Best AI tools for< Evaluate Metrics >
20 - AI tool Sites
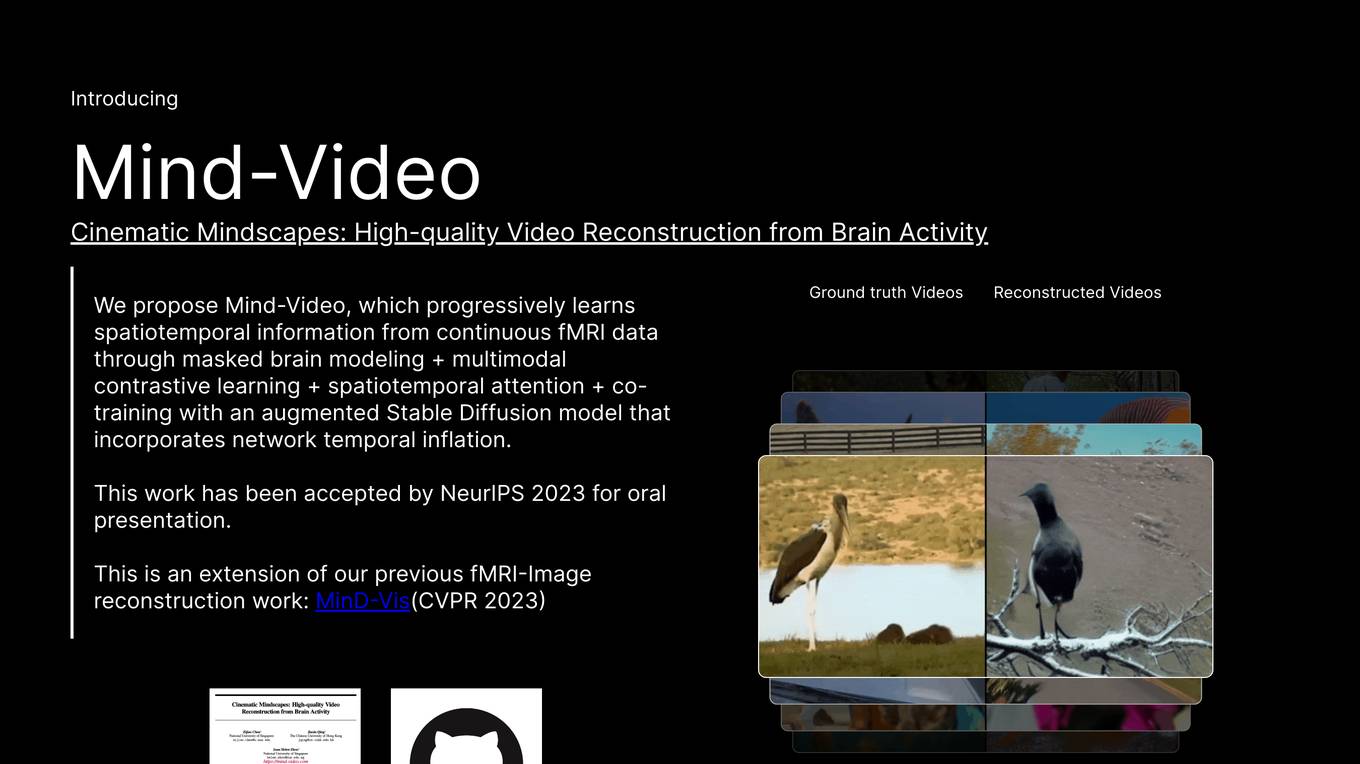
Mind-Video
Mind-Video is an AI tool that focuses on high-quality video reconstruction from brain activity data. It bridges the gap between image and video brain decoding by utilizing masked brain modeling, multimodal contrastive learning, spatiotemporal attention, and co-training with an augmented Stable Diffusion model. The tool aims to recover accurate semantic information from fMRI signals, enabling the generation of realistic videos based on brain activities.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
Galileo AI
Galileo AI is a platform that offers automated evaluations for AI applications, bringing automation and insight to AI evaluations to ensure reliable and confident shipping. It helps in eliminating 80% of evaluation time by replacing manual reviews with high-accuracy metrics, enabling rapid iteration, achieving real-time protection, and providing end-to-end visibility into agent completions. Galileo also allows developers to take control of AI complexity, de-risk AI in production, and deploy AI applications flexibly across different environments. The platform is trusted by enterprises and loved by developers for its accuracy, low-latency, and ability to run on L4 GPUs.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.
Coval
Coval is an AI tool designed to help users ship reliable AI agents faster by providing simulation and evaluations for voice and chat agents. It allows users to simulate thousands of scenarios from a few test cases, create prompts for testing, and evaluate agent interactions comprehensively. Coval offers AI-powered simulations, voice AI compatibility, performance tracking, workflow metrics, and customizable evaluation metrics to optimize AI agents efficiently.
Hirenest
Hirenest is an AI-powered hiring platform that connects job seekers with employers through skills-based assessments. Job seekers showcase their abilities upfront, while employers receive pre-screened candidates ranked by demonstrated performance. The platform offers features such as AI video interviews, MCQ assessments, and open-ended questions to evaluate candidates. Hirenest aims to revolutionize the traditional hiring process by focusing on skills rather than resume formatting, providing personalized career insights, and facilitating faster, data-driven hiring decisions.
DeepEval
DeepEval by Confident AI is a comprehensive LLM Evaluation Framework used by leading AI companies. It enables users to build reliable evaluation pipelines to test any AI system. With 50+ research-backed metrics, native multi-modal support, and auto-optimization of prompts, DeepEval offers a sophisticated evaluation ecosystem for AI applications. The framework covers unit-testing for LLMs, single and multi-turn evaluations, generation & simulation of test data, and state-of-the-art evaluation techniques like G-Eval and DAG. DeepEval is integrated with Pytest and supports various system architectures, making it a versatile tool for AI testing.

Confident AI
Confident AI is an AI evaluation and observability platform designed to help engineers, QA teams, and product leaders build reliable AI systems. It offers best-in-class evaluation metrics powered by DeepEval, real-time production alerts, and tools for tracing and monitoring AI performance. The platform aims to streamline dataset curation, metric alignment, and LLM testing automation, ultimately saving time, reducing costs, and ensuring continuous improvement of AI models.
GreetAI
GreetAI is an AI-powered platform that revolutionizes the hiring process by conducting AI video interviews to evaluate applicants efficiently. The platform provides insightful reports, customizable interview questions, and highlights key points to help recruiters make informed decisions. GreetAI offers features such as interview simulations, job post generation, AI video screenings, and detailed candidate performance metrics.
JobSynergy
JobSynergy is an AI-powered platform that revolutionizes the hiring process by automating and conducting interviews at scale. It offers a real-world interview simulator that adapts dynamically to candidates' responses, custom questions and metrics evaluation, cheating detection using eye, voice, and screen, and detailed reports for better hiring decisions. The platform enhances efficiency, candidate experience, and ensures security and integrity in the hiring process.
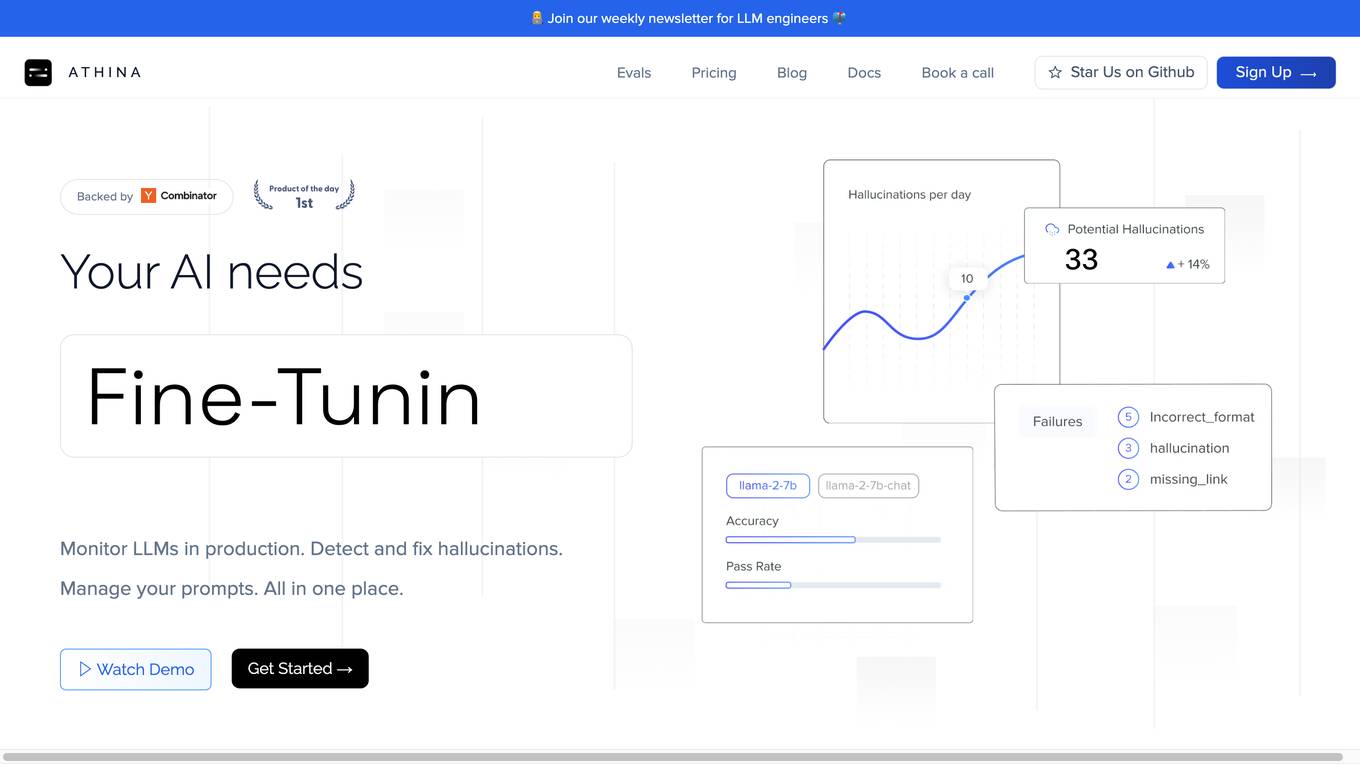
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
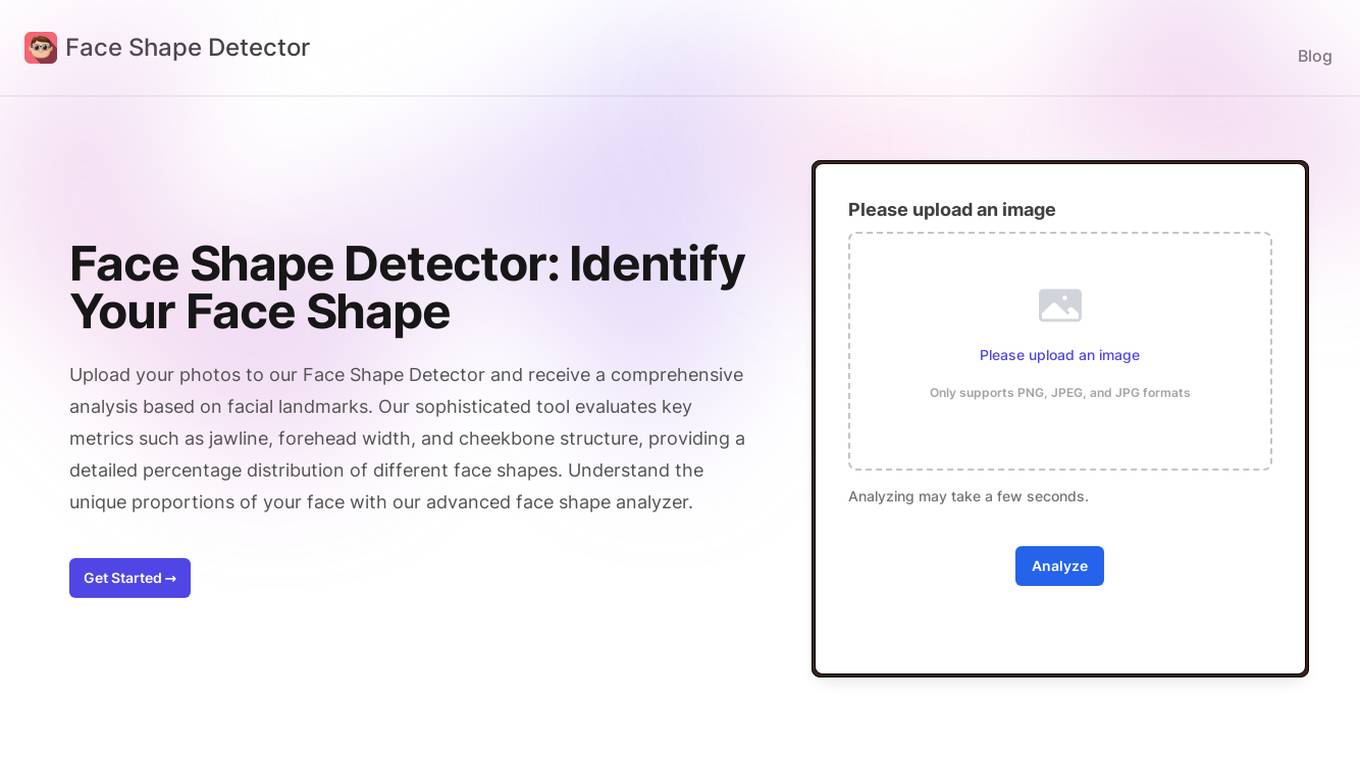
Face Shape Detector
Face Shape Detector is an advanced AI tool that analyzes facial landmarks in uploaded photos to identify the user's face shape and provide percentage distributions for different face shapes. It utilizes sophisticated algorithms to assess key metrics such as jawline, forehead width, and cheekbone structure, delivering detailed insights into facial proportions. Users can explore the power of facial analysis, understand their unique face shape, and receive quick and accurate results through this intuitive tool.
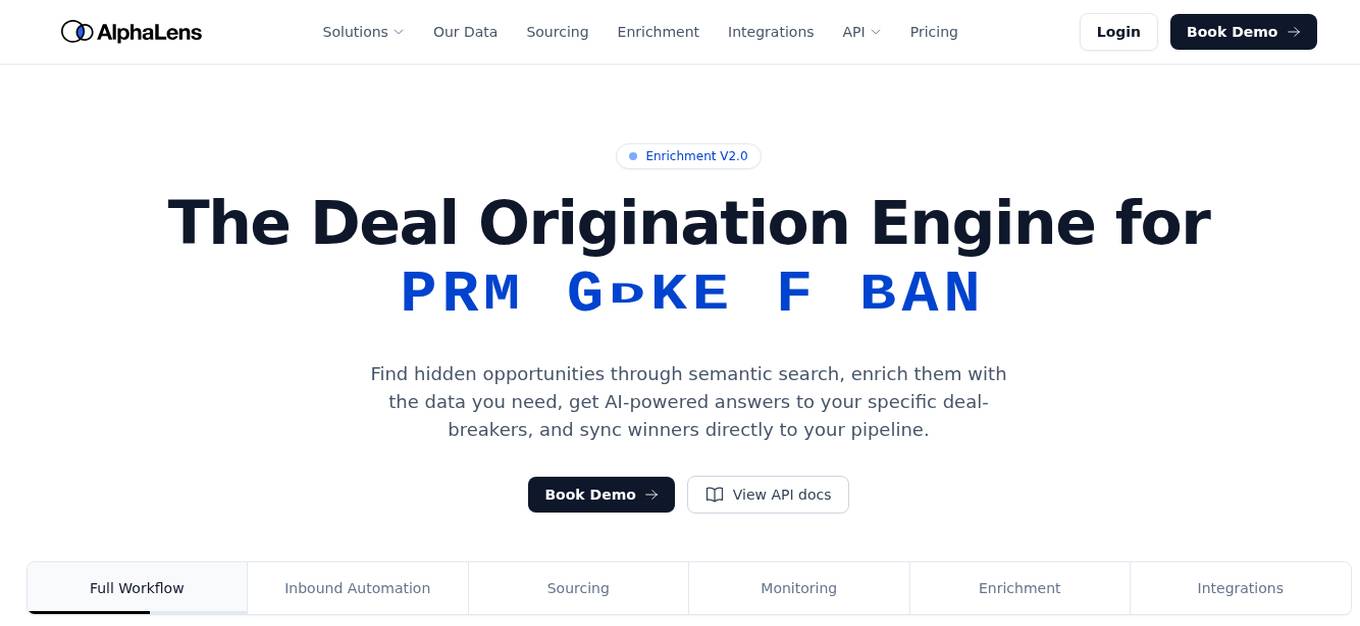
AlphaLens Intelligence Solutions
AlphaLens Intelligence Solutions is an AI-powered platform that offers a comprehensive suite of tools for deal origination, sourcing, enrichment, and CRM integrations. It provides users with the ability to extract data from pitch decks, find and evaluate companies, and enrich company profiles with deep market insights. The platform leverages generative AI, semantic search, and active monitoring to surface hidden opportunities, automate deal screening, and sync data to the user's pipeline. With a focus on private market data, AlphaLens enables users to access a vast universe of company and product information, including funding rounds, growth metrics, and target audience insights. The platform also offers REST API access, Chrome extension, and integration with CRM systems for seamless data management.

Lisapet.AI
Lisapet.AI is an AI prompt testing suite designed for product teams to streamline the process of designing, prototyping, testing, and shipping AI features. It offers a comprehensive platform with features like best-in-class AI playground, variables for dynamic data inputs, structured outputs, side-by-side editing, function calling, image inputs, assertions & metrics, performance comparison, data sets organization, shareable reports, comments & feedback, token & cost stats, and more. The application aims to help teams save time, improve efficiency, and ensure the reliability of AI features through automated prompt testing.
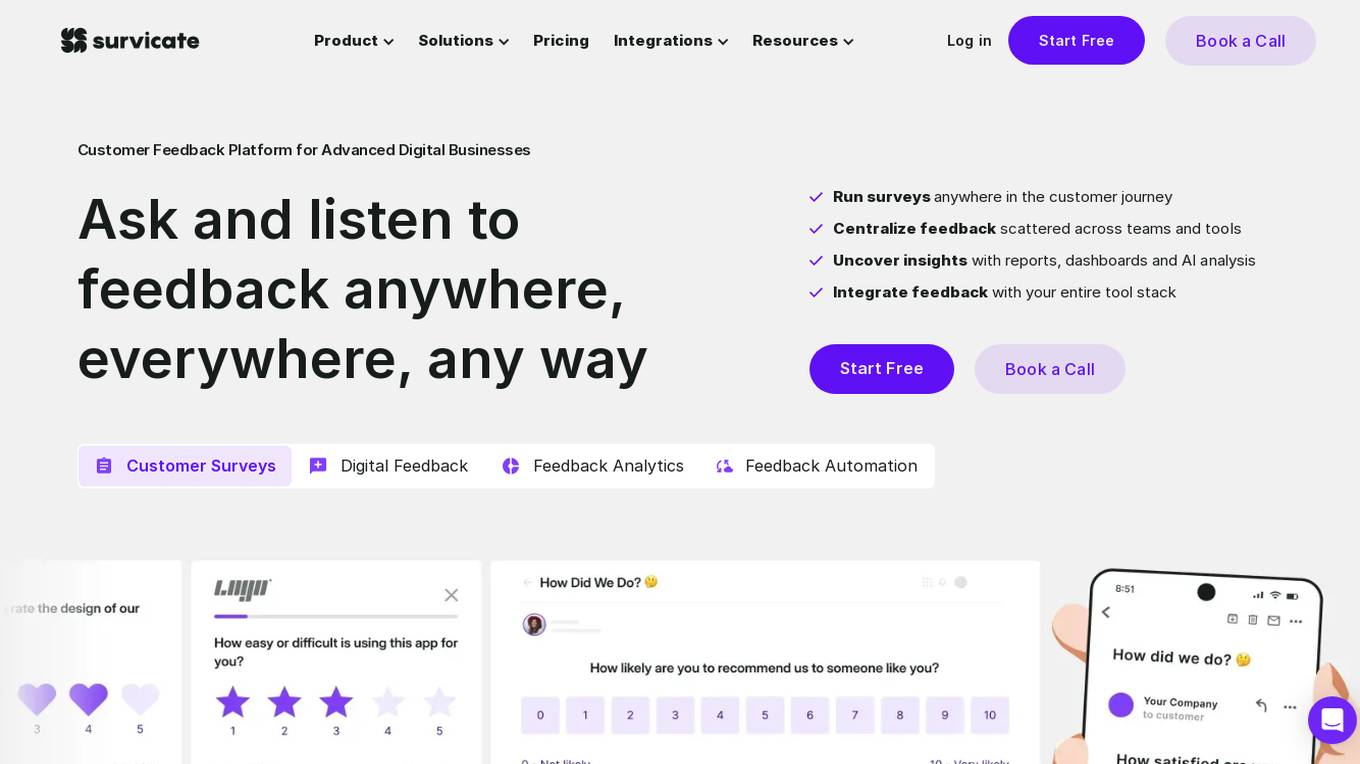
Survicate
Survicate is a customer feedback platform designed for advanced digital businesses. It offers effortless surveys, no-guesswork metrics, integrations with everyday tools, and over 150 survey templates. The platform allows users to create surveys in seconds, analyze results without drowning in data, and measure and track experiences at all user touchpoints. Survicate helps in collecting contextual product feedback, optimizing user experience, and understanding target audiences. It also enables users to evaluate customer journeys, measure customer satisfaction, and close feedback loops. With AI integration and insights hub, Survicate provides superior insights delivered fast for businesses to make informed decisions.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.
1 - Open Source AI Tools
RagaAI-Catalyst
RagaAI Catalyst is a comprehensive platform designed to enhance the management and optimization of LLM projects. It offers features such as project management, dataset management, evaluation management, trace management, prompt management, synthetic data generation, and guardrail management. These functionalities enable efficient evaluation and safeguarding of LLM applications.
20 - OpenAI Gpts

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.


IELTS Writing Test
Simulates the IELTS Writing Test, evaluates responses, and estimates band scores.
Academic Paper Evaluator
Enthusiastic about truth in academic papers, critical and analytical.