
arxiv-mcp-server
A Model Context Protocol server for searching and analyzing arXiv papers
Stars: 125
The ArXiv MCP Server acts as a bridge between AI assistants and arXiv's research repository, enabling AI models to search for and access papers programmatically through the Message Control Protocol (MCP). It offers features like paper search, access, listing, local storage, and research prompts. Users can install it via Smithery or manually for Claude Desktop. The server provides tools for paper search, download, listing, and reading, along with specialized prompts for paper analysis. Configuration can be done through environment variables, and testing is supported with a test suite. The tool is released under the MIT License and is developed by the Pearl Labs Team.
README:



🔍 Enable AI assistants to search and access arXiv papers through a simple MCP interface.
The ArXiv MCP Server provides a bridge between AI assistants and arXiv's research repository through the Message Control Protocol (MCP). It allows AI models to search for papers and access their content in a programmatic way.
🤝 Contribute • 📝 Report Bug
- 🔎 Paper Search: Query arXiv papers with filters for date ranges and categories
- 📄 Paper Access: Download and read paper content
- 📋 Paper Listing: View all downloaded papers
- 🗃️ Local Storage: Papers are saved locally for faster access
- 📝 Prompts: A Set of Research Prompts
To install ArXiv Server for Claude Desktop automatically via Smithery:
npx -y @smithery/cli install arxiv-mcp-server --client claudeInstall using uv:
uv tool install arxiv-mcp-serverFor development:
# Clone and set up development environment
git clone https://github.com/blazickjp/arxiv-mcp-server.git
cd arxiv-mcp-server
# Create and activate virtual environment
uv venv
source .venv/bin/activate
# Install with test dependencies
uv pip install -e ".[test]"Add this configuration to your MCP client config file:
{
"mcpServers": {
"arxiv-mcp-server": {
"command": "uv",
"args": [
"tool",
"run",
"arxiv-mcp-server",
"--storage-path", "/path/to/paper/storage"
]
}
}
}For Development:
{
"mcpServers": {
"arxiv-mcp-server": {
"command": "uv",
"args": [
"--directory",
"path/to/cloned/arxiv-mcp-server",
"run",
"arxiv-mcp-server",
"--storage-path", "/path/to/paper/storage"
]
}
}
}The server provides four main tools:
Search for papers with optional filters:
result = await call_tool("search_papers", {
"query": "transformer architecture",
"max_results": 10,
"date_from": "2023-01-01",
"categories": ["cs.AI", "cs.LG"]
})Download a paper by its arXiv ID:
result = await call_tool("download_paper", {
"paper_id": "2401.12345"
})View all downloaded papers:
result = await call_tool("list_papers", {})Access the content of a downloaded paper:
result = await call_tool("read_paper", {
"paper_id": "2401.12345"
})The server offers specialized prompts to help analyze academic papers:
A comprehensive workflow for analyzing academic papers that only requires a paper ID:
result = await call_prompt("deep-paper-analysis", {
"paper_id": "2401.12345"
})This prompt includes:
- Detailed instructions for using available tools (list_papers, download_paper, read_paper, search_papers)
- A systematic workflow for paper analysis
- Comprehensive analysis structure covering:
- Executive summary
- Research context
- Methodology analysis
- Results evaluation
- Practical and theoretical implications
- Future research directions
- Broader impacts
Configure through environment variables:
| Variable | Purpose | Default |
|---|---|---|
ARXIV_STORAGE_PATH |
Paper storage location | ~/.arxiv-mcp-server/papers |
Run the test suite:
python -m pytestReleased under the MIT License. See the LICENSE file for details.
Made with ❤️ by the Pearl Labs Team
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for arxiv-mcp-server
Similar Open Source Tools
arxiv-mcp-server
The ArXiv MCP Server acts as a bridge between AI assistants and arXiv's research repository, enabling AI models to search for and access papers programmatically through the Message Control Protocol (MCP). It offers features like paper search, access, listing, local storage, and research prompts. Users can install it via Smithery or manually for Claude Desktop. The server provides tools for paper search, download, listing, and reading, along with specialized prompts for paper analysis. Configuration can be done through environment variables, and testing is supported with a test suite. The tool is released under the MIT License and is developed by the Pearl Labs Team.
ai-gateway
LangDB AI Gateway is an open-source enterprise AI gateway built in Rust. It provides a unified interface to all LLMs using the OpenAI API format, focusing on high performance, enterprise readiness, and data control. The gateway offers features like comprehensive usage analytics, cost tracking, rate limiting, data ownership, and detailed logging. It supports various LLM providers and provides OpenAI-compatible endpoints for chat completions, model listing, embeddings generation, and image generation. Users can configure advanced settings, such as rate limiting, cost control, dynamic model routing, and observability with OpenTelemetry tracing. The gateway can be run with Docker Compose and integrated with MCP tools for server communication.

instructor
Instructor is a tool that provides structured outputs from Large Language Models (LLMs) in a reliable manner. It simplifies the process of extracting structured data by utilizing Pydantic for validation, type safety, and IDE support. With Instructor, users can define models and easily obtain structured data without the need for complex JSON parsing, error handling, or retries. The tool supports automatic retries, streaming support, and extraction of nested objects, making it production-ready for various AI applications. Trusted by a large community of developers and companies, Instructor is used by teams at OpenAI, Google, Microsoft, AWS, and YC startups.

LTEngine
LTEngine is a free and open-source local AI machine translation API written in Rust. It is self-hosted and compatible with LibreTranslate. LTEngine utilizes large language models (LLMs) via llama.cpp, offering high-quality translations that rival or surpass DeepL for certain languages. It supports various accelerators like CUDA, Metal, and Vulkan, with the largest model 'gemma3-27b' fitting on a single consumer RTX 3090. LTEngine is actively developed, with a roadmap outlining future enhancements and features.
hud-python
hud-python is a Python library for creating interactive heads-up displays (HUDs) in video games. It provides a simple and flexible way to overlay information on the screen, such as player health, score, and notifications. The library is designed to be easy to use and customizable, allowing game developers to enhance the user experience by adding dynamic elements to their games. With hud-python, developers can create engaging HUDs that improve gameplay and provide important feedback to players.
claude-task-master
Claude Task Master is a task management system designed for AI-driven development with Claude, seamlessly integrating with Cursor AI. It allows users to configure tasks through environment variables, parse PRD documents, generate structured tasks with dependencies and priorities, and manage task status. The tool supports task expansion, complexity analysis, and smart task recommendations. Users can interact with the system through CLI commands for task discovery, implementation, verification, and completion. It offers features like task breakdown, dependency management, and AI-driven task generation, providing a structured workflow for efficient development.
cua
Cua is a tool for creating and running high-performance macOS and Linux virtual machines on Apple Silicon, with built-in support for AI agents. It provides libraries like Lume for running VMs with near-native performance, Computer for interacting with sandboxes, and Agent for running agentic workflows. Users can refer to the documentation for onboarding, explore demos showcasing AI-Gradio and GitHub issue fixing, and utilize accessory libraries like Core, PyLume, Computer Server, and SOM. Contributions are welcome, and the tool is open-sourced under the MIT License.
e2m
E2M is a Python library that can parse and convert various file types into Markdown format. It supports the conversion of multiple file formats, including doc, docx, epub, html, htm, url, pdf, ppt, pptx, mp3, and m4a. The ultimate goal of the E2M project is to provide high-quality data for Retrieval-Augmented Generation (RAG) and model training or fine-tuning. The core architecture consists of a Parser responsible for parsing various file types into text or image data, and a Converter responsible for converting text or image data into Markdown format.
SynapseML
SynapseML (previously known as MMLSpark) is an open-source library that simplifies the creation of massively scalable machine learning (ML) pipelines. It provides simple, composable, and distributed APIs for various machine learning tasks such as text analytics, vision, anomaly detection, and more. Built on Apache Spark, SynapseML allows seamless integration of models into existing workflows. It supports training and evaluation on single-node, multi-node, and resizable clusters, enabling scalability without resource wastage. Compatible with Python, R, Scala, Java, and .NET, SynapseML abstracts over different data sources for easy experimentation. Requires Scala 2.12, Spark 3.4+, and Python 3.8+.
langcorn
LangCorn is an API server that enables you to serve LangChain models and pipelines with ease, leveraging the power of FastAPI for a robust and efficient experience. It offers features such as easy deployment of LangChain models and pipelines, ready-to-use authentication functionality, high-performance FastAPI framework for serving requests, scalability and robustness for language processing applications, support for custom pipelines and processing, well-documented RESTful API endpoints, and asynchronous processing for faster response times.
functionary
Functionary is a language model that interprets and executes functions/plugins. It determines when to execute functions, whether in parallel or serially, and understands their outputs. Function definitions are given as JSON Schema Objects, similar to OpenAI GPT function calls. It offers documentation and examples on functionary.meetkai.com. The newest model, meetkai/functionary-medium-v3.1, is ranked 2nd in the Berkeley Function-Calling Leaderboard. Functionary supports models with different context lengths and capabilities for function calling and code interpretation. It also provides grammar sampling for accurate function and parameter names. Users can deploy Functionary models serverlessly using Modal.com.
CrackSQL
CrackSQL is a powerful SQL dialect translation tool that integrates rule-based strategies with large language models (LLMs) for high accuracy. It enables seamless conversion between dialects (e.g., PostgreSQL → MySQL) with flexible access through Python API, command line, and web interface. The tool supports extensive dialect compatibility, precision & advanced processing, and versatile access & integration. It offers three modes for dialect translation and demonstrates high translation accuracy over collected benchmarks. Users can deploy CrackSQL using PyPI package installation or source code installation methods. The tool can be extended to support additional syntax, new dialects, and improve translation efficiency. The project is actively maintained and welcomes contributions from the community.
agentlang
AgentLang is an open-source programming language and framework designed for solving complex tasks with the help of AI agents. It allows users to build business applications rapidly from high-level specifications, making it more efficient than traditional programming languages. The language is data-oriented and declarative, with a syntax that is intuitive and closer to natural languages. AgentLang introduces innovative concepts such as first-class AI agents, graph-based hierarchical data model, zero-trust programming, declarative dataflow, resolvers, interceptors, and entity-graph-database mapping.
browser4
Browser4 is a lightning-fast, coroutine-safe browser designed for AI integration with large language models. It offers ultra-fast automation, deep web understanding, and powerful data extraction APIs. Users can automate the browser, extract data at scale, and perform tasks like summarizing products, extracting product details, and finding specific links. The tool is developer-friendly, supports AI-powered automation, and provides advanced features like X-SQL for precise data extraction. It also offers RPA capabilities, browser control, and complex data extraction with X-SQL. Browser4 is suitable for web scraping, data extraction, automation, and AI integration tasks.
mcphub.nvim
MCPHub.nvim is a powerful Neovim plugin that integrates MCP (Model Context Protocol) servers into your workflow. It offers a centralized config file for managing servers and tools, with an intuitive UI for testing resources. Ideal for LLM integration, it provides programmatic API access and interactive testing through the `:MCPHub` command.
open-edison
OpenEdison is a secure MCP control panel that connects AI to data/software with additional security controls to reduce data exfiltration risks. It helps address the lethal trifecta problem by providing visibility, monitoring potential threats, and alerting on data interactions. The tool offers features like data leak monitoring, controlled execution, easy configuration, visibility into agent interactions, a simple API, and Docker support. It integrates with LangGraph, LangChain, and plain Python agents for observability and policy enforcement. OpenEdison helps gain observability, control, and policy enforcement for AI interactions with systems of records, existing company software, and data to reduce risks of AI-caused data leakage.
For similar tasks

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
Awesome-CVPR2024-ECCV2024-AIGC
A Collection of Papers and Codes for CVPR 2024 AIGC. This repository compiles and organizes research papers and code related to CVPR 2024 and ECCV 2024 AIGC (Artificial Intelligence and Graphics Computing). It serves as a valuable resource for individuals interested in the latest advancements in the field of computer vision and artificial intelligence. Users can find a curated list of papers and accompanying code repositories for further exploration and research. The repository encourages collaboration and contributions from the community through stars, forks, and pull requests.
LLMs-in-science
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.
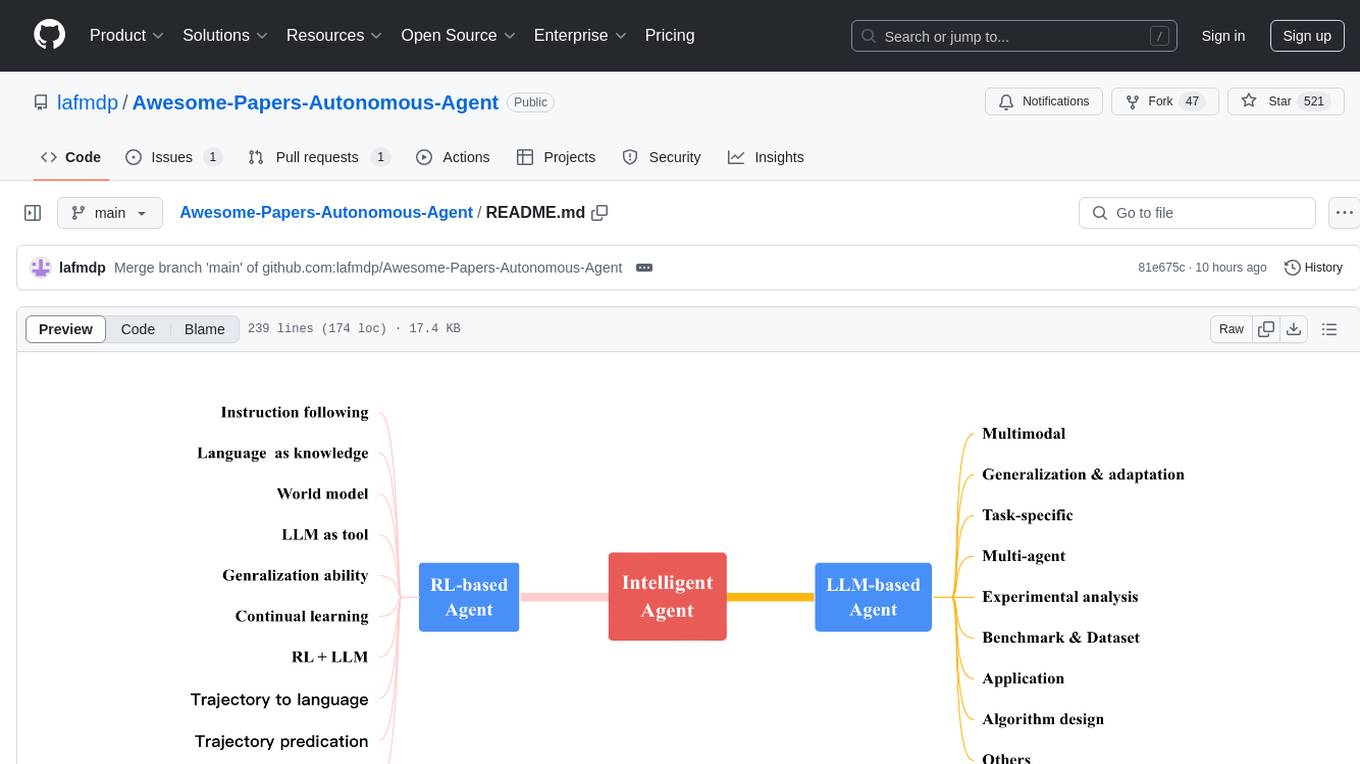
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.
awesome-lifelong-llm-agent
This repository is a collection of papers and resources related to Lifelong Learning of Large Language Model (LLM) based Agents. It focuses on continual learning and incremental learning of LLM agents, identifying key modules such as Perception, Memory, and Action. The repository serves as a roadmap for understanding lifelong learning in LLM agents and provides a comprehensive overview of related research and surveys.

LLM-Agent-Survey
LLM-Agent-Survey is a comprehensive repository that provides a curated list of papers related to Large Language Model (LLM) agents. The repository categorizes papers based on LLM-Profiled Roles and includes high-quality publications from prestigious conferences and journals. It aims to offer a systematic understanding of LLM-based agents, covering topics such as tool use, planning, and feedback learning. The repository also includes unpublished papers with insightful analysis and novelty, marked for future updates. Users can explore a wide range of surveys, tool use cases, planning workflows, and benchmarks related to LLM agents.
For similar jobs

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.