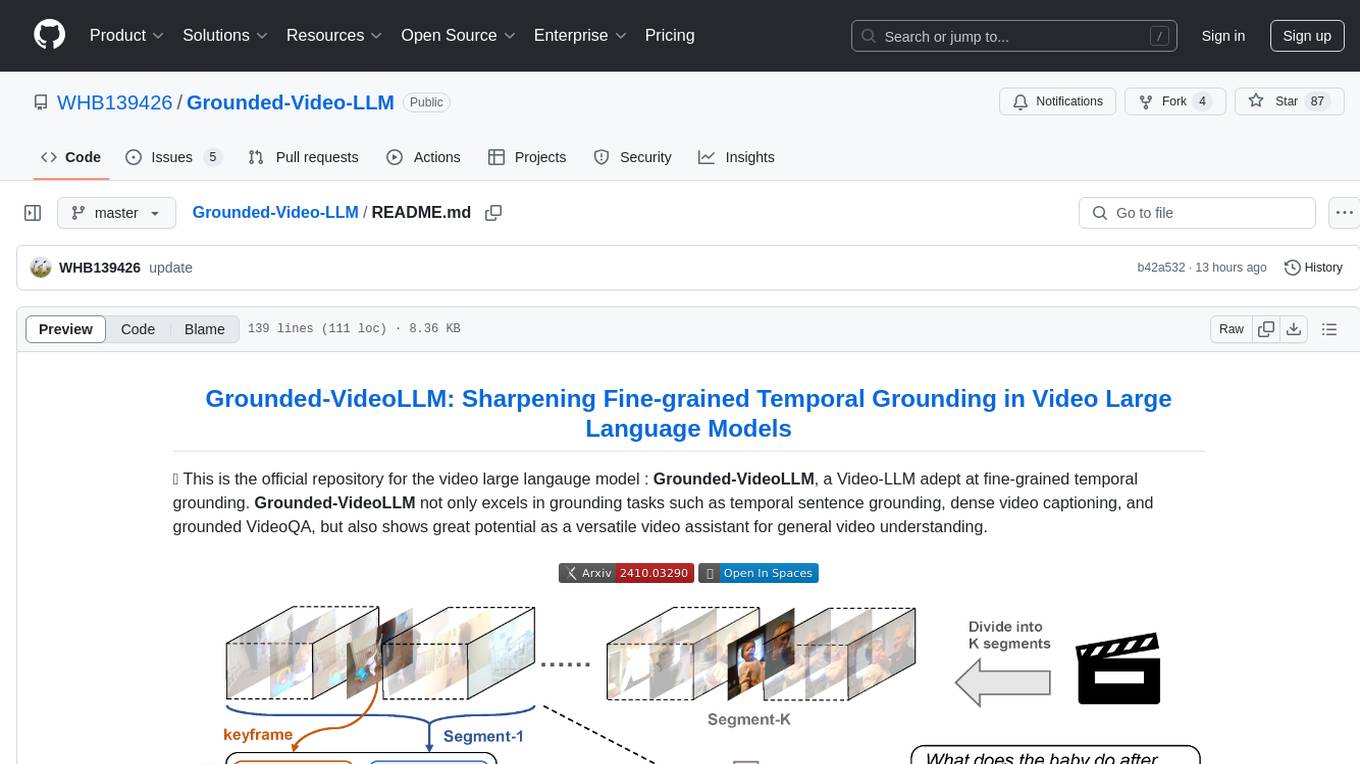
Grounded-Video-LLM
Grounded-VideoLLM is a Video Large Language Model specialized in fine-grained temporal grounding. It excels in tasks such as temporal sentence grounding, dense video captioning, and grounded VideoQA. The model incorporates an additional temporal stream, discrete temporal tokens with specific time knowledge, and a multi-stage training scheme. It shows potential as a versatile video assistant for general video understanding. The repository provides pretrained weights, inference scripts, and datasets for training. Users can run inference queries to get temporal information from videos and train the model from scratch.
For similar tasks
EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.