
MockingBird
🚀AI拟声: 5秒内克隆您的声音并生成任意语音内容 Clone a voice in 5 seconds to generate arbitrary speech in real-time
Stars: 35119
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.
README:
🚧 While I no longer actively update this repo, you can find me continuously pushing this tech forward to good side and open-source. Join me at https://discord.gg/wrAGwSH5 .

🌍 Chinese supported mandarin and tested with multiple datasets: aidatatang_200zh, magicdata, aishell3, data_aishell, and etc.
🤩 PyTorch worked for pytorch, tested in version of 1.9.0(latest in August 2021), with GPU Tesla T4 and GTX 2060
🌍 Windows + Linux run in both Windows OS and linux OS (even in M1 MACOS)
🤩 Easy & Awesome effect with only newly-trained synthesizer, by reusing the pretrained encoder/vocoder
🌍 Webserver Ready to serve your result with remote calling
Follow the original repo to test if you got all environment ready. **Python 3.7 or higher ** is needed to run the toolbox.
- Install PyTorch.
If you get an
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )This error is probably due to a low version of python, try using 3.9 and it will install successfully
- Install ffmpeg.
- Run
pip install -r requirements.txtto install the remaining necessary packages.
The recommended environment here is
Repo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtwebrtcvad-wheelsbecauserequiremants. txtwas exported a few months ago, so it doesn't work with newer versions
- Install webrtcvad
pip install webrtcvad-wheels(If you need)
or
-
install dependencies with
condaormambaconda env create -n env_name -f env.ymlmamba env create -n env_name -f env.ymlwill create a virtual environment where necessary dependencies are installed. Switch to the new environment by
conda activate env_nameand enjoy it.env.yml only includes the necessary dependencies to run the project,temporarily without monotonic-align. You can check the official website to install the GPU version of pytorch.
The following steps are a workaround to directly use the original
demo_toolbox.pywithout the changing of codes.Since the major issue comes with the PyQt5 packages used in
demo_toolbox.pynot compatible with M1 chips, were one to attempt on training models with the M1 chip, either that person can forgodemo_toolbox.py, or one can try theweb.pyin the project.
1.2.1 Install PyQt5, with ref here.
- Create and open a Rosetta Terminal, with ref here.
- Use system Python to create a virtual environment for the project
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate - Upgrade pip and install
PyQt5pip install --upgrade pip pip install pyqt5
Both packages seem to be unique to this project and are not seen in the original Real-Time Voice Cloning project. When installing with
pip install, both packages lack wheels so the program tries to directly compile from c code and could not findPython.h.
-
Install
pyworld-
brew install pythonPython.hcan come with Python installed by brew -
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/HeadersThe filepath of brew-installedPython.his unique to M1 MacOS and listed above. One needs to manually add the path to the environment variables. -
pip install pyworldthat should do.
-
-
Install
ctc-segmentationSame method does not apply to
ctc-segmentation, and one needs to compile it from the source code on github.git clone https://github.com/lumaku/ctc-segmentation.gitcd ctc-segmentation-
source /PathToMockingBird/venv/bin/activateIf the virtual environment hasn't been deployed, activate it. cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx-
/usr/bin/arch -x86_64 python setup.py buildBuild with x86 architecture. -
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-buildInstall with x86 architecture.
-
/usr/bin/arch -x86_64 pip install torch torchvision torchaudioPip installingPyTorchas an example, articulate that it's installed with x86 architecture -
pip install ffmpegInstall ffmpeg -
pip install -r requirements.txtInstall other requirements.
To run the project on x86 architecture. ref.
-
vim /PathToMockingBird/venv/bin/pythonM1Create an executable filepythonM1to condition python interpreter at/PathToMockingBird/venv/bin. - Write in the following content:
#!/usr/bin/env zsh mydir=${0:a:h} /usr/bin/arch -x86_64 $mydir/python "$@" -
chmod +x pythonM1Set the file as executable. - If using PyCharm IDE, configure project interpreter to
pythonM1(steps here), if using command line python, run/PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
Note that we are using the pretrained encoder/vocoder but not synthesizer, since the original model is incompatible with the Chinese symbols. It means the demo_cli is not working at this moment, so additional synthesizer models are required.
You can either train your models or use existing ones:
-
Preprocess with the audios and the mel spectrograms:
python encoder_preprocess.py <datasets_root>Allowing parameter--dataset {dataset}to support the datasets you want to preprocess. Only the train set of these datasets will be used. Possible names: librispeech_other, voxceleb1, voxceleb2. Use comma to sperate multiple datasets. -
Train the encoder:
python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
For training, the encoder uses visdom. You can disable it with
--no_visdom, but it's nice to have. Run "visdom" in a separate CLI/process to start your visdom server.
-
Download dataset and unzip: make sure you can access all .wav in folder
-
Preprocess with the audios and the mel spectrograms:
python pre.py <datasets_root>Allowing parameter--dataset {dataset}to support aidatatang_200zh, magicdata, aishell3, data_aishell, etc.If this parameter is not passed, the default dataset will be aidatatang_200zh. -
Train the synthesizer:
python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer -
Go to next step when you see attention line show and loss meet your need in training folder synthesizer/saved_models/.
Thanks to the community, some models will be shared:
| author | Download link | Preview Video | Info |
|---|---|---|---|
| @author | https://pan.baidu.com/s/1iONvRxmkI-t1nHqxKytY3g Baidu 4j5d | 75k steps trained by multiple datasets | |
| @author | https://pan.baidu.com/s/1fMh9IlgKJlL2PIiRTYDUvw Baidu code:om7f | 25k steps trained by multiple datasets, only works under version 0.0.1 | |
| @FawenYo | https://yisiou-my.sharepoint.com/:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/EWFWDHzee-NNg9TWdKckCc4BC7bK2j9cCbOWn0-_tK0nOg?e=n0gGgC | input output | 200k steps with local accent of Taiwan, only works under version 0.0.1 |
| @miven | https://pan.baidu.com/s/1PI-hM3sn5wbeChRryX-RCQ code: 2021 https://www.aliyundrive.com/s/AwPsbo8mcSP code: z2m0 | https://www.bilibili.com/video/BV1uh411B7AD/ | only works under version 0.0.1 |
note: vocoder has little difference in effect, so you may not need to train a new one.
- Preprocess the data:
python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>replace with your dataset root,<synthesizer_model_path>replace with directory of your best trained models of sythensizer, e.g. sythensizer\saved_mode\xxx
-
Train the wavernn vocoder:
python vocoder_train.py mandarin <datasets_root> -
Train the hifigan vocoder
python vocoder_train.py mandarin <datasets_root> hifigan
You can then try to run:python web.py and open it in browser, default as http://localhost:8080
You can then try the toolbox:
python demo_toolbox.py -d <datasets_root>
You can then try the command:
python gen_voice.py <text_file.txt> your_wav_file.wav
you may need to install cn2an by "pip install cn2an" for better digital number result.
This repository is forked from Real-Time-Voice-Cloning which only support English.
| URL | Designation | Title | Implementation source |
|---|---|---|---|
| 1803.09017 | GlobalStyleToken (synthesizer) | Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis | This repo |
| 2010.05646 | HiFi-GAN (vocoder) | Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis | This repo |
| 2106.02297 | Fre-GAN (vocoder) | Fre-GAN: Adversarial Frequency-consistent Audio Synthesis | This repo |
| 1806.04558 | SV2TTS | Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis | This repo |
| 1802.08435 | WaveRNN (vocoder) | Efficient Neural Audio Synthesis | fatchord/WaveRNN |
| 1703.10135 | Tacotron (synthesizer) | Tacotron: Towards End-to-End Speech Synthesis | fatchord/WaveRNN |
| 1710.10467 | GE2E (encoder) | Generalized End-To-End Loss for Speaker Verification | This repo |
| Dataset | Original Source | Alternative Sources |
|---|---|---|
| aidatatang_200zh | OpenSLR | Google Drive |
| magicdata | OpenSLR | Google Drive (Dev set) |
| aishell3 | OpenSLR | Google Drive |
| data_aishell | OpenSLR |
After unzip aidatatang_200zh, you need to unzip all the files under
aidatatang_200zh\corpus\train
If the dataset path is D:\data\aidatatang_200zh,then <datasets_root> isD:\data
Train the synthesizer:adjust the batch_size in synthesizer/hparams.py
//Before
tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule
(2, 5e-4, 40_000, 12), # (r, lr, step, batch_size)
(2, 2e-4, 80_000, 12), #
(2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames
(2, 3e-5, 320_000, 12), # synthesized for each decoder iteration)
(2, 1e-5, 640_000, 12)], # lr = learning rate
//After
tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule
(2, 5e-4, 40_000, 8), # (r, lr, step, batch_size)
(2, 2e-4, 80_000, 8), #
(2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames
(2, 3e-5, 320_000, 8), # synthesized for each decoder iteration)
(2, 1e-5, 640_000, 8)], # lr = learning rate
Train Vocoder-Preprocess the data:adjust the batch_size in synthesizer/hparams.py
//Before
### Data Preprocessing
max_mel_frames = 900,
rescale = True,
rescaling_max = 0.9,
synthesis_batch_size = 16, # For vocoder preprocessing and inference.
//After
### Data Preprocessing
max_mel_frames = 900,
rescale = True,
rescaling_max = 0.9,
synthesis_batch_size = 8, # For vocoder preprocessing and inference.
Train Vocoder-Train the vocoder:adjust the batch_size in vocoder/wavernn/hparams.py
//Before
# Training
voc_batch_size = 100
voc_lr = 1e-4
voc_gen_at_checkpoint = 5
voc_pad = 2
//After
# Training
voc_batch_size = 6
voc_lr = 1e-4
voc_gen_at_checkpoint = 5
voc_pad =2
4.If it happens RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).
Please refer to issue #37
Adjust the batch_size as appropriate to improve
Please refer to this video and change the virtual memory to 100G (102400), for example : When the file is placed in the D disk, the virtual memory of the D disk is changed.
FYI, my attention came after 18k steps and loss became lower than 0.4 after 50k steps.


For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MockingBird
Similar Open Source Tools
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.

r2ai
r2ai is a tool designed to run a language model locally without internet access. It can be used to entertain users or assist in answering questions related to radare2 or reverse engineering. The tool allows users to prompt the language model, index large codebases, slurp file contents, embed the output of an r2 command, define different system-level assistant roles, set environment variables, and more. It is accessible as an r2lang-python plugin and can be scripted from various languages. Users can use different models, adjust query templates dynamically, load multiple models, and make them communicate with each other.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.
AirConnect-Synology
AirConnect-Synology is a minimal Synology package that allows users to use AirPlay to stream to UPnP/Sonos & Chromecast devices that do not natively support AirPlay. It is compatible with DSM 7.0 and DSM 7.1, and provides detailed information on installation, configuration, supported devices, troubleshooting, and more. The package automates the installation and usage of AirConnect on Synology devices, ensuring compatibility with various architectures and firmware versions. Users can customize the configuration using the airconnect.conf file and adjust settings for specific speakers like Sonos, Bose SoundTouch, and Pioneer/Phorus/Play-Fi.
rwkv.cpp
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.
gollama
Gollama is a delightful tool that brings Ollama, your offline conversational AI companion, directly into your terminal. It provides a fun and interactive way to generate responses from various models without needing internet connectivity. Whether you're brainstorming ideas, exploring creative writing, or just looking for inspiration, Gollama is here to assist you. The tool offers an interactive interface, customizable prompts, multiple models selection, and visual feedback to enhance user experience. It can be installed via different methods like downloading the latest release, using Go, running with Docker, or building from source. Users can interact with Gollama through various options like specifying a custom base URL, prompt, model, and enabling raw output mode. The tool supports different modes like interactive, piped, CLI with image, and TUI with image. Gollama relies on third-party packages like bubbletea, glamour, huh, and lipgloss. The roadmap includes implementing piped mode, support for extracting codeblocks, copying responses/codeblocks to clipboard, GitHub Actions for automated releases, and downloading models directly from Ollama using the rest API. Contributions are welcome, and the project is licensed under the MIT License.

agenticSeek
AgenticSeek is a voice-enabled AI assistant powered by DeepSeek R1 agents, offering a fully local alternative to cloud-based AI services. It allows users to interact with their filesystem, code in multiple languages, and perform various tasks autonomously. The tool is equipped with memory to remember user preferences and past conversations, and it can divide tasks among multiple agents for efficient execution. AgenticSeek prioritizes privacy by running entirely on the user's hardware without sending data to the cloud.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern
ros2ai
ros2ai is a next-generation ROS 2 command line interface extension with OpenAI. It allows users to ask questions about ROS 2, get answers, and execute commands using natural language. ros2ai is easy to use, especially for ROS 2 beginners and students who do not really know ros2cli. It supports multiple languages and is available as a Docker container or can be built from source.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.
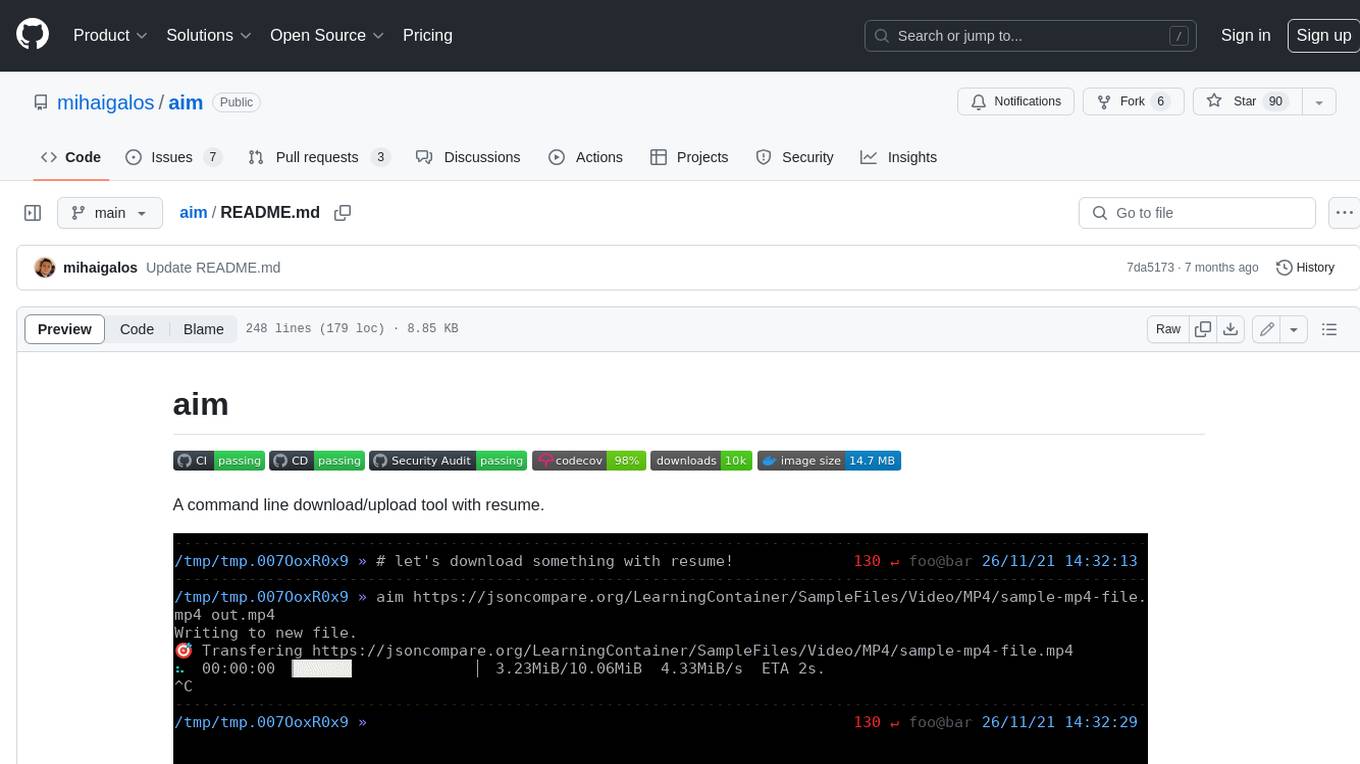
aim
Aim is a command-line tool for downloading and uploading files with resume support. It supports various protocols including HTTP, FTP, SFTP, SSH, and S3. Aim features an interactive mode for easy navigation and selection of files, as well as the ability to share folders over HTTP for easy access from other devices. Additionally, it offers customizable progress indicators and output formats, and can be integrated with other commands through piping. Aim can be installed via pre-built binaries or by compiling from source, and is also available as a Docker image for platform-independent usage.
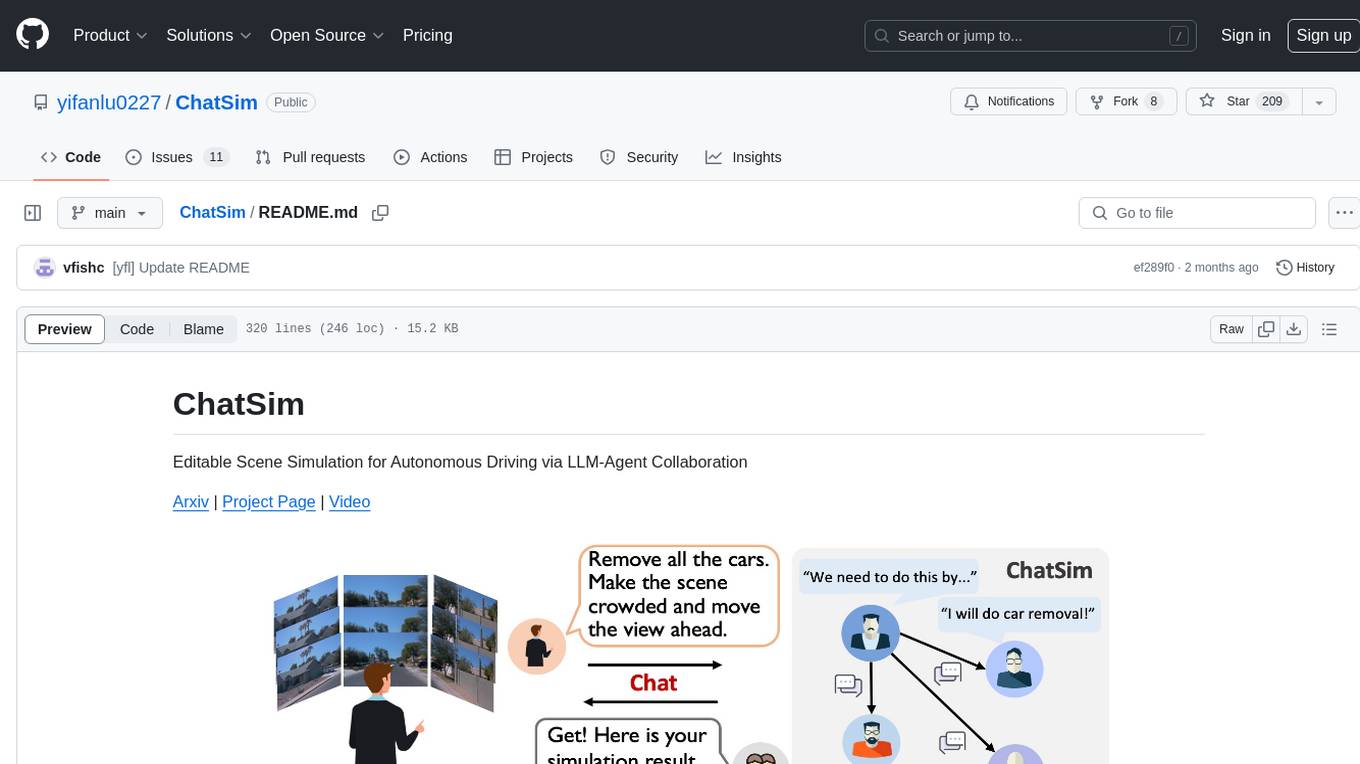
ChatSim
ChatSim is a tool designed for editable scene simulation for autonomous driving via LLM-Agent collaboration. It provides functionalities for setting up the environment, installing necessary dependencies like McNeRF and Inpainting tools, and preparing data for simulation. Users can train models, simulate scenes, and track trajectories for smoother and more realistic results. The tool integrates with Blender software and offers options for training McNeRF models and McLight's skydome estimation network. It also includes a trajectory tracking module for improved trajectory tracking. ChatSim aims to facilitate the simulation of autonomous driving scenarios with collaborative LLM-Agents.
For similar tasks
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.