Best AI tools for< Synthesize Mandarin Speech >
20 - AI tool Sites
CustomerIQ
CustomerIQ is an AI platform that automatically discovers and quantifies themes across customer feedback channels like calls, surveys, tickets, and transcripts. It aggregates customer feedback, extracts and categorizes feature requests, pain points, preferences, and highlights related to customers. The platform helps align teams, prioritize work, and build a customer-obsessed culture. CustomerIQ accelerates development by scoping project requirements faster and providing actionable insights backed with context.
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
Locus
Locus is a free browser extension that uses natural language processing to help users quickly find information on any web page. It allows users to search for specific terms or concepts using natural language queries, and then instantly jumps to the relevant section of the page. Locus also integrates with AI-powered tools such as GPT-3.5 to provide additional functionality, such as summarizing text and generating code. With Locus, users can save time and improve their productivity when reading and researching online.
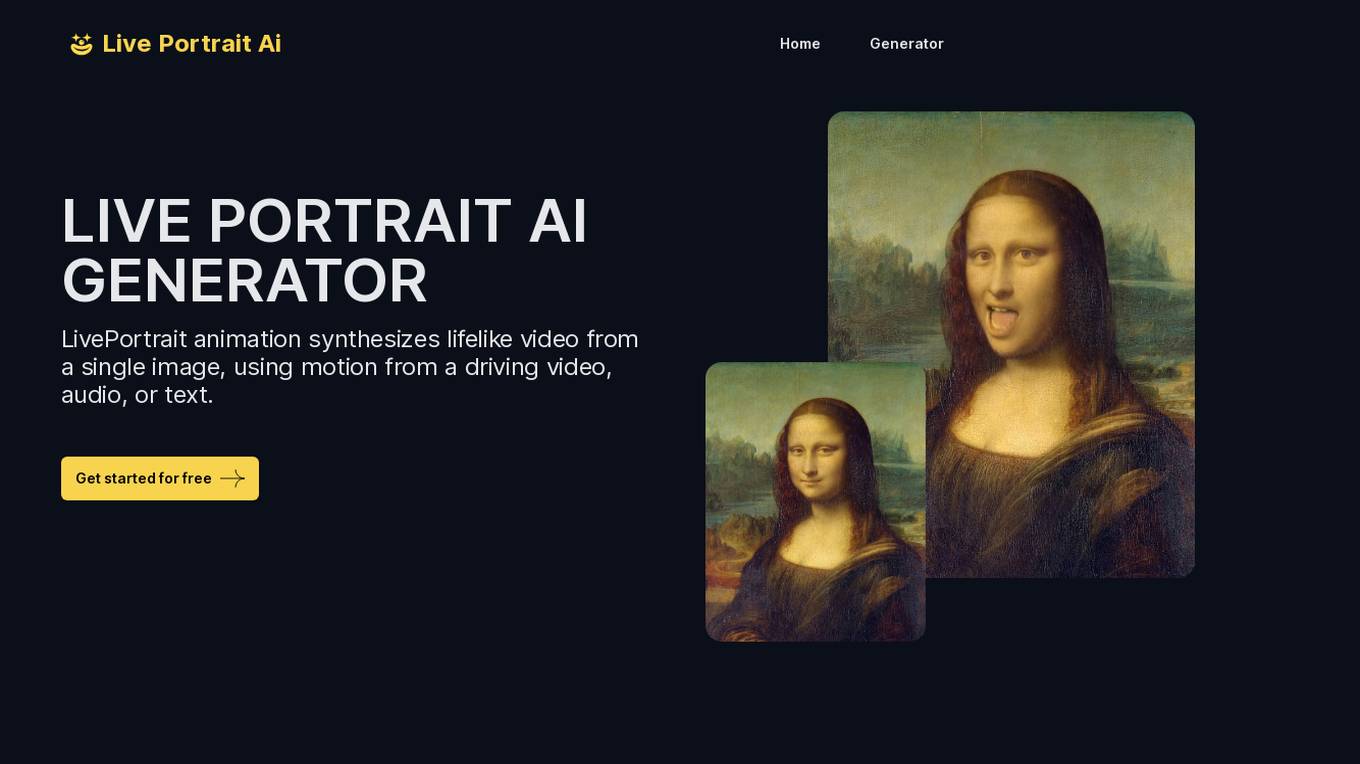
Live Portrait Ai Generator
Live Portrait Ai Generator is an AI application that transforms static portrait images into lifelike videos using advanced animation technology. Users can effortlessly animate their portraits, fine-tune animations, unleash artistic styles, and make memories move with text, music, and other elements. The tool offers a seamless stitching technology and retargeting capabilities to achieve perfect results. Live Portrait Ai enhances generation quality and generalization ability through a mixed image-video training strategy and network architecture upgrades.
Noota
Noota is a conversational intelligence platform that helps businesses record, transcribe, and generate meeting minutes. It also offers features such as automated interview reports, structured interviews, automated ATS job ad generator, generic meeting recorder, and conversational intelligence. Noota integrates with popular video conferencing platforms such as Zoom, Teams, and Meet, and offers a variety of subscription plans to meet the needs of different businesses.
Hermae Solutions
Hermae Solutions offers an AI Assistant for Enterprise Design Systems, providing onboarding acceleration, contractor efficiency, design system adoption support, knowledge distribution, and various AI documentation and Storybook assistants. The platform enables users to train custom AI assistants, embed them into documentation sites, and communicate instantly with the knowledge base. Hermae's process simplifies efficiency improvements by gathering information sources, processing data for AI supplementation, customizing integration, and supporting integration success. The AI assistant helps reduce engineering costs and increase development efficiency across the board.
Betafi
Betafi is a cloud-based user research and product feedback platform that helps businesses capture, organize, and share customer feedback from various sources, including user interviews, usability testing, and product demos. It offers features such as timestamped note-taking, automatic transcription and translation, video clipping, and integrations with popular collaboration tools like Miro, Figma, and Notion. Betafi enables teams to gather qualitative and quantitative feedback from users, synthesize insights, and make data-driven decisions to improve their products and services.
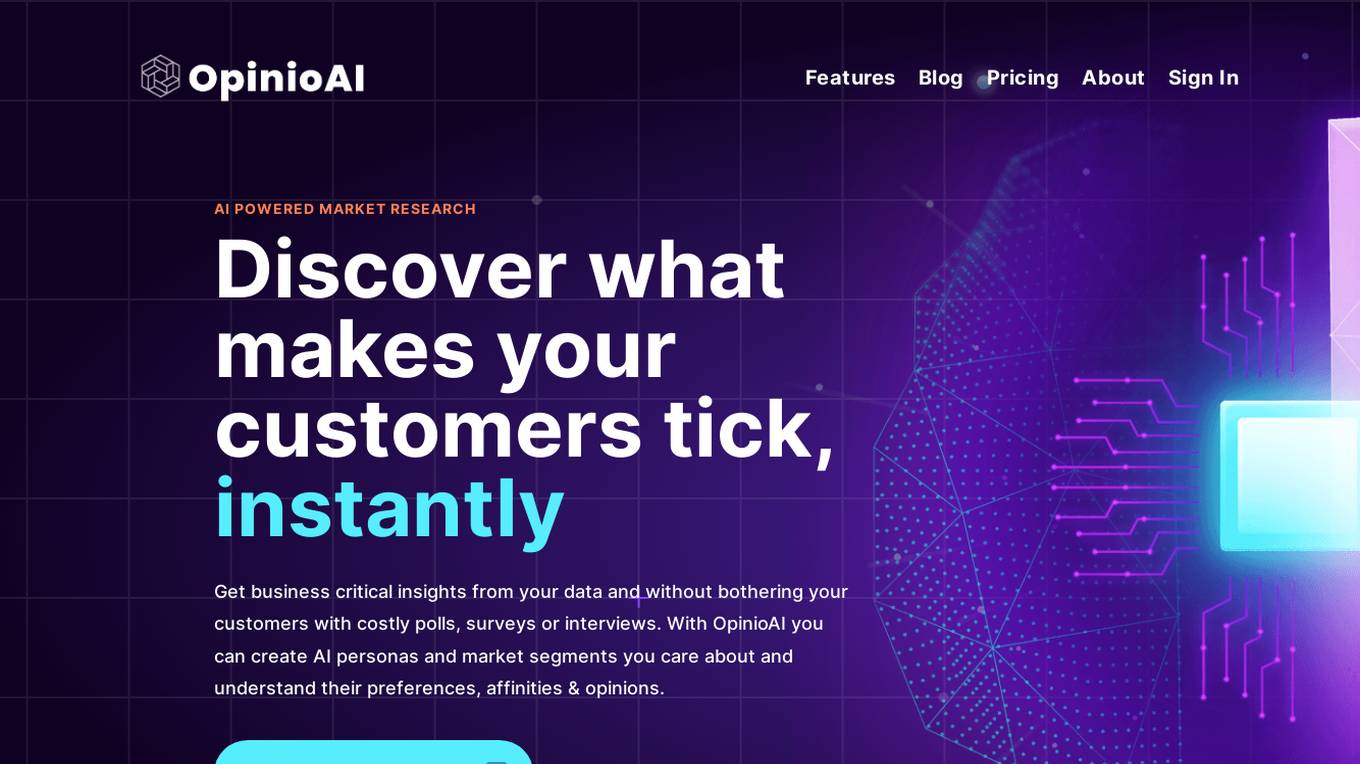
OpinioAI
OpinioAI is an AI-powered market research tool that allows users to gain business critical insights from data without the need for costly polls, surveys, or interviews. With OpinioAI, users can create AI personas and market segments to understand customer preferences, affinities, and opinions. The platform democratizes research by providing efficient, effective, and budget-friendly solutions for businesses, students, and individuals seeking valuable insights. OpinioAI leverages Large Language Models to simulate humans and extract opinions in detail, enabling users to analyze existing data, synthesize new insights, and evaluate content from the perspective of their target audience.

System Pro
System Pro is a cutting-edge platform that revolutionizes the way users conduct research, particularly in the fields of health and life sciences. It offers a fast and dependable method to discover, combine, and place scientific research in context. By leveraging advanced technology, System Pro enhances the efficiency and effectiveness of research processes, empowering users to access valuable insights with ease.
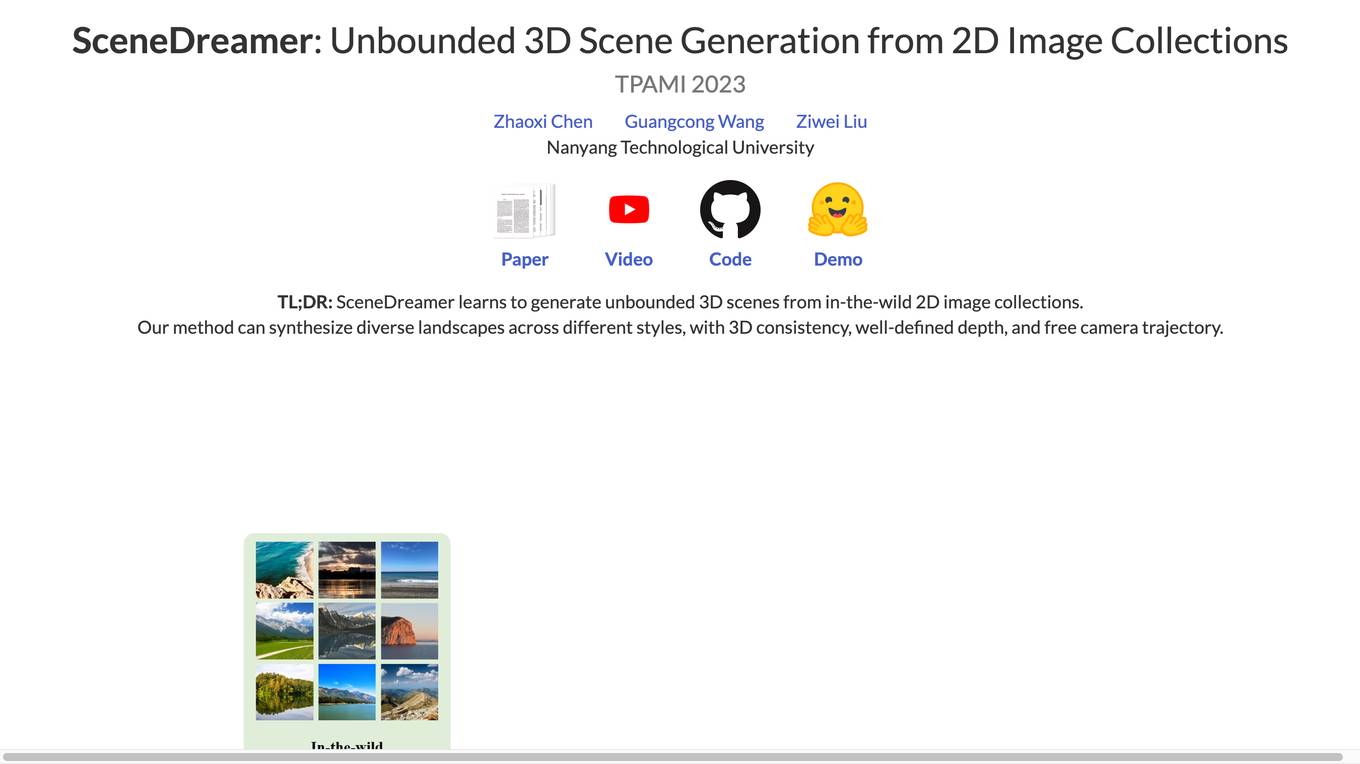
SceneDreamer
SceneDreamer is an AI tool that specializes in generating unbounded 3D scenes from 2D image collections. It utilizes an unconditional generative model to synthesize large-scale 3D landscapes with diverse styles, 3D consistency, well-defined depth, and free camera trajectory. The tool is trained solely on in-the-wild 2D image collections, without the need for 3D annotations. SceneDreamer's framework includes an efficient 3D scene representation, a generative scene parameterization, and a neural volumetric renderer to produce photorealistic images.

The Keenfolks
The Keenfolks is an AI Marketing Agency providing AI solutions for global brands to enhance media efficiency and ROI. They offer AI-powered tools to optimize media campaigns, synthesize audience data, and provide actionable intelligence. The agency helps brands transform fragmented data into unified intelligence, collaborate effectively, and improve media performance. The Keenfolks work with multinational brands across various markets, offering services such as AI assessment, content generation, customer behavior prediction, personalization automation, and data-informed decision-making.
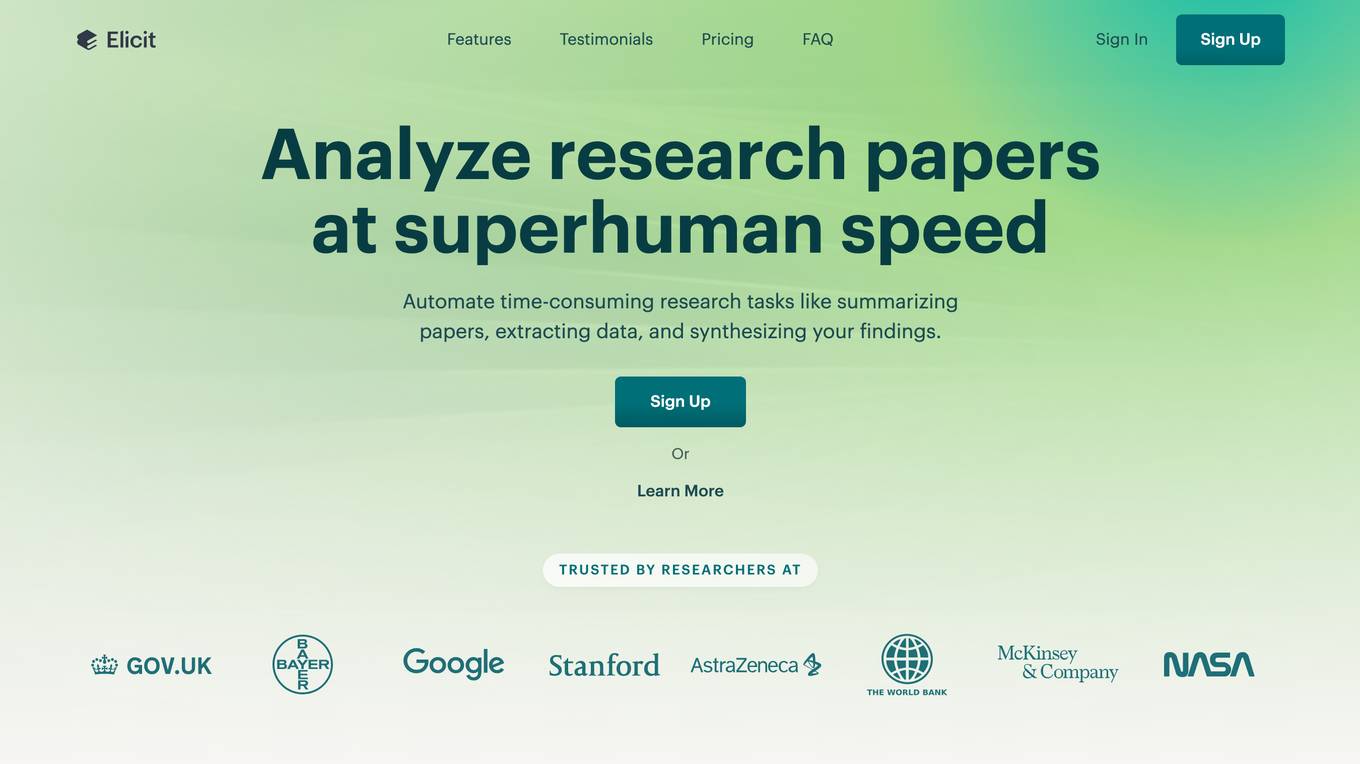
Elicit
Elicit is a research tool that uses artificial intelligence to help researchers analyze research papers more efficiently. It can summarize papers, extract data, and synthesize findings, saving researchers time and effort. Elicit is used by over 800,000 researchers worldwide and has been featured in publications such as Nature and Science. It is a powerful tool that can help researchers stay up-to-date on the latest research and make new discoveries.

Tilde.ai
Tilde.ai is a language technology platform that offers a wide range of AI-powered solutions for translation, speech technologies, and conversational AI. It combines human and artificial intelligence to help people connect and work efficiently. The platform provides machine translation, speech-to-text conversion, text-to-speech synthesis, real-time transcription, AI chatbots, internal knowledge assistants, and meeting support services. Tilde.ai aims to bridge language barriers and enhance communication by leveraging advanced language technologies.
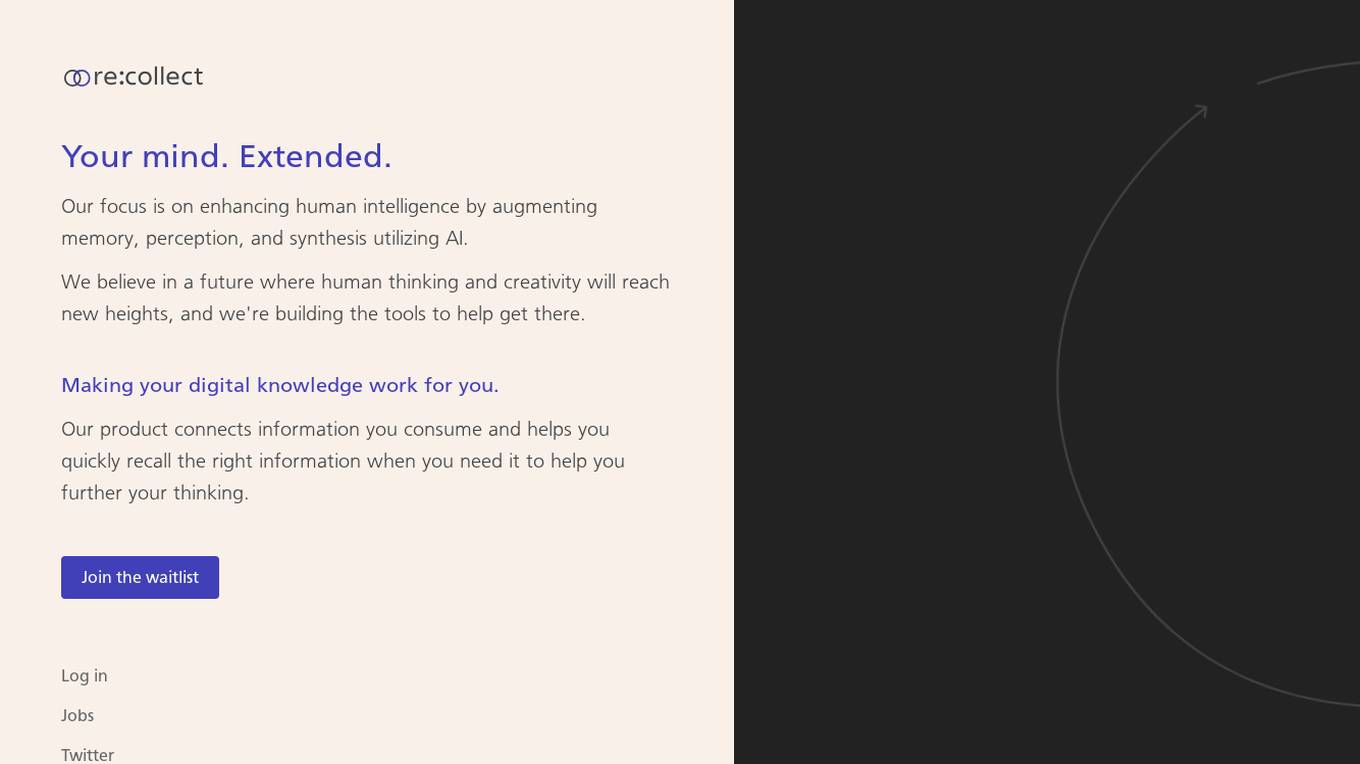
re:collect
re:collect is an AI-powered tool that helps you enhance your memory, perception, and synthesis. It connects the information you consume and helps you quickly recall the right information when you need it. With re:collect, you can:
Smart-Summarizer
Smart-Summarizer is a powerful AI-powered tool that helps you summarize text quickly and easily. With its advanced algorithms, Smart-Summarizer can automatically extract the most important points from any piece of text, creating a concise and informative summary in seconds. Whether you're a student trying to condense your notes, a researcher needing to synthesize complex information, or a professional looking to save time on reading lengthy documents, Smart-Summarizer is the perfect tool for you.
PitchPilot
PitchPilot is an AI-powered tool designed to help users create compelling presentations effortlessly. It offers features such as AI-driven scripting, natural voice synthesis, and seamless integration to enhance the presentation experience. With PitchPilot, users can focus on delivering their story while the tool takes care of scriptwriting and voiceovers. The application aims to alleviate the stress associated with creating presentations and empower users to deliver impactful messages.
Hebbia
Hebbia is an AI platform designed for finance professionals to add the power of generative AI to their firms. It allows users to explore thousands of use cases in legal, credit advisory, corporate consulting, real estate, and asset management. Hebbia synthesizes information into actionable insights, systematizes research workflows, automates tasks like quarterly earnings review and legal document analysis, and is trusted by large global institutions for its enterprise security features.
GovAI
GovAI is an AI tool designed to assist decision-makers in navigating the transition to a world with advanced AI. The tool produces rigorous research and fosters talent to address economic and national security imperatives related to AI dominance. It features analysis on various topics such as economics, export controls, public attitudes towards AI, AI governance trends, and the impact of AI on work. GovAI aims to provide insights and recommendations for policymakers and stakeholders in the AI domain.
Easy-Peasy.AI
Easy-Peasy.AI is an all-in-one AI platform that offers a variety of AI tools and solutions to assist users in content generation, copywriting, chatbot creation, image creation, audio transcription, and text-to-speech tasks. The platform provides a user-friendly interface and powerful technology to help users create high-quality content, improve writing skills, and automate various tasks using AI technology.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.
1 - Open Source AI Tools
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.
20 - OpenAI Gpts
PANˈDÔRƏ
Pandora is a Posthuman Prompt Engineer powered by the MANNS engine. Surpass human creative limitations by synthesizing diverse knowledge, advanced pattern recognition, and algorithmic creativity


AstroLex
Expertly guides users to identify gaps in research by analyzing and summarizing academic papers.


AI Debate Synthesizer OPED
Game-like GPT in which five AIs dynamically debate a given "theme" and lead to a proposal-based conclusion.
Work Contribution Record Table Synthesizer
Guides in creating a Work Contribution Record Table.