
vlmrun-hub
A hub for various industry-specific schemas to be used with VLMs.
Stars: 495
VLMRun Hub is a versatile tool for managing and running virtual machines in a centralized manner. It provides a user-friendly interface to easily create, start, stop, and monitor virtual machines across multiple hosts. With VLMRun Hub, users can efficiently manage their virtualized environments and streamline their workflow. The tool offers flexibility and scalability, making it suitable for both small-scale personal projects and large-scale enterprise deployments.
README:





Welcome to VLM Run Hub, a comprehensive repository of pre-defined Pydantic schemas for extracting structured data from unstructured visual domains such as images, videos, and documents. Designed for Vision Language Models (VLMs) and optimized for real-world use cases, VLM Run Hub simplifies the integration of visual ETL into your workflows.
| Image | JSON |

|
{
"issuing_state": "MT",
"license_number": "0812319684104",
"first_name": "Brenda",
"middle_name": "Lynn",
"last_name": "Sample",
"address": {
"street": "123 MAIN STREET",
"city": "HELENA",
"state": "MT",
"zip_code": "59601"
},
"date_of_birth": "1968-08-04",
"gender": "F",
"height": "5'06\"",
"weight": 150.0,
"eye_color": "BRO",
"issue_date": "2015-02-15",
"expiration_date": "2023-08-04",
"license_class": "D"
} |
While vision models like OpenAI’s GPT-4o and Anthropic’s Claude Vision excel in exploratory tasks like "chat with images," they often lack practicality for automation and integration, where strongly-typed, validated outputs are crucial.
The Structured Outputs API (popularized by GPT-4o, Gemini) addresses this by constraining LLMs to return data in precise, strongly-typed formats such as Pydantic models. This eliminates complex parsing and validation, ensuring outputs conform to expected types and structures. These schemas can be nested and include complex types like lists and dictionaries, enabling seamless integration with existing systems while leveraging the full capabilities of the model.
- 📚 Easy to use: Pydantic is a well-understood and battle-tested data model for structured data.
- 🔋 Batteries included: Each schema in this repo has been validated across real-world industry use cases—from healthcare to finance to media—saving you weeks of development effort.
- 🔍 Automatic Data-validation: Built-in Pydantic validation ensures your extracted data is clean, accurate, and reliable, reducing errors and simplifying downstream workflows.
- 🔌 Type-safety: With Pydantic’s type-safety and compatibility with tools like
mypyandpyright, you can build composable, modular systems that are robust and maintainable. - 🧰 Model-agnostic: Use the same schema with multiple VLM providers, no need to rewrite prompts for different VLMs.
- 🚀 Optimized for Visual ETL: Purpose-built for extracting structured data from images, videos, and documents, this repo bridges the gap between unstructured data and actionable insights.
The VLM Run Hub maintains a comprehensive catalog of all available schemas in the vlmrun/hub/catalog.yaml file. The catalog is automatically validated to ensure consistency and completeness of schema documentation. We refer the developer to the catalog-spec.yaml for the full YAML specification.
If you have a new schema you want to add to the catalog, please refer to the SCHEMA-GUIDELINES.md for the full guidelines.
Let's say we want to extract invoice metadata from an invoice image. You can readily use our Invoice schema we have defined under vlmrun.hub.schemas.document.invoice and use it with any VLM of your choosing.
For a comprehensive walkthrough of available schemas and their usage, check out our Schema Showcase Notebook.
pip install vlmrun-hubWith Instructor / OpenAI
import instructor
from openai import OpenAI
from vlmrun.hub.schemas.document.invoice import Invoice
IMAGE_URL = "https://storage.googleapis.com/vlm-data-public-prod/hub/examples/document.invoice/invoice_1.jpg"
client = instructor.from_openai(
OpenAI(), mode=instructor.Mode.MD_JSON
)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{ "role": "user", "content": [
{"type": "text", "text": "Extract the invoice in JSON."},
{"type": "image_url", "image_url": {"url": IMAGE_URL}, "detail": "auto"}
]}
],
response_model=Invoice,
temperature=0,
)JSON Response:
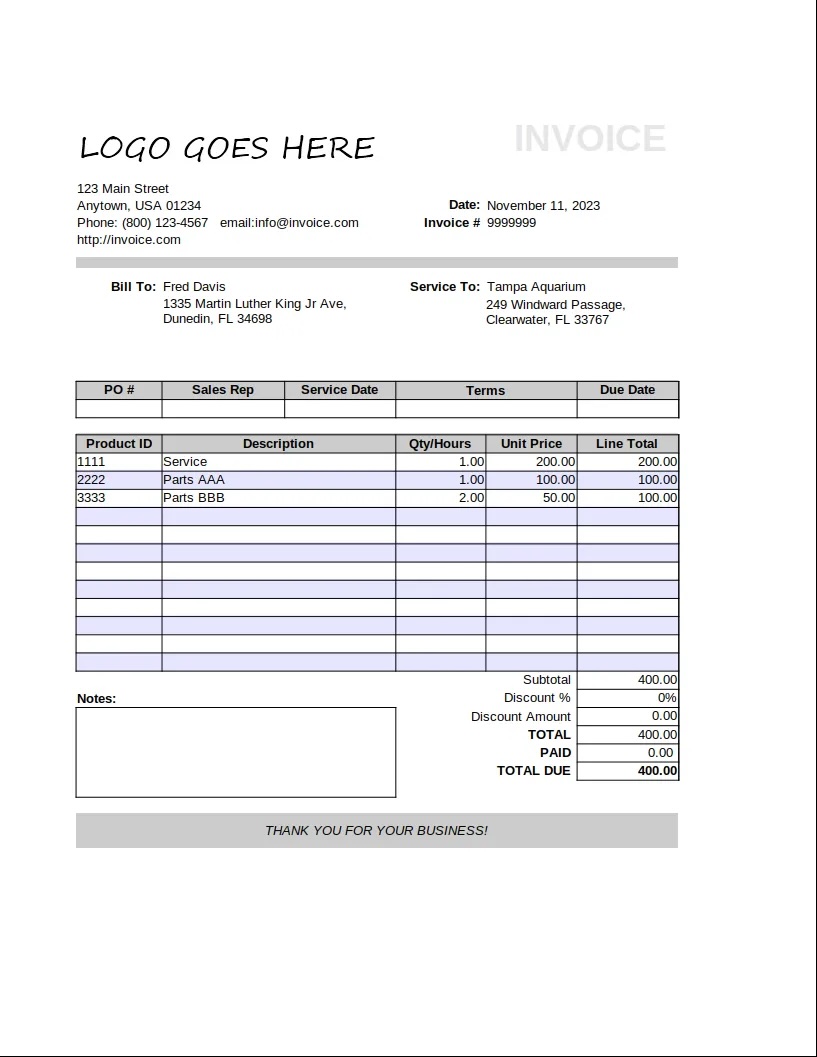
| Image | JSON Output 🔐 |
|
{
"invoice_id": "9999999",
"period_start": null,
"period_end": null,
"invoice_issue_date": "2023-11-11",
"invoice_due_date": null,
"order_id": null,
"customer_id": null,
"issuer": "Anytown, USA",
"issuer_address": {
"street": "123 Main Street",
"city": "Anytown",
"state": "USA",
"postal_code": "01234",
"country": null
},
"customer": "Fred Davis",
"customer_email": "[email protected]",
"customer_phone": "(800) 123-4567",
"customer_billing_address": {
"street": "1335 Martin Luther King Jr Ave",
"city": "Dunedin",
"state": "FL",
"postal_code": "34698",
"country": null
},
"customer_shipping_address": {
"street": "249 Windward Passage",
"city": "Clearwater",
"state": "FL",
"postal_code": "33767",
"country": null
},
"items": [
{
"description": "Service",
"quantity": 1,
"currency": null,
"unit_price": 200.0,
"total_price": 200.0
},
{
"description": "Parts AAA",
"quantity": 1,
"currency": null,
"unit_price": 100.0,
"total_price": 100.0
},
{
"description": "Parts BBB",
"quantity": 2,
"currency": null,
"unit_price": 50.0,
"total_price": 100.0
}
],
"subtotal": 400.0,
"tax": null,
"total": 400.0,
"currency": null,
"notes": "",
"others": null
} |
With VLM Run
import requests
from vlmrun.hub.schemas.document.invoice import Invoice
IMAGE_URL = "https://storage.googleapis.com/vlm-data-public-prod/hub/examples/document.invoice/invoice_1.jpg"
json_data = {
"image": IMAGE_URL,
"model": "vlm-1",
"domain": "document.invoice",
"json_schema": Invoice.model_json_schema(),
}
response = requests.post(
f"https://api.vlm.run/v1/image/generate",
headers={"Authorization": f"Bearer <your-api-key>"},
json=json_data,
)import instructor
from openai import OpenAI
from vlmrun.hub.schemas.document.invoice import Invoice
IMAGE_URL = "https://storage.googleapis.com/vlm-data-public-prod/hub/examples/document.invoice/invoice_1.jpg"
client = OpenAI()
completion = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Extract the invoice in JSON."},
{"type": "image_url", "image_url": {"url": IMAGE_URL}, "detail": "auto"}
]},
],
response_format=Invoice,
temperature=0,
)When working with the OpenAI Structured Outputs API, you need to ensure that the
response_formatis a valid Pydantic model with the supported types.
Locally with Ollama
Note: For certain vlmrun.common utilities, you will need to install our main Python SDK
via pip install vlmrun.
from ollama import chat
from vlmrun.common.image import encode_image
from vlmrun.common.utils import remote_image
from vlmrun.hub.schemas.document.invoice import Invoice
IMAGE_URL = "https://storage.googleapis.com/vlm-data-public-prod/hub/examples/document.invoice/invoice_1.jpg"
img = remote_image(IMAGE_URL)
chat_response = chat(
model="llama3.2-vision:11b",
format=Invoice.model_json_schema(),
messages=[
{
"role": "user",
"content": "Extract the invoice in JSON.",
"images": [encode_image(img, format="JPEG").split(",")[1]],
},
],
options={
"temperature": 0
},
)
response = Invoice.model_validate_json(
chat_response.message.content
)We periodically run popular VLMs on each of the examples & schemas in the catalog.yaml file and publish the results in the benchmarks directory.
| Provider | Model | Date | Results |
|---|---|---|---|
| OpenAI | gpt-4o-2024-11-20 | 2025-01-09 | link |
| OpenAI | gpt-4o-mini-2024-07-18 | 2025-01-09 | link |
| Gemini | gemini-2.0-flash-exp | 2025-01-10 | link |
| Ollama | llama3.2-vision:11b | 2025-01-10 | link |
| Ollama | Qwen2.5-VL-7B-Instruct:Q4_K_M_benxh | 2025-02-20 | link |
| Ollama + Instructor | Qwen2.5-VL-7B-Instruct:Q4_K_M_benxh | 2025-02-20 | link |
| Microsoft | phi-4 | 2025-01-10 | link |
Schemas are organized by industry for easy navigation:
vlmrun
└── hub
├── schemas
| ├── <industry>
| | ├── <use-case-1>.py
| | ├── <use-case-2>.py
| | └── ...
│ ├── aerospace
│ │ └── remote_sensing.py
│ ├── document # all document schemas are here
| | ├── invoice.py
| | ├── us_drivers_license.py
| | └── ...
│ ├── healthcare
│ │ └── medical_insurance_card.py
│ └── retail
│ │ └── ecommerce_product_caption.py
│ └── contrib # all contributions are welcome here!
│ └── <schema-name>.py
└── version.py
We're building this hub for the community, and contributions are always welcome! Follow the CONTRIBUTING and SCHEMA-GUIDELINES.md to get started.
- 💬 Send us an email at [email protected] or join our Discord for help.
- 📣 Follow us on Twitter, and LinkedIn to keep up-to-date on our products.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for vlmrun-hub
Similar Open Source Tools
vlmrun-hub
VLMRun Hub is a versatile tool for managing and running virtual machines in a centralized manner. It provides a user-friendly interface to easily create, start, stop, and monitor virtual machines across multiple hosts. With VLMRun Hub, users can efficiently manage their virtualized environments and streamline their workflow. The tool offers flexibility and scalability, making it suitable for both small-scale personal projects and large-scale enterprise deployments.
ramalama
The Ramalama project simplifies working with AI by utilizing OCI containers. It automatically detects GPU support, pulls necessary software in a container, and runs AI models. Users can list, pull, run, and serve models easily. The tool aims to support various GPUs and platforms in the future, making AI setup hassle-free.
functionary
Functionary is a language model that interprets and executes functions/plugins. It determines when to execute functions, whether in parallel or serially, and understands their outputs. Function definitions are given as JSON Schema Objects, similar to OpenAI GPT function calls. It offers documentation and examples on functionary.meetkai.com. The newest model, meetkai/functionary-medium-v3.1, is ranked 2nd in the Berkeley Function-Calling Leaderboard. Functionary supports models with different context lengths and capabilities for function calling and code interpretation. It also provides grammar sampling for accurate function and parameter names. Users can deploy Functionary models serverlessly using Modal.com.

Bindu
Bindu is an operating layer for AI agents that provides identity, communication, and payment capabilities. It delivers a production-ready service with a convenient API to connect, authenticate, and orchestrate agents across distributed systems using open protocols: A2A, AP2, and X402. Built with a distributed architecture, Bindu makes it fast to develop and easy to integrate with any AI framework. Transform any agent framework into a fully interoperable service for communication, collaboration, and commerce in the Internet of Agents.

firecrawl
Firecrawl is an API service that empowers AI applications with clean data from any website. It features advanced scraping, crawling, and data extraction capabilities. The repository is still in development, integrating custom modules into the mono repo. Users can run it locally but it's not fully ready for self-hosted deployment yet. Firecrawl offers powerful capabilities like scraping, crawling, mapping, searching, and extracting structured data from single pages, multiple pages, or entire websites with AI. It supports various formats, actions, and batch scraping. The tool is designed to handle proxies, anti-bot mechanisms, dynamic content, media parsing, change tracking, and more. Firecrawl is available as an open-source project under the AGPL-3.0 license, with additional features offered in the cloud version.
lego-ai-parser
Lego AI Parser is an open-source application that uses OpenAI to parse visible text of HTML elements. It is built on top of FastAPI, ready to set up as a server, and make calls from any language. It supports preset parsers for Google Local Results, Amazon Listings, Etsy Listings, Wayfair Listings, BestBuy Listings, Costco Listings, Macy's Listings, and Nordstrom Listings. Users can also design custom parsers by providing prompts, examples, and details about the OpenAI model under the classifier key.
chatgpt-exporter
A script to export the chat history of ChatGPT. Supports exporting to text, HTML, Markdown, PNG, and JSON formats. Also allows for exporting multiple conversations at once.

sparrow
Sparrow is an innovative open-source solution for efficient data extraction and processing from various documents and images. It seamlessly handles forms, invoices, receipts, and other unstructured data sources. Sparrow stands out with its modular architecture, offering independent services and pipelines all optimized for robust performance. One of the critical functionalities of Sparrow - pluggable architecture. You can easily integrate and run data extraction pipelines using tools and frameworks like LlamaIndex, Haystack, or Unstructured. Sparrow enables local LLM data extraction pipelines through Ollama or Apple MLX. With Sparrow solution you get API, which helps to process and transform your data into structured output, ready to be integrated with custom workflows. Sparrow Agents - with Sparrow you can build independent LLM agents, and use API to invoke them from your system. **List of available agents:** * **llamaindex** - RAG pipeline with LlamaIndex for PDF processing * **vllamaindex** - RAG pipeline with LLamaIndex multimodal for image processing * **vprocessor** - RAG pipeline with OCR and LlamaIndex for image processing * **haystack** - RAG pipeline with Haystack for PDF processing * **fcall** - Function call pipeline * **unstructured-light** - RAG pipeline with Unstructured and LangChain, supports PDF and image processing * **unstructured** - RAG pipeline with Weaviate vector DB query, Unstructured and LangChain, supports PDF and image processing * **instructor** - RAG pipeline with Unstructured and Instructor libraries, supports PDF and image processing. Works great for JSON response generation
AICentral
AI Central is a powerful tool designed to take control of your AI services with minimal overhead. It is built on Asp.Net Core and dotnet 8, offering fast web-server performance. The tool enables advanced Azure APIm scenarios, PII stripping logging to Cosmos DB, token metrics through Open Telemetry, and intelligent routing features. AI Central supports various endpoint selection strategies, proxying asynchronous requests, custom OAuth2 authorization, circuit breakers, rate limiting, and extensibility through plugins. It provides an extensibility model for easy plugin development and offers enriched telemetry and logging capabilities for monitoring and insights.

LocalAGI
LocalAGI is a powerful, self-hostable AI Agent platform that allows you to design AI automations without writing code. It provides a complete drop-in replacement for OpenAI's Responses APIs with advanced agentic capabilities. With LocalAGI, you can create customizable AI assistants, automations, chat bots, and agents that run 100% locally, without the need for cloud services or API keys. The platform offers features like no-code agents, web-based interface, advanced agent teaming, connectors for various platforms, comprehensive REST API, short & long-term memory capabilities, planning & reasoning, periodic tasks scheduling, memory management, multimodal support, extensible custom actions, fully customizable models, observability, and more.

crush
Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.
ext-apps
The @modelcontextprotocol/ext-apps repository contains the SDK and specification for MCP Apps Extension (SEP-1865). MCP Apps are a proposed standard to allow MCP Servers to display interactive UI elements in conversational MCP clients/chatbots. The repository includes SDKs for both app developers and host developers, along with examples showcasing real-world use cases. Users can build interactive UIs that run inside MCP-enabled chat clients and embed/communicate with MCP Apps in their chat applications. The SDK extends the Model Context Protocol by letting tools declare UI resources and enables bidirectional communication between the host and the UI. The repository also provides Agent Skills for building MCP Apps and instructions for installing them in AI coding agents.
Neosgenesis
Neogenesis System is an advanced AI decision-making framework that enables agents to 'think about how to think'. It implements a metacognitive approach with real-time learning, tool integration, and multi-LLM support, allowing AI to make expert-level decisions in complex environments. Key features include metacognitive intelligence, tool-enhanced decisions, real-time learning, aha-moment breakthroughs, experience accumulation, and multi-LLM support.
python-utcp
The Universal Tool Calling Protocol (UTCP) is a secure and scalable standard for defining and interacting with tools across various communication protocols. UTCP emphasizes scalability, extensibility, interoperability, and ease of use. It offers a modular core with a plugin-based architecture, making it extensible, testable, and easy to package. The repository contains the complete UTCP Python implementation with core components and protocol-specific plugins for HTTP, CLI, Model Context Protocol, file-based tools, and more.
For similar tasks
vlmrun-hub
VLMRun Hub is a versatile tool for managing and running virtual machines in a centralized manner. It provides a user-friendly interface to easily create, start, stop, and monitor virtual machines across multiple hosts. With VLMRun Hub, users can efficiently manage their virtualized environments and streamline their workflow. The tool offers flexibility and scalability, making it suitable for both small-scale personal projects and large-scale enterprise deployments.
For similar jobs

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.

AI-in-a-Box
AI-in-a-Box is a curated collection of solution accelerators that can help engineers establish their AI/ML environments and solutions rapidly and with minimal friction, while maintaining the highest standards of quality and efficiency. It provides essential guidance on the responsible use of AI and LLM technologies, specific security guidance for Generative AI (GenAI) applications, and best practices for scaling OpenAI applications within Azure. The available accelerators include: Azure ML Operationalization in-a-box, Edge AI in-a-box, Doc Intelligence in-a-box, Image and Video Analysis in-a-box, Cognitive Services Landing Zone in-a-box, Semantic Kernel Bot in-a-box, NLP to SQL in-a-box, Assistants API in-a-box, and Assistants API Bot in-a-box.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
generative-ai-cdk-constructs
The AWS Generative AI Constructs Library is an open-source extension of the AWS Cloud Development Kit (AWS CDK) that provides multi-service, well-architected patterns for quickly defining solutions in code to create predictable and repeatable infrastructure, called constructs. The goal of AWS Generative AI CDK Constructs is to help developers build generative AI solutions using pattern-based definitions for their architecture. The patterns defined in AWS Generative AI CDK Constructs are high level, multi-service abstractions of AWS CDK constructs that have default configurations based on well-architected best practices. The library is organized into logical modules using object-oriented techniques to create each architectural pattern model.

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
dify-helm
Deploy langgenius/dify, an LLM based chat bot app on kubernetes with helm chart.