
RagaAI-Catalyst
Python SDK for Agent AI Observability, Monitoring and Evaluation Framework. Includes features like agent, llm and tools tracing, debugging multi-agentic system, self-hosted dashboard and advanced analytics with timeline and execution graph view
Stars: 8520
RagaAI Catalyst is a comprehensive platform designed to enhance the management and optimization of LLM projects. It offers features such as project management, dataset management, evaluation management, trace management, prompt management, synthetic data generation, and guardrail management. These functionalities enable efficient evaluation and safeguarding of LLM applications.
README:



RagaAI Catalyst is a comprehensive platform designed to enhance the management and optimization of LLM projects. It offers a wide range of features, including project management, dataset management, evaluation management, trace management, prompt management, synthetic data generation, and guardrail management. These functionalities enable you to efficiently evaluate, and safeguard your LLM applications.
To install RagaAI Catalyst, you can use pip:
pip install ragaai-catalystBefore using RagaAI Catalyst, you need to set up your credentials. You can do this by setting environment variables or passing them directly to the RagaAICatalyst class:
from ragaai_catalyst import RagaAICatalyst
catalyst = RagaAICatalyst(
access_key="YOUR_ACCESS_KEY",
secret_key="YOUR_SECRET_KEY",
base_url="BASE_URL"
)Note: Authetication to RagaAICatalyst is necessary to perform any operations below
Create and manage projects using RagaAI Catalyst:
# Create a project
project = catalyst.create_project(
project_name="Test-RAG-App-1",
usecase="Chatbot"
)
# Get project usecases
catalyst.project_use_cases()
# List projects
projects = catalyst.list_projects()
print(projects)Manage datasets efficiently for your projects:
from ragaai_catalyst import Dataset
# Initialize Dataset management for a specific project
dataset_manager = Dataset(project_name="project_name")
# List existing datasets
datasets = dataset_manager.list_datasets()
print("Existing Datasets:", datasets)
# Create a dataset from CSV
dataset_manager.create_from_csv(
csv_path='path/to/your.csv',
dataset_name='MyDataset',
schema_mapping={'column1': 'schema_element1', 'column2': 'schema_element2'}
)
# Get project schema mapping
dataset_manager.get_schema_mapping()For more detailed information on Dataset Management, including CSV schema handling and advanced usage, please refer to the Dataset Management documentation.
Create and manage metric evaluation of your RAG application:
from ragaai_catalyst import Evaluation
# Create an experiment
evaluation = Evaluation(
project_name="Test-RAG-App-1",
dataset_name="MyDataset",
)
# Get list of available metrics
evaluation.list_metrics()
# Add metrics to the experiment
schema_mapping={
'Query': 'prompt',
'response': 'response',
'Context': 'context',
'expectedResponse': 'expected_response'
}
# Add single metric
evaluation.add_metrics(
metrics=[
{"name": "Faithfulness", "config": {"model": "gpt-4o-mini", "provider": "openai", "threshold": {"gte": 0.232323}}, "column_name": "Faithfulness_v1", "schema_mapping": schema_mapping},
]
)
# Add multiple metrics
evaluation.add_metrics(
metrics=[
{"name": "Faithfulness", "config": {"model": "gpt-4o-mini", "provider": "openai", "threshold": {"gte": 0.323}}, "column_name": "Faithfulness_gte", "schema_mapping": schema_mapping},
{"name": "Hallucination", "config": {"model": "gpt-4o-mini", "provider": "openai", "threshold": {"lte": 0.323}}, "column_name": "Hallucination_lte", "schema_mapping": schema_mapping},
{"name": "Hallucination", "config": {"model": "gpt-4o-mini", "provider": "openai", "threshold": {"eq": 0.323}}, "column_name": "Hallucination_eq", "schema_mapping": schema_mapping},
]
)
# Get the status of the experiment
status = evaluation.get_status()
print("Experiment Status:", status)
# Get the results of the experiment
results = evaluation.get_results()
print("Experiment Results:", results)Record and analyze traces of your RAG application:
from ragaai_catalyst import Tracer
# Start a trace recording
tracer = Tracer(
project_name="Test-RAG-App-1",
dataset_name="tracer_dataset_name",
metadata={"key1": "value1", "key2": "value2"},
tracer_type="langchain",
pipeline={
"llm_model": "gpt-4o-mini",
"vector_store": "faiss",
"embed_model": "text-embedding-ada-002",
}
).start()
# Your code here
# Stop the trace recording
tracer.stop()
# Get upload status
tracer.get_upload_status()Manage and use prompts efficiently in your projects:
from ragaai_catalyst import PromptManager
# Initialize PromptManager
prompt_manager = PromptManager(project_name="Test-RAG-App-1")
# List available prompts
prompts = prompt_manager.list_prompts()
print("Available prompts:", prompts)
# Get default prompt by prompt_name
prompt_name = "your_prompt_name"
prompt = prompt_manager.get_prompt(prompt_name)
# Get specific version of prompt by prompt_name and version
prompt_name = "your_prompt_name"
version = "v1"
prompt = prompt_manager.get_prompt(prompt_name,version)
# Get variables in a prompt
variable = prompt.get_variables()
print("variable:",variable)
# Get prompt content
prompt_content = prompt.get_prompt_content()
print("prompt_content:", prompt_content)
# Compile the prompt with variables
compiled_prompt = prompt.compile(query="What's the weather?", context="sunny", llm_response="It's sunny today")
print("Compiled prompt:", compiled_prompt)
# implement compiled_prompt with openai
import openai
def get_openai_response(prompt):
client = openai.OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=prompt
)
return response.choices[0].message.content
openai_response = get_openai_response(compiled_prompt)
print("openai_response:", openai_response)
# implement compiled_prompt with litellm
import litellm
def get_litellm_response(prompt):
response = litellm.completion(
model="gpt-4o-mini",
messages=prompt
)
return response.choices[0].message.content
litellm_response = get_litellm_response(compiled_prompt)
print("litellm_response:", litellm_response)For more detailed information on Prompt Management, please refer to the Prompt Management documentation.
from ragaai_catalyst import SyntheticDataGeneration
# Initialize Synthetic Data Generation
sdg = SyntheticDataGeneration()
# Process your file
text = sdg.process_document(input_data="file_path")
# Generate results
result = sdg.generate_qna(text, question_type ='complex',model_config={"provider":"openai","model":"openai/gpt-3.5-turbo"},n=5)
print(result.head())
# Get supported Q&A types
sdg.get_supported_qna()
# Get supported providers
sdg.get_supported_providers()from ragaai_catalyst import GuardrailsManager
# Initialize Guardrails Manager
gdm = GuardrailsManager(project_name=project_name)
# Get list of Guardrails available
guardrails_list = gdm.list_guardrails()
print('guardrails_list:', guardrails_list)
# Get list of fail condition for guardrails
fail_conditions = gdm.list_fail_condition()
print('fail_conditions;', fail_conditions)
#Get list of deployment ids
deployment_list = gdm.list_deployment_ids()
print('deployment_list:', deployment_list)
# Get specific deployment id with guardrails information
deployment_id_detail = gdm.get_deployment(17)
print('deployment_id_detail:', deployment_id_detail)
# Add guardrails to a deployment id
guardrails_config = {"guardrailFailConditions": ["FAIL"],
"deploymentFailCondition": "ALL_FAIL",
"alternateResponse": "Your alternate response"}
guardrails = [
{
"displayName": "Response_Evaluator",
"name": "Response Evaluator",
"config":{
"mappings": [{
"schemaName": "Text",
"variableName": "Response"
}],
"params": {
"isActive": {"value": False},
"isHighRisk": {"value": True},
"threshold": {"eq": 0},
"competitors": {"value": ["Google","Amazon"]}
}
}
},
{
"displayName": "Regex_Check",
"name": "Regex Check",
"config":{
"mappings": [{
"schemaName": "Text",
"variableName": "Response"
}],
"params":{
"isActive": {"value": False},
"isHighRisk": {"value": True},
"threshold": {"lt1": 1}
}
}
}
]
gdm.add_guardrails(deployment_id, guardrails, guardrails_config)
# Import GuardExecutor
from ragaai_catalyst import GuardExecutor
# Initialise GuardExecutor with required params and Evaluate
executor = GuardExecutor(deployment_id,gdm,field_map={'context':'document'})
message={'role':'user',
'content':'What is the capital of France'
}
prompt_params={'document':' France'}
model_params = {'temperature':.7,'model':'gpt-4o-mini'}
llm_caller = 'litellm'
executor([message],prompt_params,model_params,llm_caller)The Agentic Tracing module provides comprehensive monitoring and analysis capabilities for AI agent systems. It helps track various aspects of agent behavior including:
- LLM interactions and token usage
- Tool utilization and execution patterns
- Network activities and API calls
- User interactions and feedback
- Agent decision-making processes
The module includes utilities for cost tracking, performance monitoring, and debugging agent behavior. This helps in understanding and optimizing AI agent performance while maintaining transparency in agent operations.
from ragaai_catalyst import AgenticTracer
# Initialize tracer
tracer = AgenticTracer(
project_name="project_name",
dataset_name="dataset_name",
tracer_type="agentic",
)
# Define tracers
@tracer.trace_agents("agent_name")
# Agent Definition
@tracer.trace_llm("llm_name")
# LLM Definition
@tracer.trace_tool("tool_name")
# Tool Definition
# Perform tracing
with tracer:
# Agent execution code
passFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RagaAI-Catalyst
Similar Open Source Tools
RagaAI-Catalyst
RagaAI Catalyst is a comprehensive platform designed to enhance the management and optimization of LLM projects. It offers features such as project management, dataset management, evaluation management, trace management, prompt management, synthetic data generation, and guardrail management. These functionalities enable efficient evaluation and safeguarding of LLM applications.

firecrawl
Firecrawl is an API service that empowers AI applications with clean data from any website. It features advanced scraping, crawling, and data extraction capabilities. The repository is still in development, integrating custom modules into the mono repo. Users can run it locally but it's not fully ready for self-hosted deployment yet. Firecrawl offers powerful capabilities like scraping, crawling, mapping, searching, and extracting structured data from single pages, multiple pages, or entire websites with AI. It supports various formats, actions, and batch scraping. The tool is designed to handle proxies, anti-bot mechanisms, dynamic content, media parsing, change tracking, and more. Firecrawl is available as an open-source project under the AGPL-3.0 license, with additional features offered in the cloud version.
python-utcp
The Universal Tool Calling Protocol (UTCP) is a secure and scalable standard for defining and interacting with tools across various communication protocols. UTCP emphasizes scalability, extensibility, interoperability, and ease of use. It offers a modular core with a plugin-based architecture, making it extensible, testable, and easy to package. The repository contains the complete UTCP Python implementation with core components and protocol-specific plugins for HTTP, CLI, Model Context Protocol, file-based tools, and more.
AICentral
AI Central is a powerful tool designed to take control of your AI services with minimal overhead. It is built on Asp.Net Core and dotnet 8, offering fast web-server performance. The tool enables advanced Azure APIm scenarios, PII stripping logging to Cosmos DB, token metrics through Open Telemetry, and intelligent routing features. AI Central supports various endpoint selection strategies, proxying asynchronous requests, custom OAuth2 authorization, circuit breakers, rate limiting, and extensibility through plugins. It provides an extensibility model for easy plugin development and offers enriched telemetry and logging capabilities for monitoring and insights.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.
jambo
Jambo is a Python package that automatically converts JSON Schema definitions into Pydantic models. It streamlines schema validation and enforces type safety using Pydantic's validation features. The tool supports various JSON Schema features like strings, integers, floats, booleans, arrays, nested objects, and more. It enforces constraints such as minLength, maxLength, pattern, minimum, maximum, uniqueItems, and provides a zero-config approach for generating models. Jambo is designed to simplify the process of dynamically generating Pydantic models for AI frameworks.
firecrawl-mcp-server
Firecrawl MCP Server is a Model Context Protocol (MCP) server implementation that integrates with Firecrawl for web scraping capabilities. It supports features like scrape, crawl, search, extract, and batch scrape. It provides web scraping with JS rendering, URL discovery, web search with content extraction, automatic retries with exponential backoff, credit usage monitoring, comprehensive logging system, support for cloud and self-hosted FireCrawl instances, mobile/desktop viewport support, and smart content filtering with tag inclusion/exclusion. The server includes configurable parameters for retry behavior and credit usage monitoring, rate limiting and batch processing capabilities, and tools for scraping, batch scraping, checking batch status, searching, crawling, and extracting structured information from web pages.
flo-ai
Flo AI is a Python framework that enables users to build production-ready AI agents and teams with minimal code. It allows users to compose complex AI architectures using pre-built components while maintaining the flexibility to create custom components. The framework supports composable, production-ready, YAML-first, and flexible AI systems. Users can easily create AI agents and teams, manage teams of AI agents working together, and utilize built-in support for Retrieval-Augmented Generation (RAG) and compatibility with Langchain tools. Flo AI also provides tools for output parsing and formatting, tool logging, data collection, and JSON output collection. It is MIT Licensed and offers detailed documentation, tutorials, and examples for AI engineers and teams to accelerate development, maintainability, scalability, and testability of AI systems.
typst-mcp
Typst MCP Server is an implementation of the Model Context Protocol (MCP) that facilitates interaction between AI models and Typst, a markup-based typesetting system. The server offers tools for converting between LaTeX and Typst, validating Typst syntax, and generating images from Typst code. It provides functions such as listing documentation chapters, retrieving specific chapters, converting LaTeX snippets to Typst, validating Typst syntax, and rendering Typst code to images. The server is designed to assist Language Model Managers (LLMs) in handling Typst-related tasks efficiently and accurately.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

ollama-ex
Ollama is a powerful tool for running large language models locally or on your own infrastructure. It provides a full implementation of the Ollama API, support for streaming requests, and tool use capability. Users can interact with Ollama in Elixir to generate completions, chat messages, and perform streaming requests. The tool also supports function calling on compatible models, allowing users to define tools with clear descriptions and arguments. Ollama is designed to facilitate natural language processing tasks and enhance user interactions with language models.
firecrawl-mcp-server
Firecrawl MCP Server is a Model Context Protocol (MCP) server implementation that integrates with Firecrawl for web scraping capabilities. It offers features such as web scraping, crawling, and discovery, search and content extraction, deep research and batch scraping, automatic retries and rate limiting, cloud and self-hosted support, and SSE support. The server can be configured to run with various tools like Cursor, Windsurf, SSE Local Mode, Smithery, and VS Code. It supports environment variables for cloud API and optional configurations for retry settings and credit usage monitoring. The server includes tools for scraping, batch scraping, mapping, searching, crawling, and extracting structured data from web pages. It provides detailed logging and error handling functionalities for robust performance.
ling
Ling is a workflow framework supporting streaming of structured content from large language models. It enables quick responses to content streams, reducing waiting times. Ling parses JSON data streams character by character in real-time, outputting content in jsonuri format. It facilitates immediate front-end processing by converting content during streaming input. The framework supports data stream output via JSONL protocol, correction of token errors in JSON output, complex asynchronous workflows, status messages during streaming output, and Server-Sent Events.
mcp-hub
MCP Hub is a centralized manager for Model Context Protocol (MCP) servers, offering dynamic server management and monitoring, REST API for tool execution and resource access, MCP Server marketplace integration, real-time server status tracking, client connection management, and process lifecycle handling. It acts as a central management server connecting to and managing multiple MCP servers, providing unified API endpoints for client access, handling server lifecycle and health monitoring, and routing requests between clients and MCP servers.
llm-sandbox
LLM Sandbox is a lightweight and portable sandbox environment designed to securely execute large language model (LLM) generated code in a safe and isolated manner using Docker containers. It provides an easy-to-use interface for setting up, managing, and executing code in a controlled Docker environment, simplifying the process of running code generated by LLMs. The tool supports multiple programming languages, offers flexibility with predefined Docker images or custom Dockerfiles, and allows scalability with support for Kubernetes and remote Docker hosts.
jupyter-mcp-server
Jupyter MCP Server is a Model Context Protocol (MCP) server implementation that enables real-time interaction with Jupyter Notebooks. It allows AI to edit, document, and execute code for data analysis and visualization. The server offers features like real-time control, smart execution, and MCP compatibility. Users can use tools such as insert_execute_code_cell, append_markdown_cell, get_notebook_info, and read_cell for advanced interactions with Jupyter notebooks.
For similar tasks

cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
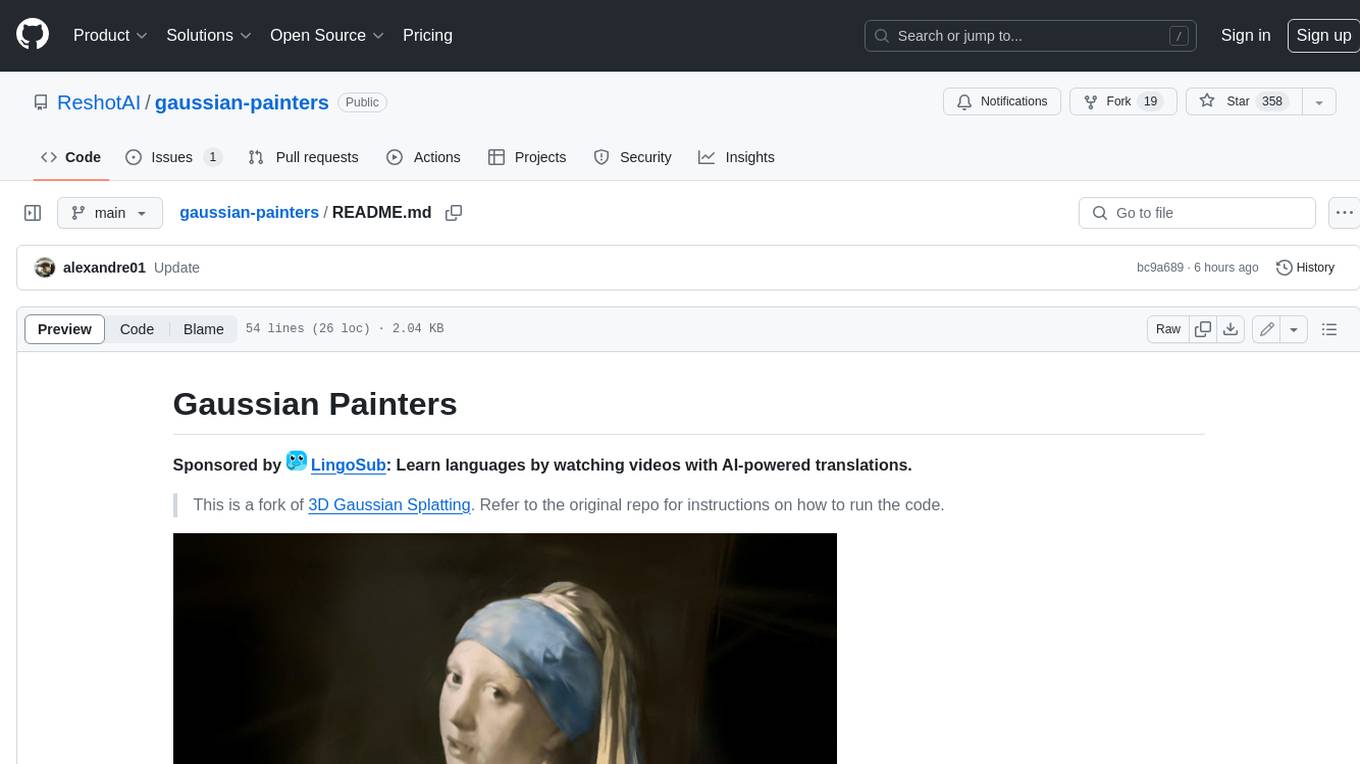
gaussian-painters
This tool is a fork of the 3D Gaussian Splatting code. It allows users to create a dataset ready to be trained with the Gaussian Splatting code. The dataset can be used for various experiments, such as creating orthogonal images, steganography, and lenticular effects. The tool also includes a visualizer that allows users to visualize the "painting" process during the Gaussian Splatting optimization.
UHGEval
UHGEval is a comprehensive framework designed for evaluating the hallucination phenomena. It includes UHGEval, a framework for evaluating hallucination, XinhuaHallucinations dataset, and UHGEval-dataset pipeline for creating XinhuaHallucinations. The framework offers flexibility and extensibility for evaluating common hallucination tasks, supporting various models and datasets. Researchers can use the open-source pipeline to create customized datasets. Supported tasks include QA, dialogue, summarization, and multi-choice tasks.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.
ollama-ebook-summary
The 'ollama-ebook-summary' repository is a Python project that creates bulleted notes summaries of books and long texts, particularly in epub and pdf formats with ToC metadata. It automates the extraction of chapters, splits them into ~2000 token chunks, and allows for asking arbitrary questions to parts of the text for improved granularity of response. The tool aims to provide summaries for each page of a book rather than a one-page summary of the entire document, enhancing content curation and knowledge sharing capabilities.

agentneo
AgentNeo is a Python package that provides functionalities for project, trace, dataset, experiment management. It allows users to authenticate, create projects, trace agents and LangGraph graphs, manage datasets, and run experiments with metrics. The tool aims to streamline AI project management and analysis by offering a comprehensive set of features.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.
RagaAI-Catalyst
RagaAI Catalyst is a comprehensive platform designed to enhance the management and optimization of LLM projects. It offers features such as project management, dataset management, evaluation management, trace management, prompt management, synthetic data generation, and guardrail management. These functionalities enable efficient evaluation and safeguarding of LLM applications.
For similar jobs
Thor
Thor is a powerful AI model management tool designed for unified management and usage of various AI models. It offers features such as user, channel, and token management, data statistics preview, log viewing, system settings, external chat link integration, and Alipay account balance purchase. Thor supports multiple AI models including OpenAI, Kimi, Starfire, Claudia, Zhilu AI, Ollama, Tongyi Qianwen, AzureOpenAI, and Tencent Hybrid models. It also supports various databases like SqlServer, PostgreSql, Sqlite, and MySql, allowing users to choose the appropriate database based on their needs.
redbox
Redbox is a retrieval augmented generation (RAG) app that uses GenAI to chat with and summarise civil service documents. It increases organisational memory by indexing documents and can summarise reports read months ago, supplement them with current work, and produce a first draft that lets civil servants focus on what they do best. The project uses a microservice architecture with each microservice running in its own container defined by a Dockerfile. Dependencies are managed using Python Poetry. Contributions are welcome, and the project is licensed under the MIT License. Security measures are in place to ensure user data privacy and considerations are being made to make the core-api secure.

WilmerAI
WilmerAI is a middleware system designed to process prompts before sending them to Large Language Models (LLMs). It categorizes prompts, routes them to appropriate workflows, and generates manageable prompts for local models. It acts as an intermediary between the user interface and LLM APIs, supporting multiple backend LLMs simultaneously. WilmerAI provides API endpoints compatible with OpenAI API, supports prompt templates, and offers flexible connections to various LLM APIs. The project is under heavy development and may contain bugs or incomplete code.
MLE-agent
MLE-Agent is an intelligent companion designed for machine learning engineers and researchers. It features autonomous baseline creation, integration with Arxiv and Papers with Code, smart debugging, file system organization, comprehensive tools integration, and an interactive CLI chat interface for seamless AI engineering and research workflows.

LynxHub
LynxHub is a platform that allows users to seamlessly install, configure, launch, and manage all their AI interfaces from a single, intuitive dashboard. It offers features like AI interface management, arguments manager, custom run commands, pre-launch actions, extension management, in-app tools like terminal and web browser, AI information dashboard, Discord integration, and additional features like theme options and favorite interface pinning. The platform supports modular design for custom AI modules and upcoming extensions system for complete customization. LynxHub aims to streamline AI workflow and enhance user experience with a user-friendly interface and comprehensive functionalities.

ChatGPT-Next-Web-Pro
ChatGPT-Next-Web-Pro is a tool that provides an enhanced version of ChatGPT-Next-Web with additional features and functionalities. It offers complete ChatGPT-Next-Web functionality, file uploading and storage capabilities, drawing and video support, multi-modal support, reverse model support, knowledge base integration, translation, customizations, and more. The tool can be deployed with or without a backend, allowing users to interact with AI models, manage accounts, create models, manage API keys, handle orders, manage memberships, and more. It supports various cloud services like Aliyun OSS, Tencent COS, and Minio for file storage, and integrates with external APIs like Azure, Google Gemini Pro, and Luma. The tool also provides options for customizing website titles, subtitles, icons, and plugin buttons, and offers features like voice input, file uploading, real-time token count display, and more.
agentneo
AgentNeo is a Python package that provides functionalities for project, trace, dataset, experiment management. It allows users to authenticate, create projects, trace agents and LangGraph graphs, manage datasets, and run experiments with metrics. The tool aims to streamline AI project management and analysis by offering a comprehensive set of features.
VoAPI
VoAPI is a new high-value/high-performance AI model interface management and distribution system. It is a closed-source tool for personal learning use only, not for commercial purposes. Users must comply with upstream AI model service providers and legal regulations. The system offers a visually appealing interface with features such as independent development documentation page support, service monitoring page configuration support, and third-party login support. Users can manage user registration time, optimize interface elements, and support features like online recharge, model pricing display, and sensitive word filtering. VoAPI also provides support for various AI models and platforms, with the ability to configure homepage templates, model information, and manufacturer information.