
yomitoku
Yomitoku is an AI-powered document image analysis package designed specifically for the Japanese language.
Stars: 568
YomiToku is a Japanese-focused AI document image analysis engine that provides full-text OCR and layout analysis capabilities for images. It recognizes, extracts, and converts text information and figures in images. It includes 4 AI models trained on Japanese datasets for tasks such as detecting text positions, recognizing text strings, analyzing layouts, and recognizing table structures. The models are specialized for Japanese document images, supporting recognition of over 7000 Japanese characters and analyzing layout structures specific to Japanese documents. It offers features like layout analysis, table structure analysis, and reading order estimation to extract information from document images without disrupting their semantic structure. YomiToku supports various output formats such as HTML, markdown, JSON, and CSV, and can also extract figures, tables, and images from documents. It operates efficiently in GPU environments, enabling fast and effective analysis of document transcriptions without requiring high-end GPUs.
README:
日本語版 | English
![]()
YomiToku は日本語に特化した AI 文章画像解析エンジン(Document AI)です。画像内の文字の全文 OCR およびレイアウト解析機能を有しており、画像内の文字情報や図表を認識、抽出、変換します。
- 🤖 日本語データセットで学習した 4 種類(文字位置の検知、文字列認識、レイアウト解析、表の構造認識)の AI モデルを搭載しています。4 種類のモデルはすべて独自に学習されたモデルで日本語文書に対して、高精度に推論可能です。
- 🇯🇵 各モデルは日本語の文書画像に特化して学習されており、7000 文字を超える日本語文字の認識をサーポート、手書き文字、縦書きなど日本語特有のレイアウト構造の文書画像の解析も可能です。(日本語以外にも英語の文書に対しても対応しています)。
- 📈 レイアウト解析、表の構造解析, 読み順推定機能により、文書画像のレイアウトの意味的構造を壊さずに情報を抽出することが可能です。
- 📄 多様な出力形式をサポートしています。html やマークダウン、json、csv のいずれかのフォーマットに変換可能です。また、文書内に含まれる図表、画像の抽出の出力も可能です。
- ⚡ GPU 環境で高速に動作し、効率的に文書の文字起こし解析が可能です。また、VRAM も 8GB 以内で動作し、ハイエンドな GPU を用意する必要はありません。
gallery.mdにも複数種類の画像の検証結果を掲載しています。
| 入力画像 | OCR の結果 |
|---|---|
 |
 |
| レイアウト解析の結果 | エクスポート (HTML で出力したものをスクショ) |
 |
 |
Markdown でエクスポートした結果は関してはリポジトリ内のstatic/out/in_demo_p1.mdを参照
-
赤枠: 図、画像等の位置 -
緑枠: 表領域全体の位置 -
ピンク枠: 表のセル構造(セル上の文字は [行番号, 列番号] (rowspan x colspan)を表します) -
青枠: 段落、テキストグループ領域 -
赤矢印: 読み順推定の結果
画像の出典:「令和 6 年版情報通信白書 3 章 2 節 AI の進化に伴い発展するテクノロジー」:(総務省) を加工して作成
- 2024 年 11 月 26 日 YomiToku v0.5.1 (beta) を公開
pip install yomitoku
- pytorch はご自身の CUDA のバージョンにあったものをインストールしてください。デフォルトでは CUDA12.4 以上に対応したものがインストールされます。
- pytorch は 2.5 以上のバージョンに対応しています。その関係で CUDA11.8 以上のバージョンが必要になります。対応できない場合は、リポジトリ内の Dockerfile を利用してください。
yomitoku ${path_data} -f md -o results -v --figure --lite
-
${path_data}解析対象の画像が含まれたディレクトリか画像ファイルのパスを直接して指定してください。ディレクトリを対象とした場合はディレクトリのサブディレクトリ内の画像も含めて処理を実行します。 -
-f,--format出力形式のファイルフォーマットを指定します。(json, csv, html, md をサポート) -
-o,--outdir出力先のディレクトリ名を指定します。存在しない場合は新規で作成されます。 -
-v,--visを指定すると解析結果を可視化した画像を出力します。 -
-l,--liteを指定すると軽量モデルで推論を実行します。通常より高速に推論できますが、若干、精度が低下する可能性があります。 -
-d,--deviceモデルを実行するためのデバイスを指定します。gpu が利用できない場合は cpu で推論が実行されます。(デフォルト: cuda) -
--ignore_line_break画像の改行位置を無視して、段落内の文章を連結して返します。(デフォルト:画像通りの改行位置位置で改行します。) -
--figure_letter検出した図表に含まれる文字も出力ファイルにエクスポートします。 -
--figure検出した図、画像を出力ファイルにエクスポートします。 -
--encodingエクスポートする出力ファイルの文字エンコーディングを指定します。サポートされていない文字コードが含まれる場合は、その文字を無視します。(utf-8, utf-8-sig, shift-jis, enc-jp, cp932) -
--combinePDFを入力に与えたときに、複数ページが含まれる場合に、それらの予測結果を一つのファイルに統合してエクスポートします。 -
--ignore_meta文章のheater, fotterなどの文字情報を出力ファイルに含めません。
その他のオプションに関しては、ヘルプを参照
yomitoku --help
NOTE
- GPU での実行を推奨します。CPU を用いての推論向けに最適化されておらず、処理時間が長くなります。
- Yomitoku は文書 OCR 向けに最適化されており、情景 OCR(看板など紙以外にプリントされた文字の読み取り)向けには最適化されていません。
- AI-OCR の識別精度を高めるために、入力画像の解像度が重要です。低解像度画像では識別精度が低下します。最低でも画像の短辺を 720px 以上の画像で推論することをお勧めします。
パッケージの詳細はドキュメントを確認してください。
本リポジトリ内に格納されているソースコードおよび本プロジェクトに関連する HuggingFaceHub 上のモデルの重みファイルのライセンスは CC BY-NC-SA 4.0 に従います。 非商用での個人利用、研究目的での利用はご自由にお使いください。 商用目的での利用に関しては、別途、商用ライセンスを提供しますので、https://www.mlism.com/ にお問い合わせください。
YomiToku © 2024 by Kotaro Kinoshita is licensed under CC BY-NC-SA 4.0. To view a copy of this license, visit https://creativecommons.org/licenses/by-nc-sa/4.0/
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for yomitoku
Similar Open Source Tools
yomitoku
YomiToku is a Japanese-focused AI document image analysis engine that provides full-text OCR and layout analysis capabilities for images. It recognizes, extracts, and converts text information and figures in images. It includes 4 AI models trained on Japanese datasets for tasks such as detecting text positions, recognizing text strings, analyzing layouts, and recognizing table structures. The models are specialized for Japanese document images, supporting recognition of over 7000 Japanese characters and analyzing layout structures specific to Japanese documents. It offers features like layout analysis, table structure analysis, and reading order estimation to extract information from document images without disrupting their semantic structure. YomiToku supports various output formats such as HTML, markdown, JSON, and CSV, and can also extract figures, tables, and images from documents. It operates efficiently in GPU environments, enabling fast and effective analysis of document transcriptions without requiring high-end GPUs.

evalplus
EvalPlus is a rigorous evaluation framework for LLM4Code, providing HumanEval+ and MBPP+ tests to evaluate large language models on code generation tasks. It offers precise evaluation and ranking, coding rigorousness analysis, and pre-generated code samples. Users can use EvalPlus to generate code solutions, post-process code, and evaluate code quality. The tool includes tools for code generation and test input generation using various backends.

openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.
readme-ai
README-AI is a developer tool that auto-generates README.md files using a combination of data extraction and generative AI. It streamlines documentation creation and maintenance, enhancing developer productivity. This project aims to enable all skill levels, across all domains, to better understand, use, and contribute to open-source software. It offers flexible README generation, supports multiple large language models (LLMs), provides customizable output options, works with various programming languages and project types, and includes an offline mode for generating boilerplate README files without external API calls.
Verbiverse
Verbiverse is a tool that uses a large language model to assist in reading PDFs and watching videos, aimed at improving language proficiency. It provides a more convenient and efficient way to use large models through predefined prompts, designed for those looking to enhance their language skills. The tool analyzes unfamiliar words and sentences in foreign language PDFs or video subtitles, providing better contextual understanding compared to traditional dictionary translations or ambiguous meanings. It offers features such as automatic loading of subtitles, word analysis by clicking or double-clicking, and a word database for collecting words. Users can run the tool on Windows x86_64 or ubuntu_22.04 x86_64 platforms by downloading the precompiled packages or by cloning the source code and setting up a virtual environment with Python. It is recommended to use a local model or smaller PDF files for testing due to potential token consumption issues with large files.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
rust-genai
genai is a multi-AI providers library for Rust that aims to provide a common and ergonomic single API to various generative AI providers such as OpenAI, Anthropic, Cohere, Ollama, and Gemini. It focuses on standardizing chat completion APIs across major AI services, prioritizing ergonomics and commonality. The library initially focuses on text chat APIs and plans to expand to support images, function calling, and more in the future versions. Version 0.1.x will have breaking changes in patches, while version 0.2.x will follow semver more strictly. genai does not provide a full representation of a given AI provider but aims to simplify the differences at a lower layer for ease of use.
LLM-Tuning
LLM-Tuning is a collection of tools and resources for fine-tuning large language models (LLMs). It includes a library of pre-trained LoRA models, a set of tutorials and examples, and a community forum for discussion and support. LLM-Tuning makes it easy to fine-tune LLMs for a variety of tasks, including text classification, question answering, and dialogue generation. With LLM-Tuning, you can quickly and easily improve the performance of your LLMs on downstream tasks.

Noi
Noi is an AI-enhanced customizable browser designed to streamline digital experiences. It includes curated AI websites, allows adding any URL, offers prompts management, Noi Ask for batch messaging, various themes, Noi Cache Mode for quick link access, cookie data isolation, and more. Users can explore, extend, and empower their browsing experience with Noi.

pytorch-lightning
PyTorch Lightning is a framework for training and deploying AI models. It provides a high-level API that abstracts away the low-level details of PyTorch, making it easier to write and maintain complex models. Lightning also includes a number of features that make it easy to train and deploy models on multiple GPUs or TPUs, and to track and visualize training progress. PyTorch Lightning is used by a wide range of organizations, including Google, Facebook, and Microsoft. It is also used by researchers at top universities around the world. Here are some of the benefits of using PyTorch Lightning: * **Increased productivity:** Lightning's high-level API makes it easy to write and maintain complex models. This can save you time and effort, and allow you to focus on the research or business problem you're trying to solve. * **Improved performance:** Lightning's optimized training loops and data loading pipelines can help you train models faster and with better performance. * **Easier deployment:** Lightning makes it easy to deploy models to a variety of platforms, including the cloud, on-premises servers, and mobile devices. * **Better reproducibility:** Lightning's logging and visualization tools make it easy to track and reproduce training results.
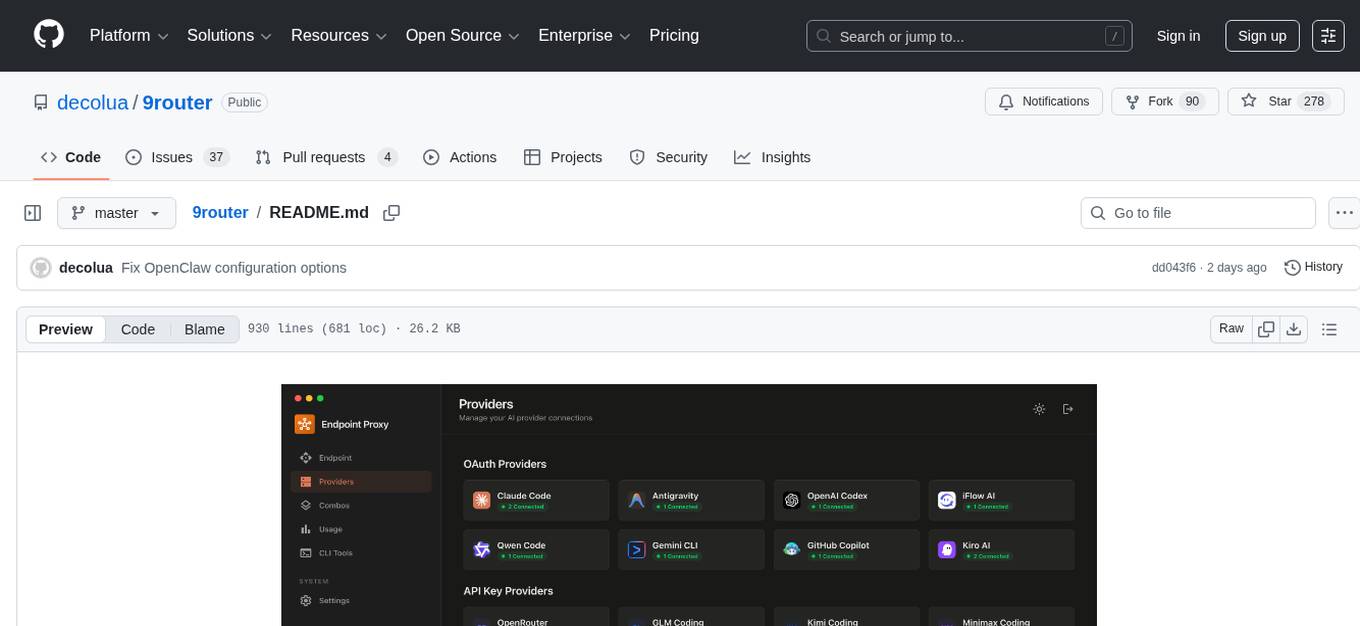
9router
9Router is a free AI router tool designed to help developers maximize their AI subscriptions, auto-route to free and cheap AI models with smart fallback, and avoid hitting limits and wasting money. It offers features like real-time quota tracking, format translation between OpenAI, Claude, and Gemini, multi-account support, auto token refresh, custom model combinations, request logging, cloud sync, usage analytics, and flexible deployment options. The tool supports various providers like Claude Code, Codex, Gemini CLI, GitHub Copilot, GLM, MiniMax, iFlow, Qwen, and Kiro, and allows users to create combos for different scenarios. Users can connect to the tool via CLI tools like Cursor, Claude Code, Codex, OpenClaw, and Cline, and deploy it on VPS, Docker, or Cloudflare Workers.
mediapipe-rs
MediaPipe-rs is a Rust library designed for MediaPipe tasks on WasmEdge WASI-NN. It offers easy-to-use low-code APIs similar to mediapipe-python, with low overhead and flexibility for custom media input. The library supports various tasks like object detection, image classification, gesture recognition, and more, including TfLite models, TF Hub models, and custom models. Users can create task instances, run sessions for pre-processing, inference, and post-processing, and speed up processing by reusing sessions. The library also provides support for audio tasks using audio data from symphonia, ffmpeg, or raw audio. Users can choose between CPU, GPU, or TPU devices for processing.
libllm
libLLM is an open-source project designed for efficient inference of large language models (LLM) on personal computers and mobile devices. It is optimized to run smoothly on common devices, written in C++14 without external dependencies, and supports CUDA for accelerated inference. Users can build the tool for CPU only or with CUDA support, and run libLLM from the command line. Additionally, there are API examples available for Python and the tool can export Huggingface models.

aiotieba
Aiotieba is an asynchronous Python library for interacting with the Tieba API. It provides a comprehensive set of features for working with Tieba, including support for authentication, thread and post management, and image and file uploading. Aiotieba is well-documented and easy to use, making it a great choice for developers who want to build applications that interact with Tieba.

oh-my-pi
oh-my-pi is an AI coding agent for the terminal, providing tools for interactive coding, AI-powered git commits, Python code execution, LSP integration, time-traveling streamed rules, interactive code review, task management, interactive questioning, custom TypeScript slash commands, universal config discovery, MCP & plugin system, web search & fetch, SSH tool, Cursor provider integration, multi-credential support, image generation, TUI overhaul, edit fuzzy matching, and more. It offers a modern terminal interface with smart session management, supports multiple AI providers, and includes various tools for coding, task management, code review, and interactive questioning.
llm_model_hub
Model Hub V2 is a one-stop platform for model fine-tuning, deployment, and debugging without code, providing users with a visual interface to quickly validate the effects of fine-tuning various open-source models, facilitating rapid experimentation and decision-making, and lowering the threshold for users to fine-tune large models. For detailed instructions, please refer to the Feishu documentation.
For similar tasks
docling
Docling is a tool that bundles PDF document conversion to JSON and Markdown in an easy, self-contained package. It can convert any PDF document to JSON or Markdown format, understand detailed page layout, reading order, recover table structures, extract metadata such as title, authors, references, and language, and optionally apply OCR for scanned PDFs. The tool is designed to be stable, lightning fast, and suitable for macOS and Linux environments.
yomitoku
YomiToku is a Japanese-focused AI document image analysis engine that provides full-text OCR and layout analysis capabilities for images. It recognizes, extracts, and converts text information and figures in images. It includes 4 AI models trained on Japanese datasets for tasks such as detecting text positions, recognizing text strings, analyzing layouts, and recognizing table structures. The models are specialized for Japanese document images, supporting recognition of over 7000 Japanese characters and analyzing layout structures specific to Japanese documents. It offers features like layout analysis, table structure analysis, and reading order estimation to extract information from document images without disrupting their semantic structure. YomiToku supports various output formats such as HTML, markdown, JSON, and CSV, and can also extract figures, tables, and images from documents. It operates efficiently in GPU environments, enabling fast and effective analysis of document transcriptions without requiring high-end GPUs.

MegaParse
MegaParse is a powerful and versatile parser designed to handle various types of documents such as text, PDFs, Powerpoint presentations, and Word documents with no information loss. It is fast, efficient, and open source, supporting a wide range of file formats. MegaParse ensures compatibility with tables, table of contents, headers, footers, and images, making it a comprehensive solution for document parsing.
NekoImageGallery
NekoImageGallery is an online AI image search engine that utilizes the Clip model and Qdrant vector database. It supports keyword search and similar image search. The tool generates 768-dimensional vectors for each image using the Clip model, supports OCR text search using PaddleOCR, and efficiently searches vectors using the Qdrant vector database. Users can deploy the tool locally or via Docker, with options for metadata storage using Qdrant database or local file storage. The tool provides API documentation through FastAPI's built-in Swagger UI and can be used for tasks like image search, text extraction, and vector search.
gemini_multipdf_chat
Gemini PDF Chatbot is a Streamlit-based application that allows users to chat with a conversational AI model trained on PDF documents. The chatbot extracts information from uploaded PDF files and answers user questions based on the provided context. It features PDF upload, text extraction, conversational AI using the Gemini model, and a chat interface. Users can deploy the application locally or to the cloud, and the project structure includes main application script, environment variable file, requirements, and documentation. Dependencies include PyPDF2, langchain, Streamlit, google.generativeai, and dotenv.
screen-pipe
Screen-pipe is a Rust + WASM tool that allows users to turn their screen into actions using Large Language Models (LLMs). It enables users to record their screen 24/7, extract text from frames, and process text and images for tasks like analyzing sales conversations. The tool is still experimental and aims to simplify the process of recording screens, extracting text, and integrating with various APIs for tasks such as filling CRM data based on screen activities. The project is open-source and welcomes contributions to enhance its functionalities and usability.
whisper
Whisper is an open-source library by Open AI that converts/extracts text from audio. It is a cross-platform tool that supports real-time transcription of various types of audio/video without manual conversion to WAV format. The library is designed to run on Linux and Android platforms, with plans for expansion to other platforms. Whisper utilizes three frameworks to function: DART for CLI execution, Flutter for mobile app integration, and web/WASM for web application deployment. The tool aims to provide a flexible and easy-to-use solution for transcription tasks across different programs and platforms.
swift-ocr-llm-powered-pdf-to-markdown
Swift OCR is a powerful tool for extracting text from PDF files using OpenAI's GPT-4 Turbo with Vision model. It offers flexible input options, advanced OCR processing, performance optimizations, structured output, robust error handling, and scalable architecture. The tool ensures accurate text extraction, resilience against failures, and efficient handling of multiple requests.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.