
Caissa
Strong chess engine
Stars: 72
Caissa is a strong, UCI command-line chess engine optimized for regular chess, FRC, and DFRC. It features its own neural network trained with self-play games, supports various UCI options, and provides different EXE versions for different CPU architectures. The engine uses advanced search algorithms, neural network evaluation, and endgame tablebases. It offers outstanding performance in ultra-short games and is written in C++ with modules for backend, frontend, and utilities like neural network trainer and self-play data generator.
README:
![]()

(image generated with DALL·E 2)
Strong, UCI command-line chess engine, written from scratch in C++ in development since early 2021. Optimized for regular chess, FRC (Fischer Random Chess) and DFRC (Double Fischer Random Chess).
Caissa is listed on many chess engines ranking lists:
- CCRL 40/2 FRC - 3965 (#5) (version 1.17)
- CCRL Chess324 - 3701 (#5) (version 1.18)
- CCRL 40/15 - 3601 (#5) (version 1.17 4CPU)
- CCRL Blitz - 3733 (#8) (version 1.16 8CPU)
- SPCC UHO-Top15 - 3671 (#8) (version 1.18)
- IpMan Chess 10+1 (R9-7945HX) - 3496 (#13) (version 1.18 avx512)
- IpMan Chess 10+1 (i9-7980XE) - 3478 (#12) (version 1.17 avx512)
- IpMan Chess 10+1 (i9-13700H) - 3543 (#13) (version 1.18 avx2-bmi2)
- IpMan Chess 5+0 - 3381 (#28) (version 1.8)
- CEGT 40/20 - 3516 (#10) (version 1.16)
- CEGT 40/4 - 3547 (#8) (version 1.15)
- CEGT 5+3 - 3530 (#9) (version 1.13.1)
The engine has been written from the ground up. In early versions it used a simple PeSTO evaluation, which was replaced by the Stockfish NNUE for a short time. Since version 0.7, Caissa uses it's own efficiently updated neural network, trained with Caissa self-play games using a custom trainer. In a way, the first own Caissa network is based on Stockfish's network, but it was much weaker because of the small data set used back then (a few million positions). Currently (as of version 1.18) over 12 billion newly generated positions are used. Also, the old self-play games are successively purged, so that the newer networks are trained only on the most recent games generated by the most recent engine, and so on.
The runtime neural network evaluation code is located in PackedNeuralNetwork.cpp and was inspired by nnue.md document. The neural network trainer is written completely from scratch and is located in NetworkTrainer.cpp, NeuralNetwork.cpp and other NeuralNetwork* files. The trainer is purely CPU-based and is heavily optimized to take advantage of many threads and AVX instructions as well as it exploits the sparse nature of the nets.
The games are generated with the utility SelfPlay.cpp, which generates games with a fixed number of nodes/depth and saves them in a custom binary game format to save space. The opening books used are either Stefan's Pohl UHO books or DFRC openings with few random moves played at the beginning.
- Hash (int) Sets the size of the transposition table in megabytes.
- MultiPV (int) Sets the number of PV lines to search and print.
- MoveOverhead (int) Sets move overhead in milliseconds. Should be increased if the engine loses time.
- Threads (int) Sets the number of threads used for searching.
- Ponder (bool) Enables pondering.
- EvalFile (string) Neural network evaluation file.
- EvalRandomization (int) Allows introducing non-determinism and weakens the engine.
- StaticContempt (int) Static contempt value used throughout whole game.
- DynamicContempt (int) Dynamic contempt value used in the opening/middlegame stage.
- SyzygyPath (string) Semicolon-separated list of paths to Syzygy endgame tablebases.
- SyzygyProbeLimit (int) Maximum number of pieces on the board where Syzygy tablebases can be used.
- UCI_AnalyseMode (bool) Enables analysis mode: search full PV lines and disable any depth constraints.
- UCI_Chess960 (bool) Enables chess 960 mode: castling moves are printed as "king captures rook".
- UCI_ShowWDL (bool) Print win/draw/loss probabilities along with classic centipawn evaluation.
- UseSAN (bool) Enables short algebraic notation output (FIDE standard) instead of default long algebraic notation.
- ColorConsoleOutput (bool) Enables colored console output for better readability.
- AVX-512 - Fastest, requires a x64 CPU with AVX-512 instruction set support. May not be supported on consumer-grade CPUs.
- BMI2 - Fast, requires a x64 CPU with AVX2 and BMI2 instruction set support. Supported by majority of modern CPUs.
- AVX2 - Fast, requires a x64 CPU with AVX2 instruction set support. May be faster than BMI2 on some older CPUs (e.g. Intel Haswell processors).
- POPCNT - Slower, requires a x64 CPU with SSE4 and POPCNT instruction set support. For older CPUs.
- Legacy - Slowest, requires any x64 CPU. For very old x64 CPUs.
- UCI protocol
- Neural network evaluation
- Syzygy and Gaviota endgame tablebases support
- Chess960 (Fischer Random) support
- Negamax with alpha-beta pruning
- Iterative Deepening with Aspiration Windows
- Principal Variation Search (PVS)
- Quiescence Search
- Transposition Table
- Multi-PV search
- Multithreaded search via shared transposition table
- Neural network evaluation
- (5x768→1024)x2→1 architecture
- effectively updated first layer
- manually vectorized code supporting SSE2, AVX2, AVX-512 and ARM NEON instructions
- clipped-ReLU activation function
- 8 variants of last layer weights selected based on piece count
- input features: absolute piece coordinates with horizontal symmetry, 11 king buckets
- Special endgame evaluation routines
- Custom CPU-based trainer using Adam algorithm
- Heavily optimized using AVX instructions, multithreading, and exploiting sparsity of the first layer input
- Network trained on data generated purely from self-play games
- Large Pages Support for Transposition Table
- Magic Bitboards
- Handling non-standard chess positions (e.g. 64 pieces on the board, etc.)
- Outstanding performance at ultra-short games (sub-second for whole game).
The projects comprises following modules:
- backend (library) - engine's core
- frontend (executable) - UCI wrapper for the backend
- utils (executable) - various utilities, such as unit tests, neural network trainer, self-play data generator, etc.
To compile for Linux just call make in src directory:
cd src
make -j
NOTE: This will compile the default AVX2/BMI2 version.
To compile for Linux using CMake:
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Final ..
make -j
NOTE: Currently, the project compiles with AVX2/BMI2 support by default.
There are three configurations supported:
- Final - final version, without asserts, etc.
- Release - development version with asserts enabled and with optimizations enabled for better performance
- Debug - development version with asserts enabled and optimizations disabled
To compile for Windows, use GenerateVisualStudioSolution.bat to generate Visual Studio solution. The only tested Visual Studio version is 2022. Using CMake directly in Visual Studio was not tested.
NOTE: After compilation make sure you copy appropriate neural net file from data/neuralNets directory to location where executable file is generated (build/bin on Linux or build\bin\x64\<Configuration> on Windows).
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Caissa
Similar Open Source Tools
Caissa
Caissa is a strong, UCI command-line chess engine optimized for regular chess, FRC, and DFRC. It features its own neural network trained with self-play games, supports various UCI options, and provides different EXE versions for different CPU architectures. The engine uses advanced search algorithms, neural network evaluation, and endgame tablebases. It offers outstanding performance in ultra-short games and is written in C++ with modules for backend, frontend, and utilities like neural network trainer and self-play data generator.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.

executorch
ExecuTorch is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch Edge ecosystem and enables efficient deployment of PyTorch models to edge devices. Key value propositions of ExecuTorch are: * **Portability:** Compatibility with a wide variety of computing platforms, from high-end mobile phones to highly constrained embedded systems and microcontrollers. * **Productivity:** Enabling developers to use the same toolchains and SDK from PyTorch model authoring and conversion, to debugging and deployment to a wide variety of platforms. * **Performance:** Providing end users with a seamless and high-performance experience due to a lightweight runtime and utilizing full hardware capabilities such as CPUs, NPUs, and DSPs.
retrace
Retrace is a local-first screen recording and search application for macOS, inspired by Rewind AI. It captures screen activity, extracts text via OCR, and makes everything searchable locally on-device. The project is in very early development, offering features like continuous screen capture, OCR text extraction, full-text search, timeline viewer, dashboard analytics, Rewind AI import, settings panel, global hotkeys, HEVC video encoding, search highlighting, privacy controls, and more. Built with a modular architecture, Retrace uses Swift 5.9+, SwiftUI, Vision framework, SQLite with FTS5, HEVC video encoding, CryptoKit for encryption, and more. Future releases will include features like audio transcription and semantic search. Retrace requires macOS 13.0+ (Apple Silicon required) and Xcode 15.0+ for building from source, with permissions for screen recording and accessibility. Contributions are welcome, and the project is licensed under the MIT License.

ai
Jetify's AI SDK for Go is a unified interface for interacting with multiple AI providers including OpenAI, Anthropic, and more. It addresses the challenges of fragmented ecosystems, vendor lock-in, poor Go developer experience, and complex multi-modal handling by providing a unified interface, Go-first design, production-ready features, multi-modal support, and extensible architecture. The SDK supports language models, embeddings, image generation, multi-provider support, multi-modal inputs, tool calling, and structured outputs.

MM-RLHF
MM-RLHF is a comprehensive project for aligning Multimodal Large Language Models (MLLMs) with human preferences. It includes a high-quality MLLM alignment dataset, a Critique-Based MLLM reward model, a novel alignment algorithm MM-DPO, and benchmarks for reward models and multimodal safety. The dataset covers image understanding, video understanding, and safety-related tasks with model-generated responses and human-annotated scores. The reward model generates critiques of candidate texts before assigning scores for enhanced interpretability. MM-DPO is an alignment algorithm that achieves performance gains with simple adjustments to the DPO framework. The project enables consistent performance improvements across 10 dimensions and 27 benchmarks for open-source MLLMs.
obsidian-ai-tagger-universe
AI Tagger Universe is a plugin for Obsidian that automatically generates intelligent tags for notes using AI. It offers flexible AI integration with various services, smart tagging system with multiple modes, tag network visualization, advanced management features, and support for multiple languages. Users can easily install the plugin, configure AI providers, generate tags, and visualize tag relationships. The plugin also supports nested tags, hierarchical tag generation, and tag format options. It includes bug fixes, major features, improvements, and language support for English and Chinese interfaces.

chipper
Chipper provides a web interface, CLI, and architecture for pipelines, document chunking, web scraping, and query workflows. It is built with Haystack, Ollama, Hugging Face, Docker, Tailwind, and ElasticSearch, running locally or as a Dockerized service. Originally created to assist in creative writing, it now offers features like local Ollama and Hugging Face API, ElasticSearch embeddings, document splitting, web scraping, audio transcription, user-friendly CLI, and Docker deployment. The project aims to be educational, beginner-friendly, and a playground for AI exploration and innovation.
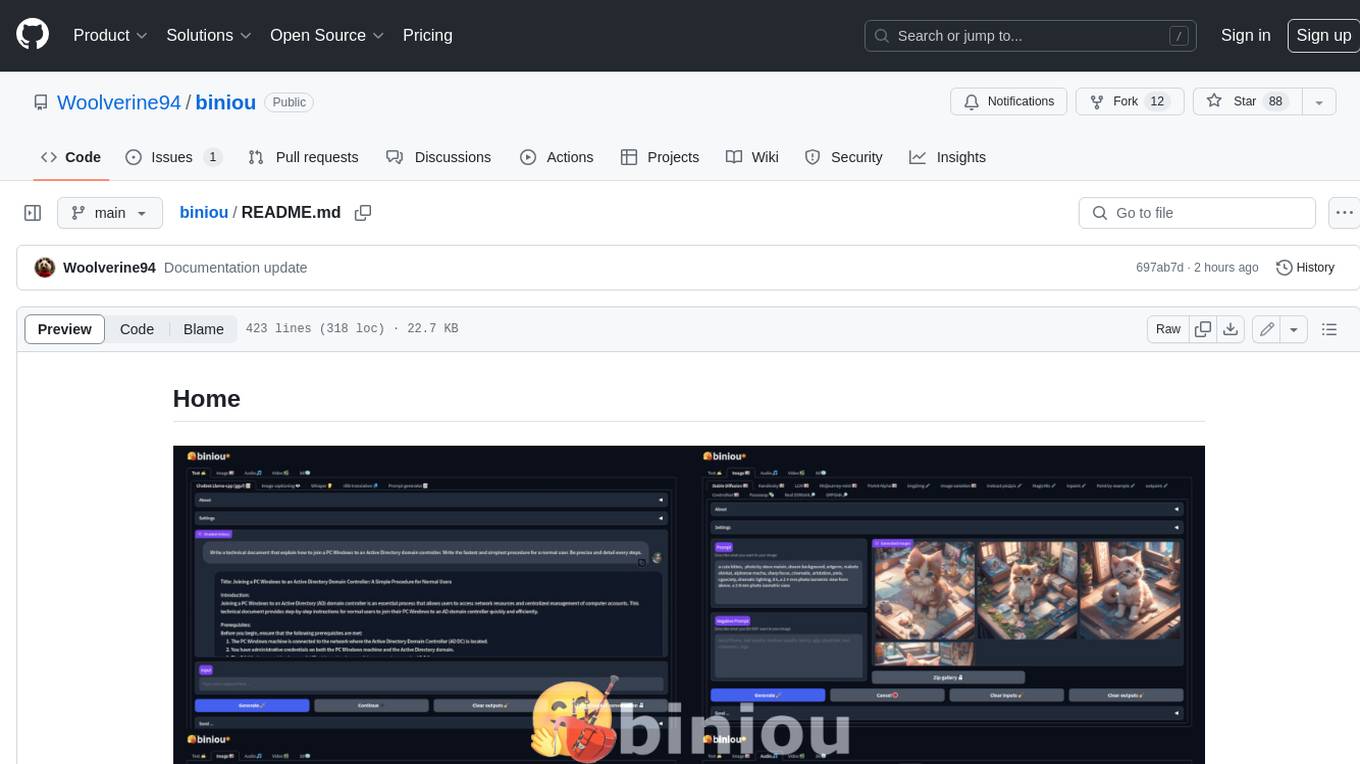
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
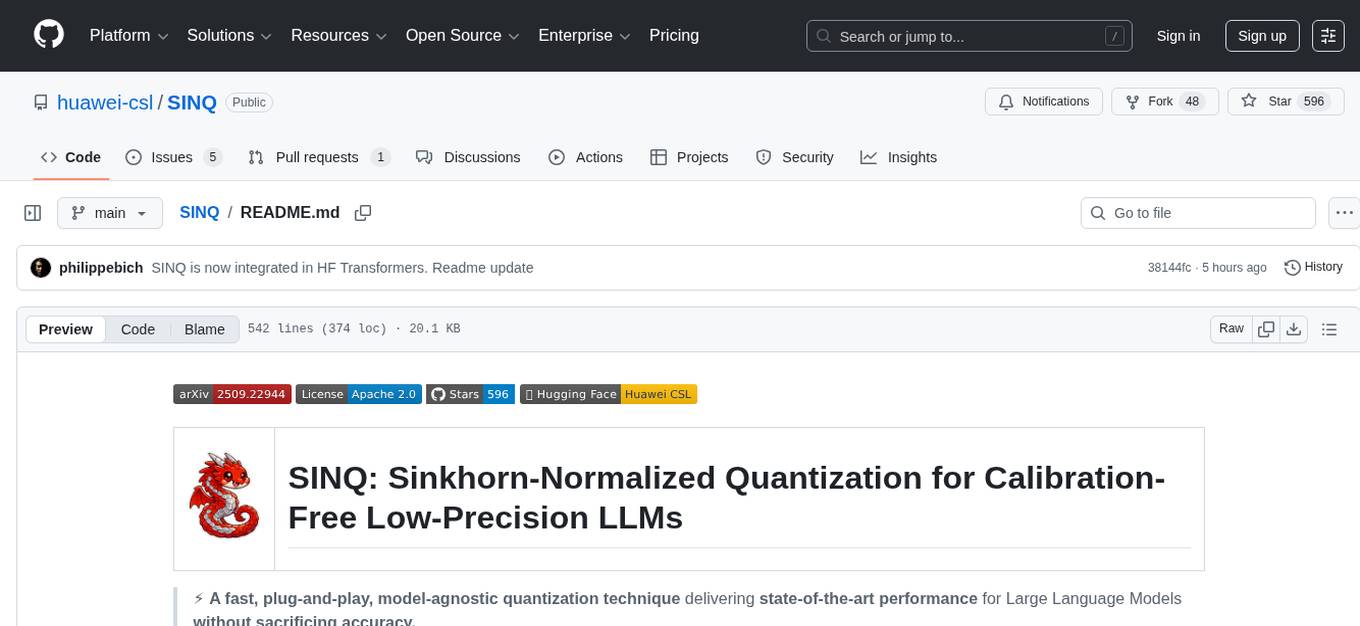
SINQ
SINQ (Sinkhorn-Normalized Quantization) is a novel, fast, and high-quality quantization method designed to make any Large Language Models smaller while keeping their accuracy almost intact. It offers a model-agnostic quantization technique that delivers state-of-the-art performance for Large Language Models without sacrificing accuracy. With SINQ, users can deploy models that would otherwise be too big, drastically reducing memory usage while preserving LLM quality. The tool quantizes models using dual scaling for better quantization and achieves a more even error distribution, leading to stable behavior across layers and consistently higher accuracy even at very low bit-widths.
vearch
Vearch is a cloud-native distributed vector database designed for efficient similarity search of embedding vectors in AI applications. It supports hybrid search with vector search and scalar filtering, offers fast vector retrieval from millions of objects in milliseconds, and ensures scalability and reliability through replication and elastic scaling out. Users can deploy Vearch cluster on Kubernetes, add charts from the repository or locally, start with Docker-compose, or compile from source code. The tool includes components like Master for schema management, Router for RESTful API, and PartitionServer for hosting document partitions with raft-based replication. Vearch can be used for building visual search systems for indexing images and offers a Python SDK for easy installation and usage. The tool is suitable for AI developers and researchers looking for efficient vector search capabilities in their applications.
NotelyVoice
Notely Voice is a free, modern, cross-platform AI voice transcription and note-taking application. It offers powerful Whisper AI Voice to Text capabilities, making it ideal for students, professionals, doctors, researchers, and anyone in need of hands-free note-taking. The app features rich text editing, simple search, smart filtering, organization with folders and tags, advanced speech-to-text, offline capability, seamless integration, audio recording, theming, cross-platform support, and sharing functionality. It includes memory-efficient audio processing, chunking configuration, and utilizes OpenAI Whisper for speech recognition technology. Built with Kotlin, Compose Multiplatform, Coroutines, Android Architecture, ViewModel, Koin, Material 3, Whisper AI, and Native Compose Navigation, Notely follows Android Architecture principles with distinct layers for UI, presentation, domain, and data.
RSTGameTranslation
RSTGameTranslation is a tool designed for translating game text into multiple languages efficiently. It provides a user-friendly interface for game developers to easily manage and localize their game content. With RSTGameTranslation, developers can streamline the translation process, ensuring consistency and accuracy across different language versions of their games. The tool supports various file formats commonly used in game development, making it versatile and adaptable to different project requirements. Whether you are working on a small indie game or a large-scale production, RSTGameTranslation can help you reach a global audience by making localization a seamless and hassle-free experience.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

probe
Probe is an AI-friendly, fully local, semantic code search tool designed to power the next generation of AI coding assistants. It combines the speed of ripgrep with the code-aware parsing of tree-sitter to deliver precise results with complete code blocks, making it perfect for large codebases and AI-driven development workflows. Probe is fully local, keeping code on the user's machine without relying on external APIs. It supports multiple languages, offers various search options, and can be used in CLI mode, MCP server mode, AI chat mode, and web interface. The tool is designed to be flexible, fast, and accurate, providing developers and AI models with full context and relevant code blocks for efficient code exploration and understanding.
For similar tasks
Minic
Minic is a chess engine developed for learning about chess programming and modern C++. It is compatible with CECP and UCI protocols, making it usable in various software. Minic has evolved from a one-file code to a more classic C++ style, incorporating features like evaluation tuning, perft, tests, and more. It has integrated NNUE frameworks from Stockfish and Seer implementations to enhance its strength. Minic is currently ranked among the top engines with an Elo rating around 3400 at CCRL scale.
Caissa
Caissa is a strong, UCI command-line chess engine optimized for regular chess, FRC, and DFRC. It features its own neural network trained with self-play games, supports various UCI options, and provides different EXE versions for different CPU architectures. The engine uses advanced search algorithms, neural network evaluation, and endgame tablebases. It offers outstanding performance in ultra-short games and is written in C++ with modules for backend, frontend, and utilities like neural network trainer and self-play data generator.
eleeye
ElephantEye is a free Chinese Chess program that follows the GNU Lesser General Public Licence. It is designed for chess enthusiasts and programmers to use freely. The program works as a XiangQi engine for XQWizard with strong AI capabilities. ElephantEye supports UCCI 3.0 protocol and offers various parameter settings for users to customize their experience. The program uses brute-force chess algorithms and static position evaluation techniques to search for optimal moves. ElephantEye has participated in computer chess competitions and has been tested on various online chess platforms. The source code of ElephantEye is available on SourceForge for developers to explore and improve.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

nmed2024
Nmed2024 is a GitHub repository that contains code for a neural network model designed for medical image analysis. The repository includes scripts for training the model, as well as pre-trained weights for quick deployment. The model is specifically tailored for detecting abnormalities in medical images, such as tumors or fractures. It utilizes deep learning techniques to achieve high accuracy and can be easily integrated into existing medical imaging systems. Researchers and developers in the healthcare industry can leverage this tool to enhance the efficiency and accuracy of medical image analysis tasks.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.