
whisper
Whisper Dart is a cross platform library for dart and flutter that allows converting audio to text / speech to text / inference from Open AI models
Stars: 527
Whisper is an open-source library by Open AI that converts/extracts text from audio. It is a cross-platform tool that supports real-time transcription of various types of audio/video without manual conversion to WAV format. The library is designed to run on Linux and Android platforms, with plans for expansion to other platforms. Whisper utilizes three frameworks to function: DART for CLI execution, Flutter for mobile app integration, and web/WASM for web application deployment. The tool aims to provide a flexible and easy-to-use solution for transcription tasks across different programs and platforms.
README:
Whisper adalah sebuah library opensource milik open ai yang berguna untuk mengubah / mendapatkan text dari sebuah audio
Library ini di buat 100% tanpa menjiplak kode orang lain, jika anda ingin feature silahkan request (jangan menulis ulang lalu mengpublish di pub.dev) / tempat lainya tanpa mencamtumkan nama SAYA AZKADEV
-
Cross Platform
- [x] linux
- [x] android
- [x] cli
- [ ] windows
- [ ] macos
- [ ] web
- [ ] ios
-
Realtime Transcribe
- [ ] android
- [ ] linux
- [ ] macos
- [ ] cli
- [ ] windows
- [ ] web
- [ ] ios
-
Bisa Transcribe Semua jenis audio / video Tanpa perlu manual convert / rubah ke wav
- [ ] android
- [ ] linux
- [ ] macos
- [ ] cli
- [ ] windows
- [ ] web
- [ ] ios
| NAME | OS | CPU | GPU | RAM |
|---|---|---|---|---|
| REALME 5 | LINEAGE OS ANDROID | SNAPDRAGON 665 | 3GB | |
| MSI MODERN 14 | UBUNTU 24.04 | AMD RYZEN 5500u | 16GB | |
| XIAOMI REDMI 4a | MIUI | 2GB | ||
| ACER | UBUNTU SERVER 24.04 |
jika anda berharap saya menerapkan pada platform tertentu selain linux / android berikan saya donasi uang di github agar saya bisa membeli perangkat, karena saat ini perangkat saya hanya 2
Di karenakan versi lama sangat kacau / berantakan, saya membuat ulang menggunakan style code yang hampir sama, namun semuanya di rubah agar bisa berjalan cross platform dan support semua feature terbaru dari sumber asli [Whisper.cpp]
Sebenarnya saya menggunakan 3 kerangka kerja agar library ini berjalan
-
Bagaimana bisa berjalan di DART secara contoh asli yang ada pada whisper.cpp terdapat sumber code untuk menjalankan di cli yang harus menjalankan command seperti ./main bla bla bla bla -model path_to_model
itu adalah sumber acuan pertama agar kita bisa mengubah sumber code.
Contoh: ini adalah source asli
saya menambah bagian sedikit, dan mengubah parameters data menjadi json, hal ini di karenakan json flexible sehingga sangat mudah di pakai dan di applikasikan ke berbagai program setelah itu saya membuat CMakeLists.txt ini untuk mengcompile semua source code cpp / c / native yang di butuhkan
-
Bagaimana Bisa berjalan di FLUTTER secara teori jika anda berhasil melakukan tadi menjalankan di dart maka akan berjalan di flutter hal ini karena flutter menggunakan bahasa dart
-
Bagaimana Bisa berjalan di web / wasm secara teori jika anda berhasil menjalankan di dart jika anda bisa mengubah style code dasar yang akan di gunakan secara general (SCHEMA) anda bisa menjalankan di web walaupun mungkin ada feature yang tidak bisa di gunakan seperti auto convert
Di karenakan kebanyakan library hanya fokus pada platform tertentu tidak ingin / tidak ada rencana berjalan di semua platform oleh karena itu mungkin anda bisa mengsupport saya melalui hal di bawah
-
DONATE / SPONSOR Sebenarnya selain saya membuat library untuk orang umum / mempermudah saya juga ingin mendapat dana agar saya bisa mempercepat release baru, semakin banyak donate akan ada kesempatan untuk release baru program / support pada platform tertentu
-
FOLLOW SOCIAL MEDIA Saya ingin memperoleh penghasilan lainya sekaligus mengshare kontent tentang developer hal lainya mungkin jika anda tidak keberatan silahkan follow semuanya
tapi tidak ada tag dart di pub.dev?
Hiraukan issue itu saya menambahkan flutter di library whisper sehingga library menjadi satu dan anda hanya merubah bagian import saja sesuai platform anda
Q: Akankah anda akan support dart penuh tanpa native library? A: Jika sumber uang saya banyak saya akan mengsupport penuh sehingga whisper akan berjalan sangat efficient
Q: Saya ingin mengkomersialkan applikasi saya transcribe apakah saya harus membayar license / mencantumkan nama anda? A: Tidak perlu membayar license, ya sebaiknya anda mencantumkan saja nama saya / link social media saya
Q: Saya ingin menambahkan di bot TELEGRAM | DISCORD | WA apakah bisa? A: Tentu namun saat ini saya hanya mengtest di cli di platform linux, jika anda berhasil compile library ke platform anda anda sudah bisa menggunakanya
Tolong jangan mencoba membuat ulang code ini, jika ingin menambah silahkan cantumkan nama saya dan link github saya di project anda
Copyright 2023-2024 NOW - AZKADEV https://github.com/azkadev
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for whisper
Similar Open Source Tools
whisper
Whisper is an open-source library by Open AI that converts/extracts text from audio. It is a cross-platform tool that supports real-time transcription of various types of audio/video without manual conversion to WAV format. The library is designed to run on Linux and Android platforms, with plans for expansion to other platforms. Whisper utilizes three frameworks to function: DART for CLI execution, Flutter for mobile app integration, and web/WASM for web application deployment. The tool aims to provide a flexible and easy-to-use solution for transcription tasks across different programs and platforms.
Kai
Kai is a cross-platform open-source AI interface that runs on Android, iOS, Windows, Mac, Linux, and Web. It supports encrypted local history storage, text to speech output, seamless switch between services, and file attachments. Users can enable or disable tools like Get Local Time, Get Location, Send Notification, Create Calendar Event, Check Recent SMS, and Send SMS. The tool is designed to provide various AI services and features for different platforms.
general
General is a DART & Flutter library created by AZKADEV to speed up development on various platforms and CLI easily. It allows access to features such as camera, fingerprint, SMS, and MMS. The library is designed for Dart language and provides functionalities for app background, text to speech, speech to text, and more.

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.
OpenAiTx
OpenAiTx is a language auto-translate tool designed for GitHub project readme & wiki. It uses premium-grade LLM for one-time translation and makes the results freely accessible to the open-source community. The tool supports Google/Bing multiple languages SEO search, which regular client translate tools cannot do. It is free and open source forever, allowing project maintainers to save time by submitting once and auto-updating in the future. OpenAiTx provides users with different style options for language display badges or text, making it easy to integrate into readme files. Contributors can participate by forking the project, cloning it, choosing a script in their preferred language, filling in their AI token, running it, and creating a pull request. It is important not to upload personal tokens for security reasons. The tool is specifically designed for GitHub markdown and aims to help users translate their projects efficiently.

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.
RSS-Translator
RSS-Translator is an open-source, simple, and self-deployable tool that allows users to translate titles or content, display in bilingual, subscribe to translated RSS/JSON feeds, support multiple translation engines, control update frequency of translation sources, view translation status, cache all translated content to reduce translation costs, view token/character usage for each source, provide AI content summarization, and retrieve full text. It currently supports various translation engines such as Free Translators, DeepL, OpenAI, ClaudeAI, Azure OpenAI, Google Gemini, Google Translate, Microsoft Translate API, Caiyun API, Moonshot AI, Together AI, OpenRouter AI, Groq, Doubao, OpenL, and Kagi API, with more being added continuously.
Odyssey
Odyssey is a framework designed to empower agents with open-world skills in Minecraft. It provides an interactive agent with a skill library, a fine-tuned LLaMA-3 model, and an open-world benchmark for evaluating agent capabilities. The framework enables agents to explore diverse gameplay opportunities in the vast Minecraft world by offering primitive and compositional skills, extensive training data, and various long-term planning tasks. Odyssey aims to advance research on autonomous agent solutions by providing datasets, model weights, and code for public use.
cursor-free-vip
Cursor Free VIP is an automation tool that registers accounts with custom emails, supports Google and GitHub account registrations, temporary GitHub account registration, kills all Cursor's running processes, resets and wipes Cursor data and hardware info. It supports Windows, macOS, and Linux systems. For optimal performance, run with privileges and always stay up to date. Always clean your browser's cache and cookies. The tool is designed for learning and research purposes, and users should comply with relevant software usage terms. It offers multi-language support and various features like Google OAuth Authentication, GitHub OAuth Authentication, automatic Cursor membership registration, system support for Windows, macOS, and Linux, and more.
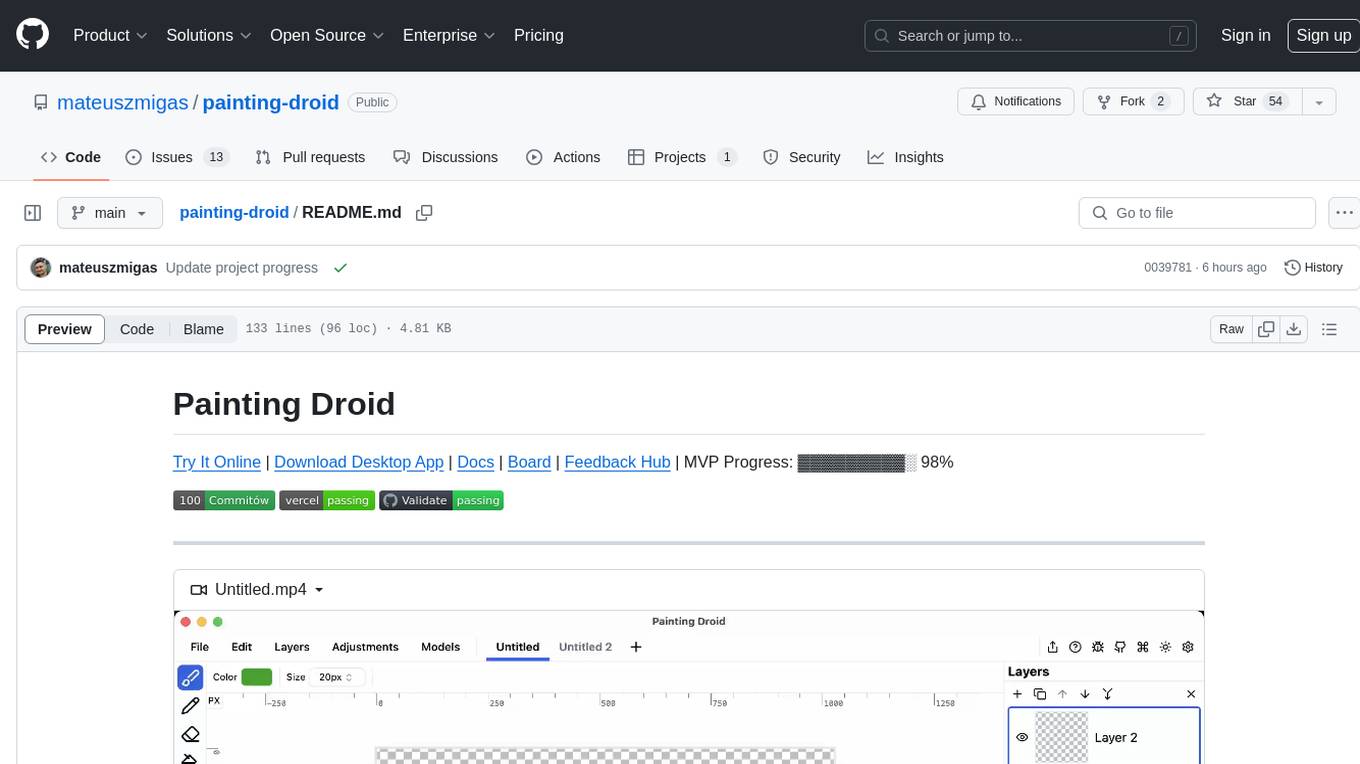
painting-droid
Painting Droid is an AI-powered cross-platform painting app inspired by MS Paint, expandable with plugins and open. It utilizes various AI models, from paid providers to self-hosted open-source models, as well as some lightweight ones built into the app. Features include regular painting app features, AI-generated content filling and augmentation, filters and effects, image manipulation, plugin support, and cross-platform compatibility.

wa_llm
WhatsApp Group Summary Bot is an AI-powered tool that joins WhatsApp groups, tracks conversations, and generates intelligent summaries. It features automated group chat responses, LLM-based conversation summaries, knowledge base integration, persistent message history with PostgreSQL, support for multiple message types, group management, and a REST API with Swagger docs. Prerequisites include Docker, Python 3.12+, PostgreSQL with pgvector extension, Voyage AI API key, and a WhatsApp account for the bot. The tool can be quickly set up by cloning the repository, configuring environment variables, starting services, and connecting devices. It offers API usage for loading new knowledge base topics and generating & dispatching summaries to managed groups. The project architecture includes FastAPI backend, WhatsApp Web API client, PostgreSQL database with vector storage, and AI-powered message processing.

GIMP-ML
A.I. for GNU Image Manipulation Program (GIMP-ML) is a repository that provides Python plugins for using computer vision models in GIMP. The code base and models are continuously updated to support newer and more stable functionality. Users can edit images with text, outpaint images, and generate images from text using models like Dalle 2 and Dalle 3. The repository encourages citations using a specific bibtex entry and follows the MIT license for GIMP-ML and the original models.
auto-dev
AutoDev is an AI-powered coding wizard that supports multiple languages, including Java, Kotlin, JavaScript/TypeScript, Rust, Python, Golang, C/C++/OC, and more. It offers a range of features, including auto development mode, copilot mode, chat with AI, customization options, SDLC support, custom AI agent integration, and language features such as language support, extensions, and a DevIns language for AI agent development. AutoDev is designed to assist developers with tasks such as auto code generation, bug detection, code explanation, exception tracing, commit message generation, code review content generation, smart refactoring, Dockerfile generation, CI/CD config file generation, and custom shell/command generation. It also provides a built-in LLM fine-tune model and supports UnitEval for LLM result evaluation and UnitGen for code-LLM fine-tune data generation.
wp-ai-chat
The 'wp-ai-chat' repository is an open-source and free WordPress AI assistant plugin that enables various AI functionalities such as AI chat conversations, AI voice playback, AI article generation, AI article summarization, AI article translation, AI PPT generation, AI document analysis, and article content voice playback. It supports integration with multiple AI text interfaces and intelligent applications from platforms like Alibaba, Tencent, and ByteDance. Users can generate articles, summarize articles, translate articles, play article content via text-to-speech services, and customize AI models and prompts. The plugin requires WordPress 6.7.1 and PHP 8.0, and provides a front-end chat interface for logged-in users.

supabase
Supabase is an open source Firebase alternative that provides a wide range of features including a hosted Postgres database, authentication and authorization, auto-generated APIs, REST and GraphQL support, realtime subscriptions, functions, file storage, AI and vector/embeddings toolkit, and a dashboard. It aims to offer developers a Firebase-like experience using enterprise-grade open source tools.
computer
Cua is a tool for creating and running high-performance macOS and Linux VMs on Apple Silicon, with built-in support for AI agents. It provides libraries like Lume for running VMs with near-native performance, Computer for interacting with sandboxes, and Agent for running agentic workflows. Users can refer to the documentation for onboarding and explore demos showcasing the tool's capabilities. Additionally, accessory libraries like Core, PyLume, Computer Server, and SOM offer additional functionality. Contributions to Cua are welcome, and the tool is open-sourced under the MIT License.
For similar tasks
whisper
Whisper is an open-source library by Open AI that converts/extracts text from audio. It is a cross-platform tool that supports real-time transcription of various types of audio/video without manual conversion to WAV format. The library is designed to run on Linux and Android platforms, with plans for expansion to other platforms. Whisper utilizes three frameworks to function: DART for CLI execution, Flutter for mobile app integration, and web/WASM for web application deployment. The tool aims to provide a flexible and easy-to-use solution for transcription tasks across different programs and platforms.

MegaParse
MegaParse is a powerful and versatile parser designed to handle various types of documents such as text, PDFs, Powerpoint presentations, and Word documents with no information loss. It is fast, efficient, and open source, supporting a wide range of file formats. MegaParse ensures compatibility with tables, table of contents, headers, footers, and images, making it a comprehensive solution for document parsing.
NekoImageGallery
NekoImageGallery is an online AI image search engine that utilizes the Clip model and Qdrant vector database. It supports keyword search and similar image search. The tool generates 768-dimensional vectors for each image using the Clip model, supports OCR text search using PaddleOCR, and efficiently searches vectors using the Qdrant vector database. Users can deploy the tool locally or via Docker, with options for metadata storage using Qdrant database or local file storage. The tool provides API documentation through FastAPI's built-in Swagger UI and can be used for tasks like image search, text extraction, and vector search.
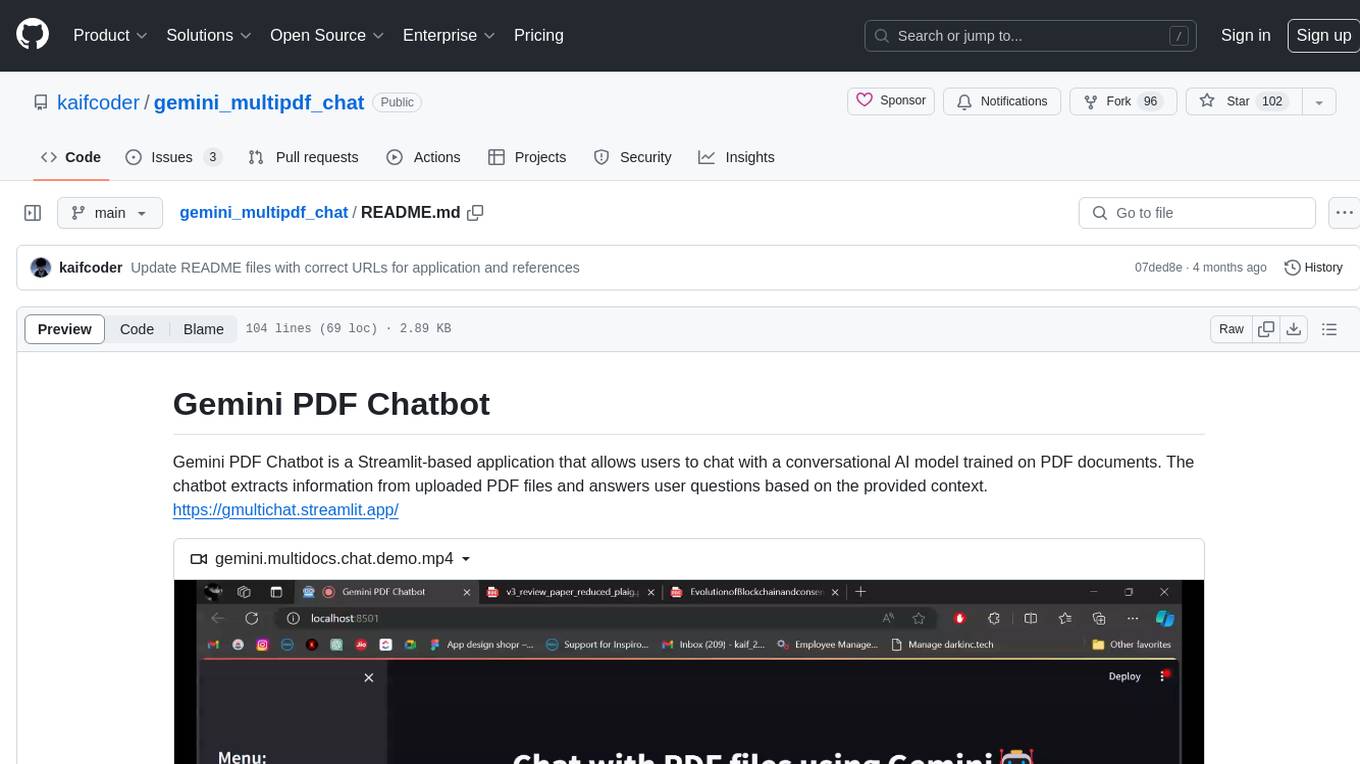
gemini_multipdf_chat
Gemini PDF Chatbot is a Streamlit-based application that allows users to chat with a conversational AI model trained on PDF documents. The chatbot extracts information from uploaded PDF files and answers user questions based on the provided context. It features PDF upload, text extraction, conversational AI using the Gemini model, and a chat interface. Users can deploy the application locally or to the cloud, and the project structure includes main application script, environment variable file, requirements, and documentation. Dependencies include PyPDF2, langchain, Streamlit, google.generativeai, and dotenv.
screen-pipe
Screen-pipe is a Rust + WASM tool that allows users to turn their screen into actions using Large Language Models (LLMs). It enables users to record their screen 24/7, extract text from frames, and process text and images for tasks like analyzing sales conversations. The tool is still experimental and aims to simplify the process of recording screens, extracting text, and integrating with various APIs for tasks such as filling CRM data based on screen activities. The project is open-source and welcomes contributions to enhance its functionalities and usability.
swift-ocr-llm-powered-pdf-to-markdown
Swift OCR is a powerful tool for extracting text from PDF files using OpenAI's GPT-4 Turbo with Vision model. It offers flexible input options, advanced OCR processing, performance optimizations, structured output, robust error handling, and scalable architecture. The tool ensures accurate text extraction, resilience against failures, and efficient handling of multiple requests.
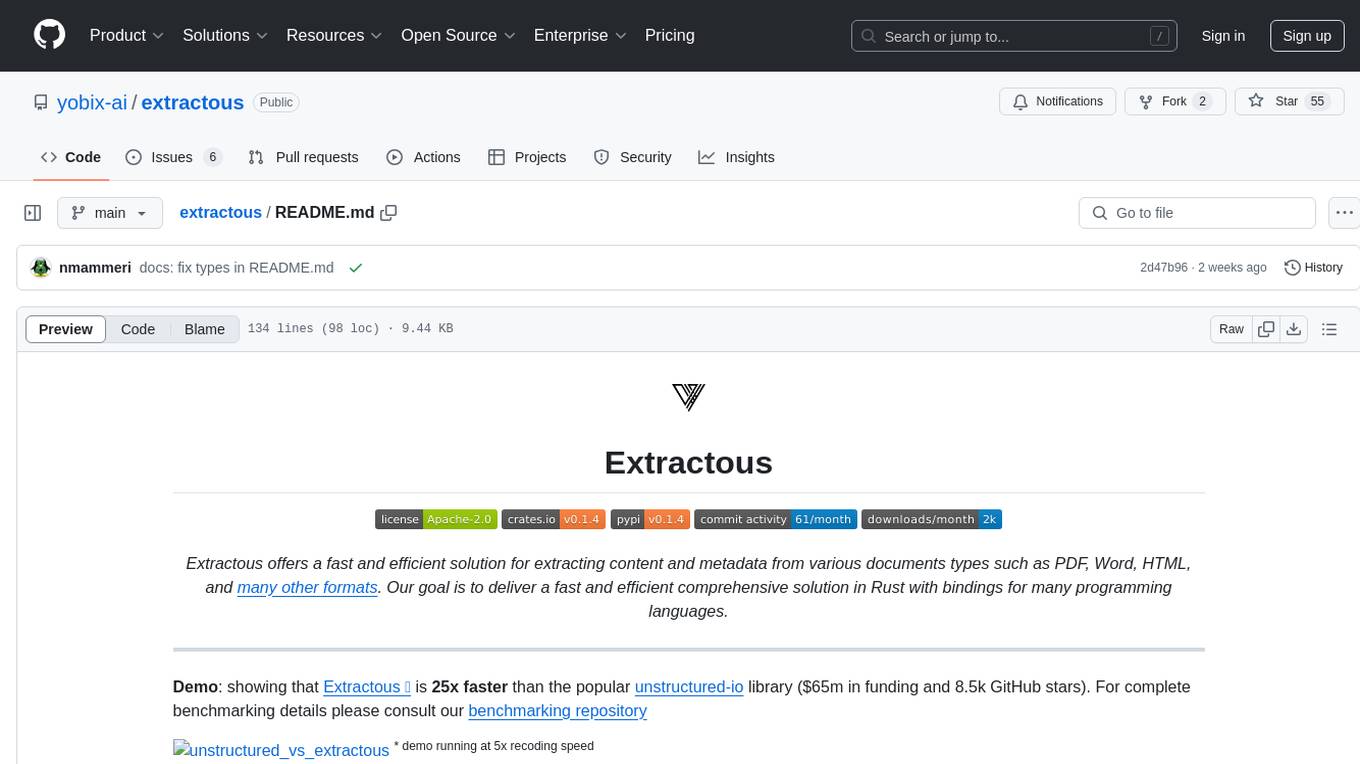
extractous
Extractous offers a fast and efficient solution for extracting content and metadata from various document types such as PDF, Word, HTML, and many other formats. It is built with Rust, providing high performance, memory safety, and multi-threading capabilities. The tool eliminates the need for external services or APIs, making data processing pipelines faster and more efficient. It supports multiple file formats, including Microsoft Office, OpenOffice, PDF, spreadsheets, web documents, e-books, text files, images, and email formats. Extractous provides a clear and simple API for extracting text and metadata content, with upcoming support for JavaScript/TypeScript. It is free for commercial use under the Apache 2.0 License.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.