
cognee
Knowledge Engine for AI Agent Memory in 6 lines of code
Stars: 12310

Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
README:
Cognee - Build AI memory with a Knowledge Engine that learns
Demo . Docs . Learn More · Join Discord · Join r/AIMemory . Community Plugins & Add-ons




Use our knowledge engine to build personalized and dynamic memory for AI Agents.
🌐 Available Languages : Deutsch | Español | Français | 日本語 | 한국어 | Português | Русский | 中文

Cognee is an open-source knowledge engine that transforms your raw data into persistent and dynamic AI memory for Agents. It combines vector search, graph databases and self-improvement to make your documents both searchable by meaning and connected by relationships as they change and evolve.
Cognee offers default knowledge creation and search which we describe bellow. But with Cognee you can build your modular knowledge blocks!
⭐ Help us reach more developers and grow the cognee community. Star this repo!
- Interconnects any type of data — including past conversations, files, images, and audio transcriptions
- Replaces traditional database lookups with a unified knowledge engine built with graphs and vectors
- Reduces developer effort and infrastructure cost while improving quality and precision
- Provides Pythonic data pipelines for ingestion from 30+ data sources
- Offers high customizability through user-defined tasks, modular pipelines, and built-in search endpoints
To learn more, check out this short, end-to-end Colab walkthrough of Cognee's core features.
Let’s try Cognee in just a few lines of code. For detailed setup and configuration, see the Cognee Docs.
- Python 3.10 to 3.13
You can install Cognee with pip, poetry, uv, or your preferred Python package manager.
uv pip install cogneeimport os
os.environ["LLM_API_KEY"] = "YOUR OPENAI_API_KEY"Alternatively, create a .env file using our template.
To integrate other LLM providers, see our LLM Provider Documentation.
Cognee will take your documents, generate a knowledge graph from them and then query the graph based on combined relationships.
Now, run a minimal pipeline:
import cognee
import asyncio
from pprint import pprint
async def main():
# Add text to cognee
await cognee.add("Cognee turns documents into AI memory.")
# Generate the knowledge graph
await cognee.cognify()
# Add memory algorithms to the graph
await cognee.memify()
# Query the knowledge graph
results = await cognee.search("What does Cognee do?")
# Display the results
for result in results:
pprint(result)
if __name__ == '__main__':
asyncio.run(main())As you can see, the output is generated from the document we previously stored in Cognee:
Cognee turns documents into AI memory.As an alternative, you can get started with these essential commands:
cognee-cli add "Cognee turns documents into AI memory."
cognee-cli cognify
cognee-cli search "What does Cognee do?"
cognee-cli delete --all
To open the local UI, run:
cognee-cli -uiSee Cognee in action:
Cognee Memory for LangGraph Agents
We welcome contributions from the community! Your input helps make Cognee better for everyone. See CONTRIBUTING.md to get started.
We're committed to fostering an inclusive and respectful community. Read our Code of Conduct for guidelines.
We recently published a research paper on optimizing knowledge graphs for LLM reasoning:
@misc{markovic2025optimizinginterfaceknowledgegraphs,
title={Optimizing the Interface Between Knowledge Graphs and LLMs for Complex Reasoning},
author={Vasilije Markovic and Lazar Obradovic and Laszlo Hajdu and Jovan Pavlovic},
year={2025},
eprint={2505.24478},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2505.24478},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cognee
Similar Open Source Tools
cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
lunary
Lunary is an open-source observability and prompt platform for Large Language Models (LLMs). It provides a suite of features to help AI developers take their applications into production, including analytics, monitoring, prompt templates, fine-tuning dataset creation, chat and feedback tracking, and evaluations. Lunary is designed to be usable with any model, not just OpenAI, and is easy to integrate and self-host.

AdalFlow
AdalFlow is a library designed to help developers build and optimize Large Language Model (LLM) task pipelines. It follows a design pattern similar to PyTorch, offering a light, modular, and robust codebase. Named in honor of Ada Lovelace, AdalFlow aims to inspire more women to enter the AI field. The library is tailored for various GenAI applications like chatbots, translation, summarization, code generation, and autonomous agents, as well as classical NLP tasks such as text classification and named entity recognition. AdalFlow emphasizes modularity, robustness, and readability to support users in customizing and iterating code for their specific use cases.

openlit
OpenLIT is an OpenTelemetry-native GenAI and LLM Application Observability tool. It's designed to make the integration process of observability into GenAI projects as easy as pie – literally, with just **a single line of code**. Whether you're working with popular LLM Libraries such as OpenAI and HuggingFace or leveraging vector databases like ChromaDB, OpenLIT ensures your applications are monitored seamlessly, providing critical insights to improve performance and reliability.

mmore
MMORE is an open-source, end-to-end pipeline for ingesting, processing, indexing, and retrieving knowledge from various file types such as PDFs, Office docs, images, audio, video, and web pages. It standardizes content into a unified multimodal format, supports distributed CPU/GPU processing, and offers hybrid dense+sparse retrieval with an integrated RAG service through CLI and APIs.
SciPIP
SciPIP is a scientific paper idea generation tool powered by a large language model (LLM) designed to assist researchers in quickly generating novel research ideas. It conducts a literature review based on user-provided background information and generates fresh ideas for potential studies. The tool is designed to help researchers in various fields by providing a GUI environment for idea generation, supporting NLP, multimodal, and CV fields, and allowing users to interact with the tool through a web app or terminal. SciPIP uses Neo4j as its database and provides functionalities for generating new ideas, fetching papers, and constructing the database.
lingoose
LinGoose is a modular Go framework designed for building AI/LLM applications. It offers the flexibility to import only the necessary modules, abstracts features for customization, and provides a comprehensive solution for developing AI/LLM applications from scratch. The framework simplifies the process of creating intelligent applications by allowing users to choose preferred implementations or create their own. LinGoose empowers developers to leverage its capabilities to streamline the development of cutting-edge AI and LLM projects.
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

AgentFly
AgentFly is an extensible framework for building LLM agents with reinforcement learning. It supports multi-turn training by adapting traditional RL methods with token-level masking. It features a decorator-based interface for defining tools and reward functions, enabling seamless extension and ease of use. To support high-throughput training, it implemented asynchronous execution of tool calls and reward computations, and designed a centralized resource management system for scalable environment coordination. A suite of prebuilt tools and environments are provided.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.
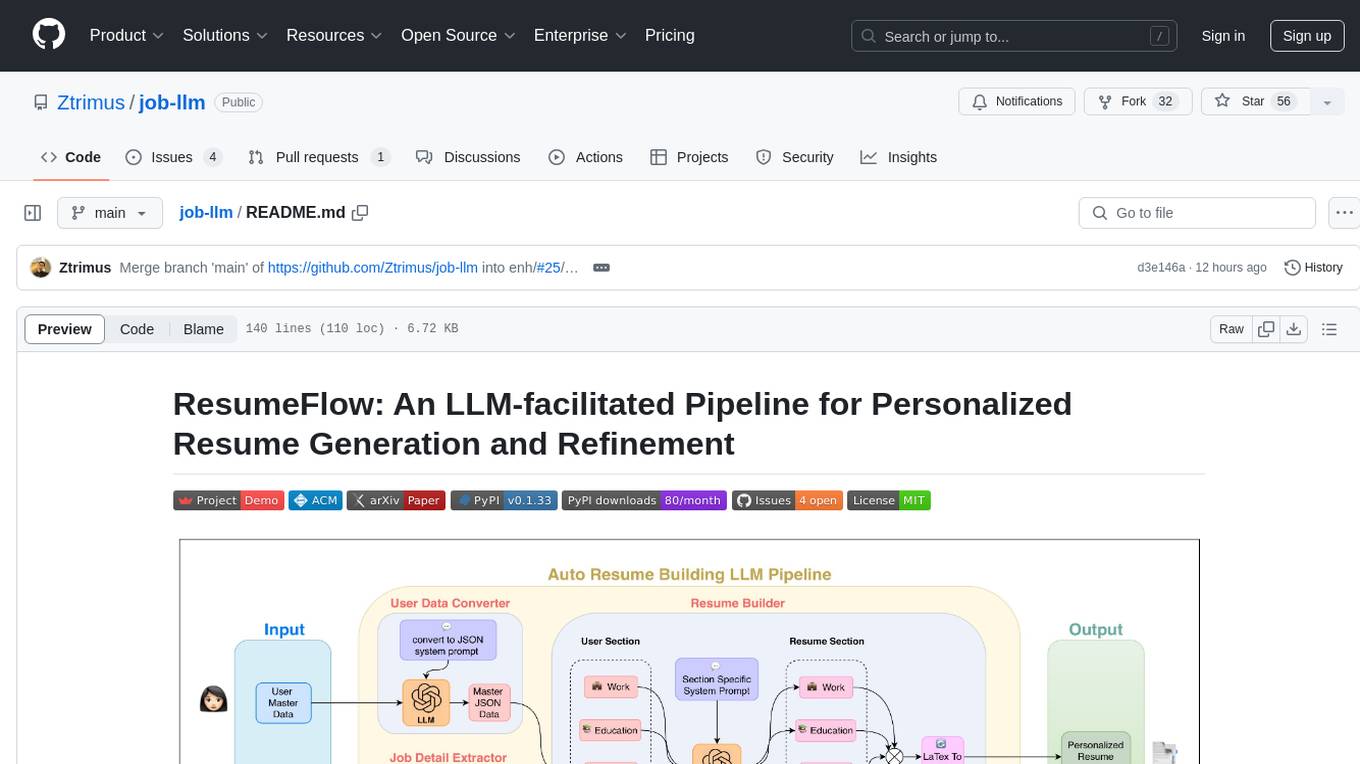
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.

superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.

lanarky
Lanarky is a Python web framework designed for building microservices using Large Language Models (LLMs). It is LLM-first, fast, modern, supports streaming over HTTP and WebSockets, and is open-source. The framework provides an abstraction layer for developers to easily create LLM microservices. Lanarky guarantees zero vendor lock-in and is free to use. It is built on top of FastAPI and offers features familiar to FastAPI users. The project is now in maintenance mode, with no active development planned, but community contributions are encouraged.
fiftyone-brain
FiftyOne Brain contains the open source AI/ML capabilities for the FiftyOne ecosystem, enabling users to automatically analyze and manipulate their datasets and models. Features include visual similarity search, query by text, finding unique and representative samples, finding media quality problems and annotation mistakes, and more.
For similar tasks
cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
dataformer
Dataformer is a robust framework for creating high-quality synthetic datasets for AI, offering speed, reliability, and scalability. It empowers engineers to rapidly generate diverse datasets grounded in proven research methodologies, enabling them to prioritize data excellence and achieve superior standards for AI models. Dataformer integrates with multiple LLM providers using one unified API, allowing parallel async API calls and caching responses to minimize redundant calls and reduce operational expenses. Leveraging state-of-the-art research papers, Dataformer enables users to generate synthetic data with adaptability, scalability, and resilience, shifting their focus from infrastructure concerns to refining data and enhancing models.
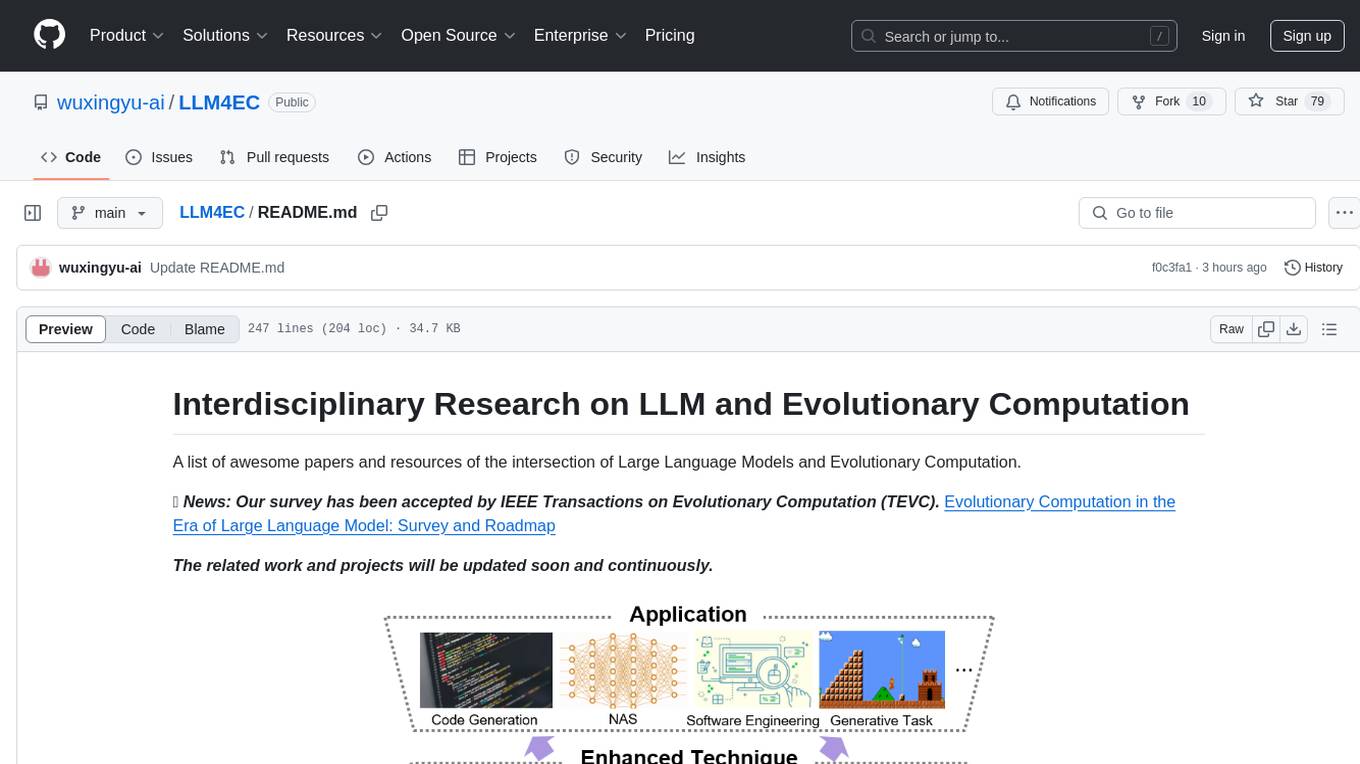
LLM4EC
LLM4EC is an interdisciplinary research repository focusing on the intersection of Large Language Models (LLM) and Evolutionary Computation (EC). It provides a comprehensive collection of papers and resources exploring various applications, enhancements, and synergies between LLM and EC. The repository covers topics such as LLM-assisted optimization, EA-based LLM architecture search, and applications in code generation, software engineering, neural architecture search, and other generative tasks. The goal is to facilitate research and development in leveraging LLM and EC for innovative solutions in diverse domains.

koordinator
Koordinator is a QoS based scheduling system for hybrid orchestration workloads on Kubernetes. It aims to improve runtime efficiency and reliability of latency sensitive workloads and batch jobs, simplify resource-related configuration tuning, and increase pod deployment density. It enhances Kubernetes user experience by optimizing resource utilization, improving performance, providing flexible scheduling policies, and easy integration into existing clusters.
Akagi
Akagi is a project designed to help users understand and improve their performance in Majsoul game matches in real-time. It provides educational insights and tools for analyzing gameplay. Users can install Akagi on Windows or Mac systems and follow the setup instructions to enhance their gaming experience. The project aims to offer features like Autoplay, Auto Ron, and integration with MajsoulUnlocker. It also focuses on enhancing user safety by providing guidelines to minimize the risk of account suspension. Akagi is a tool that combines MITM interception, AI decision-making, and user interaction to optimize gameplay strategies and performance.
DDQN-with-PyTorch-for-OpenAI-Gym
Implementation of Double DQN reinforcement learning for OpenAI Gym environments with discrete action spaces. The algorithm aims to improve sample efficiency by using two uncorrelated Q-Networks to prevent overestimation of Q-values. By updating parameters periodically, the model reduces computation time and enhances training performance. The tool is based on the Double DQN method proposed by Hasselt in 2010.
aiomultiprocess
aiomultiprocess is a Python library that combines AsyncIO and multiprocessing to achieve high levels of concurrency in Python applications. It allows running a full AsyncIO event loop on each child process, enabling multiple coroutines to execute simultaneously. The library provides a simple interface for executing asynchronous tasks on a pool of worker processes, making it easy to gather large amounts of network requests quickly. aiomultiprocess is designed to take Python codebases to the next level of performance by leveraging the combined power of AsyncIO and multiprocessing.
FrugalGPT
FrugalGPT is a framework that offers techniques for building Large Language Model (LLM) applications with budget constraints. It provides a cost-effective solution for utilizing LLMs while maintaining performance. The framework includes support for various models and offers resources for reducing costs and improving efficiency in LLM applications.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.