
llm-interface
A simple NPM interface for seamlessly interacting with 36 Large Language Model (LLM) providers, including OpenAI, Anthropic, Google Gemini, Cohere, Hugging Face Inference, NVIDIA AI, Mistral AI, AI21 Studio, LLaMA.CPP, and Ollama, and hundreds of models.
Stars: 92
LLM Interface is an npm module that streamlines interactions with various Large Language Model (LLM) providers in Node.js applications. It offers a unified interface for switching between providers and models, supporting 36 providers and hundreds of models. Features include chat completion, streaming, error handling, extensibility, response caching, retries, JSON output, and repair. The package relies on npm packages like axios, @google/generative-ai, dotenv, jsonrepair, and loglevel. Installation is done via npm, and usage involves sending prompts to LLM providers. Tests can be run using npm test. Contributions are welcome under the MIT License.
README:



LLM Interface is an npm module that streamlines your interactions with various Large Language Model (LLM) providers in your Node.js applications. It offers a unified interface, simplifying the process of switching between providers and their models.
The LLM Interface package offers comprehensive support for a wide range of language model providers, encompassing 36 different providers and hundreds of models. This extensive coverage ensures that you have the flexibility to choose the best models suited to your specific needs.
LLM Interface supports: AI21 Studio, AiLAYER, AIMLAPI, Anyscale, Anthropic, Cloudflare AI, Cohere, Corcel, DeepInfra, DeepSeek, Fireworks AI, Forefront AI, FriendliAI, Google Gemini, GooseAI, Groq, Hugging Face Inference, HyperBee AI, Lamini, LLaMA.CPP, Mistral AI, Monster API, Neets.ai, Novita AI, NVIDIA AI, OctoAI, Ollama, OpenAI, Perplexity AI, Reka AI, Replicate, Shuttle AI, TheB.ai, Together AI, Voyage AI, Watsonx AI, Writer, and Zhipu AI.
-
Unified Interface:
LLMInterface.sendMessageis a single, consistent interface to interact with 36 different LLM APIs (34 hosted LLM providers and 2 local LLM providers). - Chat Completion, Streaming and Embeddings: Supports chat completion, streaming, and embeddings (with failover).
- Dynamic Module Loading: Automatically loads and manages LLM interfaces only when they are invoked, minimizing resource usage.
- Error Handling: Robust error handling mechanisms to ensure reliable API interactions.
- Extensible: Easily extendable to support additional LLM providers as needed.
- Response Caching: Efficiently caches LLM responses to reduce costs and enhance performance.
- Graceful Retries: Automatically retry failed prompts with increasing delays to ensure successful responses.
- JSON Output: Simple to use native JSON output for various LLM providers including OpenAI, Fireworks AI, Google Gemini, and more.
- JSON Repair: Detect and repair invalid JSON responses.
v2.0.14
- Recovery Mode (Beta): Automatically repair invalid JSON objects in HTTP 400 response errors. Currently, this feature is only available with Groq.
v2.0.11
- New LLM Providers: Anyscale, Bigmodel, Corcel, Deepseek, Hyperbee AI, Lamini, Neets AI, Novita AI, NVIDIA, Shuttle AI, TheB.AI, and Together AI.
-
Caching: Supports multiple caches:
simple-cache,flat-cache, andcache-manager.flat-cacheis now an optional package. -
Logging: Improved logging with the
loglevel. - Improved Documentation: Improved documentation with new examples, glossary, and provider details. Updated API key details, model alias breakdown, and usage information.
- More Examples: LangChain.js RAG, Mixture-of-Agents (MoA), and more.
-
Removed Dependency:
@anthropic-ai/sdkis no longer required.
The project relies on several npm packages and APIs. Here are the primary dependencies:
-
axios: For making HTTP requests (used for various HTTP AI APIs). -
@google/generative-ai: SDK for interacting with the Google Gemini API. -
dotenv: For managing environment variables. Used by test cases. -
jsonrepair: Used to repair invalid JSON responses. -
loglevel: A minimal, lightweight logging library with level-based logging and filtering.
The following optional packages can added to extend LLMInterface's caching capabilities:
-
flat-cache: A simple JSON based cache. -
cache-manager: An extendible cache module that supports various backends including Redis, MongoDB, File System, Memcached, Sqlite, and more.
To install the LLM Interface npm module, you can use npm:
npm install llm-interface- Looking for API Keys? This document provides helpful links.
- Detailed usage documentation is available here.
- Various examples are also available to help you get started.
- A breakdown of model aliases is available here.
- A breakdown of embeddings model aliases is available here.
- If you still want more examples, you may wish to review the test cases for further examples.
First import LLMInterface. You can do this using either the CommonJS require syntax:
const { LLMInterface } = require('llm-interface');then send your prompt to the LLM provider:
LLMInterface.setApiKey({ openai: process.env.OPENAI_API_KEY });
try {
const response = await LLMInterface.sendMessage(
'openai',
'Explain the importance of low latency LLMs.',
);
} catch (error) {
console.error(error);
}if you prefer, you can pass use a one-liner to pass the provider and API key, essentially skipping the LLMInterface.setApiKey() step.
const response = await LLMInterface.sendMessage(
['openai', process.env.OPENAI_API_KEY],
'Explain the importance of low latency LLMs.',
);Passing a more complex message object is just as simple. The same rules apply:
const message = {
model: 'gpt-4o-mini',
messages: [
{ role: 'system', content: 'You are a helpful assistant.' },
{ role: 'user', content: 'Explain the importance of low latency LLMs.' },
],
};
try {
const response = await LLMInterface.sendMessage('openai', message, {
max_tokens: 150,
});
} catch (error) {
console.error(error);
}LLMInterfaceSendMessage and LLMInterfaceStreamMessage are still available and will be available until version 3
The project includes tests for each LLM handler. To run the tests, use the following command:
npm testTest Suites: 9 skipped, 93 passed, 93 of 102 total
Tests: 86 skipped, 784 passed, 870 total
Snapshots: 0 total
Time: 630.029 sNote: Currently skipping NVIDIA test cases due to API issues, and Ollama due to performance issues.
- [ ] Provider > Models > Azure AI
- [ ] Provider > Models > Grok
- [ ] Provider > Models > SiliconFlow
- [ ] Provider > Embeddings > Nomic
- [ ] Feature > Image Generation?
Submit your suggestions!
Contributions to this project are welcome. Please fork the repository and submit a pull request with your changes or improvements.
This project is licensed under the MIT License - see the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-interface
Similar Open Source Tools
llm-interface
LLM Interface is an npm module that streamlines interactions with various Large Language Model (LLM) providers in Node.js applications. It offers a unified interface for switching between providers and models, supporting 36 providers and hundreds of models. Features include chat completion, streaming, error handling, extensibility, response caching, retries, JSON output, and repair. The package relies on npm packages like axios, @google/generative-ai, dotenv, jsonrepair, and loglevel. Installation is done via npm, and usage involves sending prompts to LLM providers. Tests can be run using npm test. Contributions are welcome under the MIT License.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
mem0
Mem0 is a tool that provides a smart, self-improving memory layer for Large Language Models, enabling personalized AI experiences across applications. It offers persistent memory for users, sessions, and agents, self-improving personalization, a simple API for easy integration, and cross-platform consistency. Users can store memories, retrieve memories, search for related memories, update memories, get the history of a memory, and delete memories using Mem0. It is designed to enhance AI experiences by enabling long-term memory storage and retrieval.
tingly-box
Tingly Box is a tool that helps in deciding which model to call, compressing context, and routing requests efficiently. It offers secure, reliable, and customizable functional extensions. With features like unified API, smart routing, context compression, auto API translation, blazing fast performance, flexible authentication, visual control panel, and client-side usage stats, Tingly Box provides a comprehensive solution for managing AI models and tokens. It supports integration with various IDEs, CLI tools, SDKs, and AI applications, making it versatile and easy to use. The tool also allows seamless integration with OAuth providers like Claude Code, enabling users to utilize existing quotas in OpenAI-compatible tools. Tingly Box aims to simplify AI model management and usage by providing a single endpoint for multiple providers with minimal configuration, promoting seamless integration with SDKs and CLI tools.

deepchat
DeepChat is a versatile chat tool that supports multiple model cloud services and local model deployment. It offers multi-channel chat concurrency support, platform compatibility, complete Markdown rendering, and easy usability with a comprehensive guide. The tool aims to enhance chat experiences by leveraging various AI models and ensuring efficient conversation management.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

executorch
ExecuTorch is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch Edge ecosystem and enables efficient deployment of PyTorch models to edge devices. Key value propositions of ExecuTorch are: * **Portability:** Compatibility with a wide variety of computing platforms, from high-end mobile phones to highly constrained embedded systems and microcontrollers. * **Productivity:** Enabling developers to use the same toolchains and SDK from PyTorch model authoring and conversion, to debugging and deployment to a wide variety of platforms. * **Performance:** Providing end users with a seamless and high-performance experience due to a lightweight runtime and utilizing full hardware capabilities such as CPUs, NPUs, and DSPs.
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.
local-cocoa
Local Cocoa is a privacy-focused tool that runs entirely on your device, turning files into memory to spark insights and power actions. It offers features like fully local privacy, multimodal memory, vector-powered retrieval, intelligent indexing, vision understanding, hardware acceleration, focused user experience, integrated notes, and auto-sync. The tool combines file ingestion, intelligent chunking, and local retrieval to build a private on-device knowledge system. The ultimate goal includes more connectors like Google Drive integration, voice mode for local speech-to-text interaction, and a plugin ecosystem for community tools and agents. Local Cocoa is built using Electron, React, TypeScript, FastAPI, llama.cpp, and Qdrant.
superagentx
SuperAgentX is a lightweight open-source AI framework designed for multi-agent applications with Artificial General Intelligence (AGI) capabilities. It offers goal-oriented multi-agents with retry mechanisms, easy deployment through WebSocket, RESTful API, and IO console interfaces, streamlined architecture with no major dependencies, contextual memory using SQL + Vector databases, flexible LLM configuration supporting various Gen AI models, and extendable handlers for integration with diverse APIs and data sources. It aims to accelerate the development of AGI by providing a powerful platform for building autonomous AI agents capable of executing complex tasks with minimal human intervention.

sdk-typescript
Strands Agents - TypeScript SDK is a lightweight and flexible SDK that takes a model-driven approach to building and running AI agents in TypeScript/JavaScript. It brings key features from the Python Strands framework to Node.js environments, enabling type-safe agent development for various applications. The SDK supports model agnostic development with first-class support for Amazon Bedrock and OpenAI, along with extensible architecture for custom providers. It also offers built-in MCP support, real-time response streaming, extensible hooks, and conversation management features. With tools for interaction with external systems and seamless integration with MCP servers, the SDK provides a comprehensive solution for developing AI agents.

InsForge
InsForge is a backend development platform designed for AI coding agents and AI code editors. It serves as a semantic layer that enables agents to interact with backend primitives such as databases, authentication, storage, and functions in a meaningful way. The platform allows agents to fetch backend context, configure primitives, and inspect backend state through structured schemas. InsForge facilitates backend context engineering for AI coding agents to understand, operate, and monitor backend systems effectively.
chatbox
Chatbox is a desktop client for ChatGPT, Claude, and other LLMs, providing a user-friendly interface for AI copilot assistance on Windows, Mac, and Linux. It offers features like local data storage, multiple LLM provider support, image generation with Dall-E-3, enhanced prompting, keyboard shortcuts, and more. Users can collaborate, access the tool on various platforms, and enjoy multilingual support. Chatbox is constantly evolving with new features to enhance the user experience.
deepchecks
Deepchecks is a holistic open-source solution for AI & ML validation needs, enabling thorough testing of data and models from research to production. It includes components for testing, CI & testing management, and monitoring. Users can install and use Deepchecks for testing and monitoring their AI models, with customizable checks and suites for tabular, NLP, and computer vision data. The tool provides visual reports, pythonic/json output for processing, and a dynamic UI for collaboration and monitoring. Deepchecks is open source, with premium features available under a commercial license for monitoring components.
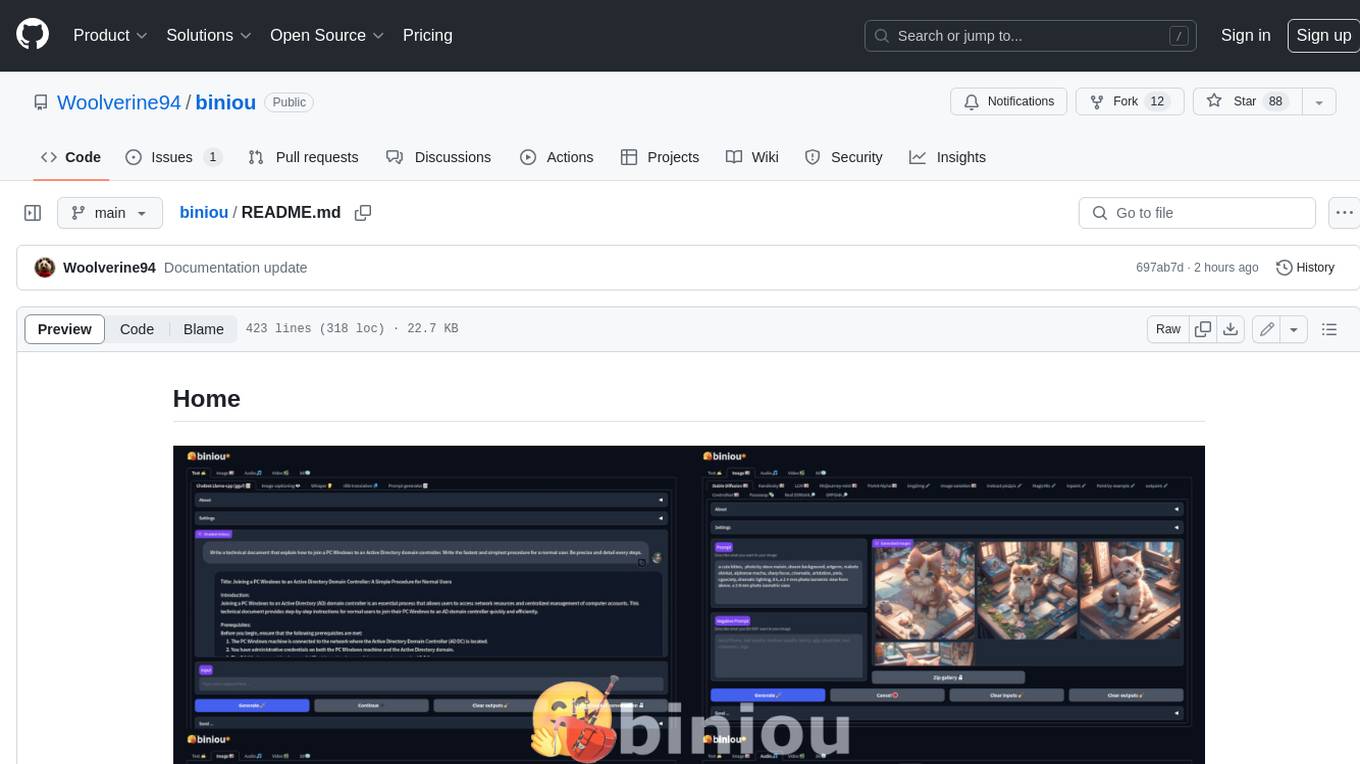
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
For similar tasks
llm-interface
LLM Interface is an npm module that streamlines interactions with various Large Language Model (LLM) providers in Node.js applications. It offers a unified interface for switching between providers and models, supporting 36 providers and hundreds of models. Features include chat completion, streaming, error handling, extensibility, response caching, retries, JSON output, and repair. The package relies on npm packages like axios, @google/generative-ai, dotenv, jsonrepair, and loglevel. Installation is done via npm, and usage involves sending prompts to LLM providers. Tests can be run using npm test. Contributions are welcome under the MIT License.
semantic-router
Semantic Router is a superfast decision-making layer for your LLMs and agents. Rather than waiting for slow LLM generations to make tool-use decisions, we use the magic of semantic vector space to make those decisions — _routing_ our requests using _semantic_ meaning.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.
luna-ai
Luna AI is a virtual streamer driven by a 'brain' composed of ChatterBot, GPT, Claude, langchain, chatglm, text-generation-webui, 讯飞星火, 智谱AI. It can interact with viewers in real-time during live streams on platforms like Bilibili, Douyin, Kuaishou, Douyu, or chat with you locally. Luna AI uses natural language processing and text-to-speech technologies like Edge-TTS, VITS-Fast, elevenlabs, bark-gui, VALL-E-X to generate responses to viewer questions and can change voice using so-vits-svc, DDSP-SVC. It can also collaborate with Stable Diffusion for drawing displays and loop custom texts. This project is completely free, and any identical copycat selling programs are pirated, please stop them promptly.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

cria
Cria is a Python library designed for running Large Language Models with minimal configuration. It provides an easy and concise way to interact with LLMs, offering advanced features such as custom models, streams, message history management, and running multiple models in parallel. Cria simplifies the process of using LLMs by providing a straightforward API that requires only a few lines of code to get started. It also handles model installation automatically, making it efficient and user-friendly for various natural language processing tasks.

beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.