
finite-monkey-engine
AI engine for smart contract audit
Stars: 305
FiniteMonkey is an advanced vulnerability mining engine powered purely by GPT, requiring no prior knowledge base or fine-tuning. Its effectiveness significantly surpasses most current related research approaches. The tool is task-driven, prompt-driven, and focuses on prompt design, leveraging 'deception' and hallucination as key mechanics. It has helped identify vulnerabilities worth over $60,000 in bounties. The tool requires PostgreSQL database, OpenAI API access, and Python environment for setup. It supports various languages like Solidity, Rust, Python, Move, Cairo, Tact, Func, Java, and Fake Solidity for scanning. FiniteMonkey is best suited for logic vulnerability mining in real projects, not recommended for academic vulnerability testing. GPT-4-turbo is recommended for optimal results with an average scan time of 2-3 hours for medium projects. The tool provides detailed scanning results guide and implementation tips for users.
README:
An AI-Powered Code Security Analysis Platform
Finite Monkey Engine v2.0 brings significant architectural upgrades and feature enhancements:
- 🎯 Precision Language Support: Focus on 4 core languages (Solidity/Rust/C++/Move) for optimal analysis experience
- 🧠 RAG Architecture Optimization: New LanceDB merged 2-table architecture with 300% query efficiency improvement
- 📊 Intelligent Context Understanding: Multi-dimensional embedding technology, significantly enhanced code comprehension
- ⚡ Performance Optimization: Unified storage strategy, 50% memory reduction, improved concurrent processing
- 🔍 Deep Business Analysis: Enhanced business flow visualization and cross-contract dependency analysis
Finite Monkey Engine is an advanced AI-driven code security analysis platform focused on blockchain and system-level code security auditing. By integrating multiple AI models and advanced static analysis techniques, it provides comprehensive, intelligent security auditing solutions for core programming language projects.
Built on Tree-sitter parsing engine and function-level analysis architecture, v2.0 focuses on 4 core languages for optimal analysis experience:
✅ Currently Fully Supported Languages:
- Solidity (.sol) - Ethereum smart contracts with complete Tree-sitter support
- Rust (.rs) - Solana ecosystem, Substrate, system-level programming
- C/C++ (.c/.cpp/.cxx/.cc/.C/.h/.hpp/.hxx) - Blockchain core, node clients
- Move (.move) - Aptos, Sui blockchain language
- Go (.go) - Blockchain infrastructure, TEE projects~~
🔄 Planned Support (Future Versions):
Cairo (.cairo) - StarkNet smart contract languageTact (.tact) - TON blockchain smart contractsFunC (.fc/.func) - TON blockchain native languageFA (.fr) - Functional smart contract languagePython (.py) - Web3, DeFi backend projectsJavaScript/TypeScript (.js/.ts) - Web3 frontend, Node.js projectsJava (.java) - Enterprise blockchain applications
💡 v2.0 Design Philosophy: Focus on core languages to provide deeply optimized analysis capabilities. Based on function-granularity code analysis architecture, theoretically extensible to any programming language. Future versions will gradually support more languages.
- Multi-Model Collaboration: Claude-4 Sonnet, GPT-4 and other AI models working intelligently together
- RAG-Enhanced Understanding: Multi-dimensional context-aware technology based on LanceDB
- Deep Business Logic Analysis: Deep understanding of DeFi protocols, governance mechanisms, and tokenomics
- Intelligent Vulnerability Discovery: AI-assisted complex vulnerability pattern recognition
- Precision Vulnerability Detection: Focus on core languages for more accurate vulnerability identification
- Cross-Contract Deep Analysis: Multi-contract interaction analysis and complex dependency tracking
- Business Scenario Review: Professional security analysis for different DeFi scenarios
- Intelligent False Positive Filtering: AI-assisted reduction of false positives, improving analysis accuracy
- Core Language Focus: Specialized framework for Solidity/Rust/C++/Move languages
- Modular Design: Planning, validation, context, and analysis modules
- Tree-sitter Parsing: Advanced parsing supporting core languages with high precision
finite-monkey-engine/
├── src/
│ ├── planning/ # Task planning and business flow analysis
│ ├── validating/ # Vulnerability detection and validation
│ ├── context/ # Context management and RAG processing
│ ├── reasoning/ # Analysis reasoning and dialogue management
│ ├── dao/ # Data access objects and entity management
│ ├── library/ # Parsing libraries and utilities
│ ├── openai_api/ # AI API integrations
│ └── prompt_factory/ # Prompt engineering and management
├── knowledges/ # Domain knowledge base
├── scripts/ # Utility scripts
└── docs/ # Documentation
- Python 3.10+
- PostgreSQL 13+ (required for storing analysis results)
- AI API Keys (supports OpenAI, Claude, DeepSeek, and other compatible services)
# 1. Clone the repository
git clone https://github.com/your-org/finite-monkey-engine.git
cd finite-monkey-engine
# 2. Install Python dependencies
pip install -r requirements.txt
# 3. Configure environment variables
cp env.example .env
# Edit .env file with your API keys and database configuration
# 4. Initialize database
psql -U postgres -d postgres -f project_task.sql
# 5. Configure project dataset
# Edit src/dataset/agent-v1-c4/datasets.json to add your project configuration
# 6. Run analysis
python src/main.pyInitialize PostgreSQL database using the provided SQL file:
# Connect to PostgreSQL database
psql -U postgres -d postgres
# Execute SQL file to create table structure
\i project_task.sql
# Or use command line directly
psql -U postgres -d postgres -f project_task.sqlConfigure your project in src/dataset/agent-v1-c4/datasets.json:
{
"your_project_id": {
"path": "your_project_folder_name",
"files": [], //no need to set, disable in future
"functions": [], //no need to set, disable in future
"exclude_in_planning": "false", //no need to set to true, disable in future
"exclude_directory": [] //no need to set, disable in future
}
}-
Set Project ID: Configure your project ID in
src/main.py
project_id = 'your_project_id'- Execute Analysis:
python src/main.py-
View Results:
- Detailed analysis records in database
-
output.xlsxreport file - Mermaid business flow diagrams (if enabled)
-
Copy environment template:
cp env.example .env
-
Edit
.envfile with your API keys and preferences
# Database Configuration (Required)
DATABASE_URL=postgresql://postgres:[email protected]:5432/postgres
# AI Model Configuration (Required)
OPENAI_API_BASE="api.openai-proxy.org" # LLM proxy platform
OPENAI_API_KEY="sk-xxxxxx" # API key
# Scan Mode Configuration
SCAN_MODE=COMMON_PROJECT_FINE_GRAINED # Recommended mode: Common project checklist fine-grained
# Available modes: PURE_SCAN (Pure scanning)
SCAN_MODE_AVA=False # Advanced scan mode features
COMPLEXITY_ANALYSIS_ENABLED=True # Enable complexity analysis
# Performance Tuning
MAX_THREADS_OF_SCAN=10 # Maximum threads for scanning phase
MAX_THREADS_OF_CONFIRMATION=50 # Maximum threads for confirmation phase
BUSINESS_FLOW_COUNT=4 # Business flow repeat count (hallucination triggers)
# Advanced Feature Configuration
ENABLE_DIALOGUE_MODE=False # Whether to enable dialogue mode
IGNORE_FOLDERS=node_modules,build,dist,test,tests,.git # Folders to ignore
# Checklist Configuration
CHECKLIST_PATH=src/knowledges/checklist.xlsx # Path to checklist file
CHECKLIST_SHEET=Sheet1 # Checklist worksheet name📝 Complete Configuration: See
env.examplefile for all configurable options and detailed descriptions
Based on actual configuration in src/openai_api/model_config.json:
WARNING must set the model name based on your llm hub! WARNING must set the model name based on your llm hub! WARNING like in openrouter, sonnet 4 need to set to anthropic/sonnet-4
{
"openai_general": "gpt-4.1",
"code_assumptions_analysis": "claude-sonnet-4-20250514",
"vulnerability_detection": "claude-sonnet-4-20250514",
"initial_vulnerability_validation": "deepseek-reasoner",
"vulnerability_findings_json_extraction": "gpt-4o-mini",
"additional_context_determination": "deepseek-reasoner",
"comprehensive_vulnerability_analysis": "deepseek-reasoner",
"final_vulnerability_extraction": "gpt-4o-mini",
"structured_json_extraction": "gpt-4.1",
"embedding_model": "text-embedding-3-large"
}SCAN_MODE=PURE_SCAN
COMPLEXITY_ANALYSIS_ENABLED=False
MAX_THREADS_OF_SCAN=3
BUSINESS_FLOW_COUNT=2SCAN_MODE=COMMON_PROJECT_FINE_GRAINED
COMPLEXITY_ANALYSIS_ENABLED=True
MAX_THREADS_OF_SCAN=8
MAX_THREADS_OF_CONFIRMATION=30
BUSINESS_FLOW_COUNT=4SCAN_MODE=PURE_SCAN
BUSINESS_FLOW_COUNT=1
MAX_THREADS_OF_SCAN=3
MAX_THREADS_OF_CONFIRMATION=10
COMPLEXITY_ANALYSIS_ENABLED=False- Smart Contract Security: Solidity, Rust, Move contract analysis
- DeFi Protocol Analysis: AMM, lending, governance mechanism review
- Cross-Chain Applications: Bridge security, multi-chain deployment analysis
- NFT & Gaming: Minting logic, marketplace integration security
- Web3 Backend: Python/Node.js API security analysis
- Blockchain Infrastructure: Go/C++ node and client security
- Enterprise Applications: Java enterprise blockchain applications
- System-Level Code: C/C++ core components and TEE projects
- Polyglot Codebases: Cross-language dependency analysis
- Microservice Architecture: Multi-service security assessment
- Full-Stack Applications: Frontend, backend, and contract integration security
The platform generates comprehensive analysis reports including:
- Security Vulnerability Report: Detailed vulnerability findings with severity ratings
- Business Flow Diagrams: Visual representation of contract interactions
- Gas Optimization Suggestions: Performance improvement recommendations
- Best Practice Compliance: Adherence to security standards and guidelines
Run the test suite:
# Unit tests
python -m pytest tests/
# Integration tests
python -m pytest tests/integration/
# Coverage report
python -m pytest --cov=src tests/We welcome contributions! Please see our Contributing Guidelines for details.
- Fork the repository
- Create a feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.
- ANTLR4: For Solidity parsing capabilities
- Claude AI: For advanced code understanding
- Mermaid: For business flow visualization
- OpenAI: For AI-powered analysis capabilities
- Email: [email protected]
- Twitter: @xy9301
- Telegram: https://t.me/+4-s4jDfy-ig1M2Y1
- Core Language Specialization: Focus on Solidity/Rust/C++/Move for optimal analysis experience
- RAG Architecture Revolution: LanceDB merged 2-table architecture with 300% performance improvement
- Intelligent Embedding: Multi-dimensional code understanding with significantly enhanced analysis precision
- Architecture Optimization: 50% memory reduction, supporting larger-scale projects
- v2.0 is fully backward compatible, no configuration changes required
- Unsupported language files will be automatically skipped without affecting system operation
- Recommended to update configuration files for optimal performance experience
🎉 Finite Monkey Engine v2.0 - Making Code Security Analysis More Intelligent, Professional, and Efficient!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for finite-monkey-engine
Similar Open Source Tools
finite-monkey-engine
FiniteMonkey is an advanced vulnerability mining engine powered purely by GPT, requiring no prior knowledge base or fine-tuning. Its effectiveness significantly surpasses most current related research approaches. The tool is task-driven, prompt-driven, and focuses on prompt design, leveraging 'deception' and hallucination as key mechanics. It has helped identify vulnerabilities worth over $60,000 in bounties. The tool requires PostgreSQL database, OpenAI API access, and Python environment for setup. It supports various languages like Solidity, Rust, Python, Move, Cairo, Tact, Func, Java, and Fake Solidity for scanning. FiniteMonkey is best suited for logic vulnerability mining in real projects, not recommended for academic vulnerability testing. GPT-4-turbo is recommended for optimal results with an average scan time of 2-3 hours for medium projects. The tool provides detailed scanning results guide and implementation tips for users.
claude-007-agents
Claude Code Agents is an open-source AI agent system designed to enhance development workflows by providing specialized AI agents for orchestration, resilience engineering, and organizational memory. These agents offer specialized expertise across technologies, AI system with organizational memory, and an agent orchestration system. The system includes features such as engineering excellence by design, advanced orchestration system, Task Master integration, live MCP integrations, professional-grade workflows, and organizational intelligence. It is suitable for solo developers, small teams, enterprise teams, and open-source projects. The system requires a one-time bootstrap setup for each project to analyze the tech stack, select optimal agents, create configuration files, set up Task Master integration, and validate system readiness.

llamafarm
LlamaFarm is a comprehensive AI framework that empowers users to build powerful AI applications locally, with full control over costs and deployment options. It provides modular components for RAG systems, vector databases, model management, prompt engineering, and fine-tuning. Users can create differentiated AI products without needing extensive ML expertise, using simple CLI commands and YAML configs. The framework supports local-first development, production-ready components, strategy-based configuration, and deployment anywhere from laptops to the cloud.
evi-run
evi-run is a powerful, production-ready multi-agent AI system built on Python using the OpenAI Agents SDK. It offers instant deployment, ultimate flexibility, built-in analytics, Telegram integration, and scalable architecture. The system features memory management, knowledge integration, task scheduling, multi-agent orchestration, custom agent creation, deep research, web intelligence, document processing, image generation, DEX analytics, and Solana token swap. It supports flexible usage modes like private, free, and pay mode, with upcoming features including NSFW mode, task scheduler, and automatic limit orders. The technology stack includes Python 3.11, OpenAI Agents SDK, Telegram Bot API, PostgreSQL, Redis, and Docker & Docker Compose for deployment.
persistent-ai-memory
Persistent AI Memory System is a comprehensive tool that offers persistent, searchable storage for AI assistants. It includes features like conversation tracking, MCP tool call logging, and intelligent scheduling. The system supports multiple databases, provides enhanced memory management, and offers various tools for memory operations, schedule management, and system health checks. It also integrates with various platforms like LM Studio, VS Code, Koboldcpp, Ollama, and more. The system is designed to be modular, platform-agnostic, and scalable, allowing users to handle large conversation histories efficiently.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.
lyraios
LYRAIOS (LLM-based Your Reliable AI Operating System) is an advanced AI assistant platform built with FastAPI and Streamlit, designed to serve as an operating system for AI applications. It offers core features such as AI process management, memory system, and I/O system. The platform includes built-in tools like Calculator, Web Search, Financial Analysis, File Management, and Research Tools. It also provides specialized assistant teams for Python and research tasks. LYRAIOS is built on a technical architecture comprising FastAPI backend, Streamlit frontend, Vector Database, PostgreSQL storage, and Docker support. It offers features like knowledge management, process control, and security & access control. The roadmap includes enhancements in core platform, AI process management, memory system, tools & integrations, security & access control, open protocol architecture, multi-agent collaboration, and cross-platform support.

MassGen
MassGen is a cutting-edge multi-agent system that leverages the power of collaborative AI to solve complex tasks. It assigns a task to multiple AI agents who work in parallel, observe each other's progress, and refine their approaches to converge on the best solution to deliver a comprehensive and high-quality result. The system operates through an architecture designed for seamless multi-agent collaboration, with key features including cross-model/agent synergy, parallel processing, intelligence sharing, consensus building, and live visualization. Users can install the system, configure API settings, and run MassGen for various tasks such as question answering, creative writing, research, development & coding tasks, and web automation & browser tasks. The roadmap includes plans for advanced agent collaboration, expanded model, tool & agent integration, improved performance & scalability, enhanced developer experience, and a web interface.
leetcode-py
A Python package to generate professional LeetCode practice environments. Features automated problem generation from LeetCode URLs, beautiful data structure visualizations (TreeNode, ListNode, GraphNode), and comprehensive testing with 10+ test cases per problem. Built with professional development practices including CI/CD, type hints, and quality gates. The tool provides a modern Python development environment with production-grade features such as linting, test coverage, logging, and CI/CD pipeline. It also offers enhanced data structure visualization for debugging complex structures, flexible notebook support, and a powerful CLI for generating problems anywhere.
paelladoc
PAELLADOC is an intelligent documentation system that uses AI to analyze code repositories and generate comprehensive technical documentation. It offers a modular architecture with MECE principles, interactive documentation process, key features like Orchestrator and Commands, and a focus on context for successful AI programming. The tool aims to streamline documentation creation, code generation, and product management tasks for software development teams, providing a definitive standard for AI-assisted development documentation.
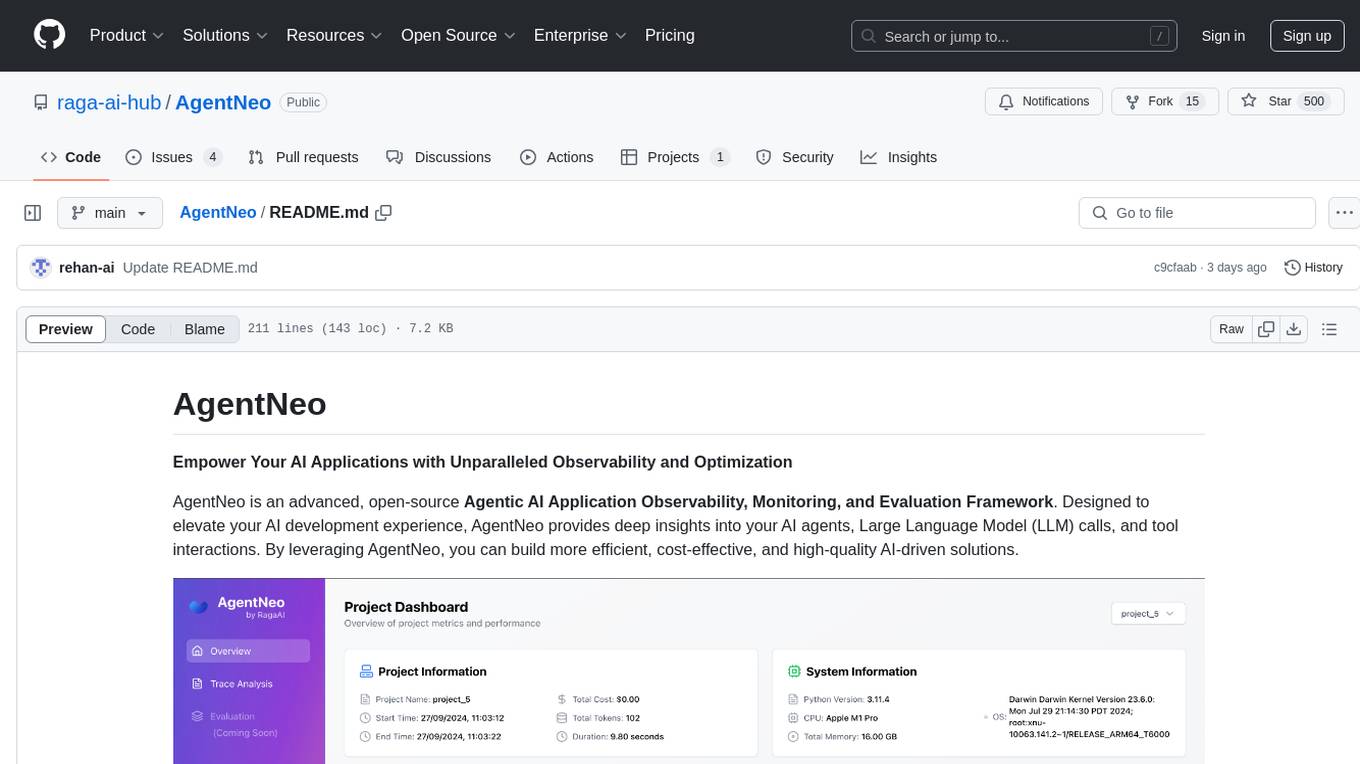
AgentNeo
AgentNeo is an advanced, open-source Agentic AI Application Observability, Monitoring, and Evaluation Framework designed to provide deep insights into AI agents, Large Language Model (LLM) calls, and tool interactions. It offers robust logging, visualization, and evaluation capabilities to help debug and optimize AI applications with ease. With features like tracing LLM calls, monitoring agents and tools, tracking interactions, detailed metrics collection, flexible data storage, simple instrumentation, interactive dashboard, project management, execution graph visualization, and evaluation tools, AgentNeo empowers users to build efficient, cost-effective, and high-quality AI-driven solutions.
aegra
Aegra is a self-hosted AI agent backend platform that provides LangGraph power without vendor lock-in. Built with FastAPI + PostgreSQL, it offers complete control over agent orchestration for teams looking to escape vendor lock-in, meet data sovereignty requirements, enable custom deployments, and optimize costs. Aegra is Agent Protocol compliant and perfect for teams seeking a free, self-hosted alternative to LangGraph Platform with zero lock-in, full control, and compatibility with existing LangGraph Client SDK.
AgriTech
AgriTech is an AI-powered smart agriculture platform designed to assist farmers with crop recommendations, yield prediction, plant disease detection, and community-driven collaboration—enabling sustainable and data-driven farming practices. It offers AI-driven decision support for modern agriculture, early-stage plant disease detection, crop yield forecasting using machine learning models, and a collaborative ecosystem for farmers and stakeholders. The platform includes features like crop recommendation, yield prediction, disease detection, an AI chatbot for platform guidance and agriculture support, a farmer community, and shopkeeper listings. AgriTech's AI chatbot provides comprehensive support for farmers with features like platform guidance, agriculture support, decision making, image analysis, and 24/7 support. The tech stack includes frontend technologies like HTML5, CSS3, JavaScript, backend technologies like Python (Flask) and optional Node.js, machine learning libraries like TensorFlow, Scikit-learn, OpenCV, and database & DevOps tools like MySQL, MongoDB, Firebase, Docker, and GitHub Actions.
opcode
opcode is a powerful desktop application built with Tauri 2 that serves as a command center for interacting with Claude Code. It offers a visual GUI for managing Claude Code sessions, creating custom agents, tracking usage, and more. Users can navigate projects, create specialized AI agents, monitor usage analytics, manage MCP servers, create session checkpoints, edit CLAUDE.md files, and more. The tool bridges the gap between command-line tools and visual experiences, making AI-assisted development more intuitive and productive.
llxprt-code
LLxprt Code is an AI-powered coding assistant that works with any LLM provider, offering a command-line interface for querying and editing codebases, generating applications, and automating development workflows. It supports various subscriptions, provider flexibility, top open models, local model support, and a privacy-first approach. Users can interact with LLxprt Code in both interactive and non-interactive modes, leveraging features like subscription OAuth, multi-account failover, load balancer profiles, and extensive provider support. The tool also allows for the creation of advanced subagents for specialized tasks and integrates with the Zed editor for in-editor chat and code selection.
For similar tasks
finite-monkey-engine
FiniteMonkey is an advanced vulnerability mining engine powered purely by GPT, requiring no prior knowledge base or fine-tuning. Its effectiveness significantly surpasses most current related research approaches. The tool is task-driven, prompt-driven, and focuses on prompt design, leveraging 'deception' and hallucination as key mechanics. It has helped identify vulnerabilities worth over $60,000 in bounties. The tool requires PostgreSQL database, OpenAI API access, and Python environment for setup. It supports various languages like Solidity, Rust, Python, Move, Cairo, Tact, Func, Java, and Fake Solidity for scanning. FiniteMonkey is best suited for logic vulnerability mining in real projects, not recommended for academic vulnerability testing. GPT-4-turbo is recommended for optimal results with an average scan time of 2-3 hours for medium projects. The tool provides detailed scanning results guide and implementation tips for users.

garak
Garak is a free tool that checks if a Large Language Model (LLM) can be made to fail in a way that is undesirable. It probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. Garak's a free tool. We love developing it and are always interested in adding functionality to support applications.

moonshot
Moonshot is a simple and modular tool developed by the AI Verify Foundation to evaluate Language Model Models (LLMs) and LLM applications. It brings Benchmarking and Red-Teaming together to assist AI developers, compliance teams, and AI system owners in assessing LLM performance. Moonshot can be accessed through various interfaces including User-friendly Web UI, Interactive Command Line Interface, and seamless integration into MLOps workflows via Library APIs or Web APIs. It offers features like benchmarking LLMs from popular model providers, running relevant tests, creating custom cookbooks and recipes, and automating Red Teaming to identify vulnerabilities in AI systems.
SinkFinder
SinkFinder + LLM is a closed-source semi-automatic vulnerability discovery tool that performs static code analysis on jar/war/zip files. It enhances the capability of LLM large models to verify path reachability and assess the trustworthiness score of the path based on the contextual code environment. Users can customize class and jar exclusions, depth of recursive search, and other parameters through command-line arguments. The tool generates rule.json configuration file after each run and requires configuration of the DASHSCOPE_API_KEY for LLM capabilities. The tool provides detailed logs on high-risk paths, LLM results, and other findings. Rules.json file contains sink rules for various vulnerability types with severity levels and corresponding sink methods.
SinkFinder
SinkFinder is a tool designed to analyze jar and zip files for security vulnerabilities. It allows users to define rules for white and blacklisting specific classes and methods that may pose a risk. The tool provides a list of common security sink names along with severity levels and associated vulnerable methods. Users can use SinkFinder to quickly identify potential security issues in their Java applications by scanning for known sink patterns and configurations.

agentic-radar
The Agentic Radar is a security scanner designed to analyze and assess agentic systems for security and operational insights. It helps users understand how agentic systems function, identify potential vulnerabilities, and create security reports. The tool includes workflow visualization, tool identification, and vulnerability mapping, providing a comprehensive HTML report for easy reviewing and sharing. It simplifies the process of assessing complex workflows and multiple tools used in agentic systems, offering a structured view of potential risks and security frameworks.

aderyn
Aderyn is a powerful Solidity static analyzer designed to help protocol engineers and security researchers find vulnerabilities in Solidity code bases. It provides off-the-shelf support for Foundry and Hardhat projects, allows for custom frameworks through a configuration file, and generates reports in Markdown, JSON, and Sarif formats. Users can install Aderyn using Cyfrinup, curl, Homebrew, or npm, and quickly identify vulnerabilities in their Solidity code. The tool also offers a VS Code extension for seamless integration with the IDE.
pentest-agent
Pentest Agent is a lightweight and versatile tool designed for conducting penetration testing on network systems. It provides a user-friendly interface for scanning, identifying vulnerabilities, and generating detailed reports. The tool is highly customizable, allowing users to define specific targets and parameters for testing. Pentest Agent is suitable for security professionals and ethical hackers looking to assess the security posture of their systems and networks.
For similar jobs
hackingBuddyGPT
hackingBuddyGPT is a framework for testing LLM-based agents for security testing. It aims to create common ground truth by creating common security testbeds and benchmarks, evaluating multiple LLMs and techniques against those, and publishing prototypes and findings as open-source/open-access reports. The initial focus is on evaluating the efficiency of LLMs for Linux privilege escalation attacks, but the framework is being expanded to evaluate the use of LLMs for web penetration-testing and web API testing. hackingBuddyGPT is released as open-source to level the playing field for blue teams against APTs that have access to more sophisticated resources.
aircrackauto
AirCrackAuto is a tool that automates the aircrack-ng process for Wi-Fi hacking. It is designed to make it easier for users to crack Wi-Fi passwords by automating the process of capturing packets, generating wordlists, and launching attacks. AirCrackAuto is a powerful tool that can be used to crack Wi-Fi passwords in a matter of minutes.

AIMr
AIMr is an AI aimbot tool written in Python that leverages modern technologies to achieve an undetected system with a pleasing appearance. It works on any game that uses human-shaped models. To optimize its performance, users should build OpenCV with CUDA. For Valorant, additional perks in the Discord and an Arduino Leonardo R3 are required.
aircrack-ng
Aircrack-ng is a comprehensive suite of tools designed to evaluate the security of WiFi networks. It covers various aspects of WiFi security, including monitoring, attacking (replay attacks, deauthentication, fake access points), testing WiFi cards and driver capabilities, and cracking WEP and WPA PSK. The tools are command line-based, allowing for extensive scripting and have been utilized by many GUIs. Aircrack-ng primarily works on Linux but also supports Windows, macOS, FreeBSD, OpenBSD, NetBSD, Solaris, and eComStation 2.
Awesome_GPT_Super_Prompting
Awesome_GPT_Super_Prompting is a repository that provides resources related to Jailbreaks, Leaks, Injections, Libraries, Attack, Defense, and Prompt Engineering. It includes information on ChatGPT Jailbreaks, GPT Assistants Prompt Leaks, GPTs Prompt Injection, LLM Prompt Security, Super Prompts, Prompt Hack, Prompt Security, Ai Prompt Engineering, and Adversarial Machine Learning. The repository contains curated lists of repositories, tools, and resources related to GPTs, prompt engineering, prompt libraries, and secure prompting. It also offers insights into Cyber-Albsecop GPT Agents and Super Prompts for custom GPT usage.
ai-exploits
AI Exploits is a repository that showcases practical attacks against AI/Machine Learning infrastructure, aiming to raise awareness about vulnerabilities in the AI/ML ecosystem. It contains exploits and scanning templates for responsibly disclosed vulnerabilities affecting machine learning tools, including Metasploit modules, Nuclei templates, and CSRF templates. Users can use the provided Docker image to easily run the modules and templates. The repository also provides guidelines for using Metasploit modules, Nuclei templates, and CSRF templates to exploit vulnerabilities in machine learning tools.
airgeddon
Airgeddon is a versatile bash script designed for Linux systems to conduct wireless network audits. It provides a comprehensive set of features and tools for auditing and securing wireless networks. The script is user-friendly and offers functionalities such as scanning, capturing handshakes, deauth attacks, and more. Airgeddon is regularly updated and supported, making it a valuable tool for both security professionals and enthusiasts.
PentestGPT
PentestGPT is a penetration testing tool empowered by ChatGPT, designed to automate the penetration testing process. It operates interactively to guide penetration testers in overall progress and specific operations. The tool supports solving easy to medium HackTheBox machines and other CTF challenges. Users can use PentestGPT to perform tasks like testing connections, using different reasoning models, discussing with the tool, searching on Google, and generating reports. It also supports local LLMs with custom parsers for advanced users.