
llms-interview-questions
🟣 LLMs interview questions and answers to help you prepare for your next machine learning and data science interview in 2024.
Stars: 56
This repository contains a comprehensive collection of 63 must-know Large Language Models (LLMs) interview questions. It covers topics such as the architecture of LLMs, transformer models, attention mechanisms, training processes, encoder-decoder frameworks, differences between LLMs and traditional statistical language models, handling context and long-term dependencies, transformers for parallelization, applications of LLMs, sentiment analysis, language translation, conversation AI, chatbots, and more. The readme provides detailed explanations, code examples, and insights into utilizing LLMs for various tasks.
README:

You can also find all 63 answers here 👉 Devinterview.io - LLMs
Large Language Models (LLMs) are advanced artificial intelligence systems designed to understand, process, and generate human-like text. Examples include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), Claude, and Llama.
These models have revolutionized natural language processing tasks such as translation, summarization, and question-answering.
LLMs are built on the Transformer architecture, which uses a network of transformer blocks with multi-headed self-attention mechanisms. This allows the model to understand the context of words within a broader text.
class TransformerBlock(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.attention = nn.MultiheadAttention(embed_dim, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(embed_dim, 4 * embed_dim),
nn.ReLU(),
nn.Linear(4 * embed_dim, embed_dim)
)
self.layer_norm1 = nn.LayerNorm(embed_dim)
self.layer_norm2 = nn.LayerNorm(embed_dim)
def forward(self, x):
attn_output, _ = self.attention(x, x, x)
x = self.layer_norm1(x + attn_output)
ff_output = self.feed_forward(x)
return self.layer_norm2(x + ff_output)LLMs process text by breaking it into tokens and converting them into embeddings - high-dimensional numerical representations that capture semantic meaning.
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
text = "Hello, how are you?"
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
embeddings = outputs.last_hidden_stateThis mechanism allows the model to focus on different parts of the input when processing each token, enabling it to capture complex relationships within the text.
-
Unsupervised Pretraining: The model learns language patterns from vast amounts of unlabeled text data.
-
Fine-Tuning: The pretrained model is further trained on specific tasks or domains to improve performance.
-
Prompt-Based Learning: The model learns to generate responses based on specific prompts or instructions.
-
Continual Learning: Ongoing training to keep the model updated with new information and language trends.
Different LLMs use various configurations of the encoder-decoder framework:
- GPT models use a decoder-only architecture for unidirectional processing.
- BERT uses an encoder-only architecture for bidirectional understanding.
- T5 (Text-to-Text Transfer Transformer) uses both encoder and decoder for versatile text processing tasks.
The Transformer model architecture has revolutionized Natural Language Processing (NLP) due to its ability to capture long-range dependencies and outperform previous methods. Its foundation is built on attention mechanisms.
-
Encoder-Decoder Structure: The original Transformer featured separate encoders for processing input sequences and decoders for generating outputs. However, variants like GPT (Generative Pre-trained Transformer) use only the encoder for tasks such as language modeling.
-
Self-Attention Mechanism: This allows the model to weigh different parts of the input sequence when processing each element, forming the core of both encoder and decoder.
The encoder consists of multiple identical layers, each containing:
- Multi-Head Self-Attention Module
- Feed-Forward Neural Network
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x):
x = x + self.self_attn(self.norm1(x))
x = x + self.feed_forward(self.norm2(x))
return xThe decoder also consists of multiple identical layers, each containing:
- Masked Multi-Head Self-Attention Module
- Multi-Head Encoder-Decoder Attention Module
- Feed-Forward Neural Network
To incorporate sequence order information, positional encodings are added to the input embeddings:
def positional_encoding(max_seq_len, d_model):
pos = np.arange(max_seq_len)[:, np.newaxis]
i = np.arange(d_model)[np.newaxis, :]
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
angle_rads = pos * angle_rates
sines = np.sin(angle_rads[:, 0::2])
cosines = np.cos(angle_rads[:, 1::2])
pos_encoding = np.concatenate([sines, cosines], axis=-1)
return torch.FloatTensor(pos_encoding)The multi-head attention mechanism allows the model to jointly attend to information from different representation subspaces:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % num_heads == 0
self.depth = d_model // num_heads
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.dense = nn.Linear(d_model, d_model)
def split_heads(self, x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.depth)
return x.permute(0, 2, 1, 3)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
q = self.split_heads(self.wq(q), batch_size)
k = self.split_heads(self.wk(k), batch_size)
v = self.split_heads(self.wv(v), batch_size)
scaled_attention = scaled_dot_product_attention(q, k, v, mask)
concat_attention = scaled_attention.permute(0, 2, 1, 3).contiguous()
concat_attention = concat_attention.view(batch_size, -1, self.d_model)
return self.dense(concat_attention)Each encoder and decoder layer includes a fully connected feed-forward network:
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(F.relu(self.linear1(x)))- Encoder-Decoder Models: Use teacher forcing during training.
- GPT-style Models: Employ self-learning schedules with the encoder only.
- Scalability: Transformer models can be scaled up to handle word-level or subword-level tokens.
- Adaptability: The architecture can accommodate diverse input modalities, including text, images, and audio.
- LLMs: Based on transformer architectures with self-attention mechanisms. They can process and understand long-range dependencies in text across vast contexts.
- Traditional models: Often use simpler architectures like N-grams or Hidden Markov Models. They rely on fixed-length contexts and struggle with long-range dependencies.
- LLMs: Typically have billions of parameters and are trained on massive datasets, allowing them to capture complex language patterns and generalize to various tasks.
- Traditional models: Usually have fewer parameters and are trained on smaller, task-specific datasets, limiting their generalization capabilities.
- LLMs: Often use unsupervised pre-training on large corpora, followed by fine-tuning for specific tasks. They employ techniques like masked language modeling and next sentence prediction.
- Traditional models: Typically trained in a supervised manner on specific tasks, requiring labeled data for each application.
- LLMs: Can handle variable-length inputs and process text as sequences of tokens, often using subword tokenization methods like Byte-Pair Encoding (BPE) or SentencePiece.
- Traditional models: Often require fixed-length inputs or use simpler tokenization methods like word-level or character-level splitting.
- LLMs: Generate contextual embeddings for words, capturing their meaning based on surrounding context. This allows for better handling of polysemy and homonymy.
- Traditional models: Often use static word embeddings or simpler representations, which may not capture context-dependent meanings effectively.
- LLMs: Can be applied to a wide range of natural language processing tasks with minimal task-specific fine-tuning, exhibiting strong few-shot and zero-shot learning capabilities.
- Traditional models: Usually designed and trained for specific tasks, requiring separate models for different applications.
- LLMs: Require significant computational resources for training and inference, often necessitating specialized hardware like GPUs or TPUs.
- Traditional models: Generally have lower computational demands, making them more suitable for resource-constrained environments.
The Attention Mechanism is a crucial innovation in transformer models, allowing them to process entire sequences simultaneously. Unlike sequential models like RNNs or LSTMs, transformers can parallelize operations, making them efficient for long sequences.
- For each word or position, the transformer generates three vectors: Query, Key, and Value.
- These vectors are used in a weighted sum to focus on specific parts of the input sequence.
- Calculated using the Dot-Product Method: multiplying Query and Key vectors, then normalizing through a softmax function.
- The Scaled Dot-Product Method adjusts key vectors for better numerical stability:
$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$
where $d_k$ is the dimension of the key vectors.
- Allows the model to learn multiple representation subspaces:
- Divides vector spaces into independent subspaces.
- Conducts attention separately over these subspaces.
- Each head provides a weighted sum of word representations, which are then combined.
- Enables the model to focus on different aspects of the input sequence simultaneously.
- Adds positional information to the input, as attention mechanisms don't inherently consider sequence order.
- Usually implemented as sinusoidal functions or learned embeddings:
$$ PE_{(pos,2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right) $$
$$ PE_{(pos,2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right) $$
- Encoder-Decoder Architecture: Consists of an encoder that processes the input sequence and a decoder that generates the output sequence.
- Stacked Layers: Multiple layers of attention and feed-forward networks, allowing for incremental refinement of representations.
import tensorflow as tf
# Input sequence: 10 words, each represented by a 3-dimensional vector
sequence_length, dimension, batch_size = 10, 3, 2
input_sequence = tf.random.normal((batch_size, sequence_length, dimension))
# Multi-head attention layer with 2 attention heads
num_attention_heads = 2
multi_head_layer = tf.keras.layers.MultiHeadAttention(num_heads=num_attention_heads, key_dim=dimension)
# Self-attention: query, key, and value are all derived from the input sequence
output_sequence = multi_head_layer(query=input_sequence, value=input_sequence, key=input_sequence)
print(output_sequence.shape) # Output: (2, 10, 3)Positional encodings are a crucial component in Large Language Models (LLMs) that address the inherent limitation of transformer architectures in capturing sequence information.
Transformer-based models process all tokens simultaneously through self-attention mechanisms, making them position-agnostic. Positional encodings inject position information into the model, enabling it to understand the order of words in a sequence.
-
Additive Approach: Positional encodings are added to the input word embeddings, combining static word representations with positional information.
-
Sinusoidal Function: Many LLMs, including the GPT series, use trigonometric functions to generate positional encodings.
The positional encoding (PE) for a given position pos and dimension i is calculated as:
$$ PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) $$ $$ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) $$
Where:
-
posis the position in the sequence -
iis the dimension index (0 ≤ i < d_model/2) -
d_modelis the dimensionality of the model
- The use of sine and cosine functions allows the model to learn relative positions.
- Different frequency components capture relationships at various scales.
- The constant
10000prevents function saturation.
Here's a Python implementation of positional encoding:
import numpy as np
def positional_encoding(seq_length, d_model):
position = np.arange(seq_length)[:, np.newaxis]
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe = np.zeros((seq_length, d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
# Example usage
seq_length, d_model = 100, 512
positional_encodings = positional_encoding(seq_length, d_model)Pre-training and fine-tuning are important concepts in the development and application of Large Language Models (LLMs). These processes enable LLMs to achieve impressive performance across various Natural Language Processing (NLP) tasks.
Pre-training is the initial phase of LLM development, characterized by:
-
Massive Data Ingestion: LLMs are exposed to enormous amounts of text data, typically hundreds of gigabytes or even terabytes.
-
Self-supervised Learning: Models learn from unlabeled data using techniques like:
- Masked Language Modeling (MLM)
- Next Sentence Prediction (NSP)
- Causal Language Modeling (CLM)
-
General Language Understanding: Pre-training results in models with broad knowledge of language patterns, semantics, and world knowledge.
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load pre-trained GPT-2 model and tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# Generate text
prompt = "The future of artificial intelligence is"
input_ids = tokenizer.encode(prompt, return_tensors='pt')
output = model.generate(input_ids, max_length=50, num_return_sequences=1)
print(tokenizer.decode(output[0], skip_special_tokens=True))Fine-tuning adapts pre-trained models to specific tasks or domains:
-
Task-specific Adaptation: Adjusts the model for particular NLP tasks such as:
- Text Classification
- Named Entity Recognition (NER)
- Question Answering
- Summarization
-
Transfer Learning: Leverages general knowledge from pre-training to perform well on specific tasks, often with limited labeled data.
-
Efficiency: Requires significantly less time and computational resources compared to training from scratch.
from transformers import BertForSequenceClassification, BertTokenizer, AdamW
from torch.utils.data import DataLoader
# Load pre-trained BERT model and tokenizer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Prepare dataset and dataloader (assuming 'texts' and 'labels' are defined)
dataset = [(tokenizer(text, padding='max_length', truncation=True, max_length=128), label) for text, label in zip(texts, labels)]
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
# Fine-tuning loop
optimizer = AdamW(model.parameters(), lr=2e-5)
for epoch in range(3):
for batch in dataloader:
inputs = {k: v.to(model.device) for k, v in batch[0].items()}
labels = batch[1].to(model.device)
outputs = model(**inputs, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Save fine-tuned model
model.save_pretrained('./fine_tuned_bert_classifier')-
Few-shot Learning: Fine-tuning with a small number of examples, leveraging the model's pre-trained knowledge.
-
Prompt Engineering: Crafting effective prompts to guide the model's behavior without extensive fine-tuning.
-
Continual Learning: Updating models with new knowledge while retaining previously learned information.
The cornerstone of modern LLMs is the attention mechanism, which allows the model to focus on different parts of the input when processing each word. This approach significantly improves the handling of context and long-range dependencies.
Self-attention, a key component of the Transformer architecture, enables each word in a sequence to attend to all other words, capturing complex relationships:
def self_attention(query, key, value):
scores = torch.matmul(query, key.transpose(-2, -1))
attention_weights = torch.softmax(scores, dim=-1)
return torch.matmul(attention_weights, value)To incorporate sequence order information, LLMs use positional encoding. This technique adds position-dependent signals to word embeddings:
def positional_encoding(seq_len, d_model):
position = torch.arange(seq_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
pos_encoding = torch.zeros(seq_len, d_model)
pos_encoding[:, 0::2] = torch.sin(position * div_term)
pos_encoding[:, 1::2] = torch.cos(position * div_term)
return pos_encodingMulti-head attention allows the model to focus on different aspects of the input simultaneously, enhancing its ability to capture diverse contextual information:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.attention = nn.MultiheadAttention(d_model, num_heads)
def forward(self, query, key, value):
return self.attention(query, key, value)The Transformer architecture, which forms the basis of many modern LLMs, effectively processes sequences in parallel, capturing both local and global dependencies:
- Encoder: Processes the input sequence, capturing contextual information.
- Decoder: Generates output based on the encoded information and previously generated tokens.
BERT uses a bidirectional approach, considering both preceding and succeeding context:
class BERT(nn.Module):
def __init__(self, vocab_size, hidden_size, num_layers):
super().__init__()
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(hidden_size, nhead=8),
num_layers=num_layers
)
def forward(self, x):
x = self.embedding(x)
return self.transformer(x)GPT models use a unidirectional approach, predicting the next token based on previous tokens:
class GPT(nn.Module):
def __init__(self, vocab_size, hidden_size, num_layers):
super().__init__()
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.transformer = nn.TransformerDecoder(
nn.TransformerDecoderLayer(hidden_size, nhead=8),
num_layers=num_layers
)
def forward(self, x):
x = self.embedding(x)
return self.transformer(x, x)To handle extremely long sequences, some models employ techniques like:
- Sparse Attention: Focusing on a subset of tokens to reduce computational complexity.
- Sliding Window Attention: Attending to a fixed-size window of surrounding tokens.
- Hierarchical Attention: Processing text at multiple levels of granularity.
Transformers play a crucial role in achieving parallelization for both inference and training in Large Language Models (LLMs). Their architecture enables efficient parallel processing of input sequences, significantly improving computational speed.
The Transformer architecture consists of three main components:
- Input Embeddings
- Self-Attention Mechanism
- Feed-Forward Neural Networks
The self-attention mechanism is particularly important for parallelization, as it allows each token in a sequence to attend to all other tokens simultaneously.
The self-attention process involves two main steps:
- QKV (Query, Key, Value) Computation
- Weighted Sum Calculation
Without parallelization, these steps can become computational bottlenecks. However, Transformers enable efficient parallel processing through matrix operations.
import torch
def parallel_self_attention(Q, K, V):
# Compute attention scores
attention_scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(K.size(-1)))
# Apply softmax
attention_weights = torch.softmax(attention_scores, dim=-1)
# Compute output
output = torch.matmul(attention_weights, V)
return output
# Assume batch_size=32, num_heads=8, seq_length=512, d_k=64
Q = torch.randn(32, 8, 512, 64)
K = torch.randn(32, 8, 512, 64)
V = torch.randn(32, 8, 512, 64)
parallel_output = parallel_self_attention(Q, K, V)This example demonstrates how self-attention can be computed in parallel across multiple dimensions (batch, heads, and sequence length) using matrix operations.
To further speed up computations, LLMs leverage:
- Matrix Operations: Expressing multiple operations in matrix notation for concurrent execution.
- Optimized Libraries: Utilizing high-performance libraries like cuBLAS, cuDNN, and TensorRT for maximum parallelism on GPUs.
While parallelism offers significant speed improvements, it also introduces challenges related to learning dependencies and resource allocation. To address these issues, LLMs employ several techniques:
- Bucketing: Grouping inputs of similar sizes for efficient parallel processing.
- Attention Masking: Controlling which tokens attend to each other, enabling selective parallelism.
- Layer Normalization: Bridging computational steps to mitigate the impact of parallelism on learned representations.
import torch
def masked_self_attention(Q, K, V, mask):
attention_scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(K.size(-1)))
# Apply mask
attention_scores = attention_scores.masked_fill(mask == 0, float('-inf'))
attention_weights = torch.softmax(attention_scores, dim=-1)
output = torch.matmul(attention_weights, V)
return output
# Create a simple causal mask for a sequence of length 4
mask = torch.tril(torch.ones(4, 4))
Q = torch.randn(1, 1, 4, 64)
K = torch.randn(1, 1, 4, 64)
V = torch.randn(1, 1, 4, 64)
masked_output = masked_self_attention(Q, K, V, mask)Large Language Models (LLMs) have revolutionized various industries with their versatile capabilities. Here are some of the most notable applications:
-
Natural Language Processing (NLP) Tasks
- Text Generation: LLMs excel at producing human-like text, powering applications like:
- Sentiment Analysis: Determining the emotional tone of text.
- Named Entity Recognition (NER): Identifying and classifying entities in text.
-
Content Creation and Manipulation
- Text Summarization: Condensing long documents into concise summaries.
- Content Expansion: Elaborating on brief ideas or outlines.
- Style Transfer: Rewriting text in different styles or tones.
-
Language Translation
- Translating text between multiple languages with high accuracy.
- Supporting real-time translation in communication apps.
-
Conversational AI
- Chatbots: Powering customer service bots and virtual assistants.
- Question-Answering Systems: Providing accurate responses to user queries.
-
Code Generation and Analysis
- Generating code snippets based on natural language descriptions.
- Assisting in code review and bug detection.
-
Educational Tools
- Personalized Learning: Adapting content to individual student needs.
- Automated Grading: Assessing written responses and providing feedback.
-
Healthcare Applications
- Medical Record Analysis: Extracting insights from patient records.
- Drug Discovery: Assisting in the identification of potential drug candidates.
-
Financial Services
- Market Analysis: Generating reports and insights from financial data.
- Fraud Detection: Identifying unusual patterns in transactions.
-
Creative Writing Assistance
- Story Generation: Creating plot outlines or entire narratives.
- Poetry Composition: Generating verses in various styles.
-
Research and Data Analysis
- Literature Review: Summarizing and synthesizing academic papers.
- Trend Analysis: Identifying patterns in large datasets.
-
Accessibility Tools
- Text-to-Speech: Converting written text to natural-sounding speech.
- Speech Recognition: Transcribing spoken words to text.
-
Legal and Compliance
- Contract Analysis: Reviewing and summarizing legal documents.
- Regulatory Compliance: Ensuring adherence to legal standards.
10. How is GPT-4 different from its predecessors like GPT-3 in terms of capabilities and applications?
-
GPT-3: Released in 2020, it had 175 billion parameters, setting a new standard for large language models.
-
GPT-4: While the exact parameter count is undisclosed, it's believed to be significantly larger than GPT-3, potentially in the trillions. It also utilizes a more advanced neural network architecture.
-
GPT-3: Trained primarily on text data using unsupervised learning.
-
GPT-4: Incorporates multimodal training, including text and images, allowing it to understand and generate content based on visual inputs.
-
GPT-3: Demonstrated impressive natural language understanding and generation capabilities.
-
GPT-4: Shows substantial improvements in:
- Reasoning: Better at complex problem-solving and logical deduction.
- Consistency: Maintains coherence over longer conversations and tasks.
- Factual Accuracy: Reduced hallucinations and improved factual reliability.
- Multilingual Proficiency: Enhanced performance across various languages.
-
GPT-3: Widely used in chatbots, content generation, and code assistance.
-
GPT-4: Expands applications to include:
- Advanced Analytics: Better at interpreting complex data and providing insights.
- Creative Tasks: Improved ability in tasks like story writing and poetry composition.
- Visual Understanding: Can analyze and describe images, useful for accessibility tools.
- Ethical Decision Making: Improved understanding of nuanced ethical scenarios.
-
GPT-3: Raised concerns about bias and potential misuse.
-
GPT-4: Incorporates more advanced safety measures:
- Improved Content Filtering: Better at avoiding inappropriate or harmful outputs.
- Enhanced Bias Mitigation: Efforts to reduce various forms of bias in responses.
-
GPT-3: Capable of generating simple code snippets and explanations.
-
GPT-4: Significantly improved code generation and understanding:
-
GPT-3: Good at maintaining context within a single prompt.
-
GPT-4: Demonstrates superior ability to maintain context over longer conversations and across multiple turns of dialogue.
LLMs have demonstrated remarkable adaptability across various domains, leading to the development of specialized models tailored for specific industries and tasks. Here are some notable domain-specific adaptations of LLMs:
- Medical Diagnosis: LLMs trained on vast medical literature can assist in diagnosing complex conditions.
- Drug Discovery: Models like MolFormer use natural language processing techniques to predict molecular properties and accelerate drug development.
- Biomedical Literature Analysis: LLMs can summarize research papers and extract key findings from vast biomedical databases.
- Contract Analysis: Specialized models can review legal documents, identify potential issues, and suggest modifications.
- Case Law Research: LLMs trained on legal precedents can assist lawyers in finding relevant cases and statutes.
- Market Analysis: Models like FinBERT are fine-tuned on financial texts to perform sentiment analysis on market reports and news.
- Fraud Detection: LLMs can analyze transaction patterns and identify potential fraudulent activities.
- Personalized Learning: LLMs can adapt educational content based on a student's learning style and progress.
- Automated Grading: Models can assess essays and provide detailed feedback on writing style and content.
- Climate Modeling: LLMs can process and analyze vast amounts of climate data to improve predictions and understand long-term trends.
- Biodiversity Research: Specialized models can assist in species identification and ecosystem analysis from textual descriptions and images.
- Design Optimization: LLMs can suggest improvements to product designs based on specifications and historical data.
- Predictive Maintenance: Models can analyze sensor data and maintenance logs to predict equipment failures.
- Low-Resource Language Translation: Adaptations like mT5 focus on improving translation quality for languages with limited training data.
- Code Translation: Models like CodeT5 specialize in translating between different programming languages.
- Threat Detection: LLMs can analyze network logs and identify potential security breaches or unusual patterns.
- Vulnerability Analysis: Specialized models can review code and identify potential security vulnerabilities.
Large Language Models (LLMs) have significantly advanced the field of sentiment analysis, offering powerful capabilities for understanding and classifying emotions in text.
LLMs contribute to sentiment analysis in several important ways:
-
Contextual Understanding: LLMs excel at capturing long-range dependencies and context, enabling more accurate interpretation of complex sentiments.
-
Transfer Learning: Pre-trained LLMs can be fine-tuned for sentiment analysis tasks, leveraging their broad language understanding for specific domains.
-
Handling Nuance: LLMs can better grasp subtle emotional cues, sarcasm, and implicit sentiments that traditional methods might miss.
-
Multilingual Capability: Many LLMs are trained on diverse languages, facilitating sentiment analysis across different linguistic contexts.
LLMs consider bidirectional context, allowing for more accurate interpretation of:
- Complex emotions
- Idiomatic expressions
- Figurative language
LLMs effectively handle:
- Negation (e.g., "not bad" as positive)
- Ambiguous terms (e.g., "sick" as good or ill)
LLMs excel in:
- Cross-sentence sentiment analysis
- Document-level sentiment understanding
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# Load pre-trained BERT model and tokenizer
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Prepare input text
text = "The movie was not as good as I expected, quite disappointing."
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
# Perform sentiment analysis
with torch.no_grad():
outputs = model(**inputs)
predicted_class = torch.argmax(outputs.logits, dim=1)
# Map class to sentiment
sentiment_map = {0: "Very Negative", 1: "Negative", 2: "Neutral", 3: "Positive", 4: "Very Positive"}
predicted_sentiment = sentiment_map[predicted_class.item()]
print(f"Predicted Sentiment: {predicted_sentiment}")Large Language Models (LLMs) are powerful tools for generating coherent, context-aware synthetic text. Their applications span from chatbots and virtual assistants to content creation and automated writing systems.
Modern Transformer-based LLMs have revolutionized text generation techniques, enabling dynamic text synthesis with high fidelity and contextual understanding.
- Method: Selects the most probable word at each step, maintaining a pool of top-scoring sequences.
- Advantages: Simple implementation, robust against local optima.
- Drawbacks: Can produce repetitive or generic text.
def beam_search(model, start_token, beam_width=3, max_length=50):
sequences = [[start_token]]
for _ in range(max_length):
candidates = []
for seq in sequences:
next_token_probs = model.predict_next_token(seq)
top_k = next_token_probs.argsort()[-beam_width:]
for token in top_k:
candidates.append(seq + [token])
sequences = sorted(candidates, key=lambda x: model.sequence_probability(x))[-beam_width:]
return sequences[0]- Method: Extends beam search by incorporating diversity metrics to favor unique words.
- Advantages: Reduces repetition in generated text.
- Drawbacks: Increased complexity and potential for longer execution times.
- Method: Randomly samples from the top k words or the nucleus (cumulative probability distribution).
- Advantages: Enhances novelty and diversity in generated text.
- Drawbacks: May occasionally produce incoherent text.
def top_k_sampling(model, start_token, k=10, max_length=50):
sequence = [start_token]
for _ in range(max_length):
next_token_probs = model.predict_next_token(sequence)
top_k_probs = np.partition(next_token_probs, -k)[-k:]
top_k_indices = np.argpartition(next_token_probs, -k)[-k:]
next_token = np.random.choice(top_k_indices, p=top_k_probs/sum(top_k_probs))
sequence.append(next_token)
return sequence- Method: Incorporates randomness into the beam search process at each step.
- Advantages: Balances structure preservation with randomness.
- Drawbacks: May occasionally generate less coherent text.
- Method: Utilizes a score-based approach to regulate the length of generated text.
- Advantages: Useful for tasks requiring specific text lengths.
- Drawbacks: May not always achieve the exact desired length.
- Method: Introduces noise in input sequences and leverages the model's language understanding to reconstruct the original sequence.
- Advantages: Enhances privacy for input sequences without compromising output quality.
- Drawbacks: Requires a large, clean dataset for effective training.
def noisy_channel_generation(model, input_sequence, noise_level=0.1):
noisy_input = add_noise(input_sequence, noise_level)
return model.generate(noisy_input)
def add_noise(sequence, noise_level):
return [token if random.random() > noise_level else random_token() for token in sequence]Here are key ways LLMs can be utilized for translation tasks:
LLMs can perform translations without specific training on translation pairs, utilizing their broad language understanding.
# Example using a hypothetical LLM API
def zero_shot_translate(text, target_language):
prompt = f"Translate the following text to {target_language}: '{text}'"
return llm.generate(prompt)By providing a few examples, LLMs can quickly adapt to specific translation styles or domains.
few_shot_prompt = """
English: Hello, how are you?
French: Bonjour, comment allez-vous ?
English: The weather is nice today.
French: Le temps est beau aujourd'hui.
English: {input_text}
French:"""
translated_text = llm.generate(few_shot_prompt.format(input_text=user_input))LLMs can translate between multiple language pairs without the need for separate models for each pair.
LLMs consider broader context, improving translation quality for ambiguous terms or idiomatic expressions.
context_prompt = f"""
Context: In a business meeting discussing quarterly results.
Translate: "Our figures are in the black this quarter."
Target Language: Spanish
"""
contextual_translation = llm.generate(context_prompt)LLMs can maintain the tone, formality, and style of the original text in the translated version.
LLMs can leverage cross-lingual transfer to translate to and from languages with limited training data.
With optimized inference, LLMs can be used for near real-time translation in applications like chat or subtitling.
LLMs can provide explanations for their translations, helping users understand nuances and choices made during the translation process.
explanation_prompt = """
Translate the following English idiom to French and explain your translation:
"It's raining cats and dogs."
"""
translation_with_explanation = llm.generate(explanation_prompt)LLMs can be fine-tuned on domain-specific corpora to excel in translating technical, medical, or legal texts.
LLMs can be used to evaluate and score translations, providing feedback on fluency and adequacy.
Large Language Models (LLMs) have revolutionized the field of conversation AI, making chatbots more sophisticated and responsive. These models incorporate context, intent recognition, and semantic understanding, leading to more engaging and accurate interactions.
-
Intent Recognition: LLMs analyze user queries to identify the underlying intent or purpose. This enables chatbots to provide more relevant and accurate responses. Models like BERT or RoBERTa can be fine-tuned for intent classification tasks.
-
Named Entity Recognition (NER): LLMs excel at identifying specific entities (e.g., names, locations, dates) in user input, allowing for more tailored responses. Custom models built on top of LLMs can be particularly effective for domain-specific NER tasks.
-
Coreference Resolution: LLMs can recognize and resolve pronoun antecedents, enhancing the chatbot's ability to maintain consistent context throughout a conversation.
-
Natural Language Generation (NLG): LLMs generate human-like text, enabling chatbots to provide coherent and contextually appropriate responses, making interactions feel more natural.
To optimize LLMs for specific chatbot applications, they typically undergo:
- A pre-trained LLM (e.g., GPT-3, GPT-4, or BERT) serves as a base model, leveraging its knowledge gained from vast amounts of general textual data.
- The base model is then fine-tuned on a more focused dataset related to the specific chatbot function or industry (e.g., customer support, healthcare).
Here's a Python example using the transformers library to perform intent classification:
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
# Load pre-trained model and tokenizer
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def classify_intent(user_input):
# Tokenize the input
inputs = tokenizer(user_input, return_tensors="pt", truncation=True, padding=True)
# Predict the intent
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
intent_id = torch.argmax(logits, dim=1).item()
# Map the intent ID to a human-readable label
intent_label = ['Negative', 'Positive'][intent_id]
return intent_label
# Test the function
user_input = "I love this product!"
print(classify_intent(user_input)) # Output: "Positive"-
Few-shot Learning: Modern LLMs like GPT-4 can perform tasks with minimal examples, reducing the need for extensive fine-tuning.
-
Multilingual Models: LLMs like XLM-RoBERTa enable chatbots to operate across multiple languages without separate models for each language.
-
Retrieval-Augmented Generation (RAG): This technique combines LLMs with external knowledge bases, allowing chatbots to access and utilize up-to-date information beyond their training data.
-
Prompt Engineering: Sophisticated prompt design techniques help guide LLMs to produce more accurate and contextually appropriate responses in chatbot applications.
Explore all 63 answers here 👉 Devinterview.io - LLMs
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llms-interview-questions
Similar Open Source Tools
llms-interview-questions
This repository contains a comprehensive collection of 63 must-know Large Language Models (LLMs) interview questions. It covers topics such as the architecture of LLMs, transformer models, attention mechanisms, training processes, encoder-decoder frameworks, differences between LLMs and traditional statistical language models, handling context and long-term dependencies, transformers for parallelization, applications of LLMs, sentiment analysis, language translation, conversation AI, chatbots, and more. The readme provides detailed explanations, code examples, and insights into utilizing LLMs for various tasks.

MM-RLHF
MM-RLHF is a comprehensive project for aligning Multimodal Large Language Models (MLLMs) with human preferences. It includes a high-quality MLLM alignment dataset, a Critique-Based MLLM reward model, a novel alignment algorithm MM-DPO, and benchmarks for reward models and multimodal safety. The dataset covers image understanding, video understanding, and safety-related tasks with model-generated responses and human-annotated scores. The reward model generates critiques of candidate texts before assigning scores for enhanced interpretability. MM-DPO is an alignment algorithm that achieves performance gains with simple adjustments to the DPO framework. The project enables consistent performance improvements across 10 dimensions and 27 benchmarks for open-source MLLMs.
science-codeevolve
CodeEvolve is an open-source framework that combines large language models with evolutionary algorithms to discover and optimize high-performing code solutions. It democratizes algorithmic discovery by making LLM-driven evolutionary search transparent, reproducible, and accessible. CodeEvolve provides a modular foundation for automated code synthesis guided by quantifiable metrics, addressing meta-optimization tasks where complex optimization problems need to be solved. The framework features islands-based genetic algorithm, modular evolutionary operators, quality-diversity optimization, flexible LLM integration, and distributed islands for efficient exploration. Core components include CLI entry point, process runner, evolution engine, program database, exploration schedulers, evaluator, islands coordinator, LLM interface, prompt sampler, and utilities. CodeEvolve demonstrates superior performance on algorithm-discovery benchmarks and is suitable for mathematical discovery, algorithm design, scientific discovery, and software optimization. Reproducibility and determinism are emphasized, with seedable internal algorithmic decisions. Contributions from the community are welcome, focusing on new selection policies, LLM integrations, benchmark problems, documentation, performance optimizations, and bug fixes.

ex-fuzzy
Ex-Fuzzy is a comprehensive Python library for explainable artificial intelligence through fuzzy logic programming. It enables researchers and practitioners to create interpretable machine learning models using fuzzy association rules. The library supports explainable rule-based learning, complete rule base visualization and validation, advanced learning routines, and complete fuzzy logic systems support. It provides rich visualizations, statistical analysis of results, and performance comparisons between different backends. Ex-Fuzzy also supports conformal learning for more reliable predictions and offers various examples and documentation for users to get started.

ai
Jetify's AI SDK for Go is a unified interface for interacting with multiple AI providers including OpenAI, Anthropic, and more. It addresses the challenges of fragmented ecosystems, vendor lock-in, poor Go developer experience, and complex multi-modal handling by providing a unified interface, Go-first design, production-ready features, multi-modal support, and extensible architecture. The SDK supports language models, embeddings, image generation, multi-provider support, multi-modal inputs, tool calling, and structured outputs.
SINQ
SINQ (Sinkhorn-Normalized Quantization) is a novel, fast, and high-quality quantization method designed to make any Large Language Models smaller while keeping their accuracy almost intact. It offers a model-agnostic quantization technique that delivers state-of-the-art performance for Large Language Models without sacrificing accuracy. With SINQ, users can deploy models that would otherwise be too big, drastically reducing memory usage while preserving LLM quality. The tool quantizes models using dual scaling for better quantization and achieves a more even error distribution, leading to stable behavior across layers and consistently higher accuracy even at very low bit-widths.

open-webui-tools
Open WebUI Tools Collection is a set of tools for structured planning, arXiv paper search, Hugging Face text-to-image generation, prompt enhancement, and multi-model conversations. It enhances LLM interactions with academic research, image generation, and conversation management. Tools include arXiv Search Tool and Hugging Face Image Generator. Function Pipes like Planner Agent offer autonomous plan generation and execution. Filters like Prompt Enhancer improve prompt quality. Installation and configuration instructions are provided for each tool and pipe.
trpc-agent-go
A powerful Go framework for building intelligent agent systems with large language models (LLMs), hierarchical planners, memory, telemetry, and a rich tool ecosystem. tRPC-Agent-Go enables the creation of autonomous or semi-autonomous agents that reason, call tools, collaborate with sub-agents, and maintain long-term state. The framework provides detailed documentation, examples, and tools for accelerating the development of AI applications.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.
ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.

ChatDev
ChatDev is a virtual software company powered by intelligent agents like CEO, CPO, CTO, programmer, reviewer, tester, and art designer. These agents collaborate to revolutionize the digital world through programming. The platform offers an easy-to-use, highly customizable, and extendable framework based on large language models, ideal for studying collective intelligence. ChatDev introduces innovative methods like Iterative Experience Refinement and Experiential Co-Learning to enhance software development efficiency. It supports features like incremental development, Docker integration, Git mode, and Human-Agent-Interaction mode. Users can customize ChatChain, Phase, and Role settings, and share their software creations easily. The project is open-source under the Apache 2.0 License and utilizes data licensed under CC BY-NC 4.0.
EnvScaler
EnvScaler is an automated, scalable framework that creates tool-interactive environments for training LLM agents. It consists of SkelBuilder for environment description mining and quality inspection, ScenGenerator for synthesizing multiple environment scenarios, and modules for supervised fine-tuning and reinforcement learning. The tool provides data, models, and evaluation guides for users to build, generate scenarios, collect training data, train models, and evaluate performance. Users can interact with environments, build environments from scratch, and improve LLMs' task-solving abilities in complex environments.
shards
Shards is a high-performance, multi-platform, type-safe programming language designed for visual development. It is a dataflow visual programming language that enables building full-fledged apps and games without traditional coding. Shards features automatic type checking, optimized shard implementations for high performance, and an intuitive visual workflow for beginners. The language allows seamless round-trip engineering between code and visual models, empowering users to create multi-platform apps easily. Shards also powers an upcoming AI-powered game creation system, enabling real-time collaboration and game development in a low to no-code environment.

executorch
ExecuTorch is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch Edge ecosystem and enables efficient deployment of PyTorch models to edge devices. Key value propositions of ExecuTorch are: * **Portability:** Compatibility with a wide variety of computing platforms, from high-end mobile phones to highly constrained embedded systems and microcontrollers. * **Productivity:** Enabling developers to use the same toolchains and SDK from PyTorch model authoring and conversion, to debugging and deployment to a wide variety of platforms. * **Performance:** Providing end users with a seamless and high-performance experience due to a lightweight runtime and utilizing full hardware capabilities such as CPUs, NPUs, and DSPs.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.
parlant
Parlant is a structured approach to building and guiding customer-facing AI agents. It allows developers to create and manage robust AI agents, providing specific feedback on agent behavior and helping understand user intentions better. With features like guidelines, glossary, coherence checks, dynamic context, and guided tool use, Parlant offers control over agent responses and behavior. Developer-friendly aspects include instant changes, Git integration, clean architecture, and type safety. It enables confident deployment with scalability, effective debugging, and validation before deployment. Parlant works with major LLM providers and offers client SDKs for Python and TypeScript. The tool facilitates natural customer interactions through asynchronous communication and provides a chat UI for testing new behaviors before deployment.
For similar tasks
llms-interview-questions
This repository contains a comprehensive collection of 63 must-know Large Language Models (LLMs) interview questions. It covers topics such as the architecture of LLMs, transformer models, attention mechanisms, training processes, encoder-decoder frameworks, differences between LLMs and traditional statistical language models, handling context and long-term dependencies, transformers for parallelization, applications of LLMs, sentiment analysis, language translation, conversation AI, chatbots, and more. The readme provides detailed explanations, code examples, and insights into utilizing LLMs for various tasks.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.
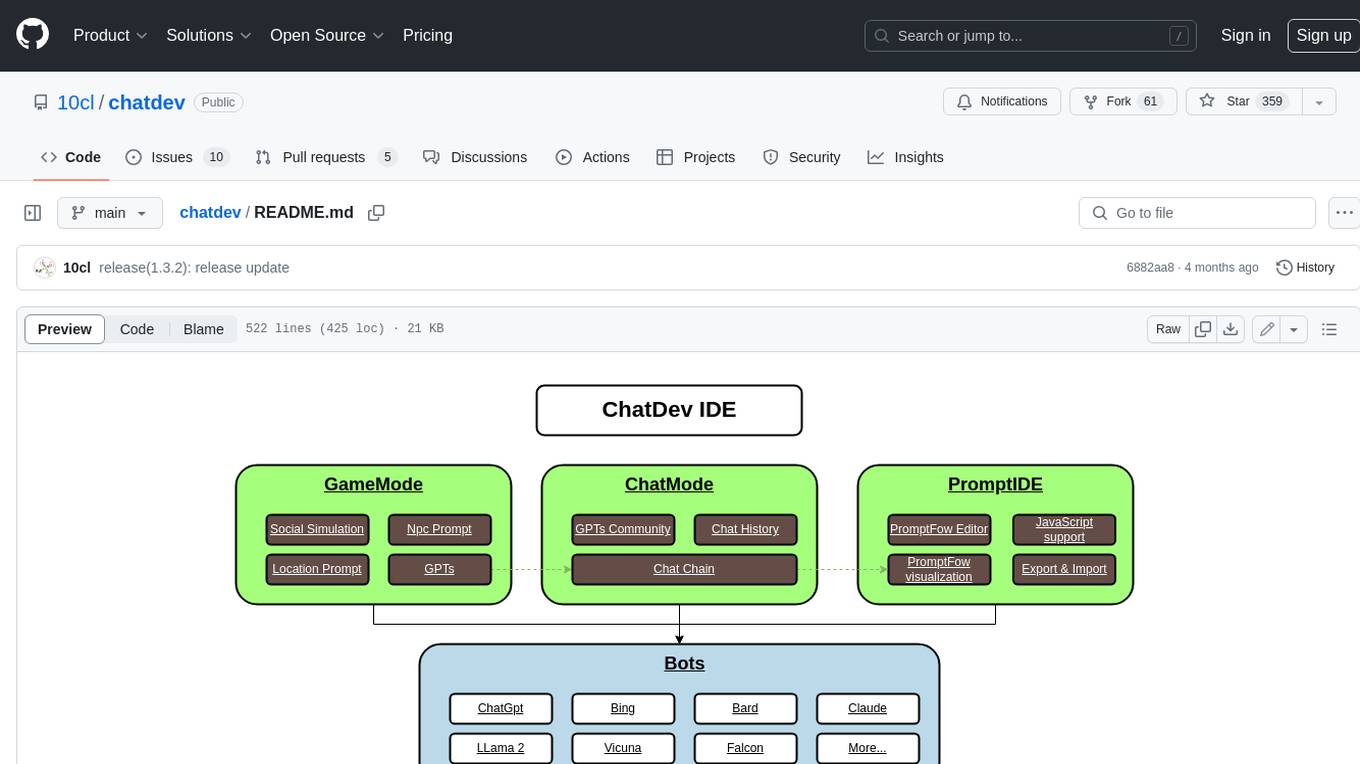
chatdev
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.
ipex-llm-tutorial
IPEX-LLM is a low-bit LLM library on Intel XPU (Xeon/Core/Flex/Arc/PVC) that provides tutorials to help users understand and use the library to build LLM applications. The tutorials cover topics such as introduction to IPEX-LLM, environment setup, basic application development, Chinese language support, intermediate and advanced application development, GPU acceleration, and finetuning. Users can learn how to build chat applications, chatbots, speech recognition, and more using IPEX-LLM.
chatgpt-api
Chat Worm is a ChatGPT client that provides access to the API for generating text using OpenAI's GPT models. It works as a single-page application directly communicating with the API, allowing users to interact with the latest GPT-4 model if they have access. The project includes web, Android, and Windows apps for easy access. Users can set up local development, contribute improvements via pull requests, report bugs or request features on GitHub, deploy to production servers, and release on different app stores. The project is licensed under the MIT License.
JamAIBase
JamAI Base is an open-source platform integrating SQLite and LanceDB databases with managed memory and RAG capabilities. It offers built-in LLM, vector embeddings, and reranker orchestration accessible through a spreadsheet-like UI and REST API. Users can transform static tables into dynamic entities, facilitate real-time interactions, manage structured data, and simplify chatbot development. The tool focuses on ease of use, scalability, flexibility, declarative paradigm, and innovative RAG techniques, making complex data operations accessible to users with varying technical expertise.

draive
draive is an open-source Python library designed to simplify and accelerate the development of LLM-based applications. It offers abstract building blocks for connecting functionalities with large language models, flexible integration with various AI solutions, and a user-friendly framework for building scalable data processing pipelines. The library follows a function-oriented design, allowing users to represent complex programs as simple functions. It also provides tools for measuring and debugging functionalities, ensuring type safety and efficient asynchronous operations for modern Python apps.
typedai
TypedAI is a TypeScript-first AI platform designed for developers to create and run autonomous AI agents, LLM based workflows, and chatbots. It offers advanced autonomous agents, software developer agents, pull request code review agent, AI chat interface, Slack chatbot, and supports various LLM services. The platform features configurable Human-in-the-loop settings, functional callable tools/integrations, CLI and Web UI interface, and can be run locally or deployed on the cloud with multi-user/SSO support. It leverages the Python AI ecosystem through executing Python scripts/packages and provides flexible run/deploy options like single user mode, Firestore & Cloud Run deployment, and multi-user SSO enterprise deployment. TypedAI also includes UI examples, code examples, and automated LLM function schemas for seamless development and execution of AI workflows.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.
Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.