
thinc
🔮 A refreshing functional take on deep learning, compatible with your favorite libraries
Stars: 2816
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models.
README:
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models. Previous versions of Thinc have been running quietly in production in thousands of companies, via both spaCy and Prodigy. We wrote the new version to let users compose, configure and deploy custom models built with their favorite framework.
![]()



-
Type-check your model definitions with custom types and
mypyplugin. - Wrap PyTorch, TensorFlow and MXNet models for use in your network.
- Concise functional-programming approach to model definition, using composition rather than inheritance.
- Optional custom infix notation via operator overloading.
- Integrated config system to describe trees of objects and hyperparameters.
- Choice of extensible backends.
- Read more →
Thinc is compatible with Python 3.6+ and runs on Linux, macOS and
Windows. The latest releases with binary wheels are available from
pip. Before you install Thinc and its
dependencies, make sure that your pip, setuptools and wheel are up to
date. For the most recent releases, pip 19.3 or newer is recommended.
pip install -U pip setuptools wheel
pip install thincSee the extended installation docs for details on optional dependencies for different backends and GPU. You might also want to set up static type checking to take advantage of Thinc's type system.
⚠️ If you have installed PyTorch and you are using Python 3.7+, uninstall the packagedataclasseswithpip uninstall dataclasses, since it may have been installed by PyTorch and is incompatible with Python 3.7+.
Also see the /examples directory and
usage documentation for more examples. Most examples
are Jupyter notebooks – to launch them on
Google Colab (with GPU support!) click on
the button next to the notebook name.
| Notebook | Description |
|---|---|
intro_to_thinc |
Everything you need to know to get started. Composing and training a model on the MNIST data, using config files, registering custom functions and wrapping PyTorch, TensorFlow and MXNet models. |
transformers_tagger_bert |
How to use Thinc, transformers and PyTorch to train a part-of-speech tagger. From model definition and config to the training loop. |
pos_tagger_basic_cnn |
Implementing and training a basic CNN for part-of-speech tagging model without external dependencies and using different levels of Thinc's config system. |
parallel_training_ray |
How to set up synchronous and asynchronous parameter server training with Thinc and Ray. |
| Documentation | Description |
|---|---|
| Introduction | Everything you need to know. |
| Concept & Design | Thinc's conceptual model and how it works. |
| Defining and using models | How to compose models and update state. |
| Configuration system | Thinc's config system and function registry. |
| Integrating PyTorch, TensorFlow & MXNet | Interoperability with machine learning frameworks |
| Layers API | Weights layers, transforms, combinators and wrappers. |
| Type Checking | Type-check your model definitions and more. |
| Module | Description |
|---|---|
thinc.api |
User-facing API. All classes and functions should be imported from here. |
thinc.types |
Custom types and dataclasses. |
thinc.model |
The Model class. All Thinc models are an instance (not a subclass) of Model. |
thinc.layers |
The layers. Each layer is implemented in its own module. |
thinc.shims |
Interface for external models implemented in PyTorch, TensorFlow etc. |
thinc.loss |
Functions to calculate losses. |
thinc.optimizers |
Functions to create optimizers. Currently supports "vanilla" SGD, Adam and RAdam. |
thinc.schedules |
Generators for different rates, schedules, decays or series. |
thinc.backends |
Backends for numpy and cupy. |
thinc.config |
Config parsing and validation and function registry system. |
thinc.util |
Utilities and helper functions. |
Thinc uses black for auto-formatting,
flake8 for linting and
mypy for type checking. All code is
written compatible with Python 3.6+, with type hints wherever possible. See
the type reference for more details on
Thinc's custom types.
Building Thinc from source requires the full dependencies listed in
requirements.txt to be installed. You'll also need a
compiler to build the C extensions.
git clone https://github.com/explosion/thinc
cd thinc
python -m venv .env
source .env/bin/activate
pip install -U pip setuptools wheel
pip install -r requirements.txt
pip install --no-build-isolation .Alternatively, install in editable mode:
pip install -r requirements.txt
pip install --no-build-isolation --editable .Or by setting PYTHONPATH:
export PYTHONPATH=`pwd`
pip install -r requirements.txt
python setup.py build_ext --inplaceThinc comes with an extensive test suite. The following should all pass and not report any warnings or errors:
python -m pytest thinc # test suite
python -m mypy thinc # type checks
python -m flake8 thinc # lintingTo view test coverage, you can run python -m pytest thinc --cov=thinc. We aim
for a 100% test coverage. This doesn't mean that we meticulously write tests for
every single line – we ignore blocks that are not relevant or difficult to test
and make sure that the tests execute all code paths.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for thinc
Similar Open Source Tools
thinc
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models.
clai
Clai is a command line context-feeder for AI tasks, supporting MCP client, vendor agnosticism, conversations, rate limit circumvention, profiles, and Unix-like functionality. Users can easily combine and tweak features for diverse use cases. Supported vendors include OpenAI, Anthropic, Mistral, Deepseek, Novita AI, Ollama, and Inception. Users need API keys for model access. Installation via 'go install' or setup script. 'clai help' provides guidance on usage. Glow can be installed for formatted markdown output.

spaCy
spaCy is an industrial-strength Natural Language Processing (NLP) library in Python and Cython. It incorporates the latest research and is designed for real-world applications. The library offers pretrained pipelines supporting 70+ languages, with advanced neural network models for tasks such as tagging, parsing, named entity recognition, and text classification. It also facilitates multi-task learning with pretrained transformers like BERT, along with a production-ready training system and streamlined model packaging, deployment, and workflow management. spaCy is commercial open-source software released under the MIT license.
rag-chatbot
The RAG ChatBot project combines Lama.cpp, Chroma, and Streamlit to build a Conversation-aware Chatbot and a Retrieval-augmented generation (RAG) ChatBot. The RAG Chatbot works by taking a collection of Markdown files as input and provides answers based on the context provided by those files. It utilizes a Memory Builder component to load Markdown pages, divide them into sections, calculate embeddings, and save them in an embedding database. The chatbot retrieves relevant sections from the database, rewrites questions for optimal retrieval, and generates answers using a local language model. It also remembers previous interactions for more accurate responses. Various strategies are implemented to deal with context overflows, including creating and refining context, hierarchical summarization, and async hierarchical summarization.
AirConnect-Synology
AirConnect-Synology is a minimal Synology package that allows users to use AirPlay to stream to UPnP/Sonos & Chromecast devices that do not natively support AirPlay. It is compatible with DSM 7.0 and DSM 7.1, and provides detailed information on installation, configuration, supported devices, troubleshooting, and more. The package automates the installation and usage of AirConnect on Synology devices, ensuring compatibility with various architectures and firmware versions. Users can customize the configuration using the airconnect.conf file and adjust settings for specific speakers like Sonos, Bose SoundTouch, and Pioneer/Phorus/Play-Fi.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.

airunner
AI Runner is a multi-modal AI interface that allows users to run open-source large language models and AI image generators on their own hardware. The tool provides features such as voice-based chatbot conversations, text-to-speech, speech-to-text, vision-to-text, text generation with large language models, image generation capabilities, image manipulation tools, utility functions, and more. It aims to provide a stable and user-friendly experience with security updates, a new UI, and a streamlined installation process. The application is designed to run offline on users' hardware without relying on a web server, offering a smooth and responsive user experience.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.
DiffusionToolkit
Diffusion Toolkit is an image metadata-indexer and viewer for AI-generated images. It helps you organize, search, and sort your ever-growing collection. Key features include: - Scanning images and storing prompts and other metadata (PNGInfo) - Searching for images using simple queries or filters - Viewing images and metadata easily - Tagging images with favorites, ratings, and NSFW flags - Sorting images by date created, aesthetic score, or rating - Auto-tagging NSFW images by keywords - Blurring images tagged as NSFW - Creating and managing albums - Viewing and searching prompts - Drag-and-drop functionality Diffusion Toolkit supports various image formats, including JPG/JPEG, PNG, WebP, and TXT metadata. It also supports metadata formats from popular AI image generators like AUTOMATIC1111, InvokeAI, NovelAI, Stable Diffusion, and more. You can use Diffusion Toolkit even on images without metadata and still enjoy features like rating and album management.

coreply
Coreply is an open-source Android app that provides texting suggestions while typing, enhancing the typing experience with intelligent, context-aware suggestions. It supports various texting apps and offers real-time AI suggestions, customizable LLM settings, and ensures no data collection. Users can install the app, configure it with an API key, and start receiving suggestions while typing in messaging apps. The tool supports different AI models from providers like OpenAI, Google AI Studio, Openrouter, Groq, and Codestral for chat completion and fill-in-the-middle tasks.

cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
SimpleAICV_pytorch_training_examples
SimpleAICV_pytorch_training_examples is a repository that provides simple training and testing examples for various computer vision tasks such as image classification, object detection, semantic segmentation, instance segmentation, knowledge distillation, contrastive learning, masked image modeling, OCR text detection, OCR text recognition, human matting, salient object detection, interactive segmentation, image inpainting, and diffusion model tasks. The repository includes support for multiple datasets and networks, along with instructions on how to prepare datasets, train and test models, and use gradio demos. It also offers pretrained models and experiment records for download from huggingface or Baidu-Netdisk. The repository requires specific environments and package installations to run effectively.
spandrel
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.
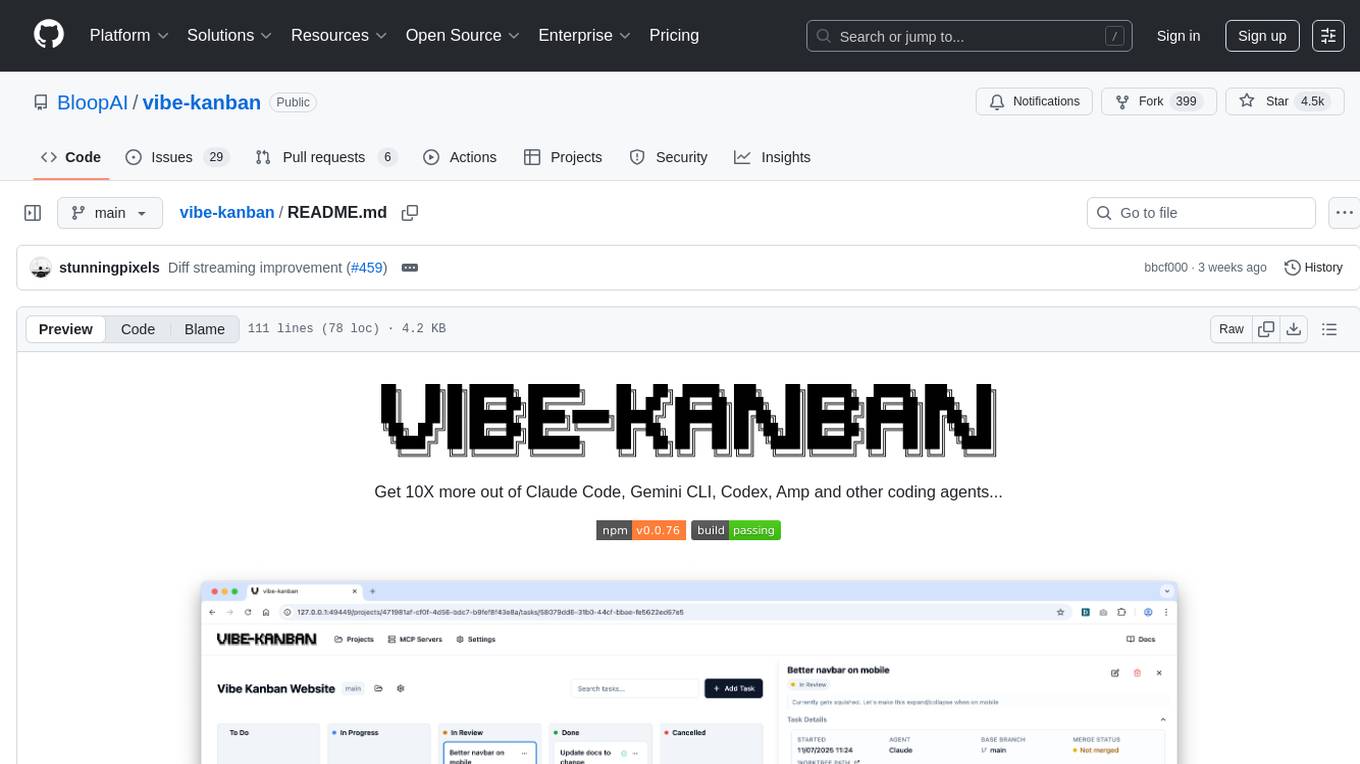
vibe-kanban
Vibe Kanban is a tool designed to streamline the process of planning, reviewing, and orchestrating tasks for human engineers working with AI coding agents. It allows users to easily switch between different coding agents, orchestrate their execution, review work, start dev servers, and track task statuses. The tool centralizes the configuration of coding agent MCP configs, providing a comprehensive solution for managing coding tasks efficiently.

pgvecto.rs
pgvecto.rs is a Postgres extension written in Rust that provides vector similarity search functions. It offers ultra-low-latency, high-precision vector search capabilities, including sparse vector search and full-text search. With complete SQL support, async indexing, and easy data management, it simplifies data handling. The extension supports various data types like FP16/INT8, binary vectors, and Matryoshka embeddings. It ensures system performance with production-ready features, high availability, and resource efficiency. Security and permissions are managed through easy access control. The tool allows users to create tables with vector columns, insert vector data, and calculate distances between vectors using different operators. It also supports half-precision floating-point numbers for better performance and memory usage optimization.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.