
dataformer
Solving data for LLMs - Create quality synthetic datasets!
Stars: 143
Dataformer is a robust framework for creating high-quality synthetic datasets for AI, offering speed, reliability, and scalability. It empowers engineers to rapidly generate diverse datasets grounded in proven research methodologies, enabling them to prioritize data excellence and achieve superior standards for AI models. Dataformer integrates with multiple LLM providers using one unified API, allowing parallel async API calls and caching responses to minimize redundant calls and reduce operational expenses. Leveraging state-of-the-art research papers, Dataformer enables users to generate synthetic data with adaptability, scalability, and resilience, shifting their focus from infrastructure concerns to refining data and enhancing models.
README:
Dataformer empowers engineers with a robust framework for creating high-quality synthetic datasets for AI, offering speed, reliability, and scalability. Our mission is to supercharge your AI development process by enabling rapid generation of diverse, premium datasets grounded in proven research methodologies. In the world of AI, compute costs are high, and output quality is paramount. Dataformer allows you to prioritize data excellence, addressing both these challenges head-on. By crafting top-tier synthetic data, you can invest your precious time in achieving and sustaining superior standards for your AI models.
We integrate with multiple LLM providers using one unified API and allow you to make parallel async API calls while respecting rate-limits. We offer the option to cache responses from LLM providers, minimizing redundant API calls and directly reducing operational expenses.
Leverage state-of-the-art research papers to generate synthetic data while ensuring adaptability, scalability, and resilience. Shift your focus from infrastructure concerns to refining your data and enhancing your models.
PyPi (Stable)
pip install dataformer
Github Source (Latest):
pip install dataformer@git+https://github.com/DataformerAI/dataformer.git
Using Git (Development):
git clone https://github.com/DataformerAI/dataformer.git
cd dataformer
pip install -e .
AsyncLLM supports various API providers, including:
- OpenAI
- Groq
- Together
- DeepInfra
- OpenRouter
Choose the provider that best suits your needs!
Here's a quick example of how to use Dataformer's AsyncLLM for efficient asynchronous generation:
from dataformer.llms import AsyncLLM
from dataformer.utils import get_request_list, get_messages
from datasets import load_dataset
# Load a sample dataset
dataset = load_dataset("dataformer/self-knowledge", split="train").select(range(3))
instructions = [example["question"] for example in dataset]
# Prepare the request list
sampling_params = {"temperature": 0.7}
request_list = get_request_list(instructions, sampling_params)
# Initialize AsyncLLM with your preferred API provider
llm = AsyncLLM(api_provider="groq", model="llama-3.1-8b-instant")
# Generate responses asynchronously
response_list = get_messages(llm.generate(request_list))We welcome contributions! Check our issues or open a new one to get started.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for dataformer
Similar Open Source Tools
dataformer
Dataformer is a robust framework for creating high-quality synthetic datasets for AI, offering speed, reliability, and scalability. It empowers engineers to rapidly generate diverse datasets grounded in proven research methodologies, enabling them to prioritize data excellence and achieve superior standards for AI models. Dataformer integrates with multiple LLM providers using one unified API, allowing parallel async API calls and caching responses to minimize redundant calls and reduce operational expenses. Leveraging state-of-the-art research papers, Dataformer enables users to generate synthetic data with adaptability, scalability, and resilience, shifting their focus from infrastructure concerns to refining data and enhancing models.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.

MemoryBear
MemoryBear is a next-generation AI memory system developed by RedBear AI, focusing on overcoming limitations in knowledge storage and multi-agent collaboration. It empowers AI with human-like memory capabilities, enabling deep knowledge understanding and cognitive collaboration. The system addresses challenges such as knowledge forgetting, memory gaps in multi-agent collaboration, and semantic ambiguity during reasoning. MemoryBear's core features include memory extraction engine, graph storage, hybrid search, memory forgetting engine, self-reflection engine, and FastAPI services. It offers a standardized service architecture for efficient integration and invocation across applications.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.

vulcan-sql
VulcanSQL is an Analytical Data API Framework for AI agents and data apps. It aims to help data professionals deliver RESTful APIs from databases, data warehouses or data lakes much easier and secure. It turns your SQL into APIs in no time!

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.

ai-data-analysis-MulitAgent
AI-Driven Research Assistant is an advanced AI-powered system utilizing specialized agents for data analysis, visualization, and report generation. It integrates LangChain, OpenAI's GPT models, and LangGraph for complex research processes. Key features include hypothesis generation, data processing, web search, code generation, and report writing. The system's unique Note Taker agent maintains project state, reducing overhead and improving context retention. System requirements include Python 3.10+ and Jupyter Notebook environment. Installation involves cloning the repository, setting up a Conda virtual environment, installing dependencies, and configuring environment variables. Usage instructions include setting data, running Jupyter Notebook, customizing research tasks, and viewing results. Main components include agents for hypothesis generation, process supervision, visualization, code writing, search, report writing, quality review, and note-taking. Workflow involves hypothesis generation, processing, quality review, and revision. Customization is possible by modifying agent creation and workflow definition. Current issues include OpenAI errors, NoteTaker efficiency, runtime optimization, and refiner improvement. Contributions via pull requests are welcome under the MIT License.

Upsonic
Upsonic offers a cutting-edge enterprise-ready framework for orchestrating LLM calls, agents, and computer use to complete tasks cost-effectively. It provides reliable systems, scalability, and a task-oriented structure for real-world cases. Key features include production-ready scalability, task-centric design, MCP server support, tool-calling server, computer use integration, and easy addition of custom tools. The framework supports client-server architecture and allows seamless deployment on AWS, GCP, or locally using Docker.


wren-engine
Wren Engine is a semantic engine designed to serve as the backbone of the semantic layer for LLMs. It simplifies the user experience by translating complex data structures into a business-friendly format, enabling end-users to interact with data using familiar terminology. The engine powers the semantic layer with advanced capabilities to define and manage modeling definitions, metadata, schema, data relationships, and logic behind calculations and aggregations through an analytics-as-code design approach. By leveraging Wren Engine, organizations can ensure a developer-friendly semantic layer that reflects nuanced data relationships and dynamics, facilitating more informed decision-making and strategic insights.

ReaLHF
ReaLHF is a distributed system designed for efficient RLHF training with Large Language Models (LLMs). It introduces a novel approach called parameter reallocation to dynamically redistribute LLM parameters across the cluster, optimizing allocations and parallelism for each computation workload. ReaL minimizes redundant communication while maximizing GPU utilization, achieving significantly higher Proximal Policy Optimization (PPO) training throughput compared to other systems. It supports large-scale training with various parallelism strategies and enables memory-efficient training with parameter and optimizer offloading. The system seamlessly integrates with HuggingFace checkpoints and inference frameworks, allowing for easy launching of local or distributed experiments. ReaLHF offers flexibility through versatile configuration customization and supports various RLHF algorithms, including DPO, PPO, RAFT, and more, while allowing the addition of custom algorithms for high efficiency.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.
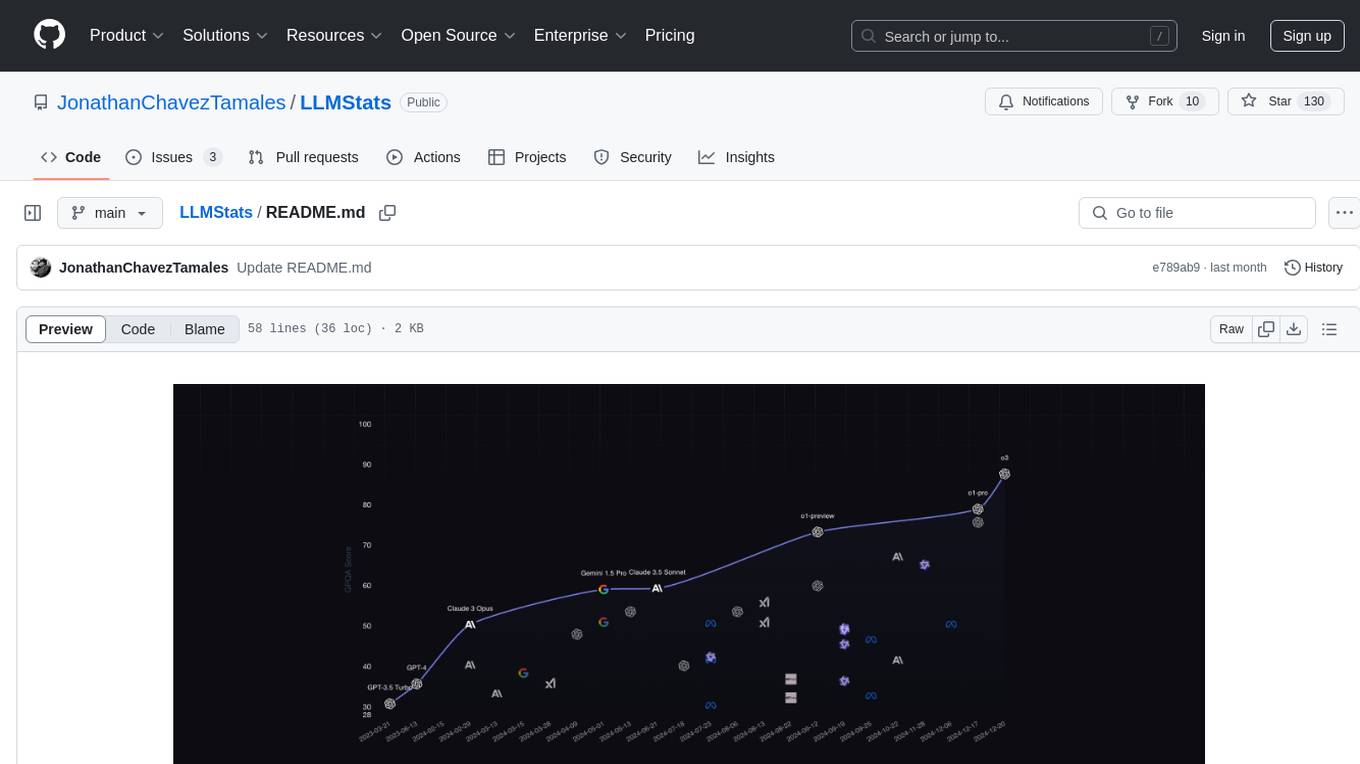
LLMStats
LLMStats is a community-driven repository providing detailed information on hundreds of Language Models (LLMs). Users can compare and explore LLMs through an interactive dashboard at llm-stats.com. The repository includes model parameters, context window sizes, licensing details, capabilities, provider pricing, performance metrics, and standardized benchmark results. Community contributions are welcome to maintain data accuracy. The platform prioritizes data quality through verifiable source links, community review processes, multiple source citations, and regular data validation. While not guaranteed to be 100% accurate, efforts are made to ensure the information is as reliable as possible.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.

crewAI
CrewAI is a cutting-edge framework designed to orchestrate role-playing autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It enables AI agents to assume roles, share goals, and operate in a cohesive unit, much like a well-oiled crew. Whether you're building a smart assistant platform, an automated customer service ensemble, or a multi-agent research team, CrewAI provides the backbone for sophisticated multi-agent interactions. With features like role-based agent design, autonomous inter-agent delegation, flexible task management, and support for various LLMs, CrewAI offers a dynamic and adaptable solution for both development and production workflows.
For similar tasks

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
dataformer
Dataformer is a robust framework for creating high-quality synthetic datasets for AI, offering speed, reliability, and scalability. It empowers engineers to rapidly generate diverse datasets grounded in proven research methodologies, enabling them to prioritize data excellence and achieve superior standards for AI models. Dataformer integrates with multiple LLM providers using one unified API, allowing parallel async API calls and caching responses to minimize redundant calls and reduce operational expenses. Leveraging state-of-the-art research papers, Dataformer enables users to generate synthetic data with adaptability, scalability, and resilience, shifting their focus from infrastructure concerns to refining data and enhancing models.
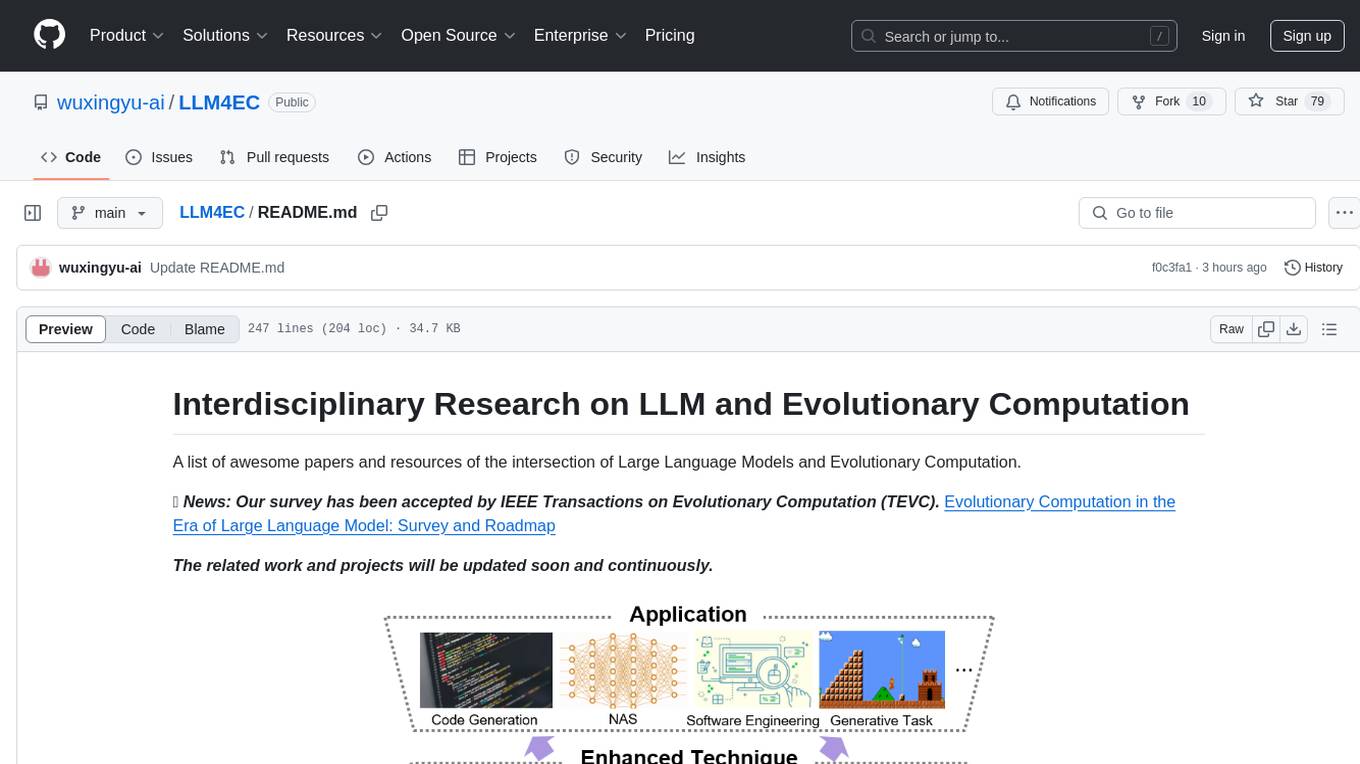
LLM4EC
LLM4EC is an interdisciplinary research repository focusing on the intersection of Large Language Models (LLM) and Evolutionary Computation (EC). It provides a comprehensive collection of papers and resources exploring various applications, enhancements, and synergies between LLM and EC. The repository covers topics such as LLM-assisted optimization, EA-based LLM architecture search, and applications in code generation, software engineering, neural architecture search, and other generative tasks. The goal is to facilitate research and development in leveraging LLM and EC for innovative solutions in diverse domains.

obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.
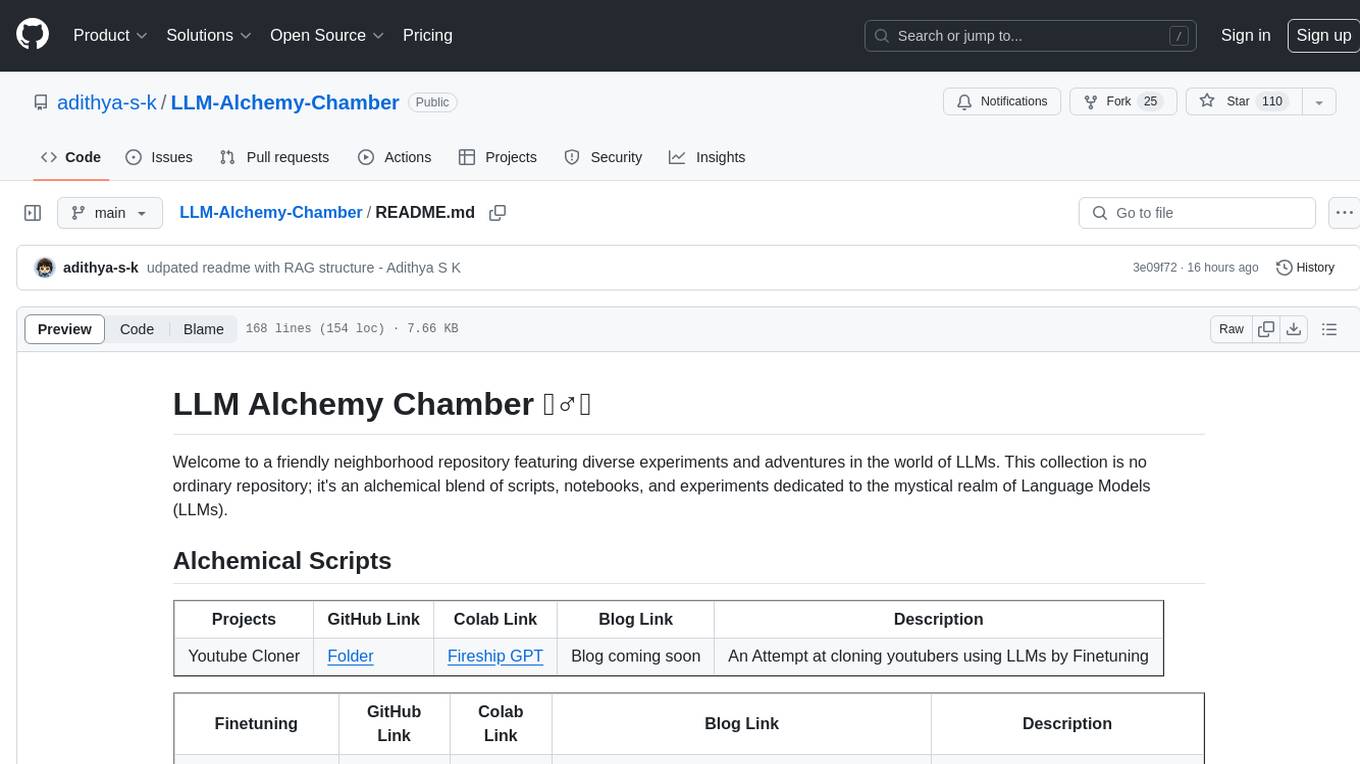
LLM-Alchemy-Chamber
LLM Alchemy Chamber is a repository dedicated to exploring the world of Language Models (LLMs) through various experiments and projects. It contains scripts, notebooks, and experiments focused on tasks such as fine-tuning different LLM models, quantization for performance optimization, dataset generation for instruction/QA tasks, and more. The repository offers a collection of resources for beginners and enthusiasts interested in delving into the mystical realm of LLMs.
bonito
Bonito is an open-source model for conditional task generation, converting unannotated text into task-specific training datasets for instruction tuning. It is a lightweight library built on top of Hugging Face `transformers` and `vllm` libraries. The tool supports various task types such as question answering, paraphrase generation, sentiment analysis, summarization, and more. Users can easily generate synthetic instruction tuning datasets using Bonito for zero-shot task adaptation.
Auto-Data
Auto Data is a library designed for the automatic generation of realistic datasets, essential for the fine-tuning of Large Language Models (LLMs). This highly efficient and lightweight library enables the swift and effortless creation of comprehensive datasets across various topics, regardless of their size. It addresses challenges encountered during model fine-tuning due to data scarcity and imbalance, ensuring models are trained with sufficient examples.
erag
ERAG is an advanced system that combines lexical, semantic, text, and knowledge graph searches with conversation context to provide accurate and contextually relevant responses. This tool processes various document types, creates embeddings, builds knowledge graphs, and uses this information to answer user queries intelligently. It includes modules for interacting with web content, GitHub repositories, and performing exploratory data analysis using various language models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.