
Minic
A simple chess engine to learn and play with
Stars: 88
Minic is a chess engine developed for learning about chess programming and modern C++. It is compatible with CECP and UCI protocols, making it usable in various software. Minic has evolved from a one-file code to a more classic C++ style, incorporating features like evaluation tuning, perft, tests, and more. It has integrated NNUE frameworks from Stockfish and Seer implementations to enhance its strength. Minic is currently ranked among the top engines with an Elo rating around 3400 at CCRL scale.
README:
![]()
![]()
![]()
![]()
Minic is a chess engine I'm developing to learn about chess programming and modern C++ (please see this lovely wiki for more details on chess programming).
Minic has no graphic interface (GUI) but is compatible with both CECP (xboard) and UCI protocol so you can use it in your favorite software (for instance Cutechess, Arena, Banksia, Winboard/Xboard, c-chess-cli, ...).
Minic is currently one of the 15 best engines in major rating lists and the strongest french one.
Here are some shortcuts to navigate in this document :
- Support Minic development
- History & the NNUE Minic story
- Minic NNUE "originality" status
- Testing and strength
- Rating Lists & competitions
- Release process
- How to compile
- Syzygy EGT
- How to run
- Options
- Videos
- Thanks
Generating data, learning process, tuning, optimization and testing of a chess engine is quite hardware intensive ! I have some good hardware at home but this is far from enough. This is why I opened a Patreon account for Minic ; if you want to support Minic development, it is the place to be ;-)
For a year and a half Minic was (mainly) a one-file-code with very dense lines. This is of course very wrong in terms of software design... So why is it so? First reason is that Minic was first developped as a week-end project (in mid-october 2018), the quick-and-dirty way, and since then I was having fun going on the way of minimal lines of code direction ; being a "small" code size engine was part of the stakes in developing it the first few months.
Until version 2 of Minic, some optional features such as evaluation and searchs tuning, perft, tests, uci support, book generation ... were available in the Add-Ons directory ; they are now fused with the source code for a while.
Nowadays, in fact since the release of version "2", the engine is written in a more classic C++ style, although some very dense lines may still be present and recall Minic past compacity...
More details about Minic history in the next paragraphs...
Initially, the code size of Minic was supposed not to go above 2000sloc. It started as a week-end project in october 2018 (http://talkchess.com/forum3/viewtopic.php?f=2&t=68701). But, as soon as more features (especially SMP, material tables and bitboard) came up, I tried to keep it under 4000sloc and then 5000sloc, ... This is why this engine was named Minic, this stands for "Minimal Chess" (and is not related to the GM Dragoljub Minić) but it has not much to do with minimalism anymore nowadays... For the record, here is a link to the very first published version of Minic (https://github.com/tryingsomestuff/Minic/blob/dbb2fc7f026d5cacbd35bc379d8a1cdc1cad5674/minic.cc).
Version "1" was published as a one year anniversary release in october 2019. At this point Minic has already gone from a 1800 Elo 2-days-of-work engine, to a 2800 Elo engine being invited at TCEC qualification league !
Version "2" was released for April 1st 2020 (during covid-19 confinement in France). For this version, the one file Minic was splitted into many header and source files, and commented a lot more, without negative impact on speed and strength.
Minic2, since release 2.47 of August 8th 2020 (http://talkchess.com/forum3/viewtopic.php?f=2&t=73521&hilit=minic2&start=50#p855313), has the possibility to be build using a shameless copy of the NNUE framework of Stockfish. Integration of NNUE was done easily and I hoped this can be done for any engines, especially if NNUE is released as a standalone library (see https://github.com/dshawul/nncpu-probe for instance). First tests shown that "MinicNNUE" is around 200Elo stronger than Minic, around the level of Xiphos or Ethereal at this date at short TC and maybe something like 50Elo higher at longer TC (so around Komodo11).
When using a NNUE network with this Stockfish implementation, it is important that Minic is called "MinicNNUE". Indeed, MinicNNUE (with copy/pasted SF NNUE implementation), won't be the official Minic, as this is not my own work at all.
Later on, starting from version 2.50, the NNUE learner from NodChip repository has also been ported to Minic so that networks can be built using Minic data and search can be done. The genFen part of Nodchip was not ported and instead replaced by an internal process to produce training data. This included both extracting position from fixed depth game and from random positions.
Nets I built are still available at https://github.com/tryingsomestuff/NNUE-Nets.
Version "3" of Minic is released in november 2020 (during second covid-19 confinement) as a 2 years anniversary release and is not using, nor compatible with, SF NNUE implementation anymore. More about this just below...
Starting from release 3.00, Minic is not using Stockfish NNUE implementation anymore and is no more compatible with SF nets. It was too much foreign code inside Minic to be fair, to be maintained, to be fun. Seer chess engine author is offering a very well written implementation of NNUE that I borrowed and adapt to Minic (https://github.com/connormcmonigle/seer-nnue). The code was more or less 400 lines. I choose to keep some Stockfish code just for binary sfens format conversion as everyone (or at least many many) is using this data format for now. Training code is an external tool written in Python without any dependency to engine, also first adapted from Seer repository and then taking ideas from Gary Linscott pytorch trainer (https://github.com/glinscott/nnue-pytorch). A new story was written in Minic 3 and the code has diverged quite a lot from the initial one.
Nets I built are available at https://github.com/tryingsomestuff/NNUE-Nets. Beware there is no retrocompatibility of the net from version to version.
- use of PST score in move sorter to compensate near 0 history of quiet move
- aggregate history score for move sorter and history heuristic (cmh + history[piece and color][tosquare] + history[color][square][square])
- danger (from evaluation) based pruning and reductions in search
- emergency (from IID loop instabilities) based pruning and reductions in search
- history aware (boom / moob) based pruning and reductions in search
- use mobility data in search
- contempt opponent model taking opponent name or opponent rating into account
- "features" based evaluation parameter available to the user to tune game play (HCE evaluation only, not for NNUE)
- using a depth factor for pruning and reduction that takes TT entry depth into account
- training NNUE on DFRC data
- Inference code : originally based on Seer one (Connor McMonigle), many refactoring and experiements inside (clipped ReLU, quantization on read, vectorization, sub-net depending on pieces number, ...).
- Network topology : Many many have been tested (with or without skip connections, bigger or smaller input layer, number of layers, pieces buckets, ...) mainly without success. Always trying to find a better idea ... Currently a multi-bucket (based on the number of pieces) net with a common input layer and 2 inner nets.
- Training code : mainly based on the Gary Linscott and Tomasz Sobczyk (@Sopel) pytorch trainer (https://github.com/glinscott/nnue-pytorch), adapted and tuned to Minic.
- Data generation code : fully original, pure Minic data. Many ideas has been tried (generate inside search tree, self-play, multi-pv, random, with or without syzygy, ...). Some LC0 data are also used after being rescored using previous Minic version.
- Other tools : many little tools around training process, borrowed here and there and adapated or developed by myself.
In brief, Minic NNUE world is vastly inspired from what others are doing and is using pure Minic data (Minic generated or otherwise rescored).
Minic is currently in the 20 best engines with a Elo rating around 3400 at CCRL scale.
This table shows the evolution of nets strength of various Minic nets on an AVX2 hardware at short TC (10s+0.1). Results will be a lot different on older hardware where NNUE evaluation is much slower. I thus encourage users to only use Minic with NNUE nets on recent hardware. As we see, nets strenght is increasing version after version, this is due to better data, new net topologies but also of course to the fact that I rescore (or regenerate) data with previous version of Minic before training a new net. Moreover, the decision to revert SF implementation and start my own work based on Seer initial implementation led to a 2 years net training journey to fill the performance gap ...
Rank Name Elo +/- Games Score Draw
1 minic_2.53_nn-97f742aaefcd 165 24 458 72.1% 42.8%
2 minic_3.17_NiNe3 112 24 457 65.5% 44.0%
3 minic_2.53_napping_nexus 97 24 458 63.6% 42.1%
4 minic_3.18 97 25 457 63.6% 40.5%
5 minic_3.17 -5 24 457 49.3% 41.4%
6 minic_2.53_nascent_nutrient -8 25 457 48.9% 40.5%
7 minic_3.14 -55 23 458 42.1% 46.7%
8 minic_3.08 -57 25 457 41.9% 40.9%
9 minic_3.02_nettling_nemesis -72 25 458 39.7% 39.3%
10 minic_3.06_nocturnal_nadir -114 25 457 34.1% 38.9%
11 minic_3.04_noisy_notch -155 27 458 29.0% 33.2%
More details about those nets I built are available at https://github.com/tryingsomestuff/NNUE-Nets.
In this table, Minic 3.19 is used to compare NNUE performances on various CPU architecture (effect of vectorisation).
Rank Name Elo +/- Games Score Draw
1 minic_3.19_slylake 68 23 422 59.7% 50.7%
2 minic_3.19_sandybridge 14 23 423 52.0% 53.4%
3 minic_3.19_nehalem -27 23 421 46.1% 52.3%
4 minic_3.19_core2 -55 24 422 42.2% 49.3%
What does this say ? Well ... for NNUE, using AVX2 is very important. This can explain some strange results during some testing process and in rating list where I sometimes see my nets underperforming a lot. So please, use AVX2 hardware (and the corresponding Minic binary, i.e. the "skylake" one for Intel or at least the "znver1" for AMD) for NNUE testing if possible.
I'd love to own a big enough hardware to test with more than 8 threads ... Here are 3s+0.1 TC results to illustrate threading capabilities. Minic is thus scaling very well.
Rank Name Elo +/- Games Score Draw
1 minic_3.19_8 123 34 156 67.0% 58.3%
2 minic_3.19_6 94 36 156 63.1% 54.5%
3 minic_3.19_4 20 33 156 52.9% 63.5%
4 minic_3.19_2 -45 35 156 43.6% 59.0%
5 minic_3.19_1 -206 41 156 23.4% 42.9%
Moreover, speed test on CCC hardware, 2x AMD EPYC 7H12 (128 physical cores) :
250 threads : 101,008,415 NPS
125 threads : 73,460,779 NPS
and speed test on a 2x Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz (52 physical cores) :
104 threads : 46,291,408 NPS
52 threads : 25,175,817 NPS
suggest Minic is reacting quite well to hyperthreading.
Here are some fast TC results of a gauntlet tournament (STC 10s+0.1) for Minic 3.36.
Rank Name Elo +/- Games Score Draw
0 minic_3.36 22 5 9852 53.1% 50.6%
1 seer 103 11 1642 64.4% 57.9%
2 rofChade3 52 11 1642 57.4% 55.8%
3 Uralochka3.39e-avx2 -47 11 1642 43.3% 57.3%
4 komodo-13.02 -78 13 1642 39.0% 41.7%
5 Wasp600-linux-avx -80 12 1642 38.7% 49.2%
6 stockfish.8 -81 13 1642 38.6% 41.9%
Minic random-mover (level = 0) stats are the following :
7.73% 0-1 {Black mates}
7.50% 1-0 {White mates}
2.45% 1/2-1/2 {Draw by 3-fold repetition}
21.99% 1/2-1/2 {Draw by fifty moves rule}
54.16% 1/2-1/2 {Draw by insufficient mating material}
6.13% 1/2-1/2 {Draw by stalemate}
Here is 4 years of CCRL progress (single thread)

- 40/15: Minic 3.31 + Natural Naughtiness is tested at 3447 on the CCRL 40/15 scale, 4 cores
- Blitz: Minic 3.31 + Natural Naughtiness is tested at 3609 on the CCRL BLITZ scale, 8 cores
- FRC: Minic 3.32 + Natural Naughtiness is tested at 3591 on the CCRL FRC list
- 40/4: Minic 3.27 + Natural Naughtiness is tested at 3409 on the CEGT 40/4 list
- 40/20: Minic Minic 3.32 + Natural Naughtiness is tested at 3388 on the CEGT 40/20 list
- 5+3 pb=on: 3.27 + Natural Naughtiness is tested at 3445 on the CEGT 5+3 PB=ON list
- 25+8: Minic 3.22 + Nylon Nonchalance is tested at 3430 on the CEGT 25+8 list
- Minic 3.30 + Natural Naughtiness is tested at 3285 on the fastgm 60sec+0.6sec rating list
- Minic 3.30 + Natural Naughtiness is tested at 3347 on the fastgm 10min+6sec rating list
- Minic 3.24 + Nylon Nonchalance is tested at 3303 on the fastgm 60min+15sec rating list
- Minic 3.18 + Nimble Nothingness is tested at 3276 on the fastgm 60sec+0.6sec 16 cores rating list
- Minic 3.31 + Natural Naughtiness is tested at 3528 on the SP-CC 3min+1s rating list
- Minic 3.17 + Nucleated Neurulation is tested at 3229 on the GRL 40/2 rating list
- Minic 3.06 using Nocturnal Nadir net is tested at 3078 on the GRL 40/15 rating list
- Minic 3.18 + Nimble Nothingness is tested at 3305 on the BRUCE rating list
- Minic 3.27 + Natural Naughtiness is tested at 3347 on the IpmanChess rating list
- STS : 1191/1500 @10sec per position (single thread on an i7-9700K)
- WAC : 291/300 @10sec per position (single thread on an i7-9700K)
TCEC hardware: Minic is at 3440 (https://tcec-chess.com/bayeselo.txt)
Here are Minic results at TCEC main event (https://tcec-chess.com/)
TCEC15: 8th/10 in Division 4a (https://www.chessprogramming.org/TCEC_Season_15)
TCEC16: 13th/18 in Qualification League (https://www.chessprogramming.org/TCEC_Season_16)
TCEC17: 7th/16 in Q League, 13th/16 in League 2 (https://www.chessprogramming.org/TCEC_Season_17)
TCEC18: 4th/10 in League 3 (https://www.chessprogramming.org/TCEC_Season_18)
TCEC19: 3rd/10 in League 3 (https://www.chessprogramming.org/TCEC_Season_19)
TCEC20: 2nd/10 in League 3, 9th/10 in League 2 (https://www.chessprogramming.org/TCEC_Season_20)
TCEC21: 1st/12 in League 3, 6th/10 in League 2 (https://www.chessprogramming.org/TCEC_Season_21)
TCEC22: 2nd/8 in League 2, 8th/8 in League 1 (well tried ;) ) (https://www.chessprogramming.org/TCEC_Season_22)
TCEC23: 3rd/12 in League 1 ! (https://tcec-chess.com/#div=l1&game=1&season=23)
TCEC24: 9rd/12 in League 1 ! (https://tcec-chess.com/#div=l1&game=1&season=24)
TCEC25: 8rd/12 in League 1 ! (https://tcec-chess.com/#div=l1&game=1&season=25)
WARNING : the former Dist directory as been REMOVED from the repository because it was starting to be too big. Unofficial releases are not available anymore here. All (including unofficial) releases are available in a new repo, here : https://github.com/tryingsomestuff/Minic-Dist, also available as a git submodule.
Some stable/official ones will still be made available as github release (https://github.com/tryingsomestuff/Minic/releases). I "officially release" (create a github version) as soon as I have some validated elo (at least +10) or an important bug fix.
In a github release, a tester shall only use the given (attached) binaries. The full "source" package always contains everything (source code, test suites, opening suite, books, ...) but using git "submodule" so that the main repository remains small.
Binaries are named following this convention :
Linux 64:
-- Intel --
* minic_X.YY_linux_x64_skylake : fully optimized Linux64 (popcnt+avx2+bmi2)
* minic_X.YY_linux_x64_sandybridge : optimized Linux64 (popcnt+avx)
* minic_X.YY_linux_x64_nehalem : optimized Linux64 (popcnt+sse4.2)
* minic_X.YY_linux_x64_core2 : basic Linux64 (nopopcnt+sse3)
-- AMD --
* minic_X.YY_linux_x64_znver3 : fully optimized Linux64 (popcnt+avx2+bmi2)
* minic_X.YY_linux_x64_znver1 : almost optimized Linux64 (popcnt+avx2)
* minic_X.YY_linux_x64_bdver1 : optimized Linux64 (nopopcnt+avx)
* minic_X.YY_linux_x64_barcelona : optimized Linux64 (nopopcnt+sse4A)
* minic_X.YY_linux_x64_athlon64-sse3 : basic Linux64 (nopopcnt+sse3)
Windows 64:
Some as for Linux with naming convention like this minic_X.YY_mingw_x64_skylake.exe
Windows 32:
* minic_X.YY_mingw_x32_pentium2.exe : very basic Windows32
Others:
* minic_X.YY_android : android armv7
* minic_X.YY_linux_x32_armv7 : RPi armv7
* minic_X.YY_linux_x64_armv8 : RPi armv8
Please note that for Linux binaries to work you will need a recent libc installed on your system.
Please note that Win32 binaries are very slow so please use Win64 one if possible.
Please note that Minic has always been a little weaker under Windows OS (probably due to cross-compilation lacking PGO).
- Linux (g++>=11 or clang++>=18 requiered, Minic is using C++20): just type "make" (defining CC and CXX is possible), or use the given build script Tools/tools/build.sh (or make your own ...), or try to have a look at Tools/TCEC/update.sh for some hints. The executable will be available in Dist/Minic3 subdirectory.
- Windows : use the Linux cross-compilation script given or make your own. From time to time I also check that recent VisualStudio versions can compile Minic without warnings but I don't distribute any VS project.
- Android/RPi/... (experimental...) : use the given cross-compilation script or make your own.
A minimal working example on Linux for dev version would be
git clone https://github.com/tryingsomestuff/Minic.git
cd Minic
git submodule update --init Fathom
make
# done exe in Dist/Minic3
To compile with SYZYGY support you'll need to clone https://github.com/jdart1/Fathom as Fathom directory and activate WITH_SYZYGY definition at compile time (this is default behaviour). This can be done using the given git submodule or by hand. To use EGT just specify syzygyPath in the command line or using the GUI option.
add the command line option "-xboard" to go to xboard/winboard mode or -uci for UCI. If not option is given Minic will default to use UCI protocol.
Please note that if you want to force specific option from command line instead of using protocol option, you have to first specific protocol as the first command line argument. For instance minic -uci -minOutputLevel 0 will give a very verbose Minic using uci.
Other available options (depending on compilation option, see config.hpp) are mainly for development or debug purpose. They do not start the protocol loop. Here is an incompleted list :
- -perft_test : run the inner perft test
- -eval <"fen"> : static evaluation of the given position
- -gen <"fen"> : move generation on the given position
- -perft <"fen"> depth : perft on the given position and depth
- -analyze <"fen"> depth : analysis on the given position and depth
- -qsearch <"fen"> : just a qsearch ...
- -mateFinder <"fen"> depth : same as analysis but without prunings in search
- -pgn : extraction tool to build tuning data
- -tuning : run an evaluation tuning session (a.k.a. Texel tunings)
- -selfplay [depth] [number of games] (default are 15 and 1): launch some selfplay game with genfen activated
- ...
Starting from release 1.00 Minic support setting options using protocol (both XBoard and UCI). Option priority are as follow : command line option can be override by protocol option. This way, Minic supports strength limitation, FRC, pondering, can use contempt, ...
If compiled with the WITH_SEARCH_TUNING definition, Minic can expose all search algorithm parameters so that they can be tweaked. Also, when compiled with WITH_PIECE_TUNING, Minic can expose all middle- and end-game pieces values.
Minic comes with some command line options :
- -minOutputLevel [from 0 or 8] (default is 5 which means "classic GUI output"): make Minic more verbose for debug purpose (if set < 5). This option is often needed when using unsual things as evaluation tuning or command line analysis for instance in order to have full display of outputs. Here are the various level
logTrace = 0, logDebug = 1, logInfo = 2, logInfoPrio = 3, logWarn = 4, logGUI = 5, logError = 6, logFatal = 7, logOff = 8 - -debugMode [0 or 1] (default is 0 which means "false"): will write every output also in a file (named minic.debug by default)
- -debugFile [name_of_file] (default is minic.debug): name of the debug output file
- -ttSizeMb [number_in_Mb] (default is 128Mb, protocol option is "Hash"): force the size of the hash table. This is usefull for command line analysis mode for instance
- -threads [number_of_threads] (default is 1): force the number of threads used. This is usefull for command line analysis mode for instance
- -multiPV [from 1 to 4 ] (default is 1): search more lines at the same time
- -syzygyPath [path_to_egt_directory] (default is none): specify the path to syzygy end-game table directory
- -FRC [0 or 1] (default is 0, protocol option is "UCI_Chess960"): activate Fisher random chess mode. This is usefull for command line analysis mode for instance
- -NNUEFile [path_to_neural_network_file] (default is none): specify the neural network (NNUE) to be used and activate NNUE evaluation
- -forceNNUE [0 or 1] (default is false): if a NNUEFile is loaded, forceNNUE equal true will results in a pure NNUE evaluation, while the default is hybrid evaluation
Remark for Windows users : it may be quite difficult to get the path format for the NNUE file ok under Windows. Here is a working example (thanks to Stefan Pohl) for cutechess-cli as a guide:
cutechess-cli.exe -engine name="Minic3.06NoNa" cmd="C:/Engines/Minic/minic_3.06_mingw_x64_nehalem.exe" dir="C:/Engines/Minic" option.NNUEFile=C:/Engines/Minic/nocturnal_nadir.bin option.Hash=256 option.Threads=1 proto=uci
Starting from Minic 3.07, no need to worry about this, the official corresponding net is embeded inside the binary using the INCBIN technology.
Minic strength can be ajdusted using the level option (from command line or using protocol option support, using value from 0 to 100). Level 0 is a random mover, 1 to 30 very weak, ..., level 100 is full strength. For now it uses multipv, maximum depth adjustment and randomness to make Minic play weaker moves (also a fixed node option is available to avoid randomness if needed).
Current level Elo are more or less so that even a beginner can beat low levels Minic. From level 50 or 60, you will start to struggle more! You can also use the UCI_Elo parameter if UCI_LimitStrenght is activated but the Elo fit is not good especially at low level. Level functionnaly will be enhanced in a near future.
Please also note that is nodesBasedLevel is activated, then no randomness is used to decrease Elo level of Minic, only number of nodes searched is changing.
- -level [from 0 to 100] (default is 100): change Minic skill level
- -limitStrength [0 or 1] (default is 0): take or not strength limitation into account
- -strength [Elo_like_number] (default is 1500): specify a Elo-like strength (not really well scaled for now ...)
- -nodesBasedLevel [ 0 or 1 ] (default is 0): switch to node based only level (no randomness)
- -randomPly [0 to 20 ] (default is 0): usefull when creating training data, play this number of total random ply at the begining of the game
- -randomOpen [from 0 to 100 ] (default is 0): value in cp that allows to add randomness for ply <10. Usefull when no book is used
There are multiple ways of generating sfen data with Minic.
- First is classic play at fixed depth to generate pgn (I am using cutechess for this). Then use convert this way
pgn-extract --fencomments -Wlalg --nochecks --nomovenumbers --noresults -w500000 -N -V -o data.plain games.pgn
Then use Minic -pgn2bin option to get a binary format sfen file. Note than position without score won't be taken into account.
-
Use Minic random mover (level = 0) and play tons of random games activating the genFen option and setting the depth of search you like with genFenDepth. This will generate a "plain" format sfen file with game results always being 0, so you will use this with lambda=1 in your trainer to be sure to don't take game outcome into account. What you will get is some genfen_XXXXXX files (one for each Minic processus, note that with cutechess if only 2 engines are playing, only 2 process will run and been reused). Those files will be in workdir directory of the engine and are in "plain" format. So after that use Minic -plain2bin on that file to get a "binary" file. Minic will generate only quiet positions (at qsearch leaf).
-
Use Minic "selfplay genfen" facility. In this case again, note that game result will always be draw because the file is written on the fly not at the end of the game. Again here you will obtain genfen_XXXXXX files. Minic will generate only quiet positions (at qsearch leaf).Data generation for learning process
-
-genFen [ 0 or 1 ] (default is 0): activate sfen generation
-
-genFenDepth [ 2 to 20] (default is 8): specify depth of search for sfen generation
-
-genFenDepthEG [ 2 to 20] (default is 12): specify depth of search in end-game for sfen generation
- -mateFinder [0 or 1] (default is 0): activate mate finder mode, which essentially means no forward pruning
- -fullXboardOutput [0 or 1] (default is 0): activate additionnal output for Xboard protocol such as nps or tthit
- -withWDL [0 or 1] (default is 0, protocol option is "WDL_display"): activate Win-Draw-Loss output. Converting score to WDL is done based on a fit perform on all recent Minic's game from main rating lists.
- -moveOverHead [ 10 to 1000 ] (default is 50): time in milliseconds to keep as a security buffer
- -armageddon [ 0 or 1 ] (default 0): play taking into account Armageddon mode (Black draw is a win)
- -UCI_Opponent [ title rating type name ] (default empty): often a string like "none 3234 computer Opponent X.YY". Minic can take this information into account to adapt its contempt value to the opponent strength
- -UCI_RatingAdv [ -10000 10000 ] (default not used): if received, Minic will use this value to adapt its contempt value to this rating advantage.
Moreover, Minic implements some "style" parameters when using HCE (hand crafted evalaution in opposition to NNUE) that allow the user to boost or minimize effects of :
- material
- attack
- development
- mobility
- positional play
- forwardness
- complexity (not yet implemented)
Default values are 50 and a range from 0 to 100 can be used. A value of 100 will double the effect, while a value of 0 will disable the feature (it is probably not a good idea to put material awareness to 0 for instance ...).
Minic on youtube, most often loosing to stronger engines ;-) :
- https://www.youtube.com/watch?v=fPBtZ7VTBnQ
- https://www.youtube.com/watch?v=juxxpN64Qcw
- https://www.youtube.com/watch?v=jb3BifP8abA
- https://www.youtube.com/watch?v=mrY4tTujC4g
- https://www.youtube.com/watch?v=_6vbzpCTFyM
- https://www.youtube.com/watch?v=EmWN79hHpZo
- https://www.youtube.com/watch?v=Ub3ug-TYJz0
- https://www.youtube.com/watch?v=w1RtRFXlf9E
- https://www.youtube.com/watch?v=wlzKxeHtKBo
- https://www.youtube.com/watch?v=04A9Qb6D-Xs
- https://www.youtube.com/watch?v=9qvs7paQRtw
- https://www.youtube.com/watch?v=JQdSmXhcpA4
- https://www.youtube.com/watch?v=HvuFOM_wX2k
- https://www.youtube.com/watch?v=RXui0aH-Mxo
- https://www.youtube.com/watch?v=umgEDThmVxY
- https://www.youtube.com/watch?v=xmmakWtLdIU
- https://www.youtube.com/watch?v=pV4AJRlsxkc
- https://www.youtube.com/watch?v=CntLrEGIuBI
- https://www.youtube.com/watch?v=gQraJtAy5bM
- https://www.youtube.com/watch?v=Lb2mWB3nBB4
- https://www.youtube.com/shorts/l35q9S7Xstg
- https://www.youtube.com/watch?v=ZUbMOMX0pp8
- https://www.youtube.com/watch?v=_VT_0DszLz0
- https://www.youtube.com/watch?v=in2snklUbyI
- https://www.youtube.com/watch?v=v5ab9dZrqTw
- https://www.youtube.com/watch?v=eLkaPFogTXg
- https://www.youtube.com/shorts/l35q9S7Xstg
- https://www.youtube.com/watch?v=cl1xaTnjwJw
- https://www.youtube.com/watch?v=in2snklUbyI
- https://www.youtube.com/watch?v=fwdBVOa3-QA
- https://www.youtube.com/watch?v=Keb18-nF1Vk
- https://www.youtube.com/watch?v=hsFOpD9tL7A
GM Matthew Sadler (Silicon Road youtube channel) game analysis
- https://www.youtube.com/watch?v=9p_jaqHA3QM
- https://www.youtube.com/watch?v=yTZuNEV40X4
- https://www.youtube.com/watch?v=3ttQaGKMAy4
- https://www.youtube.com/watch?v=lGYqW32iMD8
- https://www.youtube.com/watch?v=QT9yz1x0_84
- https://www.youtube.com/watch?v=-GxZRu0GHnQ
Of course many/most idea in Minic are taken from the beautifull chess developer community. Here's a very incomplete list of open-source engines that were inspiring for me:
Arasan by Jon Dart
Berserk by Jay Honnold
CPW by Pawel Koziol and Edmund Moshammer
Deepov by Romain Goussault
Defenchess by Can Cetin and Dogac Eldenk
Demolito by Lucas Braesch
Dorpsgek by Dan Ravensloft
Ethereal by Andrew Grant
Galjoen by Werner Taelemans
Koivisto by Kim Kåhre and Finn Eggers
Madchess by Erik Madsen
Rodent by Pawel Koziol
RubiChess by Andreas Matthies
Seer by Connor McMonigle
Stockfish by the stockfish contributors (https://github.com/official-stockfish/Stockfish/blob/master/AUTHORS)
Texel by Peter Österlund
Topple by Vincent Tang
TSCP by Tom Kerrigan
Vajolet by Marco Belli
Vice by BlueFeverSoft
Weiss by Terje Kirstihagen
Winter by Jonathan Rosenthal
Xiphos by Milos Tatarevic
Zurichess by Alexandru Moșoi
Many thanks also to all testers for all those long time control tests, they really are valuable inputs in the chess engine development process.
Also thanks to TCEC and CCC for letting Minic participate to many event, it is fun to see Minic on such a great hardware.
Thanks to Karlson Pfannschmidt for the bayesian optimization chess-tuning-tools
And of course thanks to all the members of the talkchess forum and CPW, and to H.G. Muller and Joost Buijs for hosting the well-known friendly monthly tourney.
- Am I a chess player ?
- yes
- good one ?
- no (https://lichess.org/@/xr_a_y)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Minic
Similar Open Source Tools
Minic
Minic is a chess engine developed for learning about chess programming and modern C++. It is compatible with CECP and UCI protocols, making it usable in various software. Minic has evolved from a one-file code to a more classic C++ style, incorporating features like evaluation tuning, perft, tests, and more. It has integrated NNUE frameworks from Stockfish and Seer implementations to enhance its strength. Minic is currently ranked among the top engines with an Elo rating around 3400 at CCRL scale.
simple_GRPO
simple_GRPO is a very simple implementation of the GRPO algorithm for reproducing r1-like LLM thinking. It provides a codebase that supports saving GPU memory, understanding RL processes, trying various improvements like multi-answer generation, regrouping, penalty on KL, and parameter tuning. The project focuses on simplicity, performance, and core loss calculation based on Hugging Face's trl. It offers a straightforward setup with minimal dependencies and efficient training on multiple GPUs.
tetris-ai
A bot that plays Tetris using deep reinforcement learning. The agent learns to play by training itself with a neural network and Q Learning algorithm. It explores different 'paths' to achieve higher scores and makes decisions based on predicted scores for possible moves. The game state includes attributes like lines cleared, holes, bumpiness, and total height. The agent is implemented in Python using Keras framework with a deep neural network structure. Training involves a replay queue, random sampling, and optimization techniques. Results show the agent's progress in achieving higher scores over episodes.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.
LangBridge
LangBridge is a tool that bridges mT5 encoder and the target LM together using only English data. It enables models to effectively solve multilingual reasoning tasks without the need for multilingual supervision. The tool provides pretrained models like Orca 2, MetaMath, Code Llama, Llemma, and Llama 2 for various instruction-tuned and not instruction-tuned scenarios. Users can install the tool to replicate evaluations from the paper and utilize the models for multilingual reasoning tasks. LangBridge is particularly useful for low-resource languages and may lower performance in languages where the language model is already proficient.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
parsee-core
Parsee AI is a high-level open source data extraction and structuring framework specialized for the extraction of data from a financial domain, but can be used for other use-cases as well. It aims to make the structuring of data from unstructured sources like PDFs, HTML files, and images as easy as possible. Parsee can be used locally in Python environments or through a hosted version for cloud-based jobs. It supports the extraction of tables, numbers, and other data elements, with the ability to create custom extraction templates and run jobs using different models.

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.
sunone_aimbot
Sunone Aimbot is an AI-powered aim bot for first-person shooter games. It leverages YOLOv8 and YOLOv10 models, PyTorch, and various tools to automatically target and aim at enemies within the game. The AI model has been trained on more than 30,000 images from popular first-person shooter games like Warface, Destiny 2, Battlefield 2042, CS:GO, Fortnite, The Finals, CS2, and more. The aimbot can be configured through the `config.ini` file to adjust various settings related to object search, capture methods, aiming behavior, hotkeys, mouse settings, shooting options, Arduino integration, AI model parameters, overlay display, debug window, and more. Users are advised to follow specific recommendations to optimize performance and avoid potential issues while using the aimbot.

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!
cameratrapai
SpeciesNet is an ensemble of AI models designed for classifying wildlife in camera trap images. It consists of an object detector that finds objects of interest in wildlife camera images and an image classifier that classifies those objects to the species level. The ensemble combines these two models using heuristics and geographic information to assign each image to a single category. The models have been trained on a large dataset of camera trap images and are used for species recognition in the Wildlife Insights platform.
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.
For similar tasks
Minic
Minic is a chess engine developed for learning about chess programming and modern C++. It is compatible with CECP and UCI protocols, making it usable in various software. Minic has evolved from a one-file code to a more classic C++ style, incorporating features like evaluation tuning, perft, tests, and more. It has integrated NNUE frameworks from Stockfish and Seer implementations to enhance its strength. Minic is currently ranked among the top engines with an Elo rating around 3400 at CCRL scale.
Caissa
Caissa is a strong, UCI command-line chess engine optimized for regular chess, FRC, and DFRC. It features its own neural network trained with self-play games, supports various UCI options, and provides different EXE versions for different CPU architectures. The engine uses advanced search algorithms, neural network evaluation, and endgame tablebases. It offers outstanding performance in ultra-short games and is written in C++ with modules for backend, frontend, and utilities like neural network trainer and self-play data generator.
eleeye
ElephantEye is a free Chinese Chess program that follows the GNU Lesser General Public Licence. It is designed for chess enthusiasts and programmers to use freely. The program works as a XiangQi engine for XQWizard with strong AI capabilities. ElephantEye supports UCCI 3.0 protocol and offers various parameter settings for users to customize their experience. The program uses brute-force chess algorithms and static position evaluation techniques to search for optimal moves. ElephantEye has participated in computer chess competitions and has been tested on various online chess platforms. The source code of ElephantEye is available on SourceForge for developers to explore and improve.
Kolo
Kolo is a lightweight tool for fast and efficient data generation, fine-tuning, and testing of Large Language Models (LLMs) on your local machine. It simplifies the fine-tuning and data generation process, runs locally without the need for cloud-based services, and supports popular LLM toolkits. Kolo is built using tools like Unsloth, Torchtune, Llama.cpp, Ollama, Docker, and Open WebUI. It requires Windows 10 OS or higher, Nvidia GPU with CUDA 12.1 capability, and 8GB+ VRAM, and 16GB+ system RAM. Users can join the Discord group for issues or feedback. The tool provides easy setup, training data generation, and integration with major LLM frameworks.
llm-data-scrapers
LLM Data Scrapers is a collection of open source tools and scrapers designed to gather data for Large Language Models (LLMs). The repository includes various tools such as gitingest for extracting codebases, repomix for packing repositories into AI-friendly files, llm-scraper for converting webpages into structured data, crawl4ai for web crawling, and firecrawl for turning websites into LLM-ready markdown or structured data. Additionally, the repository offers tools like llmstxt-generator for generating training data, trafilatura for gathering web text and metadata, RepoToTextForLLMs for fetching repo content, marker for converting PDFs, reader for converting URLs to LLM-friendly inputs, and files-to-prompt for concatenating files into prompts for LLMs.
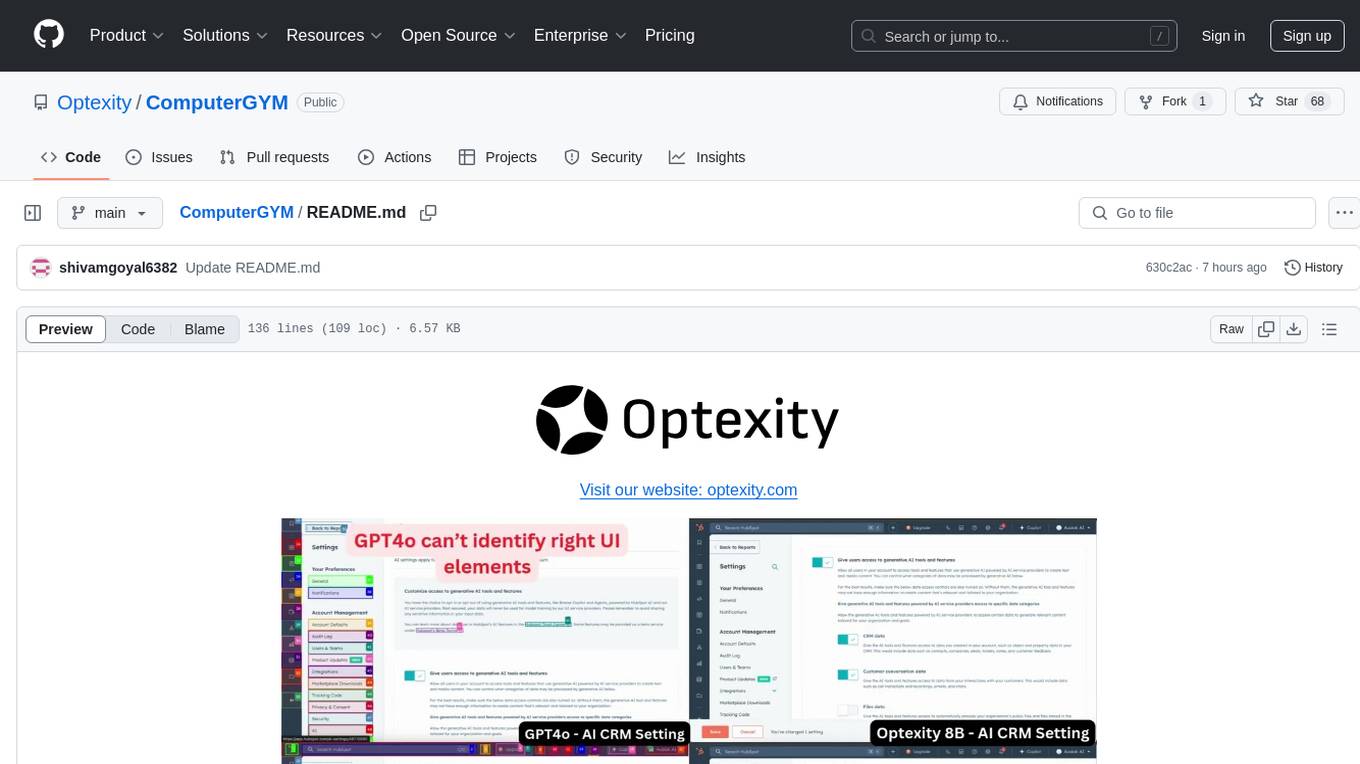
ComputerGYM
Optexity is a framework for training foundation models using human demonstrations of computer tasks. It enables recording, processing, and utilizing demonstrations to train AI agents for web-based tasks. The tool also plans to incorporate training through self-exploration, software documentations, and YouTube videos in the future.
speculators
Speculators is a unified library for building, training, and storing speculative decoding algorithms for large language model (LLM) inference. It speeds up LLM inference by using a smaller, faster draft model (the speculator) to propose tokens, which are then verified by the larger base model, reducing latency without compromising output quality. Trained models can seamlessly run in vLLM, enabling the deployment of speculative decoding in production-grade inference servers.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.