
cyclops
A toolkit for evaluating and monitoring AI models in clinical settings
Stars: 79

Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
README:
![]()


![]()
![]()
![]()
![]()
cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely:
-
data- Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data -
models- Use common model implementations using scikit-learn and PyTorch -
tasks- Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data -
evaluate- Evaluate models on clinical prediction tasks -
monitor- Detect dataset shift relevant for clinical use cases -
report- Create model report cards for clinical ML models
cyclops also provides example end-to-end use case implementations on clinical datasets such as
python3 -m pip install pycyclopscyclops has many optional dependencies that are used for specific functionality. For
example, the monai library is used for loading
DICOM images to create datasets. Hence, monai can be installed using
python3 -m pip install pycyclops[monai]. Specific sets of dependencies are listed
below.
| Dependency | pip extra | Notes |
|---|---|---|
| xgboost | xgboost | Allows use of XGBoost model |
| torch | torch | Allows use of PyTorch models |
| torchvision | torchvision | Allows use of Torchvision library |
| torchxrayvision | torchxrayvision | Uses TorchXRayVision library |
| monai | monai | Uses MONAI to load and transform images |
| alibi | alibi | Uses Alibi for additional explainability functionality |
| alibi-detect | alibi-detect | Uses Alibi Detect for dataset shift detection |
The development environment can be set up using poetry. Hence, make sure it is installed and then run:
python3 -m poetry install
source $(poetry env info --path)/bin/activateIn order to install dependencies for testing (codestyle, unit tests, integration tests), run:
python3 -m poetry install --with testAPI documentation is built using Sphinx and can be locally built by:
python3 -m poetry install --with docs
cd docs
make html SPHINXOPTS="-D nbsphinx_allow_errors=True"Contributing to cyclops is welcomed. See Contributing for guidelines.
If you need to build the documentations locally, make sure to install Pandoc in addition to docs poetry group.
To use jupyter notebooks, the python virtual environment can be installed and used inside an IPython kernel. After activating the virtual environment, run:
python3 -m ipykernel install --user --name <name_of_kernel>Now, you can navigate to the notebook's Kernel tab and set it as
<name_of_kernel>.
Reference to cite when you use cyclops in a project or a research paper:
@article {Krishnan2022.12.02.22283021,
author = {Krishnan, Amrit and Subasri, Vallijah and McKeen, Kaden and Kore, Ali and Ogidi, Franklin and Alinoori, Mahshid and Lalani, Nadim and Dhalla, Azra and Verma, Amol and Razak, Fahad and Pandya, Deval and Dolatabadi, Elham},
title = {CyclOps: Cyclical development towards operationalizing ML models for health},
elocation-id = {2022.12.02.22283021},
year = {2022},
doi = {10.1101/2022.12.02.22283021},
publisher = {Cold Spring Harbor Laboratory Press},
URL = {https://www.medrxiv.org/content/early/2022/12/08/2022.12.02.22283021},
journal = {medRxiv}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cyclops
Similar Open Source Tools
cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
open-unlearning
OpenUnlearning is an easily extensible framework that unifies LLM unlearning evaluation benchmarks. It provides efficient implementations of TOFU and MUSE unlearning benchmarks, supporting 5 unlearning methods, 3+ datasets, 6+ evaluation metrics, and 7+ LLMs. Users can easily extend the framework to incorporate more variants, collaborate by adding new benchmarks, unlearning methods, datasets, and evaluation metrics, and drive progress in the field.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.
ModelGenerator
AIDO.ModelGenerator is a software stack designed for developing AI-driven Digital Organisms. It enables researchers to adapt pretrained models and generate finetuned models for various tasks. The framework supports rapid prototyping with experiments like applying pre-trained models to new data, developing finetuning tasks, benchmarking models, and testing new architectures. Built on PyTorch, HuggingFace, and Lightning, it facilitates seamless integration with these ecosystems. The tool caters to cross-disciplinary teams in ML & Bio, offering installation, usage, tutorials, and API reference in its documentation.
lance
Lance is a modern columnar data format optimized for ML workflows and datasets. It offers high-performance random access, vector search, zero-copy automatic versioning, and ecosystem integrations with Apache Arrow, Pandas, Polars, and DuckDB. Lance is designed to address the challenges of the ML development cycle, providing a unified data format for collection, exploration, analytics, feature engineering, training, evaluation, deployment, and monitoring. It aims to reduce data silos and streamline the ML development process.
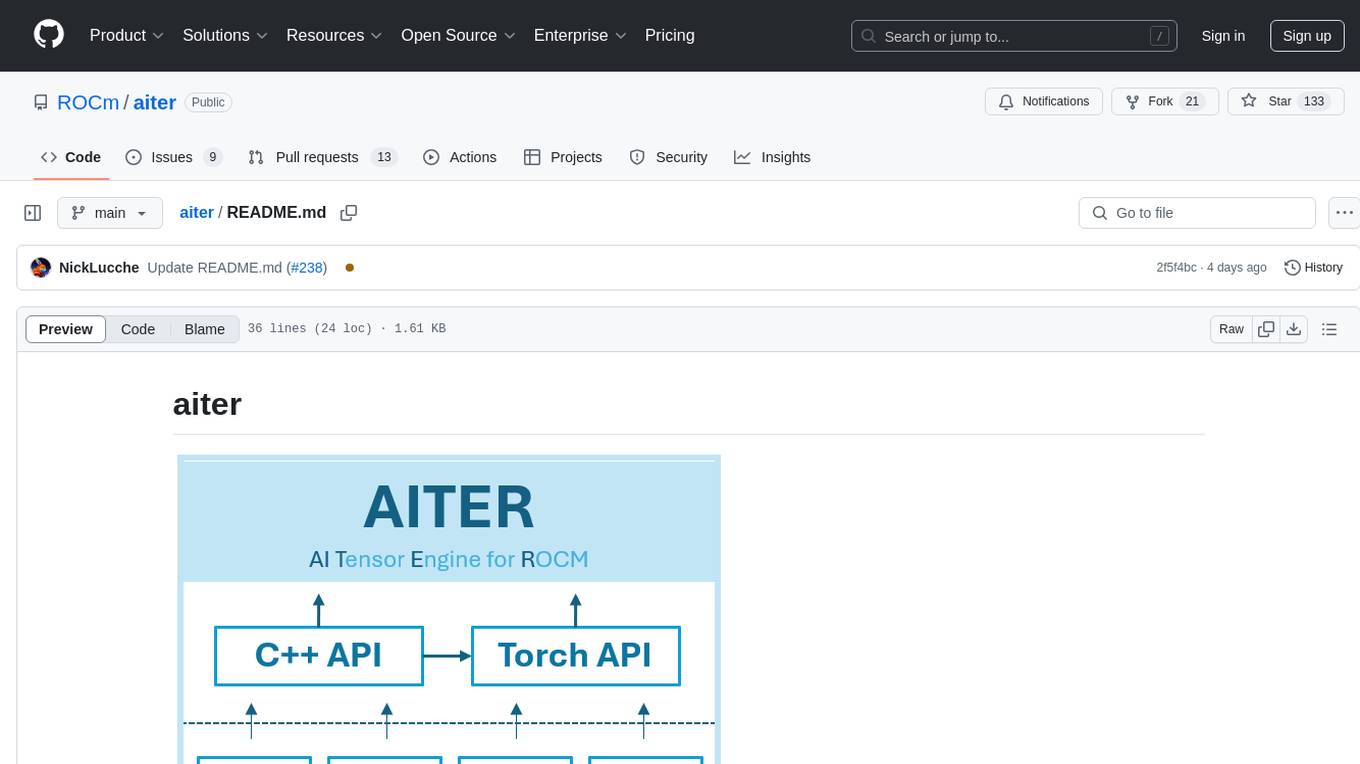
aiter
AITER is AMD’s centralized repository that supports various high performance AI operators for AI workloads acceleration. It serves as a unified platform for customer operator-level requests, catering to different customer needs. Developers can focus on operators and customers can integrate this collection into their own frameworks. Features include C++ and Python level APIs, kernels from triton/ck/asm, support for inference, training, GEMM, and communication kernels for workarounds in any kernel-framework combination for any architecture limitation.
AIQC
AIQC is an open source Python package that provides a declarative API for end-to-end MLOps in order to make deep learning more accessible to researchers. It utilizes a SQLite object-relational model for machine learning objects and stacks standardized workflows for various analyses, data types, and libraries. The benefits include a 90% reduction in data wrangling, reproducibility, and no need to install and maintain application and database servers for experiment tracking. AIQC is pip-installable and provides a Dash-Plotly UI for real-time experiment tracking.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.

slideflow
Slideflow is a deep learning library for digital pathology, offering a user-friendly interface for model development. It is designed for medical researchers and AI enthusiasts, providing an accessible platform for developing state-of-the-art pathology models. Slideflow offers customizable training pipelines, robust slide processing and stain normalization toolkit, support for weakly-supervised or strongly-supervised labels, built-in foundation models, multiple-instance learning, self-supervised learning, generative adversarial networks, explainability tools, layer activation analysis tools, uncertainty quantification, interactive user interface for model deployment, and more. It supports both PyTorch and Tensorflow, with optional support for Libvips for slide reading. Slideflow can be installed via pip, Docker container, or from source, and includes non-commercial add-ons for additional tools and pretrained models. It allows users to create projects, extract tiles from slides, train models, and provides evaluation tools like heatmaps and mosaic maps.

vision-parse
Vision Parse is a tool that leverages Vision Language Models to parse PDF documents into beautifully formatted markdown content. It offers smart content extraction, content formatting, multi-LLM support, PDF document support, and local model hosting using Ollama. Users can easily convert PDFs to markdown with high precision and preserve document hierarchy and styling. The tool supports multiple Vision LLM providers like OpenAI, LLama, and Gemini for accuracy and speed, making document processing efficient and effortless.
ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project facilitates sharing and exchanging technologies related to large model semantic cache through open-source collaboration.

beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.

pipeline
Pipeline is a Python library designed for constructing computational flows for AI/ML models. It supports both development and production environments, offering capabilities for inference, training, and finetuning. The library serves as an interface to Mystic, enabling the execution of pipelines at scale and on enterprise GPUs. Users can also utilize this SDK with Pipeline Core on a private hosted cluster. The syntax for defining AI/ML pipelines is reminiscent of sessions in Tensorflow v1 and Flows in Prefect.
For similar tasks
cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
gaussian-painters
This tool is a fork of the 3D Gaussian Splatting code. It allows users to create a dataset ready to be trained with the Gaussian Splatting code. The dataset can be used for various experiments, such as creating orthogonal images, steganography, and lenticular effects. The tool also includes a visualizer that allows users to visualize the "painting" process during the Gaussian Splatting optimization.
UHGEval
UHGEval is a comprehensive framework designed for evaluating the hallucination phenomena. It includes UHGEval, a framework for evaluating hallucination, XinhuaHallucinations dataset, and UHGEval-dataset pipeline for creating XinhuaHallucinations. The framework offers flexibility and extensibility for evaluating common hallucination tasks, supporting various models and datasets. Researchers can use the open-source pipeline to create customized datasets. Supported tasks include QA, dialogue, summarization, and multi-choice tasks.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.
ollama-ebook-summary
The 'ollama-ebook-summary' repository is a Python project that creates bulleted notes summaries of books and long texts, particularly in epub and pdf formats with ToC metadata. It automates the extraction of chapters, splits them into ~2000 token chunks, and allows for asking arbitrary questions to parts of the text for improved granularity of response. The tool aims to provide summaries for each page of a book rather than a one-page summary of the entire document, enhancing content curation and knowledge sharing capabilities.

agentneo
AgentNeo is a Python package that provides functionalities for project, trace, dataset, experiment management. It allows users to authenticate, create projects, trace agents and LangGraph graphs, manage datasets, and run experiments with metrics. The tool aims to streamline AI project management and analysis by offering a comprehensive set of features.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.
RagaAI-Catalyst
RagaAI Catalyst is a comprehensive platform designed to enhance the management and optimization of LLM projects. It offers features such as project management, dataset management, evaluation management, trace management, prompt management, synthetic data generation, and guardrail management. These functionalities enable efficient evaluation and safeguarding of LLM applications.
For similar jobs
cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.