
biniou
a self-hosted webui for 30+ generative ai
Stars: 619
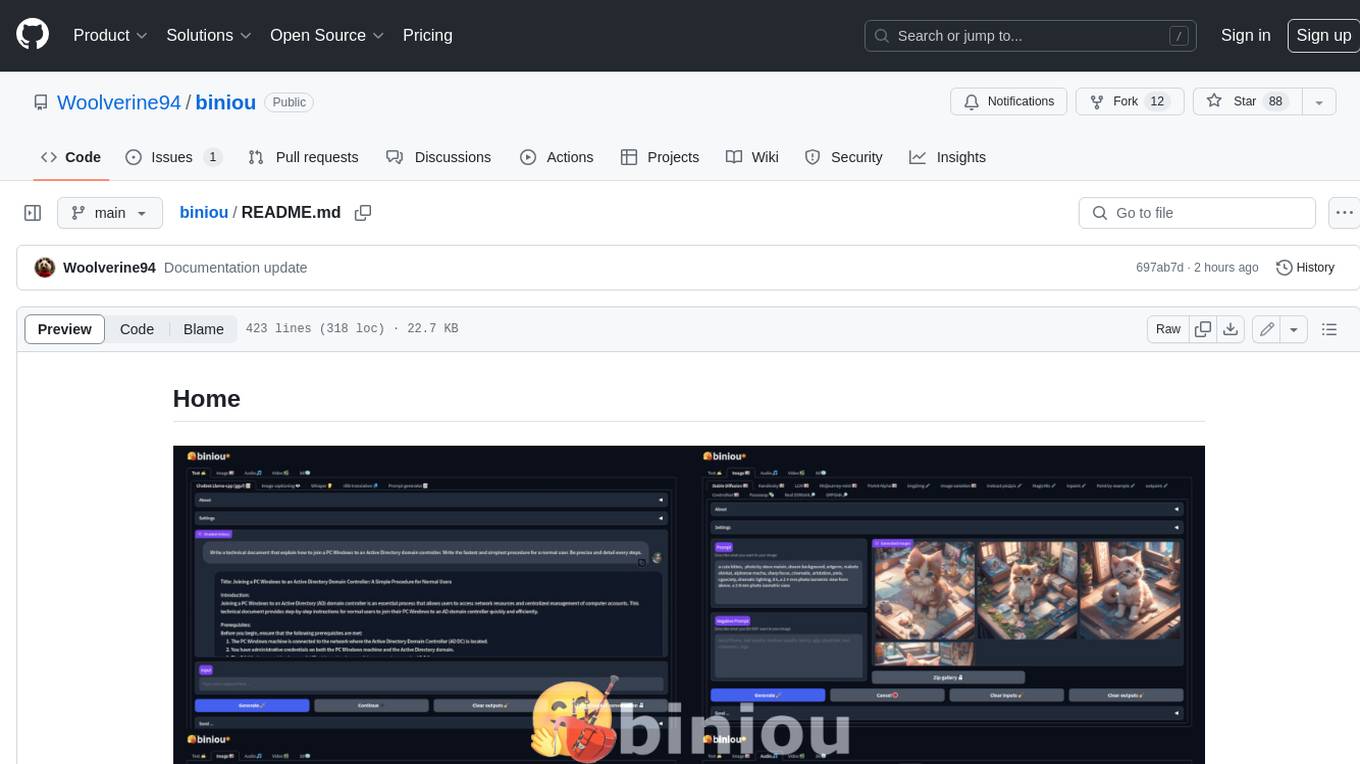
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
README:

![]()
![]()
biniou is a self-hosted webui for several kinds of GenAI (generative artificial intelligence). You can generate multimedia contents with AI and use a chatbot on your own computer, even without dedicated GPU and starting from 8GB RAM. Can work offline (once deployed and required models downloaded).
GNU/Linux base : [ OpenSUSE | RHEL | Arch | Mandriva | Debian ] • Windows • macOS Intel (experimental) • Docker Documentation ❓ | Showroom 🖼️ | Video presentation (by @Natlamir) 🎞️ | Windows install tutorial (by Fahd Mirza) 🎞️
-
🆕 2025-09-27 : 🔥 Weekly update 🔥 >
- Update of Chatbot specialized model Cydonia to bartowski/TheDrummer_Cydonia-ReduX-22B-v1-GGUF and update of chatbot model Magistral small to bartowski/mistralai_Magistral-Small-2509-GGUF.
- Add support for Llava model Steven0090/llava1.6-Mistral-7B-Instruct-v0.2-gguf.
- Add support for Flux model minpeter/FLUX-Hyperscale-fused.
- Add support for Audiogen model AkhilTolani/audiogen-v2.
- Add support for Flux LoRA models glif-loradex-trainer/Angelo-ec24_scifi_retro and tanzim1/Inkwatercolor.
-
🆕 2025-09-20 : 🔥 Weekly update 🔥 >
- Add support for Chatbot high-end model bartowski/baidu_ERNIE-4.5-21B-A3B-Thinking-GGUF and chatbot code specialized model unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF.
- Add support for Flux model AlekseyCalvin/FluxKrea_HSTurbo_Diffusers.
- Add support for SDXL model RunDiffusion/Juggernaut-XL-v6.
- Add support for Musicgen model pharoAIsanders420/musicgen-stereo-dub.
- Add support for Flux LoRA models WizWhite/wizard-s-acid-reflux and fofr/flux-cassette-futurism.
-
🆕 2025-09-13 : 🔥 Weekly update 🔥 >
- Add support for Chatbot high-end model bartowski/NousResearch_Hermes-4-14B-GGUF, chatbot specialized model bartowski/Aurore-Reveil_Koto-Small-7B-IT-GGUF and update of MiniCPM4-8B-GGUF to DevQuasar/openbmb.MiniCPM4.1-8B-GGUF.
- Add support for Flux LoRA models blurgy/CoMPaSS-FLUX.1 and saurabhswami/Tintincomicslora.
- Add support for Instruct pix2pix model Ekenayy/instruct-pix2pix-full.
- Add support for SDXL model John6666/stellaratormix-photorealism-v30-sdxl.
- Bugfix for workflow generating CUDA container.
- Bugfix and enhancement for Debian OCI installer.
-
🆕 2025-09-06 : 🔥 Weekly update 🔥 >
- Add support for Chatbot model bartowski/glm-4-9b-chat-abliterated-GGUF and Chatbot high-end model bartowski/TheDrummer_Skyfall-31B-v4-GGUF.
- Add support for Flux LoRA models nerijs/flux_prettyshot_v1, gokaygokay/Flux-2D-Game-Assets-LoRA, Kie-Fells/earl-moran-flux-32dim and UmeAiRT/FLUX.1-dev-LoRA-Romanticism.
- Update for new visual identity (dark theme).
- Update of technical stack : huggingface-hub 0.34.4, transformers 4.51.3, diffusers 0.34.0 and peft 0.17.1.
-
🆕 2025-08-30 : 🔥 Weekly update 🔥 >
- Add support for Chatbot model bartowski/tencent_Hunyuan-7B-Instruct-GGUF, update of models AceReason-Nemotron to bartowski/nvidia_AceReason-Nemotron-1.1-7B-GGUF and Cydonia to bartowski/TheDrummer_Cydonia-24B-v4.1-GGUF.
- Add support for SD 1.5 model stablediffusionapi/anything-v5
- Add support for Flux LoRA models Datou1111/Slow-Shutter, strangerzonehf/Flux-NFTv4-Designs-LoRA, tanzim1/WSJ-Hedcut, and prithivMLmods/Flux.1-Dev-Pov-DoorEye-LoRA.
- Modification of visual identity, by introducing a new logo for biniou.
• Features
• Prerequisites
• Installation
GNU/Linux
OpenSUSE Leap 15.5 / OpenSUSE Tumbleweed
Rocky 9.3+ / Alma 9.3+ / CentOS Stream 9 / Fedora 39+
CachyOS
OpenMandriva
Debian 12 / Ubuntu 22.04.3 / Ubuntu 24.04 / Linux Mint 21.2+ / Linux Mint 22+ / Pop! OS
Windows 10 / Windows 11
macOS Intel Homebrew install
Dockerfile
• CUDA support
• How To Use
• Good to know
• Credits
• License
-
Text generation using :
- ✍️ llama-cpp based chatbot module (uses .gguf models)
- 👁️ Llava multimodal chatbot module (uses .gguf models)
- 👁️ Microsoft GIT image captioning module
- 👂 Whisper speech-to-text module
- 👥 nllb translation module (200 languages)
- 📝 Prompt generator (require 16GB+ RAM for ChatGPT output type)
-
Image generation and modification using :
- 🖼️ Stable Diffusion module
- 🖼️ Kandinsky module (require 16GB+ RAM)
- 🖼️ Latent Consistency Models module
- 🖼️ Midjourney-mini module
- 🖼️PixArt-Alpha module
- 🖌️ Stable Diffusion Img2img module
- 🖌️ IP-Adapter module
- 🖼️ Stable Diffusion Image variation module (require 16GB+ RAM)
- 🖌️ Instruct Pix2Pix module
- 🖌️ MagicMix module
- 🖌️ Stable Diffusion Inpaint module
- 🖌️ Fantasy Studio Paint by Example module (require 16GB+ RAM)
- 🖌️ Stable Diffusion Outpaint module (require 16GB+ RAM)
- 🖼️ Stable Diffusion ControlNet module
- 🖼️ Photobooth module
- 🎭 Insight Face faceswapping module
- 🔎 Real ESRGAN upscaler module
- 🔎GFPGAN face restoration module
-
Audio generation using :
- 🎶 MusicGen module
- 🎶 MusicGen Melody module (require 16GB+ RAM)
- 🎶 MusicLDM module
- 🔊 Audiogen module (require 16GB+ RAM)
- 🔊 Harmonai module
- 🗣️ Bark module
-
Video generation and modification using :
- 📼 Modelscope module (require 16GB+ RAM)
- 📼 Text2Video-Zero module
- 📼 AnimateDiff module (require 16GB+ RAM)
- 📼 Stable Video Diffusion module (require 16GB+ RAM)
- 🖌️ Video Instruct-Pix2Pix module (require 16GB+ RAM)
-
3D objects generation using :
- 🧊 Shap-E txt2shape module
- 🧊 Shap-E img2shape module (require 16GB+ RAM)
-
Other features
- Zeroconf installation through one-click installers or Windows exe.
- User friendly : Everything required to run biniou is installed automatically, either at install time or at first use.
- WebUI in English, French, Chinese (traditional).
- Easy management through a control panel directly inside webui : update, restart, shutdown, activate authentication, control network access or share your instance online with a single click.
- Easy management of models through a simple interface.
- Communication between modules : send an output as an input to another module
- Powered by 🤗 Huggingface and gradio
- Cross platform : GNU/Linux, Windows 10/11 and macOS(experimental, via homebrew)
- Convenient Dockerfile for cloud instances
- Generation settings saved as metadatas in each content.
- Support for CUDA (see CUDA support)
- Experimental support for ROCm (see here)
- Support for Stable Diffusion SD-1.5, SD-2.1, SD-Turbo, SDXL, SDXL-Turbo, SDXL-Lightning, Hyper-SD, Stable Diffusion 3, SD 3.5 Medium and Large, LCM, VegaRT, Segmind, Playground-v2, Koala, Pixart-Alpha, Pixart-Sigma, Kandinsky, Flux Dev, Flux Schnell, Flux Lite and compatible models, through built-in model list or standalone .safetensors files
- Support for LoRA models (SD 1.5, SDXL, SD 3.5 medium, SD 3.5 large and Flux)
- Support for textual inversion
- Support llama-cpp-python optimizations CUDA, OpenBLAS, OpenCL BLAS, ROCm and Vulkan through a simple setting
- Support for gpt-oss, Llama 2/3, Mistral, Mixtral, Qwen 2/3, Deepseek, Gemma, and compatible GGUF quantized models, through built-in model list or standalone .gguf files.
- Easy copy/paste integration for TheBloke GGUF quantized models.
-
Minimal hardware :
- 64bit CPU (AMD64 architecture ONLY)
- 8GB RAM
- Storage requirements :
- for GNU/Linux : at least 20GB for installation without models.
- for Windows : at least 30GB for installation without models.
- for macOS : at least ??GB for installation without models.
- Storage type : HDD
- Internet access (required only for installation and models download) : unlimited bandwidth optical fiber internet access
-
Recommended hardware :
- Massively multicore 64bit CPU (AMD64 architecture ONLY) and a GPU compatible with CUDA or ROCm
- 16GB+ RAM
- Storage requirements :
- for GNU/Linux : around 200GB for installation including all defaults models.
- for Windows : around 200GB for installation including all defaults models.
- for macOS : around ??GB for installation including all defaults models.
- Storage type : SSD Nvme
- Internet access (required only for installation and models download) : unlimited bandwidth optical fiber internet access
-
Operating system :
- a 64 bit OS :
- Debian 12
- Ubuntu 22.04.3 / 24.04
- Linux Mint 21.2+ / 22+
- Pop! OS
- Rocky 9.3+
- Alma 9.3+
- CentOS Stream 9
- Fedora 39+
- OpenSUSE Leap 15.5
- OpenSUSE Tumbleweed
- CachyOS
- OpenMandriva
- Windows 10 22H2
- Windows 11 22H2
- macOS ???
- a 64 bit OS :
-
Software pre-requisites (will be installed automatically with install scripts) :
- Python 3.10 or 3.11 (3.11+ wouldn't work)
- git
- pip
- python3.x-venv
- python3.x-dev
- gcc
- perl
- make / Cmake via Visual Studio 2017 for Windows
- ffmpeg
- openssl
Note : biniou supports Cuda or ROCm but does not require a dedicated GPU to run. You can install it in a virtual machine.
- Copy/paste and execute the following command in a terminal :
sh <(curl https://raw.githubusercontent.com/Woolverine94/biniou/main/oci-opensuse.sh || wget -O - https://raw.githubusercontent.com/Woolverine94/biniou/main/oci-opensuse.sh)- Copy/paste and execute the following command in a terminal :
sh <(curl https://raw.githubusercontent.com/Woolverine94/biniou/main/oci-rhel.sh || wget -O - https://raw.githubusercontent.com/Woolverine94/biniou/main/oci-rhel.sh)- Copy/paste and execute the following command in a terminal :
sh (curl https://raw.githubusercontent.com/Woolverine94/biniou/main/oci-arch.sh|psub)- Copy/paste and execute the following command in a terminal :
sh <(curl https://raw.githubusercontent.com/Woolverine94/biniou/main/oci-mandriva.sh || wget -O - https://raw.githubusercontent.com/Woolverine94/biniou/main/oci-mandriva.sh)- Copy/paste and execute the following command in a terminal :
sh <(curl https://raw.githubusercontent.com/Woolverine94/biniou/main/oci-debian.sh || wget -O - https://raw.githubusercontent.com/Woolverine94/biniou/main/oci-debian.sh)- Install the pre-requisites as root :
apt install git pip python3 python3-venv gcc perl make ffmpeg openssl- Clone this repository as user :
git clone https://github.com/Woolverine94/biniou.git- Launch the installer :
cd ./biniou
./install.sh- (optional, but highly recommended) Install TCMalloc as root to optimize memory management :
apt install google-perftoolsWindows installation has more prerequisites than GNU/Linux one, and requires following softwares (which will be installed automatically) :
- Git
- Python 3.11 (and specifically 3.11 version)
- OpenSSL
- Visual Studio Build tools
- Windows 10/11 SDK
- Vcredist
- ffmpeg
- ... and all their dependencies.
It's a lot of changes on your operating system, and this could potentially bring unwanted behaviors on your system, depending on which softwares are already installed on it.
-
Download and execute : biniou_netinstall.exe
OR
-
Download and execute : install_win.cmd (right-click on the link and select "Save Target/Link as ..." to download)
All the installation is automated, but Windows UAC will ask you for confirmation for each software installed during the "prerequisites" phase. You can avoid this by running the chosen installer as administrator.
install_win.cmd
Proceed as follow :
- Download and edit install_win.cmd
- Modify
set DEFAULT_BINIOU_DIR="%userprofile%"toset DEFAULT_BINIOU_DIR="E:\datas\somedir"(for example) - Only use absolute path (e.g.:
E:\datas\somedirand not.\datas\somedir) - Don't add a trailing slash (e.g.:
E:\datas\somedirand notE:\datas\somedir\) - Don't add a "biniou" suffix to your path (e.g.:
E:\datas\somedir\biniou), as the biniou directory will be created by the git clone command - Save and launch install_win.cmd
-
Install Homebrew for your operating system
-
Install required homebrew "bottles" :
brew install git python3 gcc gcc@11 perl make ffmpeg openssl- Install python virtualenv :
python3 -m pip install virtualenv- Clone this repository as user :
git clone https://github.com/Woolverine94/biniou.git- Launch the installer :
cd ./biniou
./install.shThese instructions assumes that you already have a configured and working docker environment.
- Create the docker image :
docker build -t biniou https://github.com/Woolverine94/biniou.gitor, for CUDA support :
docker build -t biniou https://raw.githubusercontent.com/Woolverine94/biniou/main/CUDA/DockerfileAlternatively, you can directly pull a weekly updated image from ghcr.io using :
docker pull ghcr.io/woolverine94/biniou:mainor, for CUDA support :
docker pull ghcr.io/woolverine94/biniou-cuda:main- Launch the container :
- For Dockerfile generated images :
docker run -it --restart=always -p 7860:7860 \
-v biniou_outputs:/home/biniou/biniou/outputs \
-v biniou_models:/home/biniou/biniou/models \
-v biniou_cache:/home/biniou/.cache/huggingface \
-v biniou_gfpgan:/home/biniou/biniou/gfpgan \
biniou:latestor, with CUDA support :
docker run -it --gpus all --restart=always -p 7860:7860 \
-v biniou_outputs:/home/biniou/biniou/outputs \
-v biniou_models:/home/biniou/biniou/models \
-v biniou_cache:/home/biniou/.cache/huggingface \
-v biniou_gfpgan:/home/biniou/biniou/gfpgan \
biniou:latest- For docker images pulled from ghcr.io :
docker run -it --restart=always -p 7860:7860 \
-v biniou_outputs:/home/biniou/biniou/outputs \
-v biniou_models:/home/biniou/biniou/models \
-v biniou_cache:/home/biniou/.cache/huggingface \
-v biniou_gfpgan:/home/biniou/biniou/gfpgan \
ghcr.io/woolverine94/biniou:mainor, with CUDA support :
docker run -it --gpus all --restart=always -p 7860:7860 \
-v biniou_outputs:/home/biniou/biniou/outputs \
-v biniou_models:/home/biniou/biniou/models \
-v biniou_cache:/home/biniou/.cache/huggingface \
-v biniou_gfpgan:/home/biniou/biniou/gfpgan \
ghcr.io/woolverine94/biniou-cuda:main-
Access the webui by the url :
https://127.0.0.1:7860 or https://127.0.0.1:7860/?__theme=dark for dark theme
... or replace 127.0.0.1 by ip of your container
Note : to save storage space, the previous container launch command defines common shared volumes for all biniou containers and ensure that the container auto-restart in case of OOM crash. Remove
--restartand-varguments if you didn't want these behaviors.
biniou is natively cpu-only, to ensure compatibility with a wide range of hardware, but you can easily activate CUDA support through Nvidia CUDA (if you have a functional CUDA 12.1 environment) or AMD ROCm (if you have a functional ROCm 5.6 environment) by selecting the type of optimization to activate (CPU, CUDA or ROCm for Linux), in the WebUI control module.
Currently, all modules except Chatbot, Llava and faceswap modules, could benefits from CUDA optimization.
- Launch by executing from the biniou directory :
- for GNU/Linux :
cd /home/$USER/biniou
./webui.sh- for Windows :
Double-click webui.cmd in the biniou directory (C:\Users\%username%\biniou\). When asked by the UAC, configure the firewall according to your network type to authorize access to the webui
Note : First start could be very slow on Windows 11 (comparing to others OS).
-
Access the webui by the url :
https://127.0.0.1:7860 or https://127.0.0.1:7860/?__theme=dark for dark theme
You can also access biniou from any device (including smartphones) on the same LAN/Wifi network by replacing 127.0.0.1 in the url with biniou host ip address. -
Quit by using the keyboard shortcut CTRL+C in the Terminal
-
Update this application (biniou + python virtual environment) by using the WebUI control updates options.
-
Most frequent cause of crash is not enough memory on the host. Symptom is biniou program closing and returning to/closing the terminal without specific error message. You can use biniou with 8GB RAM, but 16GB at least is recommended to avoid OOM (out of memory) error.
-
biniou use a lot of differents AI models, which requires a lot of space : if you want to use all the modules in biniou, you will need around 200GB of disk space only for the default model of each module. Models are downloaded on the first run of each module or when you select a new model in a module and generate content. Models are stored in the directory /models of the biniou installation. Unused models could be deleted to save some space.
-
... consequently, you will need a fast internet access to download models.
-
A backup of every content generated is available inside the /outputs directory of the biniou folder.
-
biniou natively only rely on CPU for all operations. It use a specific CPU-only version of PyTorch. The result is a better compatibility with a wide range of hardware, but degraded performances. Depending on your hardware, expect slowness. See here for Nvidia CUDA support and AMD ROCm experimental support (GNU/Linux only).
-
Defaults settings are selected to permit generation of contents on low-end computers, with the best ratio performance/quality. If you have a configuration above the minimal settings, you could try using other models, increasing media dimensions or duration, modifying inference parameters or other settings (like token merging for images) to obtain better quality contents.
-
biniou is licensed under GNU GPL3, but each model used in biniou has its own license. Please consult each model license to know what you can and cannot do with the models. For each model, you can find a link to the huggingface page of the model in the "About" section of the associated module.
-
Don't have too much expectations : biniou is in an early stage of development, and most open source software used in it are in development (some are still experimental).
-
Every biniou modules offers 2 accordions elements About and Settings :
- About is a quick help feature that describes the module and gives instructions and tips on how to use it.
- Settings is a panel setting specific to the module that lets you configure the generation parameters.
This application uses the following softwares and technologies :
- 🤗 Huggingface : Diffusers and Transformers libraries and almost all the generative models.
- Gradio : webUI
- llama-cpp-python : python bindings for llama-cpp
- Llava
- BakLLava
- Microsoft GIT : Image2text
- Whisper : speech2text
- nllb translation : language translation
- Stable Diffusion : txt2img, img2img, Image variation, inpaint, ControlNet, Text2Video-Zero, img2vid
- Kandinsky : txt2img
- Latent consistency models : txt2img
- PixArt-Alpha : PixArt-Alpha
- IP-Adapter : IP-Adapter img2img
- Instruct pix2pix : pix2pix
- MagicMix : MagicMix
- Fantasy Studio Paint by Example : paintbyex
- Controlnet Auxiliary models : preview models for ControlNet module
- IP-Adapter FaceID : Adapter model for Photobooth module
- Photomaker Adapter model for Photobooth module
- Insight Face : faceswapping
- Real ESRGAN : upscaler
- GFPGAN : face restoration
- Audiocraft : musicgen, musicgen melody, audiogen
- MusicLDM : MusicLDM
- Harmonai : harmonai
- Bark : text2speech
- Modelscope text-to-video-synthesis : txt2vid
- AnimateLCM : txt2vid
- Open AI Shap-E : txt2shape, img2shape
-
compel : Prompt enhancement for various
StableDiffusionPipeline-based modules -
tomesd : Token merging for various
StableDiffusionPipeline-based modules - Python
- PyTorch
- Git
- ffmpeg
... and all their dependencies
GNU General Public License v3.0
GitHub @Woolverine94 ·
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for biniou
Similar Open Source Tools
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.

mini-sglang
Mini-SGLang is a lightweight yet high-performance inference framework for Large Language Models. With a compact codebase of ~5,000 lines of Python, it serves as both a capable inference engine and a transparent reference for researchers and developers. It achieves state-of-the-art throughput and latency with advanced optimizations such as Radix Cache, Chunked Prefill, Overlap Scheduling, Tensor Parallelism, and Optimized Kernels integrating FlashAttention and FlashInfer for maximum efficiency. Mini-SGLang is designed to demystify the complexities of modern LLM serving systems, providing a clean, modular, and fully type-annotated codebase that is easy to understand and modify.
jan
Jan is an open-source ChatGPT alternative that runs 100% offline on your computer. It supports universal architectures, including Nvidia GPUs, Apple M-series, Apple Intel, Linux Debian, and Windows x64. Jan is currently in development, so expect breaking changes and bugs. It is lightweight and embeddable, and can be used on its own within your own projects.
llama-assistant
Llama Assistant is an AI-powered assistant that helps with daily tasks, such as voice recognition, natural language processing, summarizing text, rephrasing sentences, answering questions, and more. It runs offline on your local machine, ensuring privacy by not sending data to external servers. The project is a work in progress with regular feature additions.
llama-assistant
Llama Assistant is a local AI assistant that respects your privacy. It is an AI-powered assistant that can recognize your voice, process natural language, and perform various actions based on your commands. It can help with tasks like summarizing text, rephrasing sentences, answering questions, writing emails, and more. The assistant runs offline on your local machine, ensuring privacy by not sending data to external servers. It supports voice recognition, natural language processing, and customizable UI with adjustable transparency. The project is a work in progress with new features being added regularly.
automatic
Automatic is an Image Diffusion implementation with advanced features. It supports multiple diffusion models, built-in control for text, image, batch, and video processing, and is compatible with various platforms and backends. The tool offers optimized processing with the latest torch developments, built-in support for torch.compile, and multiple compile backends. It also features platform-specific autodetection, queue management, enterprise-level logging, and a built-in installer with automatic updates and dependency management. Automatic is mobile compatible and provides a main interface using StandardUI and ModernUI.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
ComfyUI-fal-API
ComfyUI-fal-API is a repository containing custom nodes for using Flux models with fal API in ComfyUI. It provides nodes for image generation, video generation, language models, and vision language models. Users can easily install and configure the repository to access various nodes for different tasks such as generating images, creating videos, processing text, and understanding images. The repository also includes troubleshooting steps and is licensed under the Apache License 2.0.

LynxHub
LynxHub is a platform that allows users to seamlessly install, configure, launch, and manage all their AI interfaces from a single, intuitive dashboard. It offers features like AI interface management, arguments manager, custom run commands, pre-launch actions, extension management, in-app tools like terminal and web browser, AI information dashboard, Discord integration, and additional features like theme options and favorite interface pinning. The platform supports modular design for custom AI modules and upcoming extensions system for complete customization. LynxHub aims to streamline AI workflow and enhance user experience with a user-friendly interface and comprehensive functionalities.
Roo-Code
Roo Code is an AI-powered development tool that integrates with your code editor to help you generate code from natural language descriptions and specifications, refactor and debug existing code, write and update documentation, answer questions about your codebase, automate repetitive tasks, and utilize MCP servers. It offers different modes such as Code, Architect, Ask, Debug, and Custom Modes to adapt to various tasks and workflows. Roo Code provides tutorial and feature videos, documentation, a YouTube channel, a Discord server, a Reddit community, GitHub issues tracking, and a feature request platform. Users can set up and develop Roo Code locally by cloning the repository, installing dependencies, and running the extension in development mode or by automated/manual VSIX installation. The tool uses changesets for versioning and publishing. Please note that Roo Code, Inc. does not make any representations or warranties regarding the tools provided, and users assume all risks associated with their use.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
tingly-box
Tingly Box is a tool that helps in deciding which model to call, compressing context, and routing requests efficiently. It offers secure, reliable, and customizable functional extensions. With features like unified API, smart routing, context compression, auto API translation, blazing fast performance, flexible authentication, visual control panel, and client-side usage stats, Tingly Box provides a comprehensive solution for managing AI models and tokens. It supports integration with various IDEs, CLI tools, SDKs, and AI applications, making it versatile and easy to use. The tool also allows seamless integration with OAuth providers like Claude Code, enabling users to utilize existing quotas in OpenAI-compatible tools. Tingly Box aims to simplify AI model management and usage by providing a single endpoint for multiple providers with minimal configuration, promoting seamless integration with SDKs and CLI tools.
openchamber
OpenChamber is a web and desktop interface for the OpenCode AI coding agent, designed to work alongside the OpenCode TUI. The project was built entirely with AI coding agents under supervision, serving as a proof of concept that AI agents can create usable software. It offers features like integrated terminal, Git operations with AI commit message generation, smart tool visualization, permission management, multi-agent runs, task tracker UI, model selection UX, UI scaling controls, session auto-cleanup, and memory optimizations. OpenChamber provides cross-device continuity, remote access, and a visual alternative for developers preferring GUI workflows.
sdnext
SD.Next is an Image Diffusion implementation with advanced features. It offers multiple UI options, diffusion models, and built-in controls for text, image, batch, and video processing. The tool is multiplatform, supporting Windows, Linux, MacOS, nVidia, AMD, IntelArc/IPEX, DirectML, OpenVINO, ONNX+Olive, and ZLUDA. It provides optimized processing with the latest torch developments, including model compile, quantize, and compress functionalities. SD.Next also features Interrogate/Captioning with various models, queue management, automatic updates, and mobile compatibility.

AionUi
AionUi is a user interface library for building modern and responsive web applications. It provides a set of customizable components and styles to create visually appealing user interfaces. With AionUi, developers can easily design and implement interactive web interfaces that are both functional and aesthetically pleasing. The library is built using the latest web technologies and follows best practices for performance and accessibility. Whether you are working on a personal project or a professional application, AionUi can help you streamline the UI development process and deliver a seamless user experience.
For similar tasks
Awesome-AITools
This repo collects AI-related utilities. ## All Categories * All Categories * ChatGPT and other closed-source LLMs * AI Search engine * Open Source LLMs * GPT/LLMs Applications * LLM training platform * Applications that integrate multiple LLMs * AI Agent * Writing * Programming Development * Translation * AI Conversation or AI Voice Conversation * Image Creation * Speech Recognition * Text To Speech * Voice Processing * AI generated music or sound effects * Speech translation * Video Creation * Video Content Summary * OCR(Optical Character Recognition)

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
generative-ai-js
Generative AI JS is a JavaScript library that provides tools for creating generative art and music using artificial intelligence techniques. It allows users to generate unique and creative content by leveraging machine learning models. The library includes functions for generating images, music, and text based on user input and preferences. With Generative AI JS, users can explore the intersection of art and technology, experiment with different creative processes, and create dynamic and interactive content for various applications.
pictureChange
The 'pictureChange' repository is a plugin that supports image processing using Baidu AI, stable diffusion webui, and suno music composition AI. It also allows for file summarization and image summarization using AI. The plugin supports various stable diffusion models, administrator control over group chat features, concurrent control, and custom templates for image and text generation. It can be deployed on WeChat enterprise accounts, personal accounts, and public accounts.
Generative-AI-Indepth-Basic-to-Advance
Generative AI Indepth Basic to Advance is a repository focused on providing tutorials and resources related to generative artificial intelligence. The repository covers a wide range of topics from basic concepts to advanced techniques in the field of generative AI. Users can find detailed explanations, code examples, and practical demonstrations to help them understand and implement generative AI algorithms. The goal of this repository is to help beginners get started with generative AI and to provide valuable insights for more experienced practitioners.
nodetool
NodeTool is a platform designed for AI enthusiasts, developers, and creators, providing a visual interface to access a variety of AI tools and models. It simplifies access to advanced AI technologies, offering resources for content creation, data analysis, automation, and more. With features like a visual editor, seamless integration with leading AI platforms, model manager, and API integration, NodeTool caters to both newcomers and experienced users in the AI field.
ai-enhanced-audio-book
The ai-enhanced-audio-book repository contains AI-enhanced audio plugins developed using C++, JUCE, libtorch, RTNeural, and other libraries. It showcases neural networks learning to emulate guitar amplifiers through waveforms. Users can visit the official website for more information and obtain a copy of the book from the publisher Taylor and Francis/ Routledge/ Focal.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.