
TensorRT-Model-Optimizer
A unified library of state-of-the-art model optimization techniques like quantization, pruning, distillation, speculative decoding, etc. It compresses deep learning models for downstream deployment frameworks like TensorRT-LLM or TensorRT to optimize inference speed.
Stars: 1409

The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
README:


The NVIDIA TensorRT Model Optimizer (referred to as Model Optimizer, or ModelOpt) is a library comprising state-of-the-art model optimization techniques including quantization, distillation, pruning, speculative decoding and sparsity to accelerate models.
[Input] Model Optimizer currently supports inputs of a Hugging Face, PyTorch or ONNX model.
[Optimize] Model Optimizer provides Python APIs for users to easily compose the above model optimization techniques and export an optimized quantized checkpoint. Model Optimizer is also integrated with NVIDIA NeMo, Megatron-LM and Hugging Face Accelerate for training required inference optimization techniques.
[Export for deployment] Seamlessly integrated within the NVIDIA AI software ecosystem, the quantized checkpoint generated from Model Optimizer is ready for deployment in downstream inference frameworks like SGLang, TensorRT-LLM, TensorRT, or vLLM.
- [2025/09/17] An Introduction to Speculative Decoding for Reducing Latency in AI Inference
- [2025/09/11] How Quantization Aware Training Enables Low-Precision Accuracy Recovery
- [2025/08/29] Fine-Tuning gpt-oss for Accuracy and Performance with Quantization Aware Training
- [2025/08/01] Optimizing LLMs for Performance and Accuracy with Post-Training Quantization
- [2025/06/24] Introducing NVFP4 for Efficient and Accurate Low-Precision Inference
- [2025/05/14] NVIDIA TensorRT Unlocks FP4 Image Generation for NVIDIA Blackwell GeForce RTX 50 Series GPUs
- [2025/04/21] Adobe optimized deployment using TensorRT-Model-Optimizer + TensorRT leading to a 60% reduction in diffusion latency, a 40% reduction in total cost of ownership
- [2025/04/05] NVIDIA Accelerates Inference on Meta Llama 4 Scout and Maverick. Check out how to quantize Llama4 for deployment acceleration here
- [2025/03/18] World's Fastest DeepSeek-R1 Inference with Blackwell FP4 & Increasing Image Generation Efficiency on Blackwell
- [2025/02/25] Model Optimizer quantized NVFP4 models available on Hugging Face for download: DeepSeek-R1-FP4, Llama-3.3-70B-Instruct-FP4, Llama-3.1-405B-Instruct-FP4
- [2025/01/28] Model Optimizer has added support for NVFP4. Check out an example of NVFP4 PTQ here.
- [2025/01/28] Model Optimizer is now open source!
- [2024/10/23] Model Optimizer quantized FP8 Llama-3.1 Instruct models available on Hugging Face for download: 8B, 70B, 405B.
- [2024/09/10] Post-Training Quantization of LLMs with NVIDIA NeMo and TensorRT Model Optimizer.
Previous News
- [2024/08/28] Boosting Llama 3.1 405B Performance up to 44% with TensorRT Model Optimizer on NVIDIA H200 GPUs
- [2024/08/28] Up to 1.9X Higher Llama 3.1 Performance with Medusa
- [2024/08/15] New features in recent releases: Cache Diffusion, QLoRA workflow with NVIDIA NeMo, and more. Check out our blog for details.
- [2024/06/03] Model Optimizer now has an experimental feature to deploy to vLLM as part of our effort to support popular deployment frameworks. Check out the workflow here
- [2024/05/08] Announcement: Model Optimizer Now Formally Available to Further Accelerate GenAI Inference Performance
- [2024/03/27] Model Optimizer supercharges TensorRT-LLM to set MLPerf LLM inference records
- [2024/03/18] GTC Session: Optimize Generative AI Inference with Quantization in TensorRT-LLM and TensorRT
- [2024/03/07] Model Optimizer's 8-bit Post-Training Quantization enables TensorRT to accelerate Stable Diffusion to nearly 2x faster
- [2024/02/01] Speed up inference with Model Optimizer quantization techniques in TRT-LLM
To install stable release packages for Model Optimizer with pip from PyPI:
pip install -U nvidia-modelopt[all]To install from source in editable mode with all development dependencies or to use the latest features, run:
# Clone the Model Optimizer repository
git clone [email protected]:NVIDIA/TensorRT-Model-Optimizer.git
cd TensorRT-Model-Optimizer
pip install -e .[dev]You can also directly use the TensorRT-LLM docker images
(e.g., nvcr.io/nvidia/tensorrt-llm/release:<version>), which have Model Optimizer pre-installed.
Make sure to upgrade Model Optimizer to the latest version using pip as described above.
Visit our installation guide for
more fine-grained control on installed dependencies or for alternative docker images and environment variables to setup.
| Technique | Description | Examples | Docs |
|---|---|---|---|
| Post Training Quantization | Compress model size by 2x-4x, speeding up inference while preserving model quality! | [LLMs] [diffusers] [VLMs] [onnx] [windows] | [docs] |
| Quantization Aware Training | Refine accuracy even further with a few training steps! | [NeMo] [Hugging Face] | [docs] |
| Pruning | Reduce your model size and accelerate inference by removing unnecessary weights! | [PyTorch] | [docs] |
| Distillation | Reduce deployment model size by teaching small models to behave like larger models! | [NeMo] [Hugging Face] | [docs] |
| Speculative Decoding | Train draft modules to predict extra tokens during inference! | [Megatron] [Hugging Face] | [docs] |
| Sparsity | Efficiently compress your model by storing only its non-zero parameter values and their locations | [PyTorch] | [docs] |
- Ready-to-deploy checkpoints [🤗 Hugging Face - Nvidia TensorRT Model Optimizer Collection]
- Deployable on TensorRT-LLM, vLLM and SGLang
- More models coming soon!
| Model Type | Support Matrix |
|---|---|
| LLM Quantization | View Support Matrix |
| Diffusers Quantization | View Support Matrix |
| VLM Quantization | View Support Matrix |
| ONNX Quantization | View Support Matrix |
| Windows Quantization | View Support Matrix |
| Quantization Aware Training | View Support Matrix |
| Pruning | View Support Matrix |
| Distillation | View Support Matrix |
| Speculative Decoding | View Support Matrix |
Model Optimizer is now open source! We welcome any feedback, feature requests and PRs. Please read our Contributing guidelines for details on how to contribute to this project.
Happy optimizing!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for TensorRT-Model-Optimizer
Similar Open Source Tools
TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
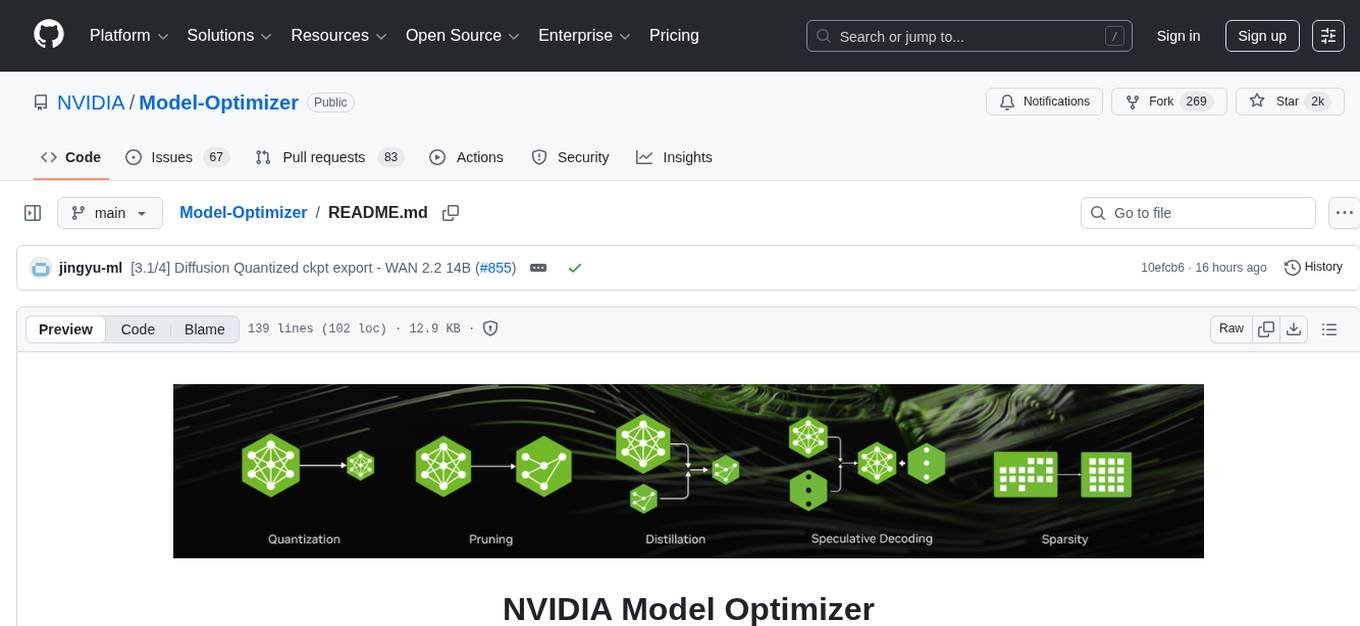
Model-Optimizer
NVIDIA Model Optimizer is a library that offers state-of-the-art model optimization techniques like quantization, distillation, pruning, speculative decoding, and sparsity to accelerate models. It supports inputs of Hugging Face, PyTorch, or ONNX models, provides Python APIs for easy composition of optimization techniques, and exports optimized quantized checkpoints. Integrated with NVIDIA Megatron-Bridge, Megatron-LM, and Hugging Face Accelerate for training required inference optimization techniques. The generated quantized checkpoint is ready for deployment in downstream inference frameworks like SGLang, TensorRT-LLM, TensorRT, or vLLM.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.

ERNIE
ERNIE 4.5 is a family of large-scale multimodal models with 10 distinct variants, including Mixture-of-Experts (MoE) models with 47B and 3B active parameters. The models feature a novel heterogeneous modality structure supporting parameter sharing across modalities while allowing dedicated parameters for each individual modality. Trained with optimal efficiency using PaddlePaddle deep learning framework, ERNIE 4.5 models achieve state-of-the-art performance across text and multimodal benchmarks, enhancing multimodal understanding without compromising performance on text-related tasks. The open-source development toolkits for ERNIE 4.5 offer industrial-grade capabilities, resource-efficient training and inference workflows, and multi-hardware compatibility.

ColossalAI
Colossal-AI is a deep learning system for large-scale parallel training. It provides a unified interface to scale sequential code of model training to distributed environments. Colossal-AI supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
efficient-transformers
Efficient Transformers Library provides reimplemented blocks of Large Language Models (LLMs) to make models functional and highly performant on Qualcomm Cloud AI 100. It includes graph transformations, handling for under-flows and overflows, patcher modules, exporter module, sample applications, and unit test templates. The library supports seamless inference on pre-trained LLMs with documentation for model optimization and deployment. Contributions and suggestions are welcome, with a focus on testing changes for model support and common utilities.
nncf
Neural Network Compression Framework (NNCF) provides a suite of post-training and training-time algorithms for optimizing inference of neural networks in OpenVINO™ with a minimal accuracy drop. It is designed to work with models from PyTorch, TorchFX, TensorFlow, ONNX, and OpenVINO™. NNCF offers samples demonstrating compression algorithms for various use cases and models, with the ability to add different compression algorithms easily. It supports GPU-accelerated layers, distributed training, and seamless combination of pruning, sparsity, and quantization algorithms. NNCF allows exporting compressed models to ONNX or TensorFlow formats for use with OpenVINO™ toolkit, and supports Accuracy-Aware model training pipelines via Adaptive Compression Level Training and Early Exit Training.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
SimAI
SimAI is the industry's first full-stack, high-precision simulator for AI large-scale training. It provides detailed modeling and simulation of the entire LLM training process, encompassing framework, collective communication, network layers, and more. This comprehensive approach offers end-to-end performance data, enabling researchers to analyze training process details, evaluate time consumption of AI tasks under specific conditions, and assess performance gains from various algorithmic optimizations.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

MiniCPM-V
MiniCPM-V is a series of end-side multimodal LLMs designed for vision-language understanding. The models take image and text inputs to provide high-quality text outputs. The series includes models like MiniCPM-Llama3-V 2.5 with 8B parameters surpassing proprietary models, and MiniCPM-V 2.0, a lighter model with 2B parameters. The models support over 30 languages, efficient deployment on end-side devices, and have strong OCR capabilities. They achieve state-of-the-art performance on various benchmarks and prevent hallucinations in text generation. The models can process high-resolution images efficiently and support multilingual capabilities.
For similar tasks

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.
TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
lightning-bolts
Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production. Users can accelerate Lightning training with the Torch ORT Callback to optimize ONNX graph for faster training & inference. Additionally, users can introduce sparsity with the SparseMLCallback to accelerate inference by leveraging the DeepSparse engine. Specific research implementations are encouraged, with contributions that help train SSL models and integrate with Lightning Flash for state-of-the-art models in applied research.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
For similar jobs
Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.

cl-waffe2
cl-waffe2 is an experimental deep learning framework in Common Lisp, providing fast, systematic, and customizable matrix operations, reverse mode tape-based Automatic Differentiation, and neural network model building and training features accelerated by a JIT Compiler. It offers abstraction layers, extensibility, inlining, graph-level optimization, visualization, debugging, systematic nodes, and symbolic differentiation. Users can easily write extensions and optimize their networks without overheads. The framework is designed to eliminate barriers between users and developers, allowing for easy customization and extension.
TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.