
easy-dataset
A powerful tool for creating fine-tuning datasets for LLM
Stars: 10963

Easy Dataset is a specialized application designed to streamline the creation of fine-tuning datasets for Large Language Models (LLMs). It offers an intuitive interface for uploading domain-specific files, intelligently splitting content, generating questions, and producing high-quality training data for model fine-tuning. With Easy Dataset, users can transform domain knowledge into structured datasets compatible with all OpenAI-format compatible LLM APIs, making the fine-tuning process accessible and efficient.
README:






A powerful tool for creating fine-tuning datasets for Large Language Models
Features • Quick Start • Documentation • Contributing • License
If you like this project, please give it a Star⭐️, or buy the author a coffee => Donate ❤️!
{kind=link}
Easy Dataset is an application specifically designed for creating fine-tuning datasets for Large Language Models (LLMs). It provides an intuitive interface for uploading domain-specific files, intelligently splitting content, generating questions, and producing high-quality training data for model fine-tuning.
With Easy Dataset, you can transform domain knowledge into structured datasets, compatible with all LLM APIs that follow the OpenAI format, making the fine-tuning process simple and efficient.

- Intelligent Document Processing: Supports intelligent recognition and processing of multiple formats including PDF, Markdown, DOCX, etc.
- Intelligent Text Splitting: Supports multiple intelligent text splitting algorithms and customizable visual segmentation
- Intelligent Question Generation: Extracts relevant questions from each text segment
- Domain Labels: Intelligently builds global domain labels for datasets, with global understanding capabilities
- Answer Generation: Uses LLM API to generate comprehensive answers and Chain of Thought (COT)
- Flexible Editing: Edit questions, answers, and datasets at any stage of the process
- Multiple Export Formats: Export datasets in various formats (Alpaca, ShareGPT) and file types (JSON, JSONL)
- Wide Model Support: Compatible with all LLM APIs that follow the OpenAI format
- User-Friendly Interface: Intuitive UI designed for both technical and non-technical users
- Custom System Prompts: Add custom system prompts to guide model responses
https://github.com/user-attachments/assets/6ddb1225-3d1b-4695-90cd-aa4cb01376a8
| Windows | MacOS | Linux | |

Setup.exe |

Intel |
M |

AppImage |
- Clone the repository:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset- Install dependencies:
npm install- Start the development server:
npm run build
npm run start- Open your browser and visit
http://localhost:1717
- Clone the repository:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset- Modify the
docker-compose.ymlfile:
services:
easy-dataset:
image: ghcr.io/conardli/easy-dataset
container_name: easy-dataset
ports:
- '1717:1717'
volumes:
- ./local-db:/app/local-db
# - ./prisma:/app/prisma If mounting is required, please manually initialize the database file first.
restart: unless-stoppedNote: Replace
{YOUR_LOCAL_DB_PATH}and{LOCAL_PRISMA_PATH}with the actual paths where you want to store the local database. It is recommended to use thelocal-dbandprismafolders in the current code repository directory to maintain consistency with the database paths when starting via NPM.
Note: If you need to mount the database file (PRISMA), you need to run
npm run db:pushin advance to initialize the database file.
- Start with docker-compose:
docker-compose up -d- Open a browser and visit
http://localhost:1717
If you want to build the image yourself, use the Dockerfile in the project root directory:
- Clone the repository:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset- Build the Docker image:
docker build -t easy-dataset .- Run the container:
docker run -d \
-p 1717:1717 \
-v {YOUR_LOCAL_DB_PATH}:/app/local-db \
-v {LOCAL_PRISMA_PATH}:/app/prisma \
--name easy-dataset \
easy-datasetNote: Replace
{YOUR_LOCAL_DB_PATH}and{LOCAL_PRISMA_PATH}with the actual paths where you want to store the local database. It is recommended to use thelocal-dbandprismafolders in the current code repository directory to maintain consistency with the database paths when starting via NPM.
- Open a browser and visit
http://localhost:1717
 |
 |
- Click the "Create Project" button on the homepage;
- Enter a project name and description;
- Configure your preferred LLM API settings
 |
 |
- Upload your files in the "Text Split" section (supports PDF, Markdown, txt, DOCX);
- View and adjust the automatically split text segments;
- View and adjust the global domain tree
 |
 |
- Batch construct questions based on text blocks;
- View and edit the generated questions;
- Organize questions using the label tree
 |
 |
- Batch construct datasets based on questions;
- Generate answers using the configured LLM;
- View, edit, and optimize the generated answers
 |
 |
- Click the "Export" button in the Datasets section;
- Choose your preferred format (Alpaca or ShareGPT);
- Select the file format (JSON or JSONL);
- Add custom system prompts as needed;
- Export your dataset
- View the demo video of this project: Easy Dataset Demo Video
- For detailed documentation on all features and APIs, visit our Documentation Site
- View the paper of this project: Easy Dataset: A Unified and Extensible Framework for Synthesizing LLM Fine-Tuning Data from Unstructured Documents
- Easy Dataset × LLaMA Factory: Enabling LLMs to Efficiently Learn Domain Knowledge
- Easy Dataset Practical Guide: How to Build High-Quality Datasets?
- Interpretation of Key Feature Updates in Easy Dataset
- Foundation Models Fine-tuning Datasets: Basic Knowledge Popularization
We welcome contributions from the community! If you'd like to contribute to Easy Dataset, please follow these steps:
- Fork the repository
- Create a new branch (
git checkout -b feature/amazing-feature) - Make your changes
- Commit your changes (
git commit -m 'Add some amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request (submit to the DEV branch)
Please ensure that tests are appropriately updated and adhere to the existing coding style.
https://docs.easy-dataset.com/geng-duo/lian-xi-wo-men
This project is licensed under the AGPL 3.0 License - see the LICENSE file for details.
If this work is helpful, please kindly cite as:
@misc{miao2025easydataset,
title={Easy Dataset: A Unified and Extensible Framework for Synthesizing LLM Fine-Tuning Data from Unstructured Documents},
author={Ziyang Miao and Qiyu Sun and Jingyuan Wang and Yuchen Gong and Yaowei Zheng and Shiqi Li and Richong Zhang},
year={2025},
eprint={2507.04009},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.04009}
}{kind=link}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for easy-dataset
Similar Open Source Tools
easy-dataset
Easy Dataset is a specialized application designed to streamline the creation of fine-tuning datasets for Large Language Models (LLMs). It offers an intuitive interface for uploading domain-specific files, intelligently splitting content, generating questions, and producing high-quality training data for model fine-tuning. With Easy Dataset, users can transform domain knowledge into structured datasets compatible with all OpenAI-format compatible LLM APIs, making the fine-tuning process accessible and efficient.
duolingo-clone
Lingo is an interactive platform for language learning that provides a modern UI/UX experience. It offers features like courses, quests, and a shop for users to engage with. The tech stack includes React JS, Next JS, Typescript, Tailwind CSS, Vercel, and Postgresql. Users can contribute to the project by submitting changes via pull requests. The platform utilizes resources from CodeWithAntonio, Kenney Assets, Freesound, Elevenlabs AI, and Flagpack. Key dependencies include @clerk/nextjs, @neondatabase/serverless, @radix-ui/react-avatar, and more. Users can follow the project creator on GitHub and Twitter, as well as subscribe to their YouTube channel for updates. To learn more about Next.js, users can refer to the Next.js documentation and interactive tutorial.
auto-subs
Auto-subs is a tool designed to automatically transcribe editing timelines using OpenAI Whisper and Stable-TS for extreme accuracy. It generates subtitles in a custom style, is completely free, and runs locally within Davinci Resolve. It works on Mac, Linux, and Windows, supporting both Free and Studio versions of Resolve. Users can jump to positions on the timeline using the Subtitle Navigator and translate from any language to English. The tool provides a user-friendly interface for creating and customizing subtitles for video content.

DeepResearch
Tongyi DeepResearch is an agentic large language model with 30.5 billion total parameters, designed for long-horizon, deep information-seeking tasks. It demonstrates state-of-the-art performance across various search benchmarks. The model features a fully automated synthetic data generation pipeline, large-scale continual pre-training on agentic data, end-to-end reinforcement learning, and compatibility with two inference paradigms. Users can download the model directly from HuggingFace or ModelScope. The repository also provides benchmark evaluation scripts and information on the Deep Research Agent Family.

superlinked
Superlinked is a compute framework for information retrieval and feature engineering systems, focusing on converting complex data into vector embeddings for RAG, Search, RecSys, and Analytics stack integration. It enables custom model performance in machine learning with pre-trained model convenience. The tool allows users to build multimodal vectors, define weights at query time, and avoid postprocessing & rerank requirements. Users can explore the computational model through simple scripts and python notebooks, with a future release planned for production usage with built-in data infra and vector database integrations.

DB-GPT
DB-GPT is a personal database administrator that can solve database problems by reading documents, using various tools, and writing analysis reports. It is currently undergoing an upgrade. **Features:** * **Online Demo:** * Import documents into the knowledge base * Utilize the knowledge base for well-founded Q&A and diagnosis analysis of abnormal alarms * Send feedbacks to refine the intermediate diagnosis results * Edit the diagnosis result * Browse all historical diagnosis results, used metrics, and detailed diagnosis processes * **Language Support:** * English (default) * Chinese (add "language: zh" in config.yaml) * **New Frontend:** * Knowledgebase + Chat Q&A + Diagnosis + Report Replay * **Extreme Speed Version for localized llms:** * 4-bit quantized LLM (reducing inference time by 1/3) * vllm for fast inference (qwen) * Tiny LLM * **Multi-path extraction of document knowledge:** * Vector database (ChromaDB) * RESTful Search Engine (Elasticsearch) * **Expert prompt generation using document knowledge** * **Upgrade the LLM-based diagnosis mechanism:** * Task Dispatching -> Concurrent Diagnosis -> Cross Review -> Report Generation * Synchronous Concurrency Mechanism during LLM inference * **Support monitoring and optimization tools in multiple levels:** * Monitoring metrics (Prometheus) * Flame graph in code level * Diagnosis knowledge retrieval (dbmind) * Logical query transformations (Calcite) * Index optimization algorithms (for PostgreSQL) * Physical operator hints (for PostgreSQL) * Backup and Point-in-time Recovery (Pigsty) * **Continuously updated papers and experimental reports** This project is constantly evolving with new features. Don't forget to star ⭐ and watch 👀 to stay up to date.
genius-ai
Genius is a modern Next.js 14 SaaS AI platform that provides a comprehensive folder structure for app development. It offers features like authentication, dashboard management, landing pages, API integration, and more. The platform is built using React JS, Next JS, TypeScript, Tailwind CSS, and integrates with services like Netlify, Prisma, MySQL, and Stripe. Genius enables users to create AI-powered applications with functionalities such as conversation generation, image processing, code generation, and more. It also includes features like Clerk authentication, OpenAI integration, Replicate API usage, Aiven database connectivity, and Stripe API/webhook setup. The platform is fully configurable and provides a seamless development experience for building AI-driven applications.
llm-interface
LLM Interface is an npm module that streamlines interactions with various Large Language Model (LLM) providers in Node.js applications. It offers a unified interface for switching between providers and models, supporting 36 providers and hundreds of models. Features include chat completion, streaming, error handling, extensibility, response caching, retries, JSON output, and repair. The package relies on npm packages like axios, @google/generative-ai, dotenv, jsonrepair, and loglevel. Installation is done via npm, and usage involves sending prompts to LLM providers. Tests can be run using npm test. Contributions are welcome under the MIT License.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
llama-assistant
Llama Assistant is an AI-powered assistant that helps with daily tasks, such as voice recognition, natural language processing, summarizing text, rephrasing sentences, answering questions, and more. It runs offline on your local machine, ensuring privacy by not sending data to external servers. The project is a work in progress with regular feature additions.

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.
pipecat
Pipecat is an open-source framework designed for building generative AI voice bots and multimodal assistants. It provides code building blocks for interacting with AI services, creating low-latency data pipelines, and transporting audio, video, and events over the Internet. Pipecat supports various AI services like speech-to-text, text-to-speech, image generation, and vision models. Users can implement new services and contribute to the framework. Pipecat aims to simplify the development of applications like personal coaches, meeting assistants, customer support bots, and more by providing a complete framework for integrating AI services.
Free-GPT4-WEB-API
FreeGPT4-WEB-API is a Python server that allows you to have a self-hosted GPT-4 Unlimited and Free WEB API, via the latest Bing's AI. It uses Flask and GPT4Free libraries. GPT4Free provides an interface to the Bing's GPT-4. The server can be configured by editing the `FreeGPT4_Server.py` file. You can change the server's port, host, and other settings. The only cookie needed for the Bing model is `_U`.
Notate
Notate is a powerful desktop research assistant that combines AI-driven analysis with advanced vector search technology. It streamlines research workflow by processing, organizing, and retrieving information from documents, audio, and text. Notate offers flexible AI capabilities with support for various LLM providers and local models, ensuring data privacy. Built for researchers, academics, and knowledge workers, it features real-time collaboration, accessible UI, and cross-platform compatibility.
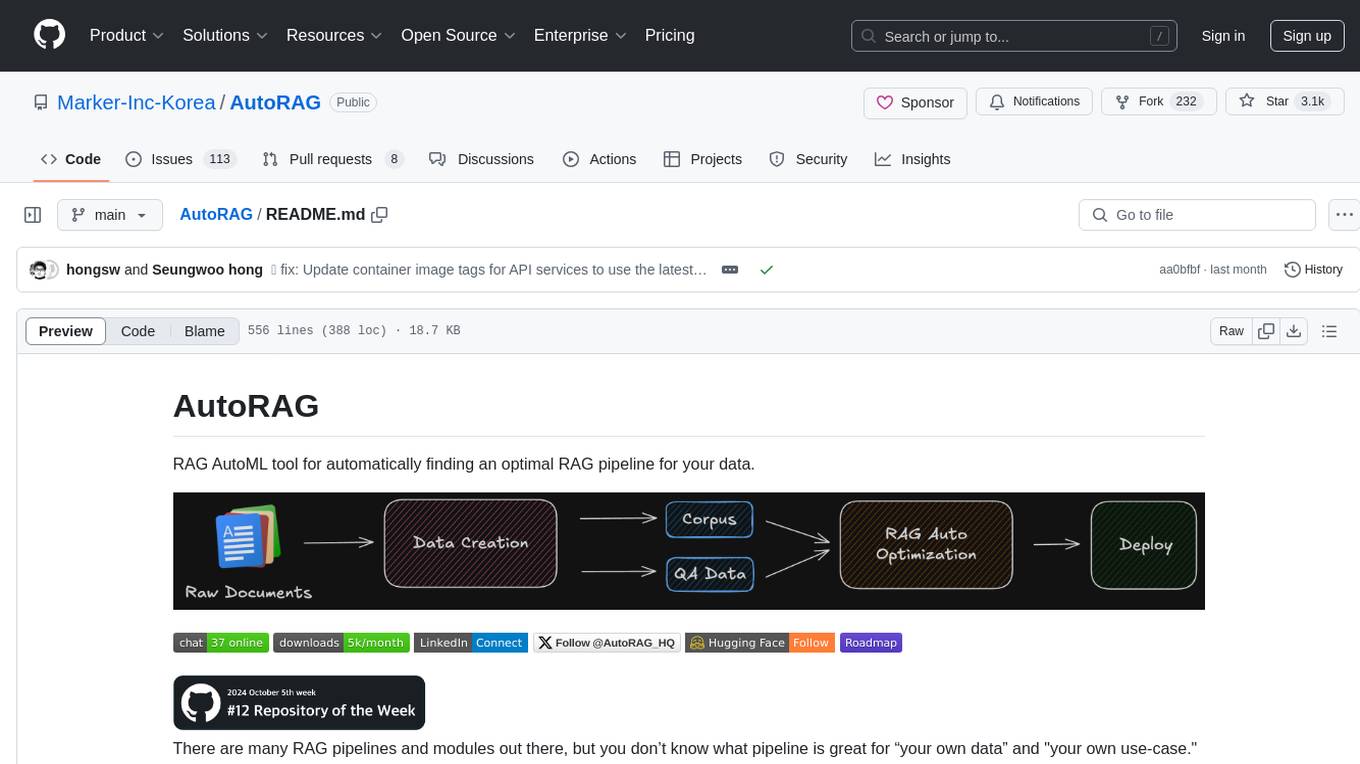
AutoRAG
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.

coreply
Coreply is an open-source Android app that provides texting suggestions while typing, enhancing the typing experience with intelligent, context-aware suggestions. It supports various texting apps and offers real-time AI suggestions, customizable LLM settings, and ensures no data collection. Users can install the app, configure it with an API key, and start receiving suggestions while typing in messaging apps. The tool supports different AI models from providers like OpenAI, Google AI Studio, Openrouter, Groq, and Codestral for chat completion and fill-in-the-middle tasks.
For similar tasks

cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
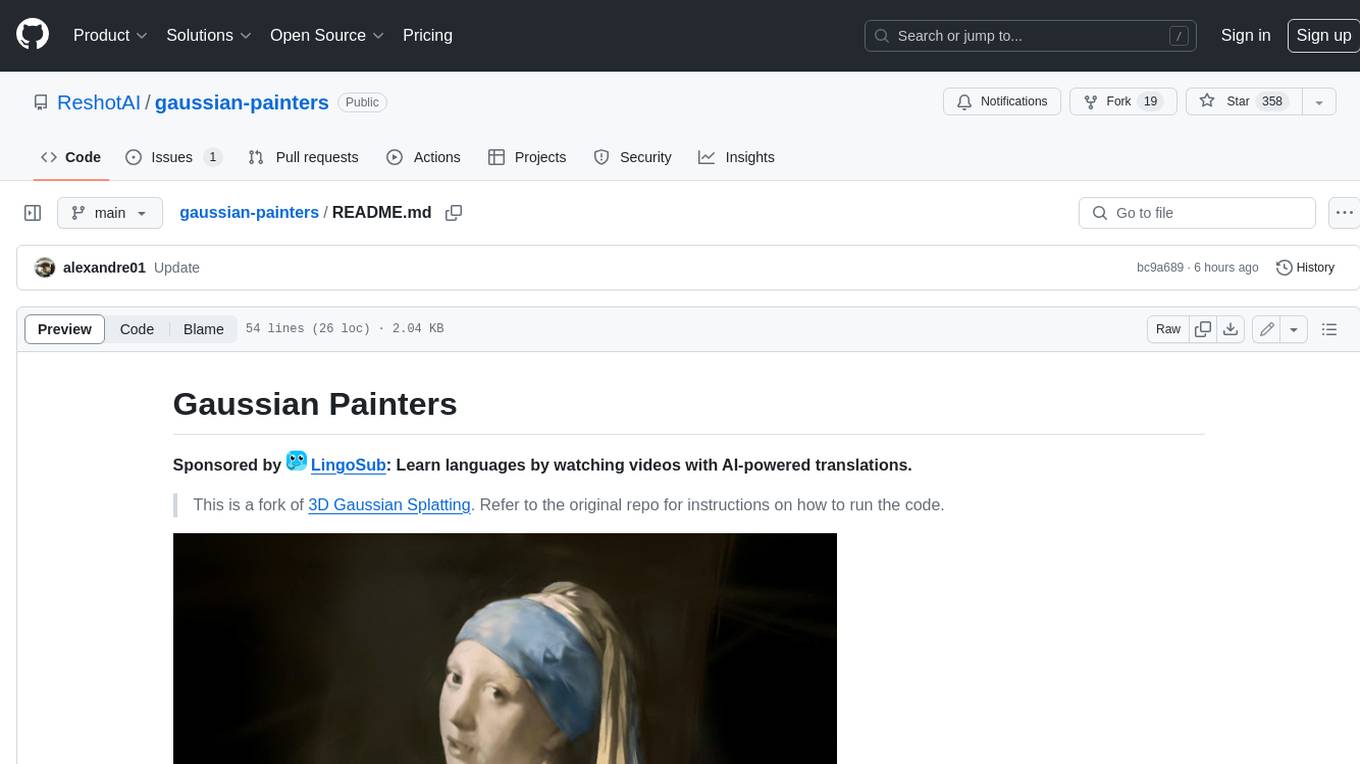
gaussian-painters
This tool is a fork of the 3D Gaussian Splatting code. It allows users to create a dataset ready to be trained with the Gaussian Splatting code. The dataset can be used for various experiments, such as creating orthogonal images, steganography, and lenticular effects. The tool also includes a visualizer that allows users to visualize the "painting" process during the Gaussian Splatting optimization.
UHGEval
UHGEval is a comprehensive framework designed for evaluating the hallucination phenomena. It includes UHGEval, a framework for evaluating hallucination, XinhuaHallucinations dataset, and UHGEval-dataset pipeline for creating XinhuaHallucinations. The framework offers flexibility and extensibility for evaluating common hallucination tasks, supporting various models and datasets. Researchers can use the open-source pipeline to create customized datasets. Supported tasks include QA, dialogue, summarization, and multi-choice tasks.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.
ollama-ebook-summary
The 'ollama-ebook-summary' repository is a Python project that creates bulleted notes summaries of books and long texts, particularly in epub and pdf formats with ToC metadata. It automates the extraction of chapters, splits them into ~2000 token chunks, and allows for asking arbitrary questions to parts of the text for improved granularity of response. The tool aims to provide summaries for each page of a book rather than a one-page summary of the entire document, enhancing content curation and knowledge sharing capabilities.

agentneo
AgentNeo is a Python package that provides functionalities for project, trace, dataset, experiment management. It allows users to authenticate, create projects, trace agents and LangGraph graphs, manage datasets, and run experiments with metrics. The tool aims to streamline AI project management and analysis by offering a comprehensive set of features.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.
RagaAI-Catalyst
RagaAI Catalyst is a comprehensive platform designed to enhance the management and optimization of LLM projects. It offers features such as project management, dataset management, evaluation management, trace management, prompt management, synthetic data generation, and guardrail management. These functionalities enable efficient evaluation and safeguarding of LLM applications.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.