
Flowise
Build AI Agents, Visually
Stars: 43984
Flowise is a tool that allows users to build customized LLM flows with a drag-and-drop UI. It is open-source and self-hostable, and it supports various deployments, including AWS, Azure, Digital Ocean, GCP, Railway, Render, HuggingFace Spaces, Elestio, Sealos, and RepoCloud. Flowise has three different modules in a single mono repository: server, ui, and components. The server module is a Node backend that serves API logics, the ui module is a React frontend, and the components module contains third-party node integrations. Flowise supports different environment variables to configure your instance, and you can specify these variables in the .env file inside the packages/server folder.
README:








- ⚡ Quick Start
- 🐳 Docker
- 👨💻 Developers
- 🌱 Env Variables
- 📖 Documentation
- 🌐 Self Host
- ☁️ Flowise Cloud
- 🙋 Support
- 🙌 Contributing
- 📄 License
Download and Install NodeJS >= 18.15.0
-
Install Flowise
npm install -g flowise
-
Start Flowise
npx flowise start
- Clone the Flowise project
- Go to
dockerfolder at the root of the project - Copy
.env.examplefile, paste it into the same location, and rename to.envfile docker compose up -d- Open http://localhost:3000
- You can bring the containers down by
docker compose stop
-
Build the image locally:
docker build --no-cache -t flowise . -
Run image:
docker run -d --name flowise -p 3000:3000 flowise
-
Stop image:
docker stop flowise
Flowise has 3 different modules in a single mono repository.
-
server: Node backend to serve API logics -
ui: React frontend -
components: Third-party nodes integrations -
api-documentation: Auto-generated swagger-ui API docs from express
- Install PNPM
npm i -g pnpm
-
Clone the repository:
git clone https://github.com/FlowiseAI/Flowise.git
-
Go into repository folder:
cd Flowise -
Install all dependencies of all modules:
pnpm install
-
Build all the code:
pnpm build
Exit code 134 (JavaScript heap out of memory)
If you get this error when running the above `build` script, try increasing the Node.js heap size and run the script again:# macOS / Linux / Git Bash export NODE_OPTIONS="--max-old-space-size=4096" # Windows PowerShell $env:NODE_OPTIONS="--max-old-space-size=4096" # Windows CMD set NODE_OPTIONS=--max-old-space-size=4096
Then run:
pnpm build
-
Start the app:
pnpm start
You can now access the app on http://localhost:3000
-
For development build:
-
Create
.envfile and specify theVITE_PORT(refer to.env.example) inpackages/ui -
Create
.envfile and specify thePORT(refer to.env.example) inpackages/server -
Run:
pnpm dev
Any code changes will reload the app automatically on http://localhost:8080
-
Flowise supports different environment variables to configure your instance. You can specify the following variables in the .env file inside packages/server folder. Read more
You can view the Flowise Docs here
Deploy Flowise self-hosted in your existing infrastructure, we support various deployments






Get Started with Flowise Cloud.
Feel free to ask any questions, raise problems, and request new features in Discussion.
Thanks go to these awesome contributors
See Contributing Guide. Reach out to us at Discord if you have any questions or issues.
Source code in this repository is made available under the Apache License Version 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Flowise
Similar Open Source Tools
Flowise
Flowise is a tool that allows users to build customized LLM flows with a drag-and-drop UI. It is open-source and self-hostable, and it supports various deployments, including AWS, Azure, Digital Ocean, GCP, Railway, Render, HuggingFace Spaces, Elestio, Sealos, and RepoCloud. Flowise has three different modules in a single mono repository: server, ui, and components. The server module is a Node backend that serves API logics, the ui module is a React frontend, and the components module contains third-party node integrations. Flowise supports different environment variables to configure your instance, and you can specify these variables in the .env file inside the packages/server folder.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.

comp
Comp AI is an open-source compliance automation platform designed to assist companies in achieving compliance with standards like SOC 2, ISO 27001, and GDPR. It transforms compliance into an engineering problem solved through code, automating evidence collection, policy management, and control implementation while maintaining data and infrastructure control.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.
snipkit
SnipKit is a CLI tool designed to manage snippets efficiently, allowing users to execute saved scripts or generate new ones with the help of AI directly from the terminal. It supports loading snippets from various sources, parameter substitution, different parameter types, themes, and customization options. The tool includes an interactive chat-style interface called SnipKit Assistant for generating parameterized scripts. Users can also work with different AI providers like OpenAI, Anthropic, Google Gemini, and more. SnipKit aims to streamline script execution and script generation workflows for developers and users who frequently work with code snippets.

TalkWithGemini
Talk With Gemini is a web application that allows users to deploy their private Gemini application for free with one click. It supports Gemini Pro and Gemini Pro Vision models. The application features talk mode for direct communication with Gemini, visual recognition for understanding picture content, full Markdown support, automatic compression of chat records, privacy and security with local data storage, well-designed UI with responsive design, fast loading speed, and multi-language support. The tool is designed to be user-friendly and versatile for various deployment options and language preferences.
elyra
Elyra is a set of AI-centric extensions to JupyterLab Notebooks that includes features like Visual Pipeline Editor, running notebooks/scripts as batch jobs, reusable code snippets, hybrid runtime support, script editors with execution capabilities, debugger, version control using Git, and more. It provides a comprehensive environment for data scientists and AI practitioners to develop, test, and deploy machine learning models and workflows efficiently.

backend.ai-webui
Backend.AI Web UI is a user-friendly web and app interface designed to make AI accessible for end-users, DevOps, and SysAdmins. It provides features for session management, inference service management, pipeline management, storage management, node management, statistics, configurations, license checking, plugins, help & manuals, kernel management, user management, keypair management, manager settings, proxy mode support, service information, and integration with the Backend.AI Web Server. The tool supports various devices, offers a built-in websocket proxy feature, and allows for versatile usage across different platforms. Users can easily manage resources, run environment-supported apps, access a web-based terminal, use Visual Studio Code editor, manage experiments, set up autoscaling, manage pipelines, handle storage, monitor nodes, view statistics, configure settings, and more.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.

sim
Sim is a platform that allows users to build and deploy AI agent workflows quickly and easily. It provides cloud-hosted and self-hosted options, along with support for local AI models. Users can set up the application using Docker Compose, Dev Containers, or manual setup with PostgreSQL and pgvector extension. The platform utilizes technologies like Next.js, Bun, PostgreSQL with Drizzle ORM, Better Auth for authentication, Shadcn and Tailwind CSS for UI, Zustand for state management, ReactFlow for flow editor, Fumadocs for documentation, Turborepo for monorepo management, Socket.io for real-time communication, and Trigger.dev for background jobs.
qwen-code
Qwen Code is an open-source AI agent optimized for Qwen3-Coder, designed to help users understand large codebases, automate tedious work, and expedite the shipping process. It offers an agentic workflow with rich built-in tools, a terminal-first approach with optional IDE integration, and supports both OpenAI-compatible API and Qwen OAuth authentication methods. Users can interact with Qwen Code in interactive mode, headless mode, IDE integration, and through a TypeScript SDK. The tool can be configured via settings.json, environment variables, and CLI flags, and offers benchmark results for performance evaluation. Qwen Code is part of an ecosystem that includes AionUi and Gemini CLI Desktop for graphical interfaces, and troubleshooting guides are available for issue resolution.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.
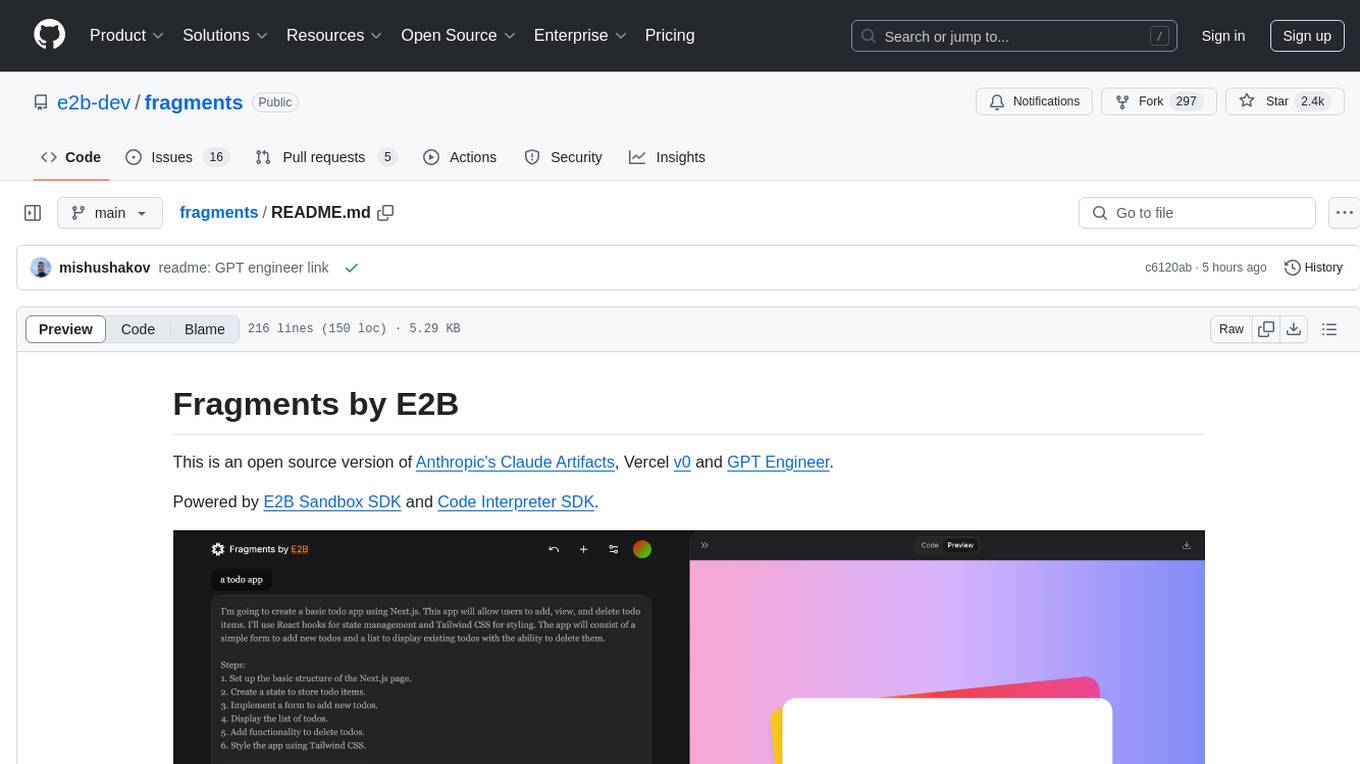
fragments
Fragments is an open-source tool that leverages Anthropic's Claude Artifacts, Vercel v0, and GPT Engineer. It is powered by E2B Sandbox SDK and Code Interpreter SDK, allowing secure execution of AI-generated code. The tool is based on Next.js 14, shadcn/ui, TailwindCSS, and Vercel AI SDK. Users can stream in the UI, install packages from npm and pip, and add custom stacks and LLM providers. Fragments enables users to build web apps with Python interpreter, Next.js, Vue.js, Streamlit, and Gradio, utilizing providers like OpenAI, Anthropic, Google AI, and more.
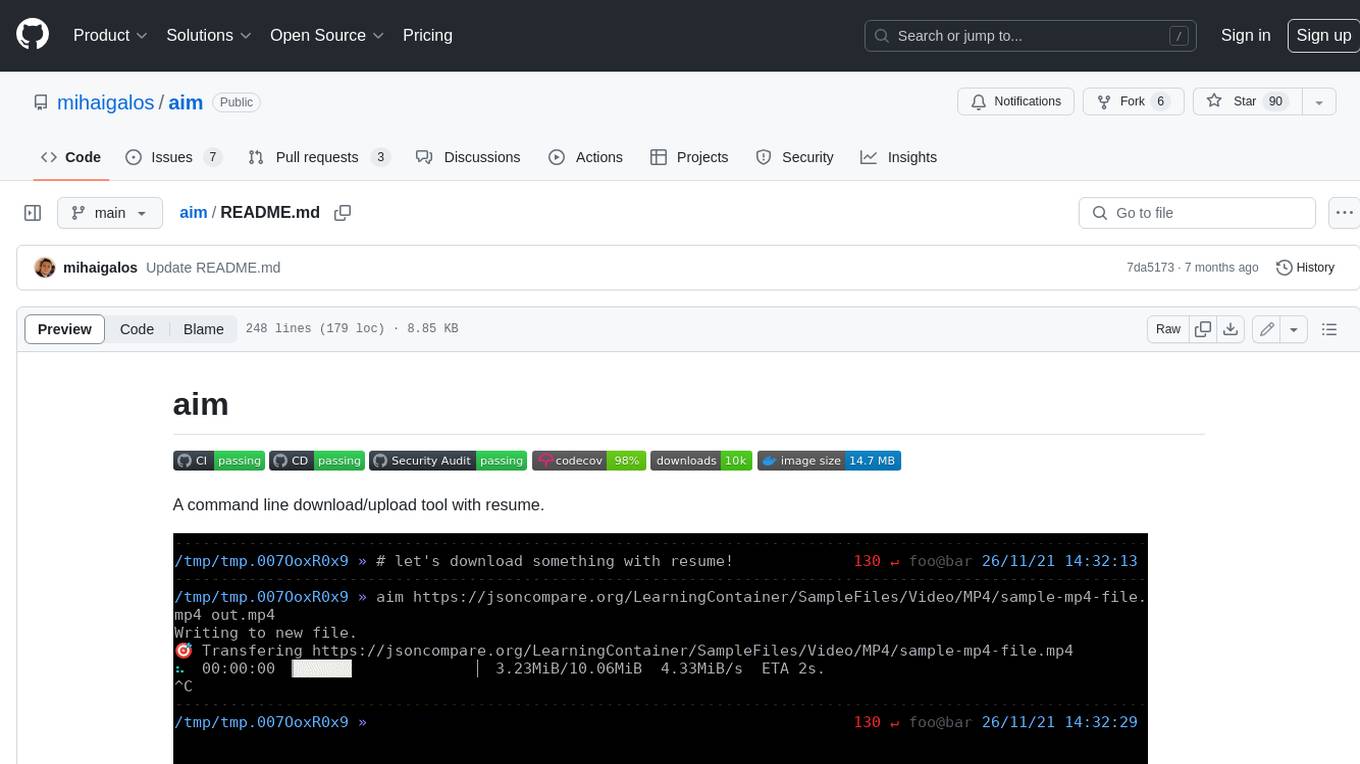
aim
Aim is a command-line tool for downloading and uploading files with resume support. It supports various protocols including HTTP, FTP, SFTP, SSH, and S3. Aim features an interactive mode for easy navigation and selection of files, as well as the ability to share folders over HTTP for easy access from other devices. Additionally, it offers customizable progress indicators and output formats, and can be integrated with other commands through piping. Aim can be installed via pre-built binaries or by compiling from source, and is also available as a Docker image for platform-independent usage.

pebblo
Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities found in the loaded data and summarizes them on the UI or a PDF report.
ai-containers
This repository contains Dockerfiles, scripts, yaml files, Helm charts, etc. used to scale out AI containers with versions of TensorFlow and PyTorch optimized for Intel platforms. Scaling is done with python, Docker, kubernetes, kubeflow, cnvrg.io, Helm, and other container orchestration frameworks for use in the cloud and on-premise.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.