
Dataset
News: the 10k dataset is ready for download.
Stars: 279
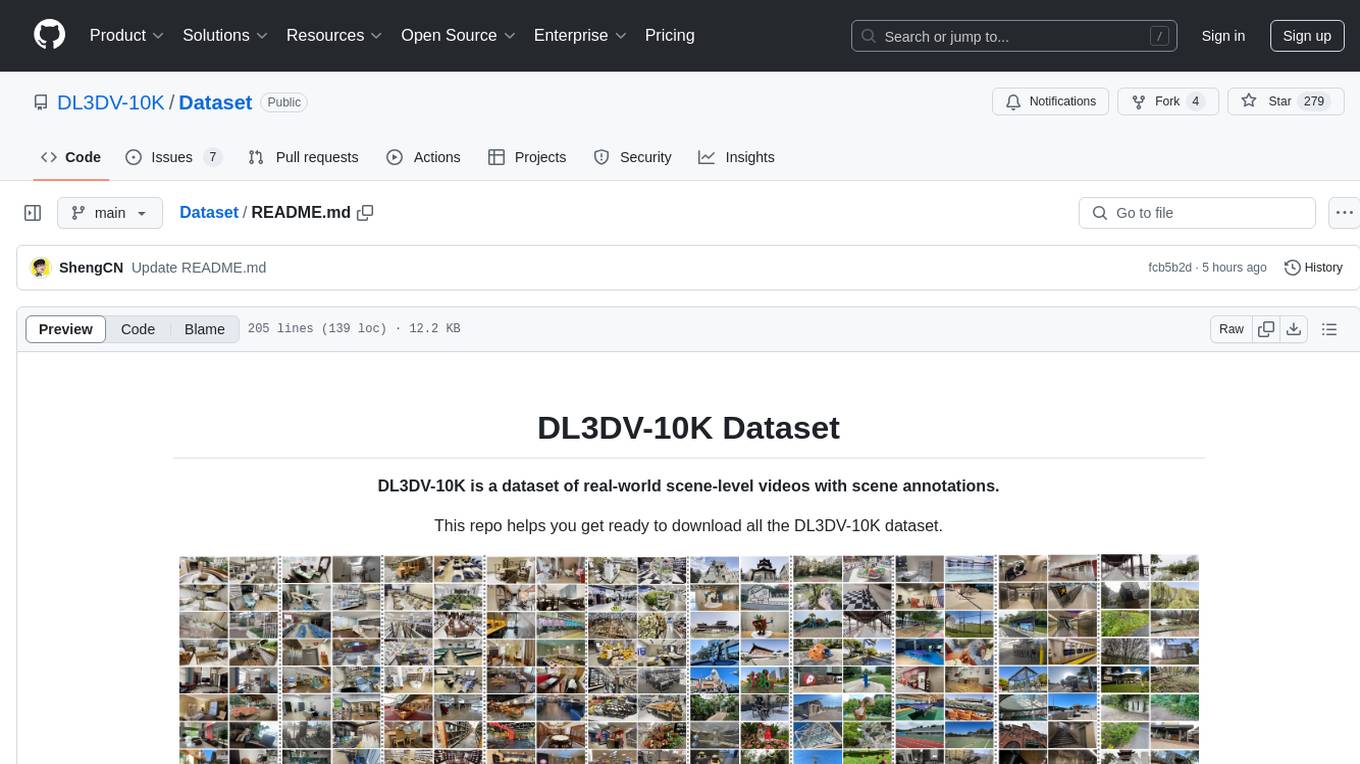
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.
README:
DL3DV-10K is a dataset of real-world scene-level videos with scene annotations.
This repo helps you get ready to download all the DL3DV-10K dataset.

Dataset Download • Website • NVS Benchmark Training Results • Data Preparation • License • Issues • BibTex
We have witnessed significant progress in deep learning-based 3D vision, ranging from neural radiance field (NeRF) based 3D representation learning to applications in novel view synthesis (NVS). However, existing scene-level datasets for deep learning-based 3D vision, limited to either synthetic environments or a narrow selection of real-world scenes, are quite insufficient. This insufficiency not only hinders a comprehensive benchmark of existing methods but also caps what could be explored in deep learning-based 3D analysis. To address this critical gap, we present DL3DV-10K, a large-scale scene dataset, featuring 51.2 million frames from 10,510 videos captured from 65 types of point-of-interest (POI) locations, covering both bounded and unbounded scenes, with different levels of reflection, transparency, and lighting. We conducted a comprehensive benchmark of recent NVS methods on DL3DV-10K, which revealed valuable insights for future research in NVS. In addition, we have obtained encouraging results in a pilot study to learn generalizable NeRF from DL3DV-10K, which manifests the necessity of a large-scale scene-level dataset to forge a path toward a foundation model for learning 3D representation.
- 10,510 multi-view scenes covering 51.2 million frames at 4k resolution.
- 140 videos as Novel view synthesis (NVS) benchmark.
- All videos are annotated by scene environment (indoor vs. outdoor), levels of reflection, transparency, and lighting.
- Released samples include colmap calculated camera pose.
- Benchmark videos offer trained parameters from the SOTA NVS methods, including 3D Gaussian Splatting, ZipNeRF, Mip-NeRF 360, Instant-NGP, and Nerfacto.
We report the performances of the main STOA methods (2023 Fall) on our large-scale NVS benchmark. Here are the quantitative results. Please refer to our paper for more details (e.g. more quantitative and qualitative results.)

Performance on the benchmark. The error metric is calculated from the mean of 140 scenes on a scale factor of 4. Zip-NeRF uses the default batch size (65536) and Zip-NeRF* uses the identical batch size as other methods (4096). Note, the training time and memory usage may be different depending on various configurations.

A presents the density plot of PSNR and SSIM and their relationship on \benchmark~for each method. B describes the performance comparison by scene complexity. The text above the bar plot is the mean value of the methods on the attribute.

DL3DV-10K has more than 10K high-quality videos that cover diverse real-world scenes for 3D vision tasks.
We have formulated the following requirements as guidelines for recording high-quality scene-level videos:

- The scene coverage is in the circle or half-circle with a 30 secs-45 secs walking diameter and has at least five instances with a natural arrangement.
- The default focal length of the camera corresponds to the 0.5x ultra-wide mode for capturing a wide range of background information.
- Each video has a horizontal view of at least 180◦ or 360◦ from different heights, including overhead and waist. It offers high-density views of objects within the coverage area.
- The video resolution should be 4K and have 60 fps (or 30 fps).
- The video's length should be at least 60 secs for mobile phone capture and 45 secs for drone video recording.
- We recommend limiting the duration of moving objects in the video to under 3 secs, with a maximum allowance of 10 secs.
- The frames should not be motion-blurred or overexposed, and the captured objects should be stereoscopic.
We provide a preview page here. The preview page has a snapshot of each scene, its hash code and labels. Some of the missing labels should be updated soon.
-
[x] Free download sample videos (11 scenes)
- [x] Access here
-
[ ] Benchmark dataset release (140 scenes)
- [x] Raw videos
- [x] Benchmark images, camera pose (Ready for download)
- The user requests here.
- We provide both Nerfstudio and 3D Gaussian Splatting formats for benchmark scenes.
- [ ] Benchmark trained weights for 3D Gaussian Splatting, ZipNeRF, Mip-NeRF 360, Instant NGP, and Nerfacto ( Coming soon)
-
[X] 10K Full Dataset Release: The whole dataset is extremly large. Here are different versions for different needs.
- 480P resolution frames with poses (~730G). Dataset link.
- 960P resolution frames with poses (~2.8T).Dataset link.
- 2K resolution frames with poses (~11T). Dataset link.
- 4K resolution frames with poses (~44T). Dataset link.
- 4K videos (~7T). Dataset link.
- COLMAP cache folders (may be useful if you need post-processing based on those cach). Dataset link.
Please go to the relevant huggingface dataset page and request the access. If you request the access, you automatically sign our term of use and license and can access the dataset. Note, the latest license is open to the usage of the dataset. But it is the user's responsibility to keep the use appropriately. The DL3DV organization disclaims any responsibility for the misuse, inappropriate use, or unethical application of the dataset by individuals or entities who download or access it. More details can be found in our license.
If you have enough space, you can use git to download a dataset from huggingface. See this link. 480P/960P versions should satisfies most needs.
If you do not have enough space, we further provide a download script here to download a subset. First make sure you have applied for the access (See above). To set up the environment for the script, call this in your python virtual environment:
pip install huggingface_hub tqdm pandasThe usage for the download.py:
usage: download.py [-h] --odir ODIR --subset {1K,2K,3K,4K,5K,6K,7K,8K,9K,10K} --resolution {4K,2K,960P,480P} --file_type {images+poses,video,colmap_cache} [--hash HASH]
[--clean_cache]
optional arguments:
-h, --help show this help message and exit
--odir ODIR output directory
--subset {1K,2K,3K,4K,5K,6K,7K,8K,9K,10K}
The subset of the benchmark to download
--resolution {4K,2K,960P,480P}
The resolution to donwnload
--file_type {images+poses,video,colmap_cache}
The file type to download
--hash HASH If set subset=hash, this is the hash code of the scene to download
--clean_cache If set, will clean the huggingface cache to save spaceHere are some examples:
# Make sure you have applied for the access.
# Use this to download the download.py script
wget https://raw.githubusercontent.com/DL3DV-10K/Dataset/main/scripts/download.py
# Download 480P resolution images and poses, 0~1K subset, output to DL3DV-10K directory
python download.py --odir DL3DV-10K --subset 1K --resolution 480P --file_type images+poses --clean_cache
# Download 960P resolution images and poses, 0~1K subset, output to DL3DV-10K directory
python download.py --odir DL3DV-10K --subset 1K --resolution 960P --file_type images+poses --clean_cache
# Download 2K resolution images and poses, 0~1K subset, output to DL3DV-10K directory
python download.py --odir DL3DV-10K --subset 1K --resolution 2K --file_type images+poses --clean_cache
# Download 4K resolution images and poses, 0~1K subset, output to DL3DV-10K directory
python download.py --odir DL3DV-10K --subset 1K --resolution 4K --file_type images+poses --clean_cache
# Download 4K resolution videos, 0~1K subset, output to DL3DV-10K directory
python download.py --odir DL3DV-10K --subset 1K --resolution 4K --file_type video --clean_cache
# Download 480P resolution images and poses, 1K~2K subset, output to DL3DV-10K directory
python download.py --odir DL3DV-10K --subset 2K --resolution 480P --file_type images+poses --clean_cacheDL3DV-10K is released under the DL3DV-10K Terms of Use. The DL3DV-10K Terms of Use, disclaimer, and the copy of the license are available in this repository.
Copyright (c) 2024
Despite our best efforts to anonymize data, there may be instances where sensitive details are inadvertently included. If you identify any such issues within the dataset (scenes), don't hesitate to get in touch with us at issue. We will manually redact any sensitive information to ensure the privacy and integrity of the dataset.
Want to contribute the DL3DV-10K dataset? Upload your video here.
The DL3DV-10K team is a non-profit organization with members inlcuding the authors of DL3DV-10K paper and volunteers who contribute to the dataset. Our mission is to make large-scale of deep learning models and datasets available to the general public.
If you found this dataset useful, please cite our paper.
@inproceedings{ling2024dl3dv,
title={Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision},
author={Ling, Lu and Sheng, Yichen and Tu, Zhi and Zhao, Wentian and Xin, Cheng and Wan, Kun and Yu, Lantao and Guo, Qianyu and Yu, Zixun and Lu, Yawen and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={22160--22169},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Dataset
Similar Open Source Tools
Dataset
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
DataFrame
DataFrame is a C++ analytical library designed for data analysis similar to libraries in Python and R. It allows you to slice, join, merge, group-by, and perform various statistical, summarization, financial, and ML algorithms on your data. DataFrame also includes a large collection of analytical algorithms in form of visitors, ranging from basic stats to more involved analysis. You can easily add your own algorithms as well. DataFrame employs extensive multithreading in almost all its APIs, making it suitable for analyzing large datasets. Key principles followed in the library include supporting any type without needing new code, avoiding pointer chasing, having all column data in contiguous memory space, minimizing space usage, avoiding data copying, using multi-threading judiciously, and not protecting the user against garbage in, garbage out.

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.
BurstGPT
This repository provides a real-world trace dataset of LLM serving workloads for research and academic purposes. The dataset includes two files, BurstGPT.csv with trace data for 2 months including some failures, and BurstGPT_without_fails.csv without any failures. Users can scale the RPS in the trace, model patterns, and leverage the trace for various evaluations. Future plans include updating the time range of the trace, adding request end times, updating conversation logs, and open-sourcing a benchmark suite for LLM inference. The dataset covers 61 consecutive days, contains 1.4 million lines, and is approximately 50MB in size.
audioseal
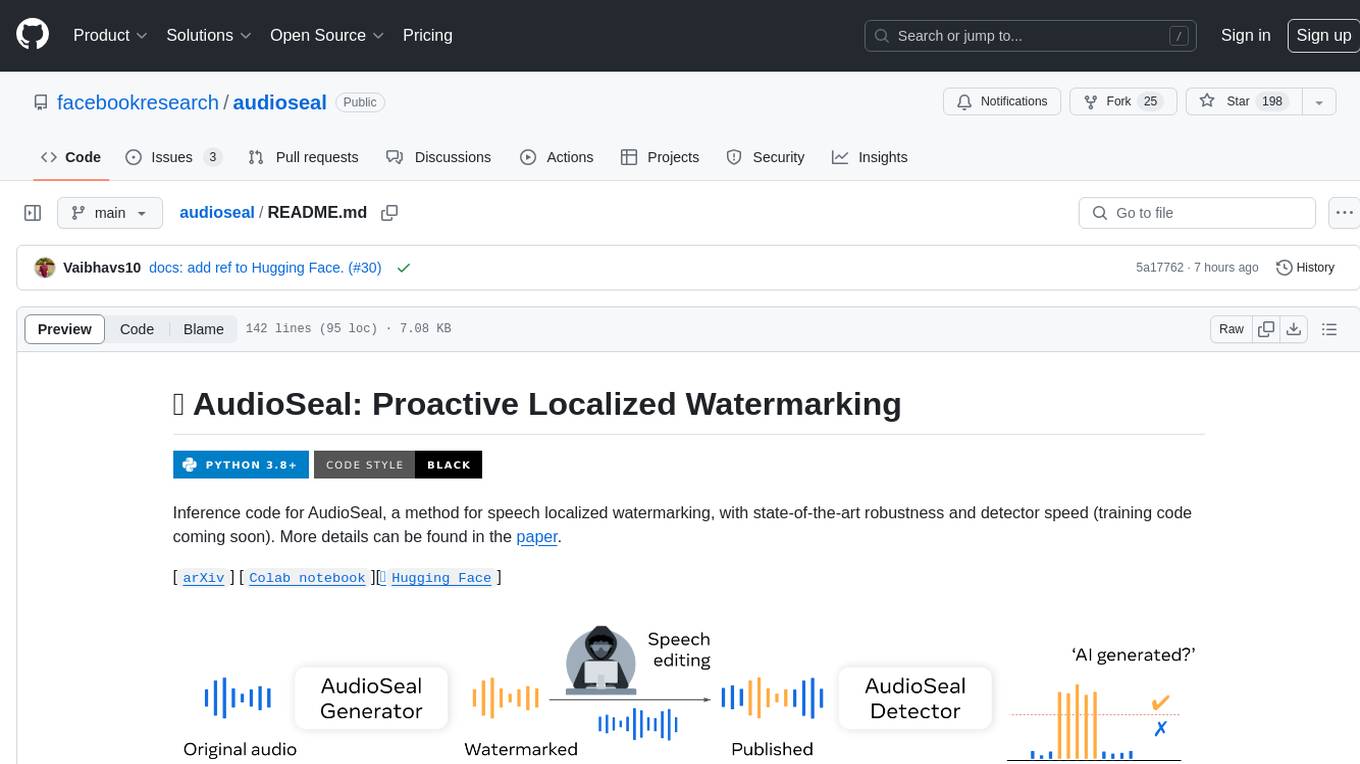
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.
feedgen
FeedGen is an open-source tool that uses Google Cloud's state-of-the-art Large Language Models (LLMs) to improve product titles, generate more comprehensive descriptions, and fill missing attributes in product feeds. It helps merchants and advertisers surface and fix quality issues in their feeds using Generative AI in a simple and configurable way. The tool relies on GCP's Vertex AI API to provide both zero-shot and few-shot inference capabilities on GCP's foundational LLMs. With few-shot prompting, users can customize the model's responses towards their own data, achieving higher quality and more consistent output. FeedGen is an Apps Script based application that runs as an HTML sidebar in Google Sheets, allowing users to optimize their feeds with ease.

NineRec
NineRec is a benchmark dataset suite for evaluating transferable recommendation models. It provides datasets for pre-training and transfer learning in recommender systems, focusing on multimodal and foundation model tasks. The dataset includes user-item interactions, item texts in multiple languages, item URLs, and raw images. Researchers can use NineRec to develop more effective and efficient methods for pre-training recommendation models beyond end-to-end training. The dataset is accompanied by code for dataset preparation, training, and testing in PyTorch environment.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.
For similar tasks
crossfire-yolo-TensorRT
This repository supports the YOLO series models and provides an AI auto-aiming tool based on YOLO-TensorRT for the game CrossFire. Users can refer to the provided link for compilation and running instructions. The tool includes functionalities for screenshot + inference, mouse movement, and smooth mouse movement. The next goal is to automatically set the optimal PID parameters on the local machine. Developers are welcome to contribute to the improvement of this tool.
Dataset
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.
AliceVision
AliceVision is a photogrammetric computer vision framework which provides a 3D reconstruction pipeline. It is designed to process images from different viewpoints and create detailed 3D models of objects or scenes. The framework includes various algorithms for feature detection, matching, and structure from motion. AliceVision is suitable for researchers, developers, and enthusiasts interested in computer vision, photogrammetry, and 3D modeling. It can be used for applications such as creating 3D models of buildings, archaeological sites, or objects for virtual reality and augmented reality experiences.
visual-reasoning-playground
AI-powered visual reasoning tools for broadcast, live streaming, and ProAV professionals. The Visual Reasoning Playground provides 17 ready-to-use tools demonstrating real-world applications of Vision Language Models (VLMs) using Moondream. From PTZ camera auto-tracking to multimodal audio+video automation, the tools offer functionalities like scene description, object detection, gesture control, smart counting, scene analysis, zone monitoring, color matching, multimodal fusion, smart photography, PTZ tracking, tracking comparison, scoreboard extraction, scoreboard OCR, framing assistance, PTZ color tuning, multimodal studio automation, voice triggers, and OBS plugin integration. The tools are designed to streamline tasks in live streaming, broadcast automation, camera control, content creation workflows, security monitoring, and more.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.