
swift-ocr-llm-powered-pdf-to-markdown
An open-source OCR API that leverages OpenAI's powerful language models with optimized performance techniques like parallel processing and batching to deliver high-quality text extraction from complex PDF documents. Ideal for businesses seeking efficient document digitization and data extraction solutions.
Stars: 219
Swift OCR is a powerful tool for extracting text from PDF files using OpenAI's GPT-4 Turbo with Vision model. It offers flexible input options, advanced OCR processing, performance optimizations, structured output, robust error handling, and scalable architecture. The tool ensures accurate text extraction, resilience against failures, and efficient handling of multiple requests.
README:
- Flexible Input Options: Accepts PDF files via direct upload or by specifying a URL.
- Advanced OCR Processing: Utilizes OpenAI's GPT-4 Turbo with Vision model for accurate text extraction.
-
Performance Optimizations:
- Parallel PDF Conversion: Converts PDF pages to images concurrently using multiprocessing.
- Batch Processing: Processes multiple images in batches to maximize throughput.
- Retry Mechanism with Exponential Backoff: Ensures resilience against transient failures and API rate limits.
- Structured Output: Extracted text is formatted using Markdown for readability and consistency.
- Robust Error Handling: Comprehensive logging and exception handling for reliable operations.
- Scalable Architecture: Asynchronous processing enables handling multiple requests efficiently.
https://github.com/user-attachments/assets/6b39f3ea-248e-4c29-ac2e-b57de64d5d65
Demo video showcasing the conversion of NASA's Apollo 17 flight documents, which include unorganized, horizontally and vertically oriented pages, into well-structured Markdown format without any issues.
Here's a single, comprehensive section on cost comparison for your README:
Our solution offers an optimal balance of affordability, accuracy, and advanced features:
- Average token usage per image: ~1200
- Total tokens per page (including prompt): ~1500
- [GPT4O] Input token cost: $5 per million tokens
- [GPT4O] Output token cost: $15 per million tokens
For 1000 documents:
- Estimated total cost: $15
- Utilizing GPT4 mini: Reduces cost to ~$8 per 1000 documents
- Implementing batch API: Further reduces cost to ~$4 per 1000 documents
This solution is significantly more affordable than alternatives:
- Our cost: $15 per 1000 documents
- CloudConvert: ~$30 per 1000 documents (PDFTron mode, 4 credits required)
While cost-effectiveness is a major advantage, our solution also provides:
- Superior accuracy and consistency
- Precise table generation
- Output in easily editable markdown format
This combination of affordability and advanced features makes solution stand out in the document processing market. It's not just about being cheaper; it's about providing excellent value through reliability, flexibility, and high-quality output.
- Python 3.8+
- Git
- Virtualenv (optional but recommended)
-
Clone the Repository
git clone https://github.com/yourusername/llm-openai-ocr.git cd llm-openai-ocr -
Create a Virtual Environment
python3 -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate
-
Install Dependencies
pip install -r requirements.txt
-
Configure Environment Variables
Create a
.envfile in the root directory and add the following variables:OPENAI_API_KEY=your_openai_api_key AZURE_OPENAI_ENDPOINT=your_azure_openai_endpoint OPENAI_DEPLOYMENT_ID=your_openai_deployment_id OPENAI_API_VERSION=your_openai_api_version # Default is "gpt-4o" BATCH_SIZE=10 # Optional: Default is 1 MAX_CONCURRENT_OCR_REQUESTS=5 # Optional: Default is 5 MAX_CONCURRENT_PDF_CONVERSION=4 # Optional: Default is 4
Note: Replace
your_openai_api_key,your_azure_openai_endpoint, andyour_openai_deployment_idwith your actual OpenAI credentials. -
Run the Application
uvicorn main:app --reload
The API will be available at
http://127.0.0.1:8000.
POST /ocr
- file: (Optional) Upload a PDF file.
- ocr_request.url: (Optional) URL of the PDF to process.
You must provide either a file or a URL, not both.
Uploading a PDF File:
curl -X POST "http://127.0.0.1:8000/ocr" -F "file=@/path/to/your/document.pdf"Providing a PDF URL:
curl -X POST "http://127.0.0.1:8000/ocr" -F "ocr_request={\"url\": \"https://example.com/document.pdf\"}" -H "Content-Type: application/json"-
200 OK
{ "text": "Extracted and formatted text from the PDF." } -
Error Responses
-
400 Bad Request: Invalid input parameters. -
422 Unprocessable Entity: Validation errors. -
500 Internal Server Error: Processing errors.
-
All configurations are managed via environment variables. Ensure you have a .env file set up with the necessary variables as described in the Installation section.
- OPENAI_API_KEY: Your OpenAI API key.
- AZURE_OPENAI_ENDPOINT: The endpoint for Azure OpenAI service.
- OPENAI_DEPLOYMENT_ID: Deployment ID for the OpenAI model.
- OPENAI_API_VERSION: API version for OpenAI (default: "gpt-4o").
- BATCH_SIZE: Number of images to process per OCR request (default: 1).
- MAX_CONCURRENT_OCR_REQUESTS: Maximum number of concurrent OCR requests (default: 5).
- MAX_CONCURRENT_PDF_CONVERSION: Maximum number of concurrent PDF page conversions (default: 4).
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for swift-ocr-llm-powered-pdf-to-markdown
Similar Open Source Tools
swift-ocr-llm-powered-pdf-to-markdown
Swift OCR is a powerful tool for extracting text from PDF files using OpenAI's GPT-4 Turbo with Vision model. It offers flexible input options, advanced OCR processing, performance optimizations, structured output, robust error handling, and scalable architecture. The tool ensures accurate text extraction, resilience against failures, and efficient handling of multiple requests.

TranslateBookWithLLM
TranslateBookWithLLM is a Python application designed for large-scale text translation, such as entire books (.EPUB), subtitle files (.SRT), and plain text. It leverages local LLMs via the Ollama API or Gemini API. The tool offers both a web interface for ease of use and a command-line interface for advanced users. It supports multiple format translations, provides a user-friendly browser-based interface, CLI support for automation, multiple LLM providers including local Ollama models and Google Gemini API, and Docker support for easy deployment.
paelladoc
PAELLADOC is an intelligent documentation system that uses AI to analyze code repositories and generate comprehensive technical documentation. It offers a modular architecture with MECE principles, interactive documentation process, key features like Orchestrator and Commands, and a focus on context for successful AI programming. The tool aims to streamline documentation creation, code generation, and product management tasks for software development teams, providing a definitive standard for AI-assisted development documentation.
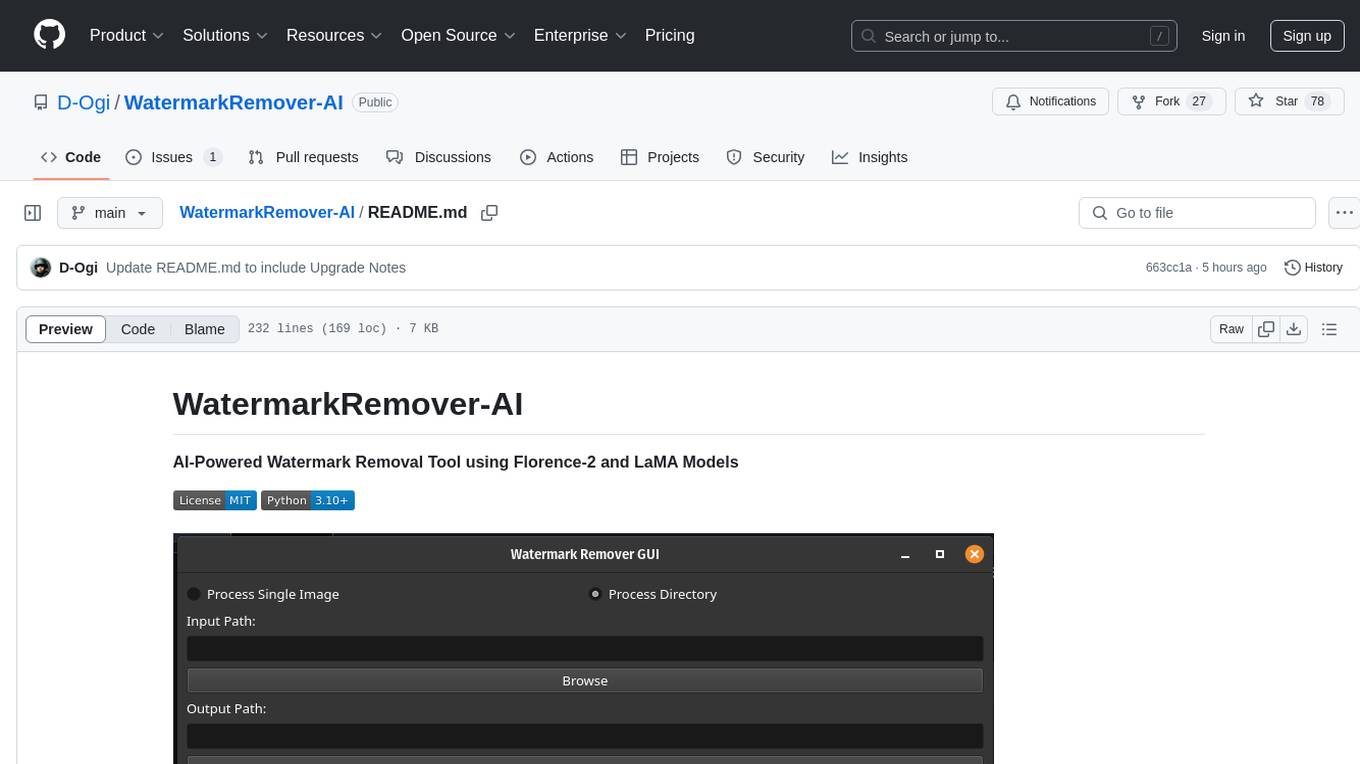
WatermarkRemover-AI
WatermarkRemover-AI is an advanced application that utilizes AI models for precise watermark detection and seamless removal. It leverages Florence-2 for watermark identification and LaMA for inpainting. The tool offers both a command-line interface (CLI) and a PyQt6-based graphical user interface (GUI), making it accessible to users of all levels. It supports dual modes for processing images, advanced watermark detection, seamless inpainting, customizable output settings, real-time progress tracking, dark mode support, and efficient GPU acceleration using CUDA.

probe
Probe is an AI-friendly, fully local, semantic code search tool designed to power the next generation of AI coding assistants. It combines the speed of ripgrep with the code-aware parsing of tree-sitter to deliver precise results with complete code blocks, making it perfect for large codebases and AI-driven development workflows. Probe is fully local, keeping code on the user's machine without relying on external APIs. It supports multiple languages, offers various search options, and can be used in CLI mode, MCP server mode, AI chat mode, and web interface. The tool is designed to be flexible, fast, and accurate, providing developers and AI models with full context and relevant code blocks for efficient code exploration and understanding.
rkllama
RKLLama is a server and client tool designed for running and interacting with LLM models optimized for Rockchip RK3588(S) and RK3576 platforms. It allows models to run on the NPU, with features such as running models on NPU, partial Ollama API compatibility, pulling models from Huggingface, API REST with documentation, dynamic loading/unloading of models, inference requests with streaming modes, simplified model naming, CPU model auto-detection, and optional debug mode. The tool supports Python 3.8 to 3.12 and has been tested on Orange Pi 5 Pro and Orange Pi 5 Plus with specific OS versions.
zotero-mcp
Zotero MCP is an open-source project that integrates AI capabilities with Zotero using the Model Context Protocol. It consists of a Zotero plugin and an MCP server, enabling AI assistants to search, retrieve, and cite references from Zotero library. The project features a unified architecture with an integrated MCP server, eliminating the need for a separate server process. It provides features like intelligent search, detailed reference information, filtering by tags and identifiers, aiding in academic tasks such as literature reviews and citation management.
scira
Scira is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for data exploration, cleaning, and modeling. With Scira, users can easily import datasets, perform statistical analysis, create insightful visualizations, and generate reports. The tool supports various data formats and offers a wide range of statistical functions and visualization options. Whether you are a data scientist, researcher, or student, Scira can help you uncover valuable insights from your data and communicate your findings effectively.
persistent-ai-memory
Persistent AI Memory System is a comprehensive tool that offers persistent, searchable storage for AI assistants. It includes features like conversation tracking, MCP tool call logging, and intelligent scheduling. The system supports multiple databases, provides enhanced memory management, and offers various tools for memory operations, schedule management, and system health checks. It also integrates with various platforms like LM Studio, VS Code, Koboldcpp, Ollama, and more. The system is designed to be modular, platform-agnostic, and scalable, allowing users to handle large conversation histories efficiently.
coding-agent-template
Coding Agent Template is a versatile tool for building AI-powered coding agents that support various coding tasks using Claude Code, OpenAI's Codex CLI, Cursor CLI, and opencode with Vercel Sandbox. It offers features like multi-agent support, Vercel Sandbox for secure code execution, AI Gateway integration, AI-generated branch names, task management, persistent storage, Git integration, and a modern UI built with Next.js and Tailwind CSS. Users can easily deploy their own version of the template to Vercel and set up the tool by cloning the repository, installing dependencies, configuring environment variables, setting up the database, and starting the development server. The tool simplifies the process of creating tasks, monitoring progress, reviewing results, and managing tasks, making it ideal for developers looking to automate coding tasks with AI agents.
lyraios
LYRAIOS (LLM-based Your Reliable AI Operating System) is an advanced AI assistant platform built with FastAPI and Streamlit, designed to serve as an operating system for AI applications. It offers core features such as AI process management, memory system, and I/O system. The platform includes built-in tools like Calculator, Web Search, Financial Analysis, File Management, and Research Tools. It also provides specialized assistant teams for Python and research tasks. LYRAIOS is built on a technical architecture comprising FastAPI backend, Streamlit frontend, Vector Database, PostgreSQL storage, and Docker support. It offers features like knowledge management, process control, and security & access control. The roadmap includes enhancements in core platform, AI process management, memory system, tools & integrations, security & access control, open protocol architecture, multi-agent collaboration, and cross-platform support.
strava-mcp
Strava MCP Server is a TypeScript implementation of a Model Context Protocol (MCP) server that serves as a bridge to the Strava API. It provides tools for accessing recent activities, detailed activity streams, segments exploration, activity and segment effort information, saved routes details, and route exporting in GPX or TCX format. The server offers AI-friendly JSON responses via MCP and utilizes Strava API V3 for seamless integration. Users can interact with their Strava data through natural language queries and advanced prompts, enabling personalized analysis and visualization of their activities.

llamafarm
LlamaFarm is a comprehensive AI framework that empowers users to build powerful AI applications locally, with full control over costs and deployment options. It provides modular components for RAG systems, vector databases, model management, prompt engineering, and fine-tuning. Users can create differentiated AI products without needing extensive ML expertise, using simple CLI commands and YAML configs. The framework supports local-first development, production-ready components, strategy-based configuration, and deployment anywhere from laptops to the cloud.
finite-monkey-engine
FiniteMonkey is an advanced vulnerability mining engine powered purely by GPT, requiring no prior knowledge base or fine-tuning. Its effectiveness significantly surpasses most current related research approaches. The tool is task-driven, prompt-driven, and focuses on prompt design, leveraging 'deception' and hallucination as key mechanics. It has helped identify vulnerabilities worth over $60,000 in bounties. The tool requires PostgreSQL database, OpenAI API access, and Python environment for setup. It supports various languages like Solidity, Rust, Python, Move, Cairo, Tact, Func, Java, and Fake Solidity for scanning. FiniteMonkey is best suited for logic vulnerability mining in real projects, not recommended for academic vulnerability testing. GPT-4-turbo is recommended for optimal results with an average scan time of 2-3 hours for medium projects. The tool provides detailed scanning results guide and implementation tips for users.

Hacx-GPT
Hacx GPT is a cutting-edge AI tool developed by BlackTechX, inspired by WormGPT, designed to push the boundaries of natural language processing. It is an advanced broken AI model that facilitates seamless and powerful interactions, allowing users to ask questions and perform various tasks. The tool has been rigorously tested on platforms like Kali Linux, Termux, and Ubuntu, offering powerful AI conversations and the ability to do anything the user wants. Users can easily install and run Hacx GPT on their preferred platform to explore its vast capabilities.
SynthLang
SynthLang is a tool designed to optimize AI prompts by reducing costs and improving processing speed. It brings academic rigor to prompt engineering, creating precise and powerful AI interactions. The tool includes core components like a Translator Engine, Performance Optimization, Testing Framework, and Technical Architecture. It offers mathematical precision, academic rigor, enhanced security, a modern interface, and instant testing. Users can integrate mathematical frameworks, model complex relationships, and apply structured prompts to various domains. Security features include API key management and data privacy. The tool also provides a CLI for prompt engineering and optimization capabilities.
For similar tasks
swift-ocr-llm-powered-pdf-to-markdown
Swift OCR is a powerful tool for extracting text from PDF files using OpenAI's GPT-4 Turbo with Vision model. It offers flexible input options, advanced OCR processing, performance optimizations, structured output, robust error handling, and scalable architecture. The tool ensures accurate text extraction, resilience against failures, and efficient handling of multiple requests.
llm-data-scrapers
LLM Data Scrapers is a collection of open source tools and scrapers designed to gather data for Large Language Models (LLMs). The repository includes various tools such as gitingest for extracting codebases, repomix for packing repositories into AI-friendly files, llm-scraper for converting webpages into structured data, crawl4ai for web crawling, and firecrawl for turning websites into LLM-ready markdown or structured data. Additionally, the repository offers tools like llmstxt-generator for generating training data, trafilatura for gathering web text and metadata, RepoToTextForLLMs for fetching repo content, marker for converting PDFs, reader for converting URLs to LLM-friendly inputs, and files-to-prompt for concatenating files into prompts for LLMs.

MegaParse
MegaParse is a powerful and versatile parser designed to handle various types of documents such as text, PDFs, Powerpoint presentations, and Word documents with no information loss. It is fast, efficient, and open source, supporting a wide range of file formats. MegaParse ensures compatibility with tables, table of contents, headers, footers, and images, making it a comprehensive solution for document parsing.
NekoImageGallery
NekoImageGallery is an online AI image search engine that utilizes the Clip model and Qdrant vector database. It supports keyword search and similar image search. The tool generates 768-dimensional vectors for each image using the Clip model, supports OCR text search using PaddleOCR, and efficiently searches vectors using the Qdrant vector database. Users can deploy the tool locally or via Docker, with options for metadata storage using Qdrant database or local file storage. The tool provides API documentation through FastAPI's built-in Swagger UI and can be used for tasks like image search, text extraction, and vector search.
gemini_multipdf_chat
Gemini PDF Chatbot is a Streamlit-based application that allows users to chat with a conversational AI model trained on PDF documents. The chatbot extracts information from uploaded PDF files and answers user questions based on the provided context. It features PDF upload, text extraction, conversational AI using the Gemini model, and a chat interface. Users can deploy the application locally or to the cloud, and the project structure includes main application script, environment variable file, requirements, and documentation. Dependencies include PyPDF2, langchain, Streamlit, google.generativeai, and dotenv.
screen-pipe
Screen-pipe is a Rust + WASM tool that allows users to turn their screen into actions using Large Language Models (LLMs). It enables users to record their screen 24/7, extract text from frames, and process text and images for tasks like analyzing sales conversations. The tool is still experimental and aims to simplify the process of recording screens, extracting text, and integrating with various APIs for tasks such as filling CRM data based on screen activities. The project is open-source and welcomes contributions to enhance its functionalities and usability.
whisper
Whisper is an open-source library by Open AI that converts/extracts text from audio. It is a cross-platform tool that supports real-time transcription of various types of audio/video without manual conversion to WAV format. The library is designed to run on Linux and Android platforms, with plans for expansion to other platforms. Whisper utilizes three frameworks to function: DART for CLI execution, Flutter for mobile app integration, and web/WASM for web application deployment. The tool aims to provide a flexible and easy-to-use solution for transcription tasks across different programs and platforms.
extractous
Extractous offers a fast and efficient solution for extracting content and metadata from various document types such as PDF, Word, HTML, and many other formats. It is built with Rust, providing high performance, memory safety, and multi-threading capabilities. The tool eliminates the need for external services or APIs, making data processing pipelines faster and more efficient. It supports multiple file formats, including Microsoft Office, OpenOffice, PDF, spreadsheets, web documents, e-books, text files, images, and email formats. Extractous provides a clear and simple API for extracting text and metadata content, with upcoming support for JavaScript/TypeScript. It is free for commercial use under the Apache 2.0 License.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.