
ai-enhanced-audio-book
A repository of AI-enhanced audio plugins written using C++, JUCE, libtorch, RTNeural and other libraries. Supports my book
Stars: 77
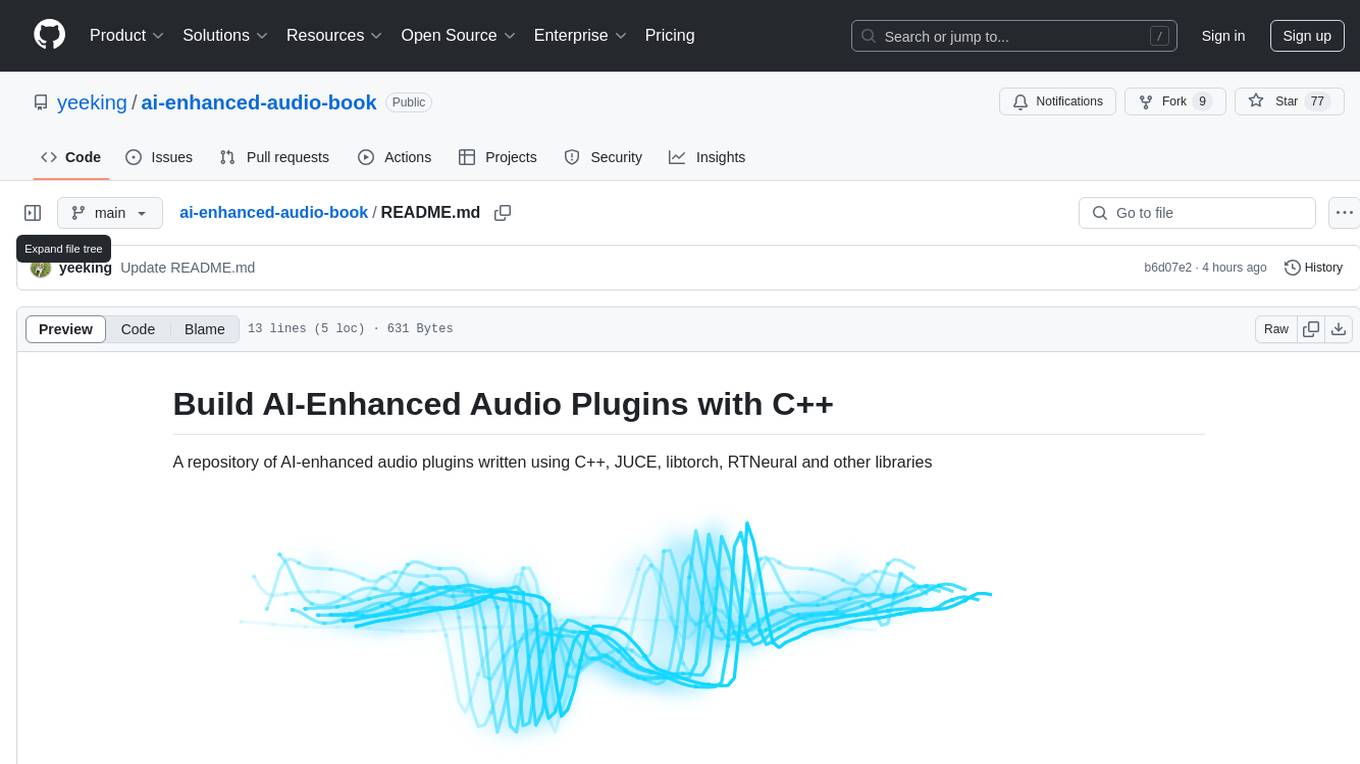
The ai-enhanced-audio-book repository contains AI-enhanced audio plugins developed using C++, JUCE, libtorch, RTNeural, and other libraries. It showcases neural networks learning to emulate guitar amplifiers through waveforms. Users can visit the official website for more information and obtain a copy of the book from the publisher Taylor and Francis/ Routledge/ Focal.
README:
A repository of AI-enhanced audio plugins written using C++, JUCE, libtorch, RTNeural and other libraries
Visit the official website for the book
Visit the publisher Taylor and Francis/ Routledge/ Focal to obtain a copy of the book
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-enhanced-audio-book
Similar Open Source Tools
ai-enhanced-audio-book
The ai-enhanced-audio-book repository contains AI-enhanced audio plugins developed using C++, JUCE, libtorch, RTNeural, and other libraries. It showcases neural networks learning to emulate guitar amplifiers through waveforms. Users can visit the official website for more information and obtain a copy of the book from the publisher Taylor and Francis/ Routledge/ Focal.
Building-AI-Applications-with-ChatGPT-APIs
This repository is for the book 'Building AI Applications with ChatGPT APIs' published by Packt. It provides code examples and instructions for mastering ChatGPT, Whisper, and DALL-E APIs through building innovative AI projects. Readers will learn to develop AI applications using ChatGPT APIs, integrate them with frameworks like Flask and Django, create AI-generated art with DALL-E APIs, and optimize ChatGPT models through fine-tuning.
amazon-sagemaker-generativeai
Repository for training and deploying Generative AI models, including text-text, text-to-image generation, prompt engineering playground and chain of thought examples using SageMaker Studio. The tool provides a platform for users to experiment with generative AI techniques, enabling them to create text and image outputs based on input data. It offers a range of functionalities for training and deploying models, as well as exploring different generative AI applications.
chatwise-releases
ChatWise is an offline tool that supports various AI models such as OpenAI, Anthropic, Google AI, Groq, and Ollama. It is multi-modal, allowing text-to-speech powered by OpenAI and ElevenLabs. The tool supports text files, PDFs, audio, and images across different models. ChatWise is currently available for macOS (Apple Silicon & Intel) with Windows support coming soon.
ollama-playground
Ollama Projects is a repository containing code for various projects built using Ollama's open-source models. The projects include Chat with PDF, Chat with PDF Using Hybrid RAG, AI Scraper, Image Search, OCR, Object Detection, Emotion Detection, and AI Researcher. These projects showcase the capabilities of Ollama's models and provide insights into AI applications in different domains.
off-grid-mobile
Off Grid is a complete offline AI suite that allows users to perform various tasks such as text generation, image generation, vision AI, voice transcription, and document analysis on their mobile devices without sending any data out. The tool offers high performance on flagship devices and supports a wide range of models for different tasks. Users can easily install the tool on Android by downloading the APK from GitHub Releases or build it from source with Node.js and JDK. The documentation provides detailed information on the system architecture, codebase, design system, visual hierarchy, test flows, and more. Contributions are welcome, and the tool is built with a focus on user privacy and data security, ensuring no cloud, subscription, or data harvesting.
vectordb-recipes
This repository contains examples, applications, starter code, & tutorials to help you kickstart your GenAI projects. * These are built using LanceDB, a free, open-source, serverless vectorDB that **requires no setup**. * It **integrates into python data ecosystem** so you can simply start using these in your existing data pipelines in pandas, arrow, pydantic etc. * LanceDB has **native Typescript SDK** using which you can **run vector search** in serverless functions! This repository is divided into 3 sections: - Examples - Get right into the code with minimal introduction, aimed at getting you from an idea to PoC within minutes! - Applications - Ready to use Python and web apps using applied LLMs, VectorDB and GenAI tools - Tutorials - A curated list of tutorials, blogs, Colabs and courses to get you started with GenAI in greater depth.
Audio-Upscaler
Audio Upscaler (AudioSR) is a powerful tool designed to enhance the fidelity of audio files, regardless of type or sampling rates. It leverages cutting-edge super-resolution techniques to upscale audio signals, resulting in superior quality output. The tool is versatile, handling all types of audio content, easy to use with a simple interface, and ensures high fidelity output with enhanced clarity and detail.
talemate
Talemate is a roleplay tool that allows users to interact with AI agents for dialogue, narration, summarization, direction, editing, world state management, character/scenario creation, text-to-speech, and visual generation. It supports multiple AI clients and APIs, offers long-term memory using ChromaDB, and provides tools for managing NPCs, AI-assisted character creation, and scenario creation. Users can customize prompts using Jinja2 templates and benefit from a modern, responsive UI. The tool also integrates with Runpod for enhanced functionality.

Genkit
Genkit is an open-source framework for building full-stack AI-powered applications, used in production by Google's Firebase. It provides SDKs for JavaScript/TypeScript (Stable), Go (Beta), and Python (Alpha) with unified interface for integrating AI models from providers like Google, OpenAI, Anthropic, Ollama. Rapidly build chatbots, automations, and recommendation systems using streamlined APIs for multimodal content, structured outputs, tool calling, and agentic workflows. Genkit simplifies AI integration with open-source SDK, unified APIs, and offers text and image generation, structured data generation, tool calling, prompt templating, persisted chat interfaces, AI workflows, and AI-powered data retrieval (RAG).
Rodel.Agent
Rodel Agent is a Windows desktop application that integrates chat, text-to-image, text-to-speech, and machine translation services, providing users with a comprehensive desktop AI experience. The application supports mainstream AI services and aims to enhance user interaction through various AI functionalities.
LLM-GenAI-Transformers-Notebooks
This repository is a collection of LLM notebooks with tutorials and projects. It covers topics such as Transformers tutorials, LLM notebooks and their applications, tools and technologies of GenAI, courses in GenAI, and Generative AI blogs/articles. Contributions are welcome.
bedrock-engineer
Bedrock Engineer is an AI assistant for software development tasks powered by Amazon Bedrock. It combines large language models with file system operations and web search functionality to support development processes. The autonomous AI agent provides interactive chat, file system operations, web search, project structure management, code analysis, code generation, data analysis, agent and tool customization, chat history management, and multi-language support. Users can select agents, customize them, select tools, and customize tools. The tool also includes a website generator for React.js, Vue.js, Svelte.js, and Vanilla.js, with support for inline styling, Tailwind.css, and Material UI. Users can connect to design system data sources and generate AWS Step Functions ASL definitions.
deepagent-releases
Abacus AI Desktop is a powerful desktop AI assistant that offers agentic browsing, listening, coding CLI, and editor functionalities. It allows users to automate their work using state-of-the-art AI technology. The platform provides a comprehensive solution for various tasks, making it a versatile tool for enhancing productivity and efficiency in daily workflows.

sycamore
Sycamore is a conversational search and analytics platform for complex unstructured data, such as documents, presentations, transcripts, embedded tables, and internal knowledge repositories. It retrieves and synthesizes high-quality answers through bringing AI to data preparation, indexing, and retrieval. Sycamore makes it easy to prepare unstructured data for search and analytics, providing a toolkit for data cleaning, information extraction, enrichment, summarization, and generation of vector embeddings that encapsulate the semantics of data. Sycamore uses your choice of generative AI models to make these operations simple and effective, and it enables quick experimentation and iteration. Additionally, Sycamore uses OpenSearch for indexing, enabling hybrid (vector + keyword) search, retrieval-augmented generation (RAG) pipelining, filtering, analytical functions, conversational memory, and other features to improve information retrieval.
applied-ai-engineering-samples
The Google Cloud Applied AI Engineering repository provides reference guides, blueprints, code samples, and hands-on labs developed by the Google Cloud Applied AI Engineering team. It contains resources for Generative AI on Vertex AI, including code samples and hands-on labs demonstrating the use of Generative AI models and tools in Vertex AI. Additionally, it offers reference guides and blueprints that compile best practices and prescriptive guidance for running large-scale AI/ML workloads on Google Cloud AI/ML infrastructure.
For similar tasks
Awesome-AITools
This repo collects AI-related utilities. ## All Categories * All Categories * ChatGPT and other closed-source LLMs * AI Search engine * Open Source LLMs * GPT/LLMs Applications * LLM training platform * Applications that integrate multiple LLMs * AI Agent * Writing * Programming Development * Translation * AI Conversation or AI Voice Conversation * Image Creation * Speech Recognition * Text To Speech * Voice Processing * AI generated music or sound effects * Speech translation * Video Creation * Video Content Summary * OCR(Optical Character Recognition)

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.
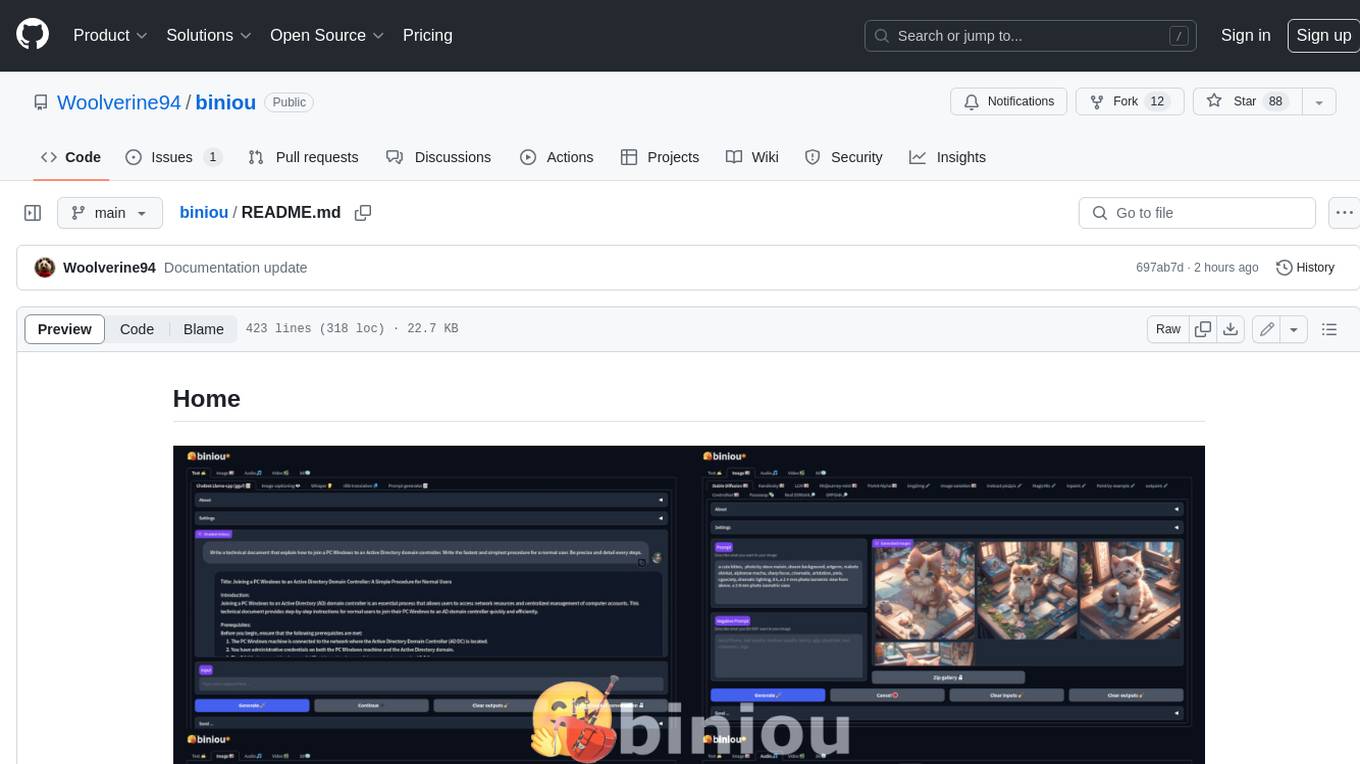
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
generative-ai-js
Generative AI JS is a JavaScript library that provides tools for creating generative art and music using artificial intelligence techniques. It allows users to generate unique and creative content by leveraging machine learning models. The library includes functions for generating images, music, and text based on user input and preferences. With Generative AI JS, users can explore the intersection of art and technology, experiment with different creative processes, and create dynamic and interactive content for various applications.
pictureChange
The 'pictureChange' repository is a plugin that supports image processing using Baidu AI, stable diffusion webui, and suno music composition AI. It also allows for file summarization and image summarization using AI. The plugin supports various stable diffusion models, administrator control over group chat features, concurrent control, and custom templates for image and text generation. It can be deployed on WeChat enterprise accounts, personal accounts, and public accounts.
Generative-AI-Indepth-Basic-to-Advance
Generative AI Indepth Basic to Advance is a repository focused on providing tutorials and resources related to generative artificial intelligence. The repository covers a wide range of topics from basic concepts to advanced techniques in the field of generative AI. Users can find detailed explanations, code examples, and practical demonstrations to help them understand and implement generative AI algorithms. The goal of this repository is to help beginners get started with generative AI and to provide valuable insights for more experienced practitioners.
nodetool
NodeTool is a platform designed for AI enthusiasts, developers, and creators, providing a visual interface to access a variety of AI tools and models. It simplifies access to advanced AI technologies, offering resources for content creation, data analysis, automation, and more. With features like a visual editor, seamless integration with leading AI platforms, model manager, and API integration, NodeTool caters to both newcomers and experienced users in the AI field.
ai-enhanced-audio-book
The ai-enhanced-audio-book repository contains AI-enhanced audio plugins developed using C++, JUCE, libtorch, RTNeural, and other libraries. It showcases neural networks learning to emulate guitar amplifiers through waveforms. Users can visit the official website for more information and obtain a copy of the book from the publisher Taylor and Francis/ Routledge/ Focal.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.
NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.