
rust-genai
Rust multiprovider generative AI client (Ollama, OpenAi, Anthropic, Gemini, DeepSeek, xAI/Grok, Groq,Cohere, ...)
Stars: 522
genai is a multi-AI providers library for Rust that aims to provide a common and ergonomic single API to various generative AI providers such as OpenAI, Anthropic, Cohere, Ollama, and Gemini. It focuses on standardizing chat completion APIs across major AI services, prioritizing ergonomics and commonality. The library initially focuses on text chat APIs and plans to expand to support images, function calling, and more in the future versions. Version 0.1.x will have breaking changes in patches, while version 0.2.x will follow semver more strictly. genai does not provide a full representation of a given AI provider but aims to simplify the differences at a lower layer for ease of use.
README:
Currently natively supports: OpenAI, Anthropic, Gemini, XAI/Grok, Ollama, Groq, DeepSeek (deepseek.com & Groq), Cohere (more to come)
Also allows a custom URL with ServiceTargetResolver (see examples/c06-target-resolver.rs)

Provides a single, ergonomic API to many generative AI providers, such as Anthropic, OpenAI, Gemini, xAI, Ollama, Groq, and more.
NOTE: Try to use the latest version (0.4.0-alpha.4). It is as robust as 0.3.x, but with updated APIs (see below) and additional functionality thanks to many great PRs.
What's new: (- fix, + addition, ! change)
(see CHANGELOG.md for more)
-
!API CHANGEChatResponse::contentis nowMessageContent(as MessageContent is now multipart). Minor impact, as ChatResponse public API (into_text...as before)- Now simpler, just use
let joined_text: Option<String> = chat_response.content.into_join_texts()
- Now simpler, just use
-
!API CHANGEMessageContent::text(&self)replaced by (becauseMessageContentnow flattens multi-part formats)MessageContent::into_joined_texts(self) -> Option<String>MessageContent::joined_texts(&self) -> Option<String>MessageContent::texts(&self) -> Vec<&str>MessageContent::into_texts(self) -> Vec<String>
-
+Custom HTTP headers inChatOptions(#78) -
+Model namespacing to specify the adapter, e.g.,openai::codex-unknown-modelwill use the OpenAI adapter and sendcodex-unknown-modelas the model name. AdapterKind and model name can still be overridden byServiceTargetResolver -
+New Adapters: Zhipu (ChatGLM) (#76), Nebius -
!API CHANGE NowChatResponse.contentis aVec<MessageContent>to support responses that include ToolCalls and text messages- you can use
let text: &str = chat_response.first_text()(wasChatResponse::content_text_as_str()) or let texts: Vec<&str> = chat_response.texts();let texts: Vec<String> = chat_response.into_texts();-
let text: String = chat_response::into_first_text()(wasChatResponse::content_text_into_string()) - To get the concatenated string of all messages:
let text: String = content.into_iter().filter_map(|c| c.text_into_string()).collect::<Vec<_>>().join("\n\n")
- you can use
-
!API CHANGE NowChatResponse::into_tool_calls()andtool_calls()returnVec<ToolCalls>rather thanOption<Vec<ToolCalls>> -
!API CHANGE MessageContent - Now usemessage_content.text()andmessage_content.into_text()(rather thantext_as_str,text_into_string) -
-Gemini ToolResponse Fix Gemini adapter wrongfully tried to parse theToolResponse.content(see #59) -
!Tool Use Streaming support, thanks to ClanceyLu, PR #58
What's new:
- Gemini Thinking Budget support
ReasoningEffort::Budget(num) - Gemini
-zero,-low,-medium, and-highsuffixes that set the corresponding budget (0,1k,8k,24k) - When set,
ReasoningEffort::Low, ...will map to their corresponding budgets1k,8k,24k
API-CHANGES (minors)
- ReasoningEffort now has an additional Budget(num) variant
- ModelIden::with_name_or_clone has been deprecated in favor of ModelIden::from_option_name(Option<String>)
Check CHANGELOG for more info
- ClanceyLu for Tool Use Streaming support PR #58
- @SilasMarvin for fixing content/tools issues with some Ollama models PR #55
-
@una-spirito for Gemini
ReasoningEffort::Budgetsupport - @jBernavaPrah for adding tracing (it was long overdue). PR #45
- @GustavoWidman for the initial Gemini tool/function support! PR #41
- @AdamStrojek for initial image support PR #36
-
@semtexzv for
stop_sequencesAnthropic support PR #34 - @omarshehab221 for de/serialize on structs PR #19
- @tusharmath for making webc::Error PR #12
- @giangndm for making stream Send PR #10
- @stargazing-dino for PR #2 - implement Groq completions
- Check out AIPACK, which wraps this genai library into an agentic runtime to run, build, and share AI Agent Packs. See
pro@coderfor a simple example of how I use AI PACK/genai for production coding.
Note: Feel free to send me a short description and a link to your application or library using genai.
- Native Multi-AI Provider/Model: OpenAI, Anthropic, Gemini, Ollama, Groq, xAI, DeepSeek (Direct chat and stream) (see examples/c00-readme.rs)
- DeepSeekR1 support, with
reasoning_content(and stream support), plus DeepSeek Groq and Ollama support (andreasoning_contentnormalization) - Image Analysis (for OpenAI, Gemini flash-2, Anthropic) (see examples/c07-image.rs)
- Custom Auth/API Key (see examples/c02-auth.rs)
- Model Alias (see examples/c05-model-names.rs)
- Custom Endpoint, Auth, and Model Identifier (see examples/c06-target-resolver.rs)
Examples | Thanks | Library Focus | Changelog | Provider Mapping: ChatOptions | Usage
//! Base examples demonstrating the core capabilities of genai
use genai::chat::printer::{print_chat_stream, PrintChatStreamOptions};
use genai::chat::{ChatMessage, ChatRequest};
use genai::Client;
const MODEL_OPENAI: &str = "gpt-4o-mini"; // o1-mini, gpt-4o-mini
const MODEL_ANTHROPIC: &str = "claude-3-haiku-20240307";
const MODEL_COHERE: &str = "command-light";
const MODEL_GEMINI: &str = "gemini-2.0-flash";
const MODEL_GROQ: &str = "llama-3.1-8b-instant";
const MODEL_OLLAMA: &str = "gemma:2b"; // sh: `ollama pull gemma:2b`
const MODEL_XAI: &str = "grok-beta";
const MODEL_DEEPSEEK: &str = "deepseek-chat";
// NOTE: These are the default environment keys for each AI Adapter Type.
// They can be customized; see `examples/c02-auth.rs`
const MODEL_AND_KEY_ENV_NAME_LIST: &[(&str, &str)] = &[
// -- De/activate models/providers
(MODEL_OPENAI, "OPENAI_API_KEY"),
(MODEL_ANTHROPIC, "ANTHROPIC_API_KEY"),
(MODEL_COHERE, "COHERE_API_KEY"),
(MODEL_GEMINI, "GEMINI_API_KEY"),
(MODEL_GROQ, "GROQ_API_KEY"),
(MODEL_XAI, "XAI_API_KEY"),
(MODEL_DEEPSEEK, "DEEPSEEK_API_KEY"),
(MODEL_OLLAMA, ""),
];
// NOTE: Model to AdapterKind (AI Provider) type mapping rule
// - starts_with "gpt" -> OpenAI
// - starts_with "claude" -> Anthropic
// - starts_with "command" -> Cohere
// - starts_with "gemini" -> Gemini
// - model in Groq models -> Groq
// - For anything else -> Ollama
//
// This can be customized; see `examples/c03-mapper.rs`
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let question = "Why is the sky red?";
let chat_req = ChatRequest::new(vec![
// -- Messages (de/activate to see the differences)
ChatMessage::system("Answer in one sentence"),
ChatMessage::user(question),
]);
let client = Client::default();
let print_options = PrintChatStreamOptions::from_print_events(false);
for (model, env_name) in MODEL_AND_KEY_ENV_NAME_LIST {
// Skip if the environment name is not set
if !env_name.is_empty() && std::env::var(env_name).is_err() {
println!("===== Skipping model: {model} (env var not set: {env_name})");
continue;
}
let adapter_kind = client.resolve_service_target(model)?.model.adapter_kind;
println!("\n===== MODEL: {model} ({adapter_kind}) =====");
println!("\n--- Question:\n{question}");
println!("\n--- Answer:");
let chat_res = client.exec_chat(model, chat_req.clone(), None).await?;
println!("{}", chat_res.content_text_as_str().unwrap_or("NO ANSWER"));
println!("\n--- Answer: (streaming)");
let chat_res = client.exec_chat_stream(model, chat_req.clone(), None).await?;
print_chat_stream(chat_res, Some(&print_options)).await?;
println!();
}
Ok(())
}- examples/c00-readme.rs - Quick overview code with multiple providers and streaming.
- examples/c01-conv.rs - Shows how to build a conversation flow.
-
examples/c02-auth.rs - Demonstrates how to provide a custom
AuthResolverto provide auth data (i.e., for api_key) per adapter kind. -
examples/c03-mapper.rs - Demonstrates how to provide a custom
AdapterKindResolverto customize the "model name" to "adapter kind" mapping. -
examples/c04-chat-options.rs - Demonstrates how to set chat generation options such as
temperatureandmax_tokensat the client level (for all requests) and per-request level. - examples/c05-model-names.rs - Shows how to get model names per AdapterKind.
- examples/c06-target-resolver.rs - For custom Auth, Endpoint, and Model.
- examples/c07-image.rs - Image Analysis support
-
genai live coding, code design, & best practices
- Adding Gemini Structured Output (vid-0060)
- Adding OpenAI Structured Output (vid-0059)
- Splitting the json value extension trait to its own public crate value-ext value-ext
- (part 1/3) Module, Error, constructors/builders
- (part 2/3) Extension Traits, Project Files, Versioning
- (part 3/3) When to Async? Project Files, Versioning strategy
-
Focuses on standardizing chat completion APIs across major AI services.
-
Native implementation, meaning no per-service SDKs.
- Reason: While there are some variations across the various APIs, they all follow the same pattern and high-level flow and constructs. Managing the differences at a lower layer is actually simpler and more cumulative across services than doing SDK gymnastics.
-
Prioritizes ergonomics and commonality, with depth being secondary. (If you require a complete client API, consider using async-openai and ollama-rs; they are both excellent and easy to use.)
-
Initially, this library will mostly focus on text chat APIs; images and function calling will come later.
-
(1) - OpenAI compatibles notes
- Models: OpenAI, DeepSeek, Groq, Ollama, xAI
| Property | OpenAI Compatibles (*1) | Anthropic | Gemini generationConfig.
|
Cohere |
|---|---|---|---|---|
temperature |
temperature |
temperature |
temperature |
temperature |
max_tokens |
max_tokens |
max_tokens (default 1024) |
maxOutputTokens |
max_tokens |
top_p |
top_p |
top_p |
topP |
p |
| Property | OpenAI Compatibles (1) | Anthropic usage.
|
Gemini usageMetadata.
|
Cohere meta.tokens.
|
|---|---|---|---|---|
prompt_tokens |
prompt_tokens |
input_tokens (added) |
promptTokenCount (2) |
input_tokens |
completion_tokens |
completion_tokens |
output_tokens (added) |
candidatesTokenCount (2) |
output_tokens |
total_tokens |
total_tokens |
(computed) |
totalTokenCount (2) |
(computed) |
prompt_tokens_details |
prompt_tokens_details |
cached/cache_creation |
N/A for now | N/A for now |
completion_tokens_details |
completion_tokens_details |
N/A for now | N/A for now | N/A for now |
-
(1) - OpenAI compatibles notes
- Models: OpenAI, DeepSeek, Groq, Ollama, xAI
- For Groq, the property
x_groq.usage. - At this point, Ollama does not emit input/output tokens when streaming due to the Ollama OpenAI compatibility layer limitation. (see ollama #4448 - Streaming Chat Completion via OpenAI API should support stream option to include Usage)
-
prompt_tokens_detailsandcompletion_tokens_detailswill have the value sent by the compatible provider (or None)
-
(2): Gemini tokens
- Right now, with Gemini Stream API, it's not really clear if the usage for each event is cumulative or needs to be added. Currently, it appears to be cumulative (i.e., the last message has the total amount of input, output, and total tokens), so that will be the assumption. See possible tweet answer for more info.
- Will add more data on ChatResponse and ChatStream, especially metadata about usage.
- Add vision/image support to chat messages and responses.
- Add function calling support to chat messages and responses.
- Add
embedandembed_batch - Add the AWS Bedrock variants (e.g., Mistral, and Anthropic). Most of the work will be on "interesting" token signature scheme (without having to drag big SDKs, might be below feature).
- Add the Google VertexAI variants.
- (might) add the Azure OpenAI variant (not sure yet).
- crates.io: crates.io/crates/genai
- GitHub: github.com/jeremychone/rust-genai
- Sponsored by BriteSnow (Jeremy Chone's consulting company)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rust-genai
Similar Open Source Tools
rust-genai
genai is a multi-AI providers library for Rust that aims to provide a common and ergonomic single API to various generative AI providers such as OpenAI, Anthropic, Cohere, Ollama, and Gemini. It focuses on standardizing chat completion APIs across major AI services, prioritizing ergonomics and commonality. The library initially focuses on text chat APIs and plans to expand to support images, function calling, and more in the future versions. Version 0.1.x will have breaking changes in patches, while version 0.2.x will follow semver more strictly. genai does not provide a full representation of a given AI provider but aims to simplify the differences at a lower layer for ease of use.
openai-scala-client
This is a no-nonsense async Scala client for OpenAI API supporting all the available endpoints and params including streaming, chat completion, vision, and voice routines. It provides a single service called OpenAIService that supports various calls such as Models, Completions, Chat Completions, Edits, Images, Embeddings, Batches, Audio, Files, Fine-tunes, Moderations, Assistants, Threads, Thread Messages, Runs, Run Steps, Vector Stores, Vector Store Files, and Vector Store File Batches. The library aims to be self-contained with minimal dependencies and supports API-compatible providers like Azure OpenAI, Azure AI, Anthropic, Google Vertex AI, Groq, Grok, Fireworks AI, OctoAI, TogetherAI, Cerebras, Mistral, Deepseek, Ollama, FastChat, and more.

candle-vllm
Candle-vllm is an efficient and easy-to-use platform designed for inference and serving local LLMs, featuring an OpenAI compatible API server. It offers a highly extensible trait-based system for rapid implementation of new module pipelines, streaming support in generation, efficient management of key-value cache with PagedAttention, and continuous batching. The tool supports chat serving for various models and provides a seamless experience for users to interact with LLMs through different interfaces.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
mediapipe-rs
MediaPipe-rs is a Rust library designed for MediaPipe tasks on WasmEdge WASI-NN. It offers easy-to-use low-code APIs similar to mediapipe-python, with low overhead and flexibility for custom media input. The library supports various tasks like object detection, image classification, gesture recognition, and more, including TfLite models, TF Hub models, and custom models. Users can create task instances, run sessions for pre-processing, inference, and post-processing, and speed up processing by reusing sessions. The library also provides support for audio tasks using audio data from symphonia, ffmpeg, or raw audio. Users can choose between CPU, GPU, or TPU devices for processing.
docutranslate
Docutranslate is a versatile tool for translating documents efficiently. It supports multiple file formats and languages, making it ideal for businesses and individuals needing quick and accurate translations. The tool uses advanced algorithms to ensure high-quality translations while maintaining the original document's formatting. With its user-friendly interface, Docutranslate simplifies the translation process and saves time for users. Whether you need to translate legal documents, technical manuals, or personal letters, Docutranslate is the go-to solution for all your document translation needs.

acte
Acte is a framework designed to build GUI-like tools for AI Agents. It aims to address the issues of cognitive load and freedom degrees when interacting with multiple APIs in complex scenarios. By providing a graphical user interface (GUI) for Agents, Acte helps reduce cognitive load and constraints interaction, similar to how humans interact with computers through GUIs. The tool offers APIs for starting new sessions, executing actions, and displaying screens, accessible via HTTP requests or the SessionManager class.
exstruct
ExStruct is an Excel structured extraction engine that reads Excel workbooks and outputs structured data as JSON, including cells, table candidates, shapes, charts, smartart, merged cell ranges, print areas/views, auto page-break areas, and hyperlinks. It offers different output modes, formula map extraction, table detection tuning, CLI rendering options, and graceful fallback in case Excel COM is unavailable. The tool is designed to fit LLM/RAG pipelines and provides benchmark reports for accuracy and utility. It supports various formats like JSON, YAML, and TOON, with optional extras for rendering and full extraction targeting Windows + Excel environments.

lingo.dev
Replexica AI automates software localization end-to-end, producing authentic translations instantly across 60+ languages. Teams can do localization 100x faster with state-of-the-art quality, reaching more paying customers worldwide. The tool offers a GitHub Action for CI/CD automation and supports various formats like JSON, YAML, CSV, and Markdown. With lightning-fast AI localization, auto-updates, native quality translations, developer-friendly CLI, and scalability for startups and enterprise teams, Replexica is a top choice for efficient and effective software localization.
OpenMemory
OpenMemory is a cognitive memory engine for AI agents, providing real long-term memory capabilities beyond simple embeddings. It is self-hosted and supports Python + Node SDKs, with integrations for various tools like LangChain, CrewAI, AutoGen, and more. Users can ingest data from sources like GitHub, Notion, Google Drive, and others directly into memory. OpenMemory offers explainable traces for recalled information and supports multi-sector memory, temporal reasoning, decay engine, waypoint graph, and more. It aims to provide a true memory system rather than just a vector database with marketing copy, enabling users to build agents, copilots, journaling systems, and coding assistants that can remember and reason effectively.
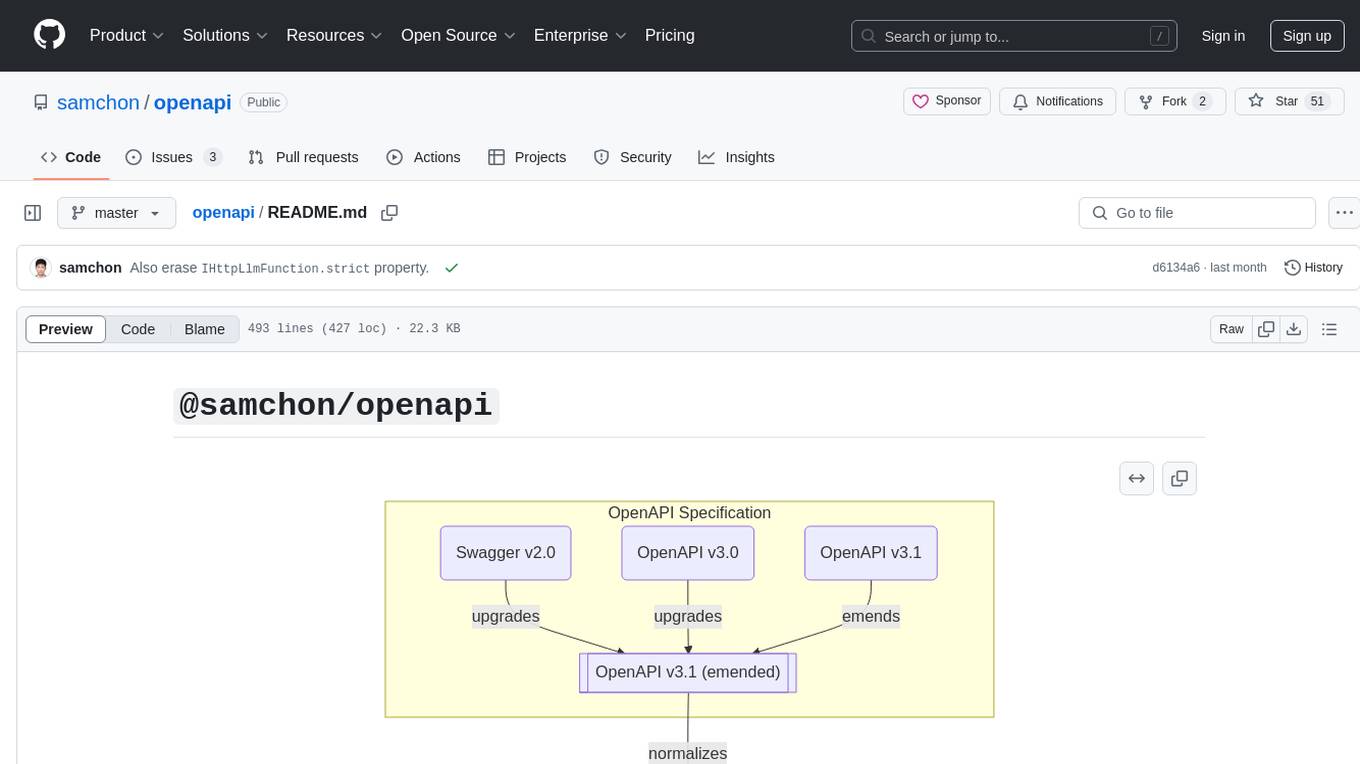
openapi
The `@samchon/openapi` repository is a collection of OpenAPI types and converters for various versions of OpenAPI specifications. It includes an 'emended' OpenAPI v3.1 specification that enhances clarity by removing ambiguous and duplicated expressions. The repository also provides an application composer for LLM (Large Language Model) function calling from OpenAPI documents, allowing users to easily perform LLM function calls based on the Swagger document. Conversions to different versions of OpenAPI documents are also supported, all based on the emended OpenAPI v3.1 specification. Users can validate their OpenAPI documents using the `typia` library with `@samchon/openapi` types, ensuring compliance with standard specifications.
adk-rust
ADK-Rust is a comprehensive and production-ready Rust framework for building AI agents. It features type-safe agent abstractions with async execution and event streaming, multiple agent types including LLM agents, workflow agents, and custom agents, realtime voice agents with bidirectional audio streaming, a tool ecosystem with function tools, Google Search, and MCP integration, production features like session management, artifact storage, memory systems, and REST/A2A APIs, and a developer-friendly experience with interactive CLI, working examples, and comprehensive documentation. The framework follows a clean layered architecture and is production-ready and actively maintained.
react-native-rag
React Native RAG is a library that enables private, local RAGs to supercharge LLMs with a custom knowledge base. It offers modular and extensible components like `LLM`, `Embeddings`, `VectorStore`, and `TextSplitter`, with multiple integration options. The library supports on-device inference, vector store persistence, and semantic search implementation. Users can easily generate text responses, manage documents, and utilize custom components for advanced use cases.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.
langchain-rust
LangChain Rust is a library for building applications with Large Language Models (LLMs) through composability. It provides a set of tools and components that can be used to create conversational agents, document loaders, and other applications that leverage LLMs. LangChain Rust supports a variety of LLMs, including OpenAI, Azure OpenAI, Ollama, and Anthropic Claude. It also supports a variety of embeddings, vector stores, and document loaders. LangChain Rust is designed to be easy to use and extensible, making it a great choice for developers who want to build applications with LLMs.
Webscout
Webscout is an all-in-one Python toolkit for web search, AI interaction, digital utilities, and more. It provides access to diverse search engines, cutting-edge AI models, temporary communication tools, media utilities, developer helpers, and powerful CLI interfaces through a unified library. With features like comprehensive search leveraging Google and DuckDuckGo, AI powerhouse for accessing various AI models, YouTube toolkit for video and transcript management, GitAPI for GitHub data extraction, Tempmail & Temp Number for privacy, Text-to-Speech conversion, GGUF conversion & quantization, SwiftCLI for CLI interfaces, LitPrinter for styled console output, LitLogger for logging, LitAgent for user agent generation, Text-to-Image generation, Scout for web parsing and crawling, Awesome Prompts for specialized tasks, Weather Toolkit, and AI Search Providers.
For similar tasks
rust-genai
genai is a multi-AI providers library for Rust that aims to provide a common and ergonomic single API to various generative AI providers such as OpenAI, Anthropic, Cohere, Ollama, and Gemini. It focuses on standardizing chat completion APIs across major AI services, prioritizing ergonomics and commonality. The library initially focuses on text chat APIs and plans to expand to support images, function calling, and more in the future versions. Version 0.1.x will have breaking changes in patches, while version 0.2.x will follow semver more strictly. genai does not provide a full representation of a given AI provider but aims to simplify the differences at a lower layer for ease of use.
LLaMa2lang
This repository contains convenience scripts to finetune LLaMa3-8B (or any other foundation model) for chat towards any language (that isn't English). The rationale behind this is that LLaMa3 is trained on primarily English data and while it works to some extent for other languages, its performance is poor compared to English.
SiriLLama
Siri LLama is an Apple shortcut that allows users to access locally running LLMs through Siri or the shortcut UI on any Apple device connected to the same network as the host machine. It utilizes Langchain and supports open source models from Ollama or Fireworks AI. Users can easily set up and configure the tool to interact with various language models for chat and multimodal tasks. The tool provides a convenient way to leverage the power of language models through Siri or the shortcut interface, enhancing user experience and productivity.
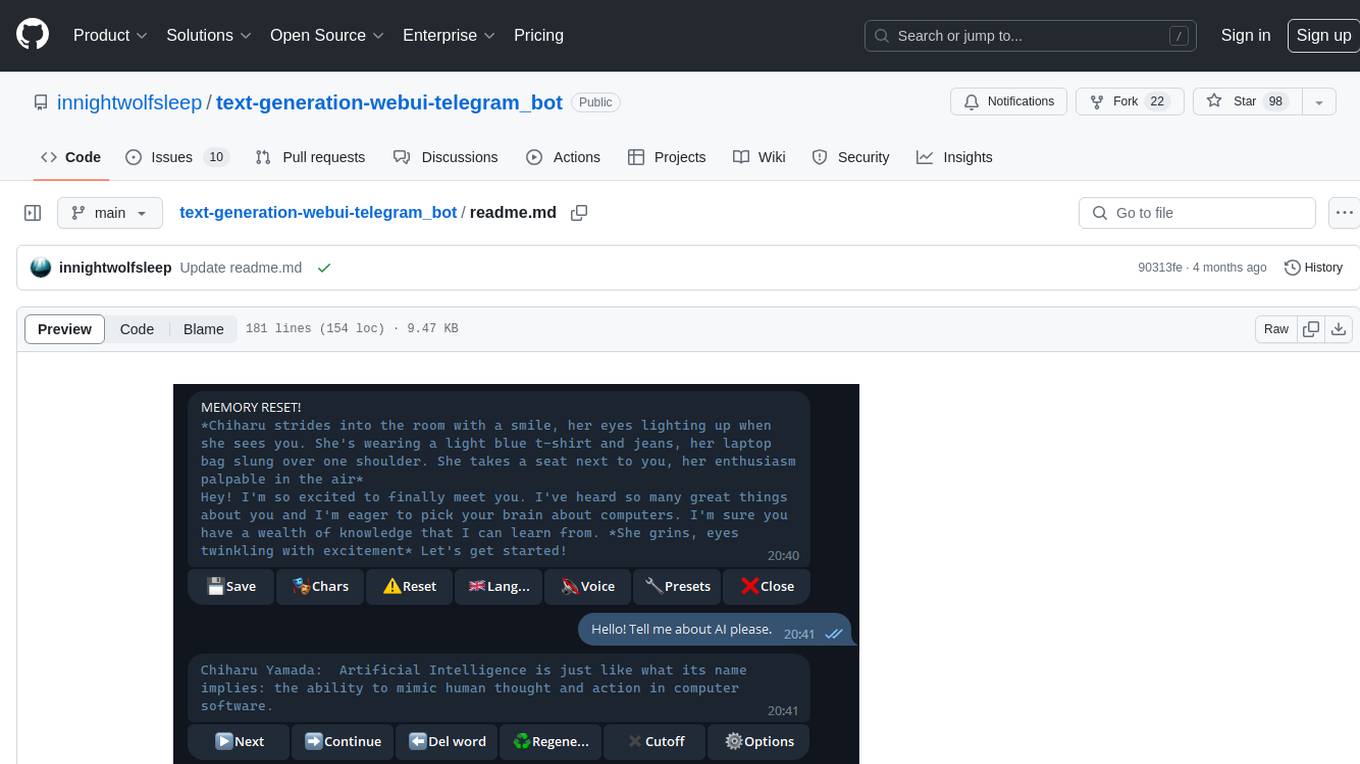
text-generation-webui-telegram_bot
The text-generation-webui-telegram_bot is a wrapper and extension for llama.cpp, exllama, or transformers, providing additional functionality for the oobabooga/text-generation-webui tool. It enhances Telegram chat with features like buttons, prefixes, and voice/image generation. Users can easily install and run the tool as a standalone app or in extension mode, enabling seamless integration with the text-generation-webui tool. The tool offers various features such as chat templates, session history, character loading, model switching during conversation, voice generation, auto-translate, and more. It supports different bot modes for personalized interactions and includes configurations for running in different environments like Google Colab. Additionally, users can customize settings, manage permissions, and utilize various prefixes to enhance the chat experience.
whetstone.chatgpt
Whetstone.ChatGPT is a simple light-weight library that wraps the Open AI API with support for dependency injection. It supports features like GPT 4, GPT 3.5 Turbo, chat completions, audio transcription and translation, vision completions, files, fine tunes, images, embeddings, moderations, and response streaming. The library provides a video walkthrough of a Blazor web app built on it and includes examples such as a command line bot. It offers quickstarts for dependency injection, chat completions, completions, file handling, fine tuning, image generation, and audio transcription.
pg_vectorize
pg_vectorize is a Postgres extension that automates text to embeddings transformation, enabling vector search and LLM applications with minimal function calls. It integrates with popular LLMs, provides workflows for vector search and RAG, and automates Postgres triggers for updating embeddings. The tool is part of the VectorDB Stack on Tembo Cloud, offering high-level APIs for easy initialization and search.
gemini-api-quickstart
This repository contains a simple Python Flask App utilizing the Google AI Gemini API to explore multi-modal capabilities. It provides a basic UI and Flask backend for easy integration and testing. The app allows users to interact with the AI model through chat messages, making it a great starting point for developers interested in AI-powered applications.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.