
lightning-bolts
Toolbox of models, callbacks, and datasets for AI/ML researchers.
Stars: 1656
Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production. Users can accelerate Lightning training with the Torch ORT Callback to optimize ONNX graph for faster training & inference. Additionally, users can introduce sparsity with the SparseMLCallback to accelerate inference by leveraging the DeepSparse engine. Specific research implementations are encouraged, with contributions that help train SSL models and integrate with Lightning Flash for state-of-the-art models in applied research.
README:
Deep Learning components for extending PyTorch Lightning
Installation • Latest Docs • Stable Docs • About • Community • Website • License

Pip / Conda
pip install lightning-boltsOther installations
Install bleeding-edge (no guarantees)
pip install https://github.com/Lightning-Universe/lightning-bolts/archive/refs/heads/master.zipTo install all optional dependencies
pip install lightning-bolts["extra"]Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production.
Torch ORT converts your model into an optimized ONNX graph, speeding up training & inference when using NVIDIA or AMD GPUs. See the documentation for more details.
from pytorch_lightning import LightningModule, Trainer
import torchvision.models as models
from pl_bolts.callbacks import ORTCallback
class VisionModel(LightningModule):
def __init__(self):
super().__init__()
self.model = models.vgg19_bn(pretrained=True)
...
model = VisionModel()
trainer = Trainer(gpus=1, callbacks=ORTCallback())
trainer.fit(model)We can introduce sparsity during fine-tuning with SparseML, which ultimately allows us to leverage the DeepSparse engine to see performance improvements at inference time.
from pytorch_lightning import LightningModule, Trainer
import torchvision.models as models
from pl_bolts.callbacks import SparseMLCallback
class VisionModel(LightningModule):
def __init__(self):
super().__init__()
self.model = models.vgg19_bn(pretrained=True)
...
model = VisionModel()
trainer = Trainer(gpus=1, callbacks=SparseMLCallback(recipe_path="recipe.yaml"))
trainer.fit(model)We'd like to encourage users to contribute general components that will help a broad range of problems; however, components that help specific domains will also be welcomed!
For example, a callback to help train SSL models would be a great contribution; however, the next greatest SSL model from your latest paper would be a good contribution to Lightning Flash.
Use Lightning Flash to train, predict and serve state-of-the-art models for applied research. We suggest looking at our VISSL Flash integration for SSL-based tasks.
Bolts is supported by the PyTorch Lightning team and the PyTorch Lightning community!
Join our Slack and/or read our CONTRIBUTING guidelines to get help becoming a contributor!
Please observe the Apache 2.0 license that is listed in this repository. In addition, the Lightning framework is Patent Pending.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for lightning-bolts
Similar Open Source Tools
lightning-bolts
Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production. Users can accelerate Lightning training with the Torch ORT Callback to optimize ONNX graph for faster training & inference. Additionally, users can introduce sparsity with the SparseMLCallback to accelerate inference by leveraging the DeepSparse engine. Specific research implementations are encouraged, with contributions that help train SSL models and integrate with Lightning Flash for state-of-the-art models in applied research.
moai
moai is a PyTorch-based AI Model Development Kit (MDK) designed to improve data-driven model workflows, design, and understanding. It offers modularity via monads for model building blocks, reproducibility via configuration-based design, productivity via a data-driven domain modelling language (DML), extensibility via plugins, and understanding via inter-model performance and design aggregation. The tool provides specific integrated actions like play, train, evaluate, plot, diff, and reprod to support heavy data-driven workflows with analytics, knowledge extraction, and reproduction. moai relies on PyTorch, Lightning, Hydra, TorchServe, ONNX, Visdom, HiPlot, Kornia, Albumentations, and the wider open-source community for its functionalities.
gigax
Gigax is a tool for creating and controlling Non-Player Characters (NPCs) powered by Large Language Models (LLMs). It allows users to define actions for NPCs such as speaking, jumping, and attacking, with quick GPU inference times. The tool provides access to open-weights models fine-tuned from Llama-3, Phi-3, Mistral, and more. Users can generate structured content with outlines, ensuring the output format is always respected. Gigax is continuously evolving with upcoming features like local server mode and API support for runtime quest generation and memory management. It offers various models on the Huggingface hub for instantiating NPCs and provides classes for handling locations, characters, items, and events.

slideflow
Slideflow is a deep learning library for digital pathology, offering a user-friendly interface for model development. It is designed for medical researchers and AI enthusiasts, providing an accessible platform for developing state-of-the-art pathology models. Slideflow offers customizable training pipelines, robust slide processing and stain normalization toolkit, support for weakly-supervised or strongly-supervised labels, built-in foundation models, multiple-instance learning, self-supervised learning, generative adversarial networks, explainability tools, layer activation analysis tools, uncertainty quantification, interactive user interface for model deployment, and more. It supports both PyTorch and Tensorflow, with optional support for Libvips for slide reading. Slideflow can be installed via pip, Docker container, or from source, and includes non-commercial add-ons for additional tools and pretrained models. It allows users to create projects, extract tiles from slides, train models, and provides evaluation tools like heatmaps and mosaic maps.
ai-toolkit
The AI Toolkit by Ostris is a collection of tools for machine learning, specifically designed for image generation, LoRA (latent representations of attributes) extraction and manipulation, and model training. It provides a user-friendly interface and extensive documentation to make it accessible to both developers and non-developers. The toolkit is actively under development, with new features and improvements being added regularly. Some of the key features of the AI Toolkit include: - Batch Image Generation: Allows users to generate a batch of images based on prompts or text files, using a configuration file to specify the desired settings. - LoRA (lierla), LoCON (LyCORIS) Extractor: Facilitates the extraction of LoRA and LoCON representations from pre-trained models, enabling users to modify and manipulate these representations for various purposes. - LoRA Rescale: Provides a tool to rescale LoRA weights, allowing users to adjust the influence of specific attributes in the generated images. - LoRA Slider Trainer: Enables the training of LoRA sliders, which can be used to control and adjust specific attributes in the generated images, offering a powerful tool for fine-tuning and customization. - Extensions: Supports the creation and sharing of custom extensions, allowing users to extend the functionality of the toolkit with their own tools and scripts. - VAE (Variational Auto Encoder) Trainer: Facilitates the training of VAEs for image generation, providing users with a tool to explore and improve the quality of generated images. The AI Toolkit is a valuable resource for anyone interested in exploring and utilizing machine learning for image generation and manipulation. Its user-friendly interface, extensive documentation, and active development make it an accessible and powerful tool for both beginners and experienced users.
omnihuman
OmniHuman is an AI model designed to understand humanoids and text. It provides functionalities to process images and videos, generating text descriptions for human actions depicted in the visual content. The tool offers support for various tasks related to human pose recognition and action understanding. Users can easily integrate OmniHuman into their projects to enhance the capabilities of their applications in recognizing and interpreting human actions in images and videos.
node-llama-cpp
node-llama-cpp is a tool that allows users to run AI models locally on their machines. It provides pre-built bindings with the option to build from source using cmake. Users can interact with text generation models, chat with models using a chat wrapper, and force models to generate output in a parseable format like JSON. The tool supports Metal and CUDA, offers CLI functionality for chatting with models without coding, and ensures up-to-date compatibility with the latest version of llama.cpp. Installation includes pre-built binaries for macOS, Linux, and Windows, with the option to build from source if binaries are not available for the platform.
fastserve-ai
FastServe-AI is a machine learning serving tool focused on GenAI & LLMs with simplicity as the top priority. It allows users to easily serve custom models by implementing the 'handle' method for 'FastServe'. The tool provides a FastAPI server for custom models and can be deployed using Lightning AI Studio. Users can install FastServe-AI via pip and run it to serve their own GPT-like LLM models in minutes.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐

starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.
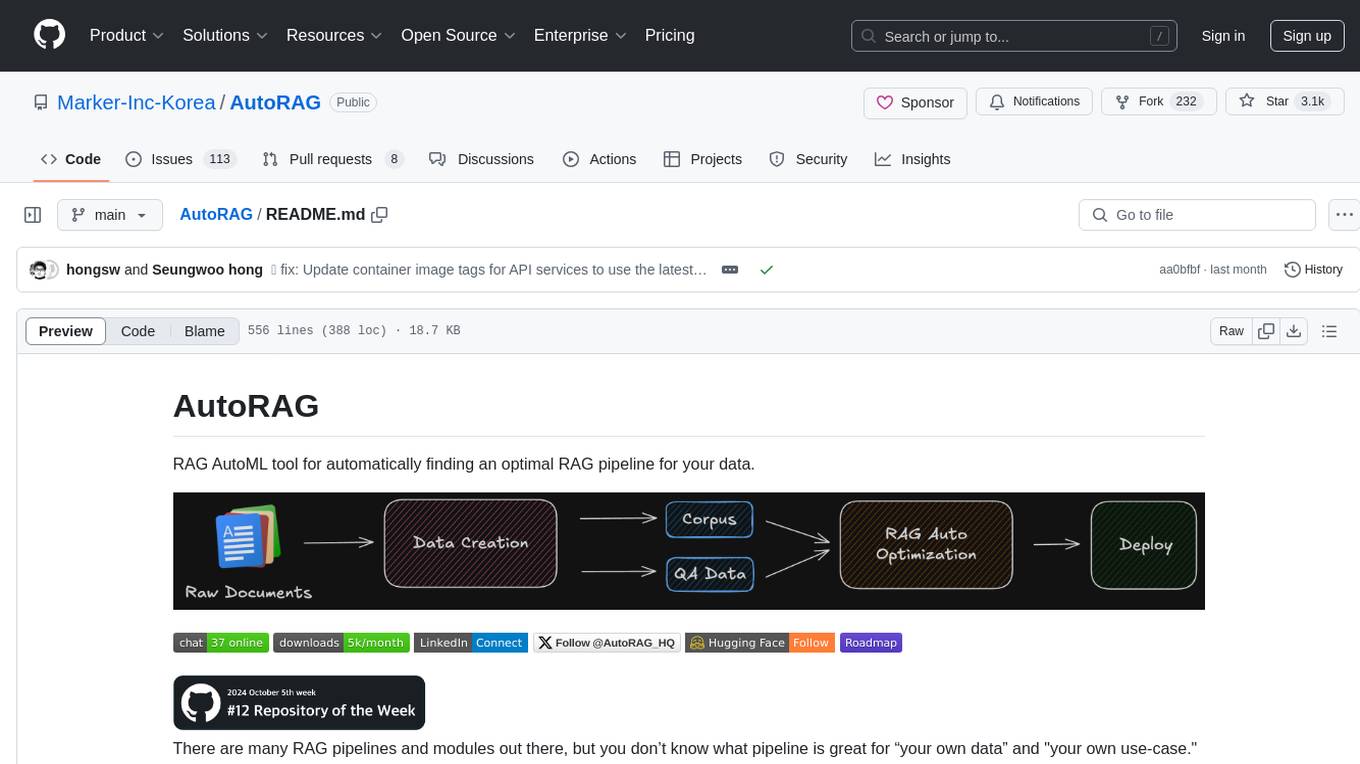
AutoRAG
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.
incubator-kie-optaplanner
A fast, easy-to-use, open source AI constraint solver for software developers. OptaPlanner is a powerful tool that helps developers solve complex optimization problems by providing a constraint satisfaction solver. It allows users to model and solve planning and scheduling problems efficiently, improving decision-making processes and resource allocation. With OptaPlanner, developers can easily integrate optimization capabilities into their applications, leading to better performance and cost-effectiveness.

obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.
catai
CatAI is a tool that allows users to run GGUF models on their computer with a chat UI. It serves as a local AI assistant inspired by Node-Llama-Cpp and Llama.cpp. The tool provides features such as auto-detecting programming language, showing original messages by clicking on user icons, real-time text streaming, and fast model downloads. Users can interact with the tool through a CLI that supports commands for installing, listing, setting, serving, updating, and removing models. CatAI is cross-platform and supports Windows, Linux, and Mac. It utilizes node-llama-cpp and offers a simple API for asking model questions. Additionally, developers can integrate the tool with node-llama-cpp@beta for model management and chatting. The configuration can be edited via the web UI, and contributions to the project are welcome. The tool is licensed under Llama.cpp's license.

DB-GPT
DB-GPT is a personal database administrator that can solve database problems by reading documents, using various tools, and writing analysis reports. It is currently undergoing an upgrade. **Features:** * **Online Demo:** * Import documents into the knowledge base * Utilize the knowledge base for well-founded Q&A and diagnosis analysis of abnormal alarms * Send feedbacks to refine the intermediate diagnosis results * Edit the diagnosis result * Browse all historical diagnosis results, used metrics, and detailed diagnosis processes * **Language Support:** * English (default) * Chinese (add "language: zh" in config.yaml) * **New Frontend:** * Knowledgebase + Chat Q&A + Diagnosis + Report Replay * **Extreme Speed Version for localized llms:** * 4-bit quantized LLM (reducing inference time by 1/3) * vllm for fast inference (qwen) * Tiny LLM * **Multi-path extraction of document knowledge:** * Vector database (ChromaDB) * RESTful Search Engine (Elasticsearch) * **Expert prompt generation using document knowledge** * **Upgrade the LLM-based diagnosis mechanism:** * Task Dispatching -> Concurrent Diagnosis -> Cross Review -> Report Generation * Synchronous Concurrency Mechanism during LLM inference * **Support monitoring and optimization tools in multiple levels:** * Monitoring metrics (Prometheus) * Flame graph in code level * Diagnosis knowledge retrieval (dbmind) * Logical query transformations (Calcite) * Index optimization algorithms (for PostgreSQL) * Physical operator hints (for PostgreSQL) * Backup and Point-in-time Recovery (Pigsty) * **Continuously updated papers and experimental reports** This project is constantly evolving with new features. Don't forget to star ⭐ and watch 👀 to stay up to date.
For similar tasks

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
lightning-bolts
Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production. Users can accelerate Lightning training with the Torch ORT Callback to optimize ONNX graph for faster training & inference. Additionally, users can introduce sparsity with the SparseMLCallback to accelerate inference by leveraging the DeepSparse engine. Specific research implementations are encouraged, with contributions that help train SSL models and integrate with Lightning Flash for state-of-the-art models in applied research.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.