
llm-app
Ready-to-run cloud templates for RAG, AI pipelines, and enterprise search with live data. 🐳Docker-friendly.⚡Always in sync with Sharepoint, Google Drive, S3, Kafka, PostgreSQL, real-time data APIs, and more.
Stars: 22934

Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.
README:
Pathway's AI Pipelines allow you to quickly put in production AI applications that offer high-accuracy RAG and AI enterprise search at scale using the most up-to-date knowledge available in your data sources. It provides you ready-to-deploy LLM (Large Language Model) App Templates. You can test them on your own machine and deploy on-cloud (GCP, AWS, Azure, Render,...) or on-premises.
The apps connect and sync (all new data additions, deletions, updates) with data sources on your file system, Google Drive, Sharepoint, S3, Kafka, PostgreSQL, real-time data APIs. They come with no infrastructure dependencies that would need a separate setup. They include built-in data indexing enabling vector search, hybrid search, and full-text search - all done in-memory, with cache.
The application templates provided in this repo scale up to millions of pages of documents. Some of them are optimized for simplicity, some are optimized for amazing accuracy. Pick the one that suits you best. You can use it out of the box, or change some steps of the pipeline - for example, if you would like to add a new data source, or change a Vector Index into a Hybrid Index, it's just a one-line change.
| Application (template) | Description |
|---|---|
Question-Answering RAG App |
Basic end-to-end RAG app. A question-answering pipeline that uses the GPT model of choice to provide answers to queries to your documents (PDF, DOCX,...) on a live connected data source (files, Google Drive, Sharepoint,...). You can also try out a demo REST endpoint. |
Live Document Indexing (Vector Store / Retriever) |
A real-time document indexing pipeline for RAG that acts as a vector store service. It performs live indexing on your documents (PDF, DOCX,...) from a connected data source (files, Google Drive, Sharepoint,...). It can be used with any frontend, or integrated as a retriever backend for a Langchain or Llamaindex application. You can also try out a demo REST endpoint. |
Multimodal RAG pipeline with GPT4o |
Multimodal RAG using GPT-4o in the parsing stage to index PDFs and other documents from a connected data source files, Google Drive, Sharepoint,...). It is perfect for extracting information from unstructured financial documents in your folders (including charts and tables), updating results as documents change or new ones arrive. |
Unstructured-to-SQL pipeline + SQL question-answering |
A RAG example which connects to unstructured financial data sources (financial report PDFs), structures the data into SQL, and loads it into a PostgreSQL table. It also answers natural language user queries to these financial documents by translating them into SQL using an LLM and executing the query on the PostgreSQL table. |
Adaptive RAG App |
A RAG application using Adaptive RAG, a technique developed by Pathway to reduce token cost in RAG up to 4x while maintaining accuracy. |
Private RAG App with Mistral and Ollama |
A fully private (local) version of the demo-question-answering RAG pipeline using Pathway, Mistral, and Ollama. |
Slides AI Search App |
An indexing pipeline for retrieving slides. It performs multi-modal of PowerPoint and PDF and maintains live index of your slides." |
The apps can be run as Docker containers, and expose an HTTP API to connect the frontend. To allow quick testing and demos, some app templates also include an optional Streamlit UI which connects to this API.
The apps rely on the Pathway Live Data framework for data source synchronization and for serving API requests (Pathway is a standalone Python library with a Rust engine built into it). They bring you a simple and unified application logic for back-end, embedding, retrieval, LLM tech stack. There is no need to integrate and maintain separate modules for your Gen AI app: Vector Database (e.g. Pinecone/Weaviate/Qdrant) + Cache (e.g. Redis) + API Framework (e.g. Fast API). Pathway's default choice of built-in vector index is based on the lightning-fast usearch library, and hybrid full-text indexes make use of Tantivy library. Everything works out of the box.
Each of the App templates in this repo contains a README.md with instructions on how to run it.
You can also find more ready-to-run code templates on the Pathway website.
Effortlessly extract and organize table and chart data from PDFs, docs, and more with multimodal RAG - in real-time:

(Check out Multimodal RAG pipeline with GPT4o to see the whole pipeline in the works. You may also check out the Unstructured-to-SQL pipeline for a minimal example that works with non-multimodal models as well.)
Automated real-time knowledge mining and alerting:

(Check out the Alerting when answers change on Google Drive app example.)
To provide feedback or report a bug, please raise an issue on our issue tracker.
Anyone who wishes to contribute to this project, whether documentation, features, bug fixes, code cleanup, testing, or code reviews, is very much encouraged to do so. If this is your first contribution to a GitHub project, here is a Get Started Guide.
If you'd like to make a contribution that needs some more work, just raise your hand on the Pathway Discord server (#get-help) and let us know what you are planning!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-app
Similar Open Source Tools
llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.

pathway
Pathway is a Python data processing framework for analytics and AI pipelines over data streams. It's the ideal solution for real-time processing use cases like streaming ETL or RAG pipelines for unstructured data. Pathway comes with an **easy-to-use Python API** , allowing you to seamlessly integrate your favorite Python ML libraries. Pathway code is versatile and robust: **you can use it in both development and production environments, handling both batch and streaming data effectively**. The same code can be used for local development, CI/CD tests, running batch jobs, handling stream replays, and processing data streams. Pathway is powered by a **scalable Rust engine** based on Differential Dataflow and performs incremental computation. Your Pathway code, despite being written in Python, is run by the Rust engine, enabling multithreading, multiprocessing, and distributed computations. All the pipeline is kept in memory and can be easily deployed with **Docker and Kubernetes**. You can install Pathway with pip: `pip install -U pathway` For any questions, you will find the community and team behind the project on Discord.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

PulsarRPA
PulsarRPA is a high-performance, distributed, open-source Robotic Process Automation (RPA) framework designed to handle large-scale RPA tasks with ease. It provides a comprehensive solution for browser automation, web content understanding, and data extraction. PulsarRPA addresses challenges of browser automation and accurate web data extraction from complex and evolving websites. It incorporates innovative technologies like browser rendering, RPA, intelligent scraping, advanced DOM parsing, and distributed architecture to ensure efficient, accurate, and scalable web data extraction. The tool is open-source, customizable, and supports cutting-edge information extraction technology, making it a preferred solution for large-scale web data extraction.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.
posthog
PostHog is an all-in-one, open source platform for building successful products. It provides tools for product analytics, web analytics, session replays, feature flags, experiments, error tracking, surveys, data warehouse, data pipelines, LLM analytics, and workflows. Users can get started with a generous free tier, self-host the platform, or use PostHog Cloud. The platform supports various SDKs and libraries for popular languages and frameworks, making it versatile and easy to integrate. PostHog is suitable for teams looking to understand user behavior, improve product performance, and automate actions or messages to users.

reductstore
ReductStore is a high-performance time series database designed for storing and managing large amounts of unstructured blob data. It offers features such as real-time querying, batching data, and HTTP(S) API for edge computing, computer vision, and IoT applications. The database ensures data integrity, implements retention policies, and provides efficient data access, making it a cost-effective solution for applications requiring unstructured data storage and access at specific time intervals.
5ire
5ire is a cross-platform desktop client that integrates a local knowledge base for multilingual vectorization, supports parsing and vectorization of various document formats, offers usage analytics to track API spending, provides a prompts library for creating and organizing prompts with variable support, allows bookmarking of conversations, and enables quick keyword searches across conversations. It is licensed under the GNU General Public License version 3.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.

azure-search-openai-demo
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access a GPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval. The repo includes sample data so it's ready to try end to end. In this sample application we use a fictitious company called Contoso Electronics, and the experience allows its employees to ask questions about the benefits, internal policies, as well as job descriptions and roles.
enterprise-commerce
Enterprise Commerce is a Next.js commerce starter that helps you launch your high-performance Shopify storefront in minutes, not weeks. It leverages the power of Vector Search and AI to deliver a superior online shopping experience without the development headaches.

meilisearch
Meilisearch is a lightning-fast search engine that seamlessly integrates into apps, websites, and workflows. It offers features like hybrid search, search-as-you-type, typo tolerance, filtering, sorting, synonym support, geosearch, extensive language support, security management, multi-tenancy, RESTful API, AI-readiness, easy installation, deployment, and maintenance.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.
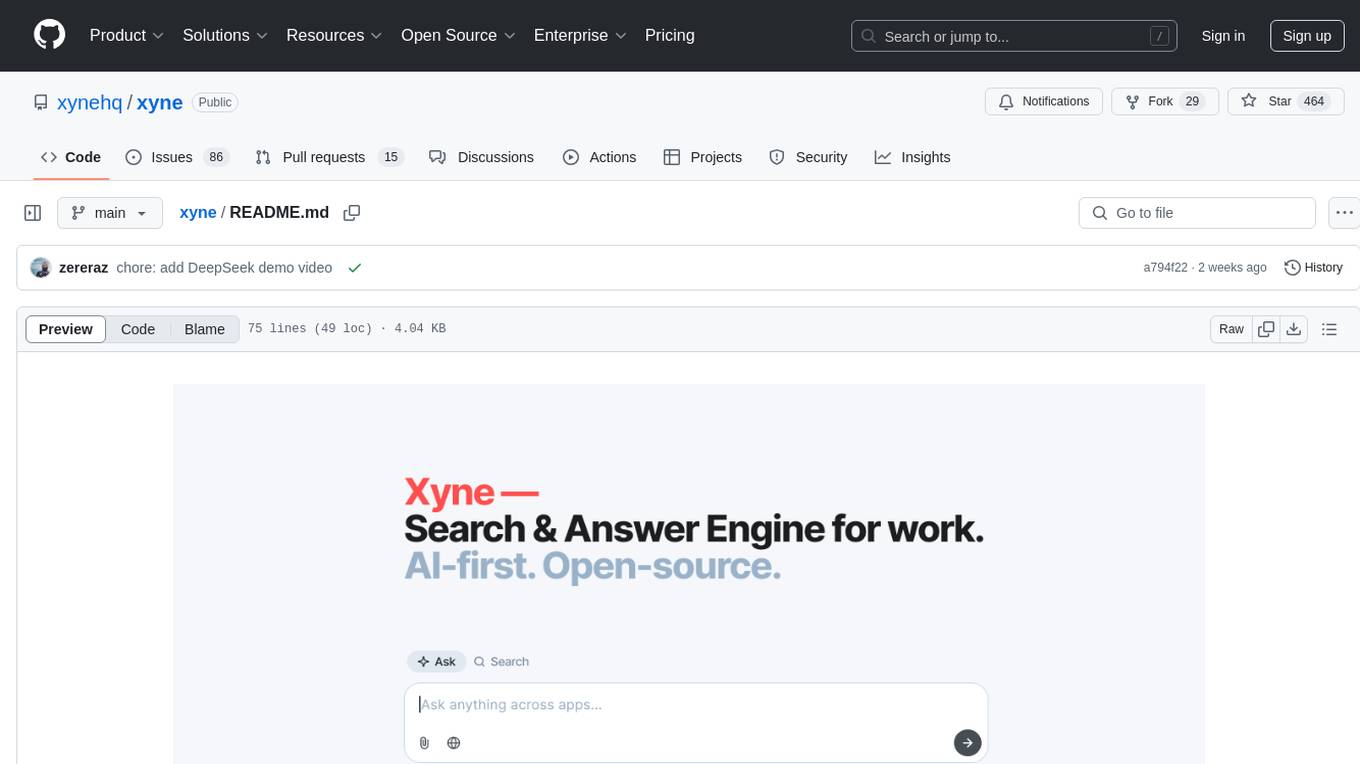
xyne
Xyne is an AI-first Search & Answer Engine for work, serving as an OSS alternative to Glean, Gemini, and MS Copilot. It securely indexes data from various applications like Google Workspace, Atlassian suite, Slack, and Github, providing a Google + ChatGPT-like experience to find information and get up-to-date answers. Users can easily locate files, triage issues, inquire about customers/deals/features/tickets, and discover relevant contacts. Xyne enhances AI models by providing contextual information in a secure, private, and responsible manner, making it the most secure and future-proof solution for integrating AI into work environments.

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"
For similar tasks
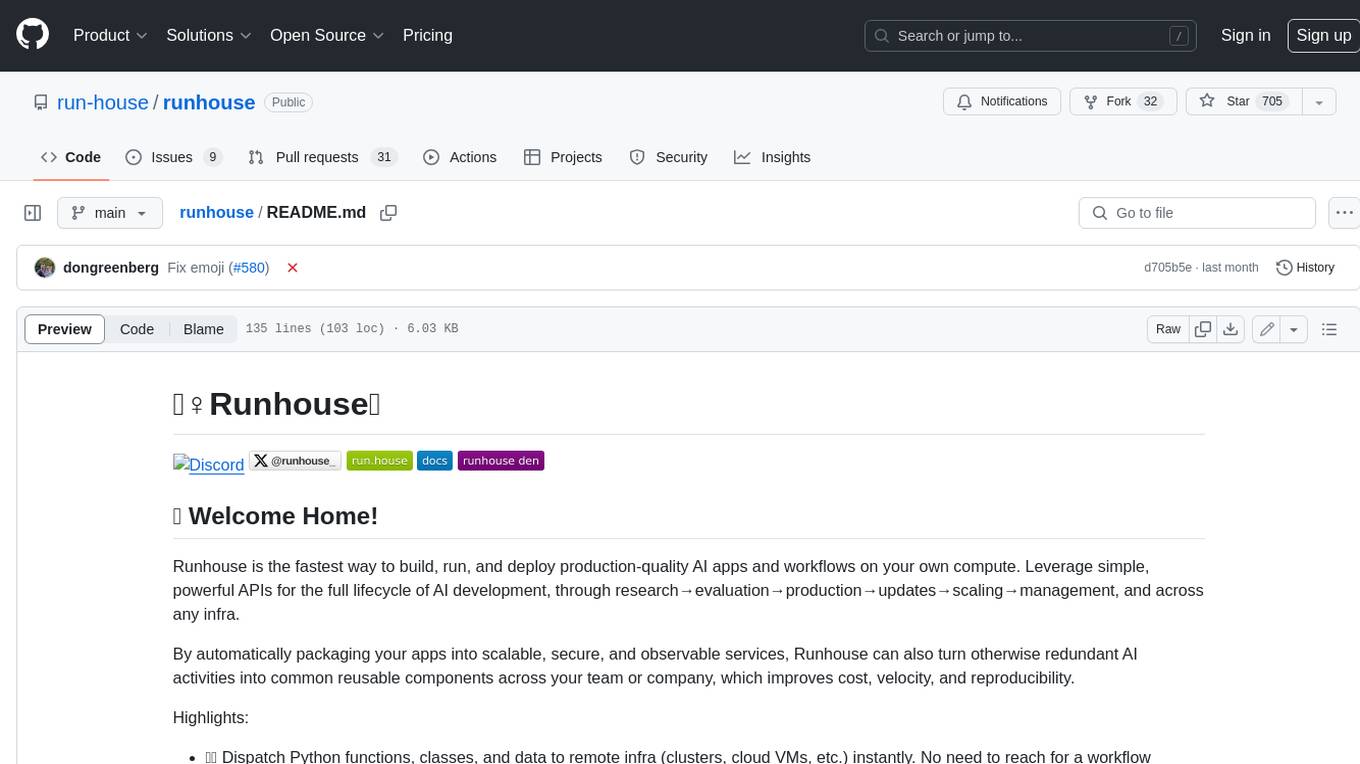
runhouse
Runhouse is a tool that allows you to build, run, and deploy production-quality AI apps and workflows on your own compute. It provides simple, powerful APIs for the full lifecycle of AI development, from research to evaluation to production to updates to scaling to management, and across any infra. By automatically packaging your apps into scalable, secure, and observable services, Runhouse can also turn otherwise redundant AI activities into common reusable components across your team or company, which improves cost, velocity, and reproducibility.

pebblo
Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities found in the loaded data and summarizes them on the UI or a PDF report.
llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.
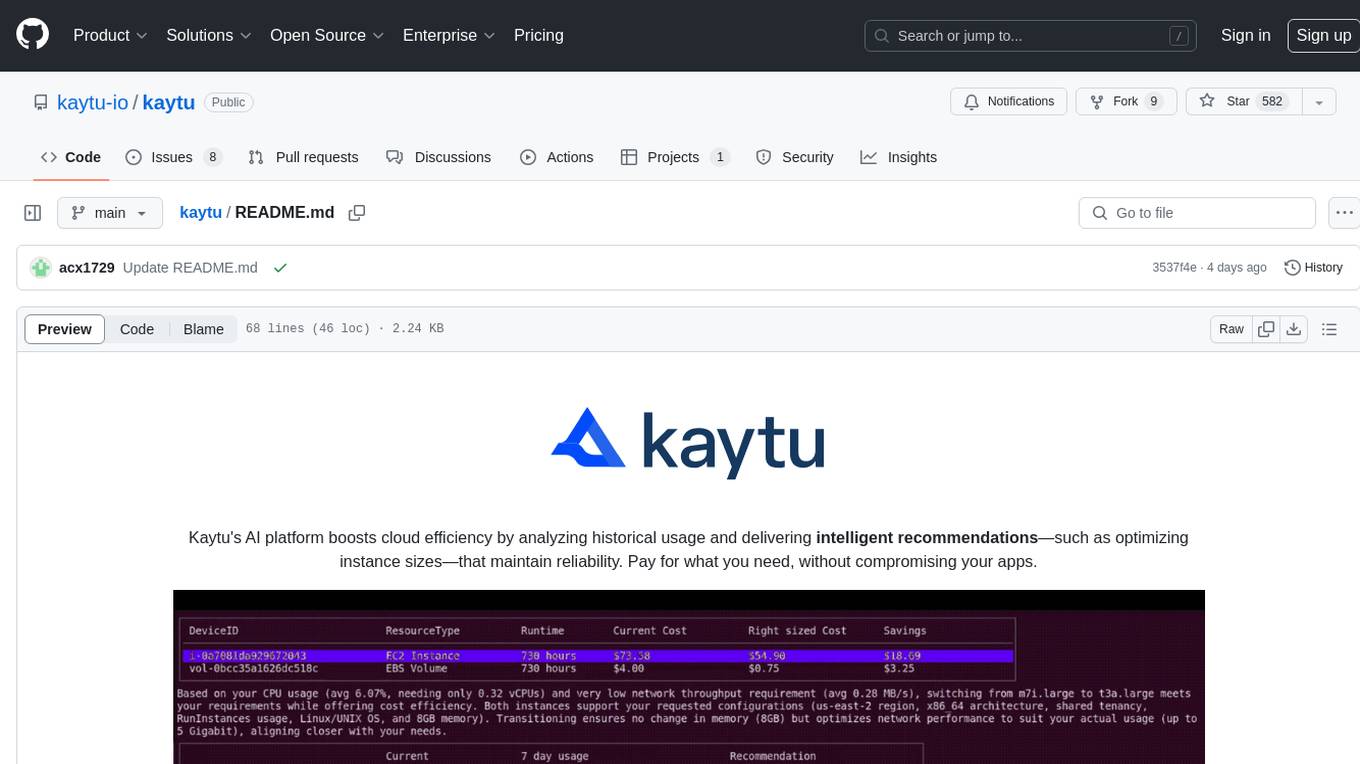
kaytu
Kaytu is an AI platform that enhances cloud efficiency by analyzing historical usage data and providing intelligent recommendations for optimizing instance sizes. Users can pay for only what they need without compromising the performance of their applications. The platform is easy to use with a one-line command, allows customization for specific requirements, and ensures security by extracting metrics from the client side. Kaytu is open-source and supports AWS services, with plans to expand to GCP, Azure, GPU optimization, and observability data from Prometheus in the future.
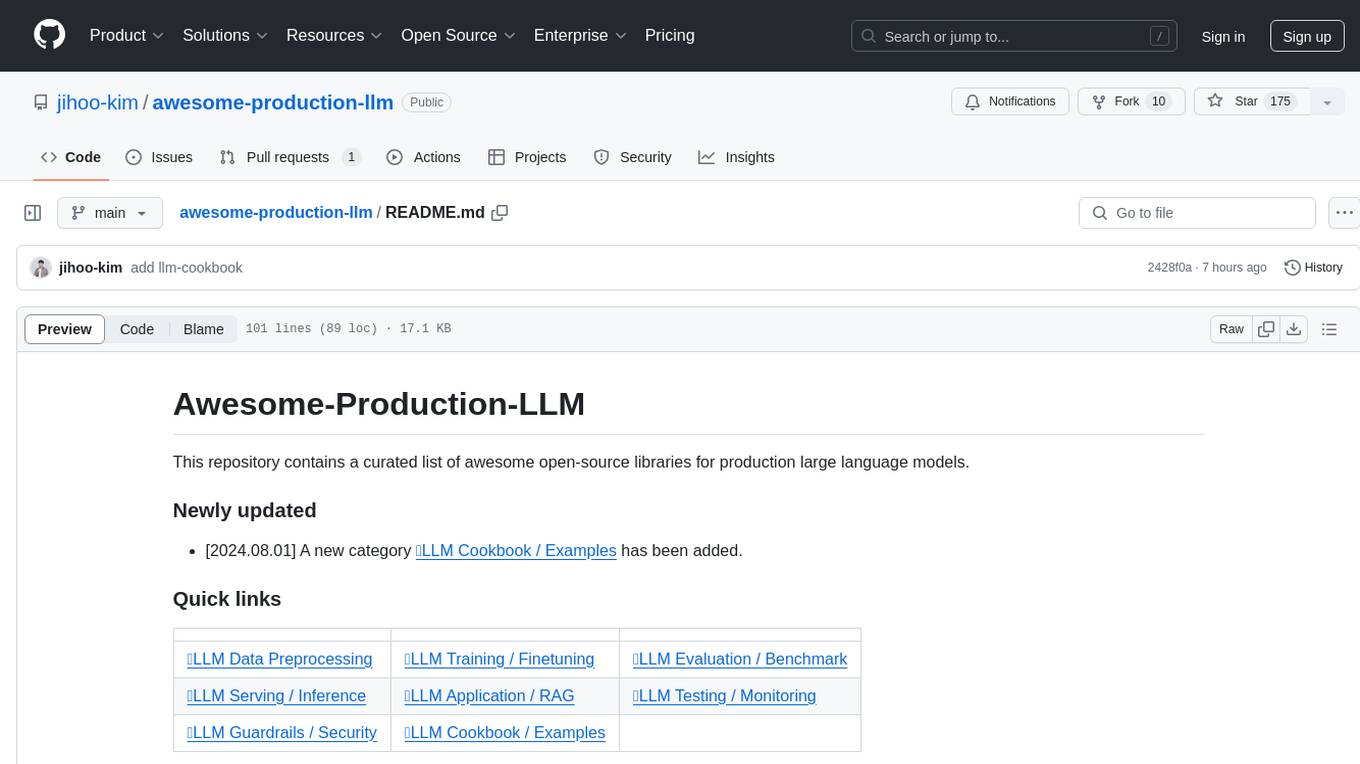
awesome-production-llm
This repository is a curated list of open-source libraries for production large language models. It includes tools for data preprocessing, training/finetuning, evaluation/benchmarking, serving/inference, application/RAG, testing/monitoring, and guardrails/security. The repository also provides a new category called LLM Cookbook/Examples for showcasing examples and guides on using various LLM APIs.
holisticai
Holistic AI is an open-source library dedicated to assessing and improving the trustworthiness of AI systems. It focuses on measuring and mitigating bias, explainability, robustness, security, and efficacy in AI models. The tool provides comprehensive metrics, mitigation techniques, a user-friendly interface, and visualization tools to enhance AI system trustworthiness. It offers documentation, tutorials, and detailed installation instructions for easy integration into existing workflows.
langkit
LangKit is an open-source text metrics toolkit for monitoring language models. It offers methods for extracting signals from input/output text, compatible with whylogs. Features include text quality, relevance, security, sentiment, toxicity analysis. Installation via PyPI. Modules contain UDFs for whylogs. Benchmarks show throughput on AWS instances. FAQs available.

nesa
Nesa is a tool that allows users to run on-prem AI for a fraction of the cost through a blind API. It provides blind privacy, zero latency on protected inference, wide model coverage, cost savings compared to cloud and on-prem AI, RAG support, and ChatGPT compatibility. Nesa achieves blind AI through Equivariant Encryption (EE), a new security technology that provides complete inference encryption with no additional latency. EE allows users to perform inference on neural networks without exposing the underlying data, preserving data privacy and security.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.