Best AI tools for< Document Analyst >
Infographic
19 - AI tool Sites
Immplify
Immplify is the ultimate platform for immigrants, offering an advanced document management system, on-demand immigration-related services, and a vibrant verified immigrant community. The platform prioritizes security, employing 2-factor authentication, data redaction, AES 256-bit encryption, and tokenization to protect users' confidential information. Immplify simplifies the immigration process by providing features like document digitization, on-the-go scanning, advanced encryption, automatic document organization, travel time tracking, intelligent document tracking, key insights dashboard, instant access to immigration guidance, and secure document sharing. Trusted by immigrants for its efficiency and reliability, Immplify streamlines tasks such as managing travel history, organizing documents, filling out visa forms, and ensuring document security.
WhatLetter
WhatLetter is an AI document translation tool designed to help immigrant families and seniors navigate important paperwork without language barriers. Users can snap a photo of any document to get instant insights, chat with an AI chatbot in their preferred language, and translate various types of documents such as personal, business, technical, and more. The tool prioritizes user privacy by not saving images on servers and retaining chat history solely for user reference. WhatLetter aims to simplify document understanding and empower users with a global experience through AI technology.
DocTranslator
DOCTRANSLATOR.COM is an AI-powered online document translation platform that offers seamless translation services for various document formats. With support for over 100 languages, the platform ensures accurate and contextually relevant translations while maintaining the natural flow of content. Users can easily upload documents, track translation progress, and receive high-quality translations tailored to their audience. The platform simplifies the translation process, providing status tracking, dedicated support, and a user-friendly experience.
SlideSpeak
SlideSpeak is an AI-powered tool designed to help users create presentations, summarize documents, and generate presentations with the assistance of AI technology. Users can easily upload PowerPoint, Word, or PDF files and utilize the ChatGPT-powered platform to summarize content, generate presentations, and interact with documents through chat. The platform aims to enhance productivity by providing efficient AI-driven solutions for document management and presentation creation.
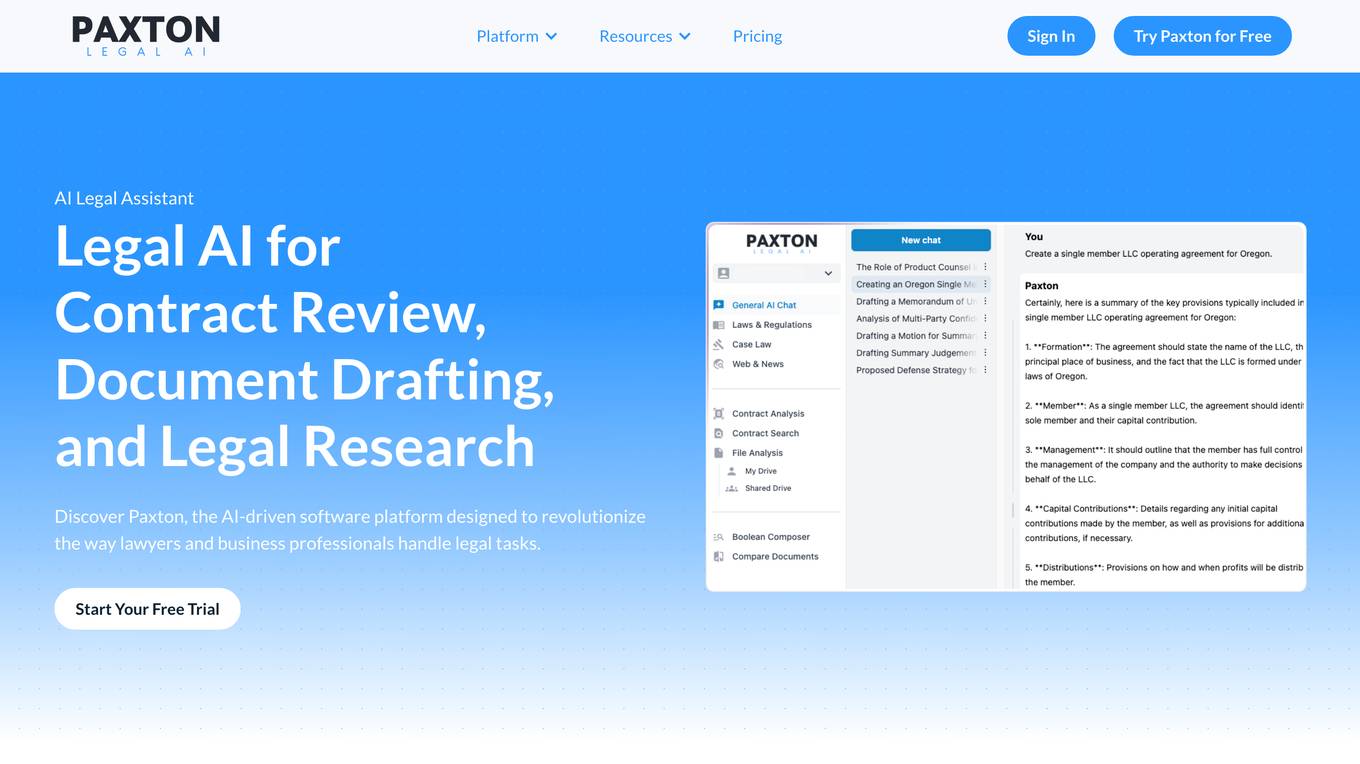
Paxton
Paxton is an advanced AI platform designed to support legal and business professionals by automating and enhancing tasks such as contract review, legal drafting, and document analysis. Utilizing state-of-the-art artificial intelligence, including proprietary Legal Language Models, Paxton streamlines complex legal processes, improves accuracy, and drives efficiency across a wide range of applications.
super.AI
Super.AI provides Intelligent Document Processing (IDP) solutions powered by Large Language Models (LLMs) and human-in-the-loop (HITL) capabilities. It automates document processing tasks such as data extraction, classification, and redaction, enabling businesses to streamline their workflows and improve accuracy. Super.AI's platform leverages cutting-edge AI models from providers like Amazon, Google, and OpenAI to handle complex documents, ensuring high-quality outputs. With its focus on accuracy, flexibility, and scalability, Super.AI caters to various industries, including financial services, insurance, logistics, and healthcare.
GenForge
GenForge is an AI-powered tool that helps you understand and summarize documents quickly and easily. With GenForge, you can: - Get a summary of any document in seconds - Ask deep-dive questions about the details of a document - Get AI support and image generation on-the-go GenForge is the perfect tool for anyone who wants to save time and improve their productivity.

ZekAI
ZekAI is an artificial intelligence platform that provides a suite of tools to help users with a variety of tasks, including writing, designing, exploring documents, and more. The platform is powered by state-of-the-art AI models, including GPT-4, GPT-3.5, and custom models, which enable it to deliver high-quality results and ensure the provision of safe content at all times.
ChatDOC
ChatDOC is an AI-powered tool that allows users to chat with PDF documents and get instant answers with cited sources. It can summarize long documents, explain complex concepts, and find key information in seconds. ChatDOC is built for professionals and is used by over 500,000 global users.

VERSE
VERSE empowers you to seamlessly interact with PDFs, revolutionizing your workflow. With AI-powered responses, direct links to PDF pages, and a distraction-free interface, VERSE enhances your productivity and comprehension. Experience the future of PDF interaction today.
PDF.ai
PDF.ai is a powerful AI-powered tool that allows you to chat with your PDF documents. With PDF.ai, you can ask questions about your PDF, get summaries, translate text, and more. PDF.ai is the perfect tool for anyone who works with PDFs on a regular basis.
AI ChatDocs
AI ChatDocs is an AI-powered tool that allows you to chat with your documents using ChatGPT. It is based on langchain, a natural language processing platform. With AI ChatDocs, you can ask questions about your documents, get summaries, translate them into different languages, and more. It is a valuable tool for anyone who works with documents on a regular basis.
PopAi
PopAi is a personal AI workspace that revolutionizes document interaction, offering seamless navigation, enhanced readability, and universal accessibility. It allows users to effortlessly navigate through intricate documents, magnify details, and tailor the layout for supreme clarity. PopAi also generates images on command, provides access to image prompts and generation codes, and offers image-based homework help, enriching educational support with visual aids. Additionally, it can effortlessly turn ideas into PowerPoint slides with customizable outlines, smart layouts, and automatic illustrations.
ChatPDF
ChatPDF is an AI-powered tool that allows users to interact with PDF documents in a conversational manner. It uses natural language processing (NLP) to understand user queries and provide relevant information or perform actions on the PDF. With ChatPDF, users can ask questions about the content of the PDF, search for specific information, extract data, translate text, and more, all through a simple chat-like interface.
TextMine
TextMine is an AI-powered knowledge base that helps businesses analyze, manage, and search thousands of documents. It uses AI to analyze unstructured textual data and document databases, automatically retrieving key terms to help users make informed decisions. TextMine's features include a document vault for storing and managing documents, a categorization system for organizing documents, and a data extraction tool for extracting insights from documents. TextMine can help businesses save time, money, and improve efficiency by automating manual data entry and information retrieval tasks.

docbot
docbot is an AI-powered tool that allows users to interact with their documents using natural language. Users can create bots, upload documents, share websites, or add text to build knowledge bases and ask questions. The tool supports a wide range of document formats and prioritizes a collaborative, mobile-first experience. docbot simplifies document understanding and management by leveraging AI technology to provide users with a seamless and secure platform for document interaction.
TextMine
TextMine is an AI-powered knowledge base designed for businesses to manage and analyze critical documents efficiently. It offers features such as document analysis, smart-search capabilities, automated data extraction, and structured dataset transformation. TextMine helps businesses save time and money by streamlining document management processes and enabling informed decision-making. The application caters to various industries like Technology, Legal Services, and Financial Services, providing solutions for teams in Procurement, Finance, Compliance, CIOs, and CDOs.
Revealr
Revealr is an AI-powered application that focuses on digitalization for business documents. It offers solutions for transforming, complying, and managing various types of documents using AI technology. Revealr helps organizations unlock knowledge from Word and PDF documents, leverage SharePoint investments, and apply AI in a trusted ecosystem to analyze and explain content. The application aims to deliver real-time access to policies and procedures, reduce costs and risks associated with managing brand portfolios, and empower remote workforces with secure information access. Revealr caters to industries such as financial services, government, insurance, and legal sectors, providing digital solutions to improve compliance, reduce risk, and enhance customer experience.

KLapper Legal Assistant
KLapper is a private and secure GenAI solution designed for law firms, integrating with Microsoft 365 Copilot to provide intelligence from various applications. It offers deep integration with Microsoft Teams and Word, ensuring seamless access within Microsoft 365. KLapper enforces robust security through mirrored DMS role-based access control and allows firms to deploy it securely within their own Microsoft Azure environment. Its Agentic AI capabilities automate administrative tasks, streamlining operations and reducing manual workload. The application assists in legal research, litigation support, document review and analysis, transactional skills, personalized legal support, and billing support.
5 - Open Source Tools
swift-ocr-llm-powered-pdf-to-markdown
Swift OCR is a powerful tool for extracting text from PDF files using OpenAI's GPT-4 Turbo with Vision model. It offers flexible input options, advanced OCR processing, performance optimizations, structured output, robust error handling, and scalable architecture. The tool ensures accurate text extraction, resilience against failures, and efficient handling of multiple requests.
yomitoku
YomiToku is a Japanese-focused AI document image analysis engine that provides full-text OCR and layout analysis capabilities for images. It recognizes, extracts, and converts text information and figures in images. It includes 4 AI models trained on Japanese datasets for tasks such as detecting text positions, recognizing text strings, analyzing layouts, and recognizing table structures. The models are specialized for Japanese document images, supporting recognition of over 7000 Japanese characters and analyzing layout structures specific to Japanese documents. It offers features like layout analysis, table structure analysis, and reading order estimation to extract information from document images without disrupting their semantic structure. YomiToku supports various output formats such as HTML, markdown, JSON, and CSV, and can also extract figures, tables, and images from documents. It operates efficiently in GPU environments, enabling fast and effective analysis of document transcriptions without requiring high-end GPUs.
paperless-ai
Paperless-AI is an automated document analyzer tool designed for Paperless-ngx users. It utilizes the OpenAI API and Ollama (Mistral, llama, phi 3, gemma 2) to automatically scan, analyze, and tag documents. The tool offers features such as automatic document scanning, AI-powered document analysis, automatic title and tag assignment, manual mode for analyzing documents, easy setup through a web interface, document processing dashboard, error handling, and Docker support. Users can configure the tool through a web interface and access a debug interface for monitoring and troubleshooting. Paperless-AI aims to streamline document organization and analysis processes for users with access to Paperless-ngx and AI capabilities.
OpenContracts
OpenContracts is an Apache-2 licensed enterprise document analytics tool that supports multiple formats, including PDF and txt-based formats. It features multiple document ingestion pipelines with a pluggable architecture for easy format and ingestion engine support. Users can create custom document analytics tools with beautiful result displays, support mass document data extraction with a LlamaIndex wrapper, and manage document collections, layout parsing, automatic vector embeddings, and human annotation. The tool also offers pluggable parsing pipelines, human annotation interface, LlamaIndex integration, data extraction capabilities, and custom data extract pipelines for bulk document querying.
OpenContracts
OpenContracts is a free and open-source document analytics platform designed to empower knowledge owners and subject matter experts. It supports multiple document formats, ingestion pipelines, and custom document analytics tools. Users can manage documents, define metadata schemas, extract layout features, generate vector embeddings, deploy custom analyzers, support new document formats, annotate documents, extract bulk data, and create bespoke data extraction workflows. The tool aims to provide a standardized architecture for analyzing contracts and making data portable, with a focus on PDF and text-based formats. It includes features like document management, layout parsing, pluggable architectures, human annotation interface, and a custom LLM framework for conversation management and real-time streaming.
20 - OpenAI Gpts

Visionary Scholar
Assistant to help researchers with thesis research and documentation process.

Refine Product Management Enhancement Document
I help refine product enhancements. Logic - Essential Details - Business Value
Decision Insight AI
Limitless, uncensored AI for decision support, data analysis, and document creation.

CannaIndustry Data Expert
Data trend analysis expert in cannabis, also skilled in image and data analysis, document generation, and web search.
Database Schema Generator
Takes in a Project Design Document and generates a database schema diagram for the project.

EPB CoPilot
Guides USAF Airmen in EPB document creation, utilizing provided military resources.

Expert Biomédical
Enhanced with biomedical document knowledge for in-depth blood test analysis.


Kazakhstani Law Assistant
Versatile legal assistant for Kazakhstani law, adept in document drafting, law analysis, and legal correspondence.
Complaint Assistant
Creates conversational, effective complaint letters, offers document formatting.
US Immigration Assistant
Paralegal specializing in Immigration Law, assisting with research and document preparation.