
yams
Persistent memory for LLMs and apps. Content-addressed storage with dedupe, compression, full-text and vector search.
Stars: 365
YAMS (Yet Another Memory System) is a persistent memory system designed for Large Language Models (LLMs) and applications. It provides content-addressed storage with features such as deduplication, compression, full-text search, and vector search. The system is built with SHA-256 content-addressed store, block-level deduplication, full-text search using SQLite FTS5, semantic search with embeddings, WAL-backed durability, high-throughput I/O, and thread-safe operations. YAMS supports Linux x86_64/ARM64 and macOS x86_64/ARM64 platforms. It is recommended to build using Conan for managing dependencies and ensuring proper installation. Users can interact with YAMS through a command-line interface for tasks like initialization, adding content, searching, and retrieving data. Additionally, YAMS provides LLM-friendly patterns for caching web content, storing code diffs, and integrating with other systems through an API in C++. Troubleshooting tips include creating a default Conan profile and handling PDF support issues during the build process. The project is licensed under Apache-2.0.
README:
Persistent memory for LLMs and apps. Content-addressed storage with dedupe, compression, full-text and vector search.




[!WARNING] Experimental Software - Not Production Ready
YAMS is under active development and should be considered experimental. The software may contain bugs, incomplete features, and breaking changes between versions. Use at your own risk.
For production workloads, please wait for a stable 1.0 release.
- SHA-256 content-addressed storage with block-level dedupe (Rabin chunking)
- Full-text search (SQLite FTS5) + semantic vector search (embeddings)
- Symbol extraction from source code (tree-sitter: C, C++, Python, JS, TS, Rust, Go, Java, C#, PHP, Kotlin, Dart, SQL, Solidity)
- Snapshot management with Merkle tree diffs and rename detection
- WAL-backed durability, high-throughput I/O, thread-safe
- Portable CLI, MCP server, and plugin architecture (ONNX, S3, PDF extraction)
- SourceHut: https://sr.ht/~trvon/yams/
- GitHub mirror: https://github.com/trvon/yams
- Docs: https://yamsmemory.ai
- Discord: https://discord.gg/rTBmRHdTEc
- License: GPL-3.0-or-later
Supported platforms: Linux x86_64/ARM64, macOS x86_64/ARM64, Windows x86_64
# Stable release (recommended)
brew install trvon/yams/yams
# Or get nightly builds for latest features
brew install trvon/yams/yams@nightly
# Verify installation
yams --version# Pull and run
docker pull ghcr.io/trvon/yams:latest
docker run --rm -v yams-data:/home/yams/.local/share/yams ghcr.io/trvon/yams:latest --version
# MCP server
docker run -i --rm -v yams-data:/home/yams/.local/share/yams ghcr.io/trvon/yams:latest serveLinux/macOS:
# Quick build (auto-detects Clang/GCC, configures Conan + Meson)
./setup.sh Release
# Build
meson compile -C build/release
# Optional: Install system-wide
meson install -C build/releaseWindows:
./setup.ps1 Release
meson compile -C build/releasePrerequisites: GCC 13+, Clang 16+, or MSVC 2022+ (C++20); meson, ninja-build, cmake, pkg-config, conan
See docs/BUILD.md for detailed instructions.
# Initialize (interactive - prompts for grammar downloads)
yams init .
# Auto mode for containers/headless
yams init --auto
# Add content
yams add ./README.md --tags docs
yams add src/ --recursive --include="*.cpp,*.h" --tags code
# Search
yams search "config file" --limit 5
yams grep "TODO" --include="*.cpp"
# List and retrieve
yams list --limit 20
yams get <hash> -o ./output.binYAMS extracts symbols (functions, classes, methods) from source code using tree-sitter:
# Interactive grammar setup
yams init
# Or auto-download recommended grammars
yams init --auto
# Manage grammars separately
yams config grammar list
yams config grammar download cpp python rustSupported: C, C++, Python, JavaScript, TypeScript, Rust, Go, Java, C#, PHP, Kotlin, Dart, SQL, Solidity
# Snapshots are created automatically on add
yams add . --recursive --include="*.cpp,*.h" --snapshot-label "v1.0"
# List snapshots
yams list --snapshots
# Compare snapshots (Merkle tree diff with rename detection)
yams diff v1.0 v1.1
yams diff v1.0 v1.1 --include="*.cpp" --statsyams serve # stdio transport (JSON-RPC)Claude Desktop config (~/Library/Application Support/Claude/claude_desktop_config.json):
{
"mcpServers": {
"yams": {
"command": "yams",
"args": ["serve"]
}
}
}YAMS supports plugins for embeddings (ONNX), storage (S3), and content extraction (PDF):
yams plugin list # List loaded plugins
yams plugin trust add ~/.local/lib/yams/plugins
yams plugin health # Check plugin status
yams doctor plugin onnx # Diagnose specific pluginRecommended model: all-MiniLM-L6-v2 (384-dim) — best speed/quality tradeoff.
The ONNX plugin supports GPU acceleration for faster embedding generation:
| Platform | Provider | Hardware |
|---|---|---|
| macOS | CoreML | Apple Silicon Neural Engine + GPU |
| Linux | CUDA | NVIDIA GPUs |
| Windows | DirectML | Any DirectX 12 GPU (NVIDIA, AMD, Intel) |
GPU support is auto-detected during build. To manually control:
# Disable GPU
YAMS_ONNX_GPU=none ./setup.sh Release
# Force specific provider
YAMS_ONNX_GPU=cuda ./setup.sh Release # Linux
YAMS_ONNX_GPU=coreml ./setup.sh Release # macOS
YAMS_ONNX_GPU=directml ./setup.ps1 # WindowsSee plugins/onnx/README.md for detailed configuration.
yams doctor # Full diagnostics
yams stats --verbose # Storage statistics
yams repair --all # Repair common issuesBuild issues: See docs/BUILD.md
Plugin discovery: yams plugin list empty? Add trust path: yams plugin trust add ~/.local/lib/yams/plugins
@misc{yams,
author = {Trevon Williams},
title = {YAMS: Content-addressable storage with semantic search},
year = {2025},
publisher = {GitHub},
url = {https://github.com/trvon/yams}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for yams
Similar Open Source Tools
yams
YAMS (Yet Another Memory System) is a persistent memory system designed for Large Language Models (LLMs) and applications. It provides content-addressed storage with features such as deduplication, compression, full-text search, and vector search. The system is built with SHA-256 content-addressed store, block-level deduplication, full-text search using SQLite FTS5, semantic search with embeddings, WAL-backed durability, high-throughput I/O, and thread-safe operations. YAMS supports Linux x86_64/ARM64 and macOS x86_64/ARM64 platforms. It is recommended to build using Conan for managing dependencies and ensuring proper installation. Users can interact with YAMS through a command-line interface for tasks like initialization, adding content, searching, and retrieving data. Additionally, YAMS provides LLM-friendly patterns for caching web content, storing code diffs, and integrating with other systems through an API in C++. Troubleshooting tips include creating a default Conan profile and handling PDF support issues during the build process. The project is licensed under Apache-2.0.
KsanaLLM
KsanaLLM is a high-performance engine for LLM inference and serving. It utilizes optimized CUDA kernels for high performance, efficient memory management, and detailed optimization for dynamic batching. The tool offers flexibility with seamless integration with popular Hugging Face models, support for multiple weight formats, and high-throughput serving with various decoding algorithms. It enables multi-GPU tensor parallelism, streaming outputs, and an OpenAI-compatible API server. KsanaLLM supports NVIDIA GPUs and Huawei Ascend NPU, and seamlessly integrates with verified Hugging Face models like LLaMA, Baichuan, and Qwen. Users can create a docker container, clone the source code, compile for Nvidia or Huawei Ascend NPU, run the tool, and distribute it as a wheel package. Optional features include a model weight map JSON file for models with different weight names.
airstore
Airstore is a filesystem for AI agents that adds any source of data into a virtual filesystem, allowing users to connect services like Gmail, GitHub, Linear, and more, and describe data needs in plain English. Results are presented as files that can be read by Claude Code. Features include smart folders for natural language queries, integrations with various services, executable MCP servers, team workspaces, and local mode operation on user infrastructure. Users can sign up, connect integrations, create smart folders, install the CLI, mount the filesystem, and use with Claude Code to perform tasks like summarizing invoices, identifying unpaid invoices, and extracting data into CSV format.
honey
Bee is an ORM framework that provides easy and high-efficiency database operations, allowing developers to focus on business logic development. It supports various databases and features like automatic filtering, partial field queries, pagination, and JSON format results. Bee also offers advanced functionalities like sharding, transactions, complex queries, and MongoDB ORM. The tool is designed for rapid application development in Java, offering faster development for Java Web and Spring Cloud microservices. The Enterprise Edition provides additional features like financial computing support, automatic value insertion, desensitization, dictionary value conversion, multi-tenancy, and more.
bee
Bee is an easy and high efficiency ORM framework that simplifies database operations by providing a simple interface and eliminating the need to write separate DAO code. It supports various features such as automatic filtering of properties, partial field queries, native statement pagination, JSON format results, sharding, multiple database support, and more. Bee also offers powerful functionalities like dynamic query conditions, transactions, complex queries, MongoDB ORM, cache management, and additional tools for generating distributed primary keys, reading Excel files, and more. The newest versions introduce enhancements like placeholder precompilation, default date sharding, ElasticSearch ORM support, and improved query capabilities.
simba
Simba is an open source, portable Knowledge Management System (KMS) designed to seamlessly integrate with any Retrieval-Augmented Generation (RAG) system. It features a modern UI and modular architecture, allowing developers to focus on building advanced AI solutions without the complexities of knowledge management. Simba offers a user-friendly interface to visualize and modify document chunks, supports various vector stores and embedding models, and simplifies knowledge management for developers. It is community-driven, extensible, and aims to enhance AI functionality by providing a seamless integration with RAG-based systems.
WilliamButcherBot
WilliamButcherBot is a Telegram Group Manager Bot and Userbot written in Python using Pyrogram. It provides features for managing Telegram groups and users, with ready-to-use methods available. The bot requires Python 3.9, Telegram API Key, Telegram Bot Token, and MongoDB URI. Users can install it locally or on a VPS, run it directly, generate Pyrogram session for Heroku, or use Docker for deployment. Additionally, users can write new modules to extend the bot's functionality by adding them to the wbb/modules/ directory.
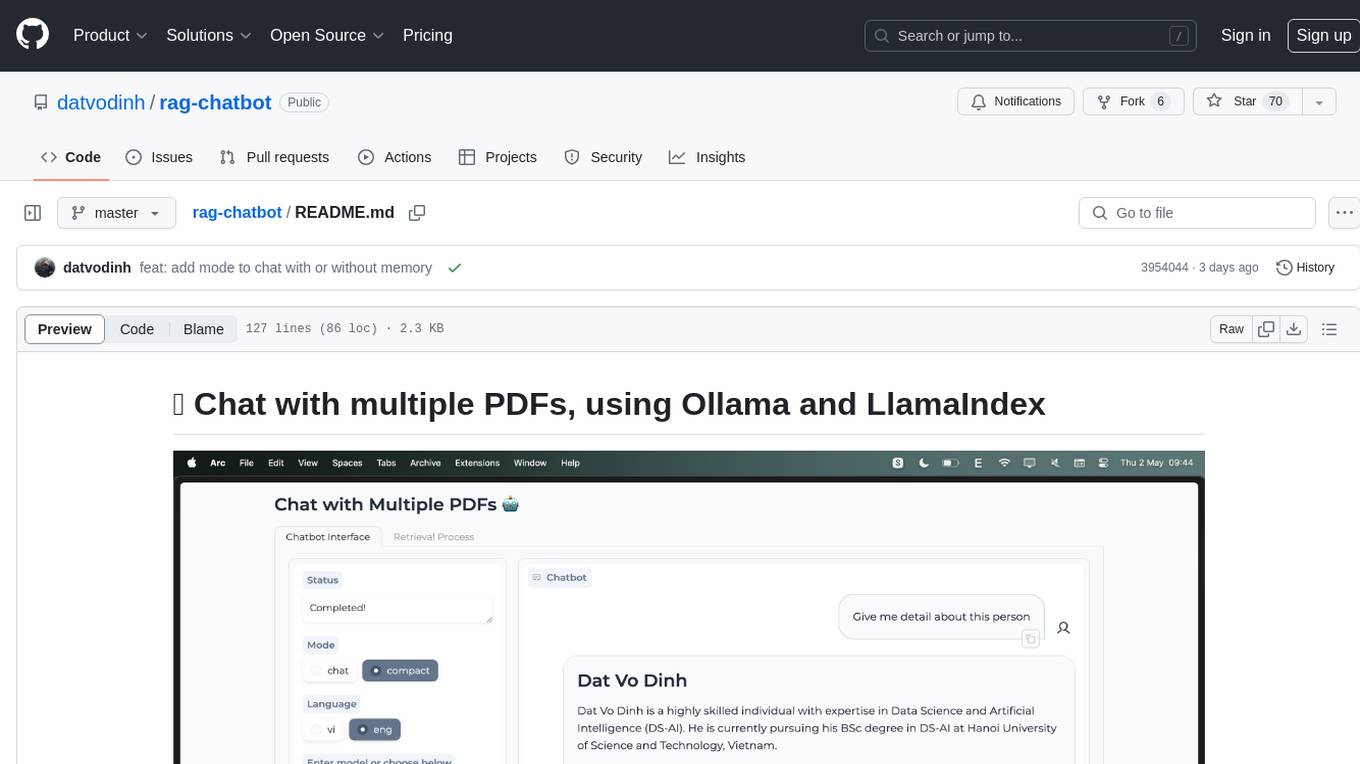
rag-chatbot
rag-chatbot is a tool that allows users to chat with multiple PDFs using Ollama and LlamaIndex. It provides an easy setup for running on local machines or Kaggle notebooks. Users can leverage models from Huggingface and Ollama, process multiple PDF inputs, and chat in multiple languages. The tool offers a simple UI with Gradio, supporting chat with history and QA modes. Setup instructions are provided for both Kaggle and local environments, including installation steps for Docker, Ollama, Ngrok, and the rag_chatbot package. Users can run the tool locally and access it via a web interface. Future enhancements include adding evaluation, better embedding models, knowledge graph support, improved document processing, MLX model integration, and Corrective RAG.
NextChat
NextChat is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro. It offers a compact client for Linux, Windows, and MacOS, with features like self-deployed LLMs compatibility, privacy-first data storage, markdown support, responsive design, and fast loading speed. Users can create, share, and debug chat tools with prompt templates, access various prompts, compress chat history, and use multiple languages. The tool also supports enterprise-level privatization and customization deployment, with features like brand customization, resource integration, permission control, knowledge integration, security auditing, private deployment, and continuous updates.
ChatGPT-Next-Web
ChatGPT Next Web is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro models. It allows users to deploy their private ChatGPT applications with ease. The tool offers features like one-click deployment, compact client for Linux/Windows/MacOS, compatibility with self-deployed LLMs, privacy-first approach with local data storage, markdown support, responsive design, fast loading speed, prompt templates, awesome prompts, chat history compression, multilingual support, and more.
Free-GPT4-WEB-API
FreeGPT4-WEB-API is a Python server that allows you to have a self-hosted GPT-4 Unlimited and Free WEB API, via the latest Bing's AI. It uses Flask and GPT4Free libraries. GPT4Free provides an interface to the Bing's GPT-4. The server can be configured by editing the `FreeGPT4_Server.py` file. You can change the server's port, host, and other settings. The only cookie needed for the Bing model is `_U`.

Acontext
Acontext is a context data platform designed for production AI agents, offering unified storage, built-in context management, and observability features. It helps agents scale from local demos to production without the need to rebuild context infrastructure. The platform provides solutions for challenges like scattered context data, long-running agents requiring context management, and tracking states from multi-modal agents. Acontext offers core features such as context storage, session management, disk storage, agent skills management, and sandbox for code execution and analysis. Users can connect to Acontext, install SDKs, initialize clients, store and retrieve messages, perform context engineering, and utilize agent storage tools. The platform also supports building agents using end-to-end scripts in Python and Typescript, with various templates available. Acontext's architecture includes client layer, backend with API and core components, infrastructure with PostgreSQL, S3, Redis, and RabbitMQ, and a web dashboard. Join the Acontext community on Discord and follow updates on GitHub.
vecs
vecs is a Python client for managing and querying vector stores in PostgreSQL with the pgvector extension. It allows users to create collections of vectors with associated metadata, index the collections for fast search performance, and query the collections based on specified filters. The tool simplifies the process of working with vector data in a PostgreSQL database, making it easier to store, retrieve, and analyze vector information.
onefilellm
OneFileLLM is a command-line tool that streamlines the creation of information-dense prompts for large language models (LLMs). It aggregates and preprocesses data from various sources, compiling them into a single text file for quick use. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, token count reporting, and XML encapsulation of output for improved LLM performance. Users can easily access private GitHub repositories by generating a personal access token. The tool's output is encapsulated in XML tags to enhance LLM understanding and processing.
mcp-devtools
MCP DevTools is a high-performance server written in Go that replaces multiple Node.js and Python-based servers. It provides access to essential developer tools through a unified, modular interface. The server is efficient, with minimal memory footprint and fast response times. It offers a comprehensive tool suite for agentic coding, including 20+ essential developer agent tools. The tool registry allows for easy addition of new tools. The server supports multiple transport modes, including STDIO, HTTP, and SSE. It includes a security framework for multi-layered protection and a plugin system for adding new tools.
ollama4j
Ollama4j is a Java library that serves as a wrapper or binding for the Ollama server. It facilitates communication with the Ollama server and provides models for deployment. The tool requires Java 11 or higher and can be installed locally or via Docker. Users can integrate Ollama4j into Maven projects by adding the specified dependency. The tool offers API specifications and supports various development tasks such as building, running unit tests, and integration tests. Releases are automated through GitHub Actions CI workflow. Areas of improvement include adhering to Java naming conventions, updating deprecated code, implementing logging, using lombok, and enhancing request body creation. Contributions to the project are encouraged, whether reporting bugs, suggesting enhancements, or contributing code.
For similar tasks

metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.
client-python
The Mistral Python Client is a tool inspired by cohere-python that allows users to interact with the Mistral AI API. It provides functionalities to access and utilize the AI capabilities offered by Mistral. Users can easily install the client using pip and manage dependencies using poetry. The client includes examples demonstrating how to use the API for various tasks, such as chat interactions. To get started, users need to obtain a Mistral API Key and set it as an environment variable. Overall, the Mistral Python Client simplifies the integration of Mistral AI services into Python applications.
ComposeAI
ComposeAI is an Android & iOS application similar to ChatGPT, built using Compose Multiplatform. It utilizes various technologies such as Compose Multiplatform, Material 3, OpenAI Kotlin, Voyager, Koin, SQLDelight, Multiplatform Settings, Coil3, Napier, BuildKonfig, Firebase Analytics & Crashlytics, and AdMob. The app architecture follows Google's latest guidelines. Users need to set up their own OpenAI API key before using the app.
aiohttp-devtools
aiohttp-devtools provides dev tools for developing applications with aiohttp and associated libraries. It includes CLI commands for running a local server with live reloading and serving static files. The tools aim to simplify the development process by automating tasks such as setting up a new application and managing dependencies. Developers can easily create and run aiohttp applications, manage static files, and utilize live reloading for efficient development.

minefield
BitBom Minefield is a tool that uses roaring bit maps to graph Software Bill of Materials (SBOMs) with a focus on speed, air-gapped operation, scalability, and customizability. It is optimized for rapid data processing, operates securely in isolated environments, supports millions of nodes effortlessly, and allows users to extend the project without relying on upstream changes. The tool enables users to manage and explore software dependencies within isolated environments by offline processing and analyzing SBOMs.
gez
Gez is a high-performance micro frontend framework based on ESM. It uses Rspack compilation and maps modules to URLs with strong caching and content-based hashing. Gez embraces modern micro frontend architecture by leveraging ESM and importmap for dependency management, providing reliable isolation with module scope, seamless integration with any modern frontend framework, intuitive development experience, and optimal performance with zero runtime overhead and reliable caching strategies.
forge
Forge is a powerful open-source tool for building modern web applications. It provides a simple and intuitive interface for developers to quickly scaffold and deploy projects. With Forge, you can easily create custom components, manage dependencies, and streamline your development workflow. Whether you are a beginner or an experienced developer, Forge offers a flexible and efficient solution for your web development needs.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.