
llama_deploy
Deploy your agentic worfklows to production
Stars: 1974
llama_deploy is an async-first framework for deploying, scaling, and productionizing agentic multi-service systems based on workflows from llama_index. It allows building workflows in llama_index and deploying them seamlessly with minimal changes to code. The system includes services endlessly processing tasks, a control plane managing state and services, an orchestrator deciding task handling, and fault tolerance mechanisms. It is designed for high-concurrency scenarios, enabling real-time and high-throughput applications.
README:


![]()
![]()
LlamaDeploy (formerly llama-agents) is an async-first framework for deploying, scaling, and productionizing agentic
multi-service systems based on workflows from llama_index.
With LlamaDeploy, you can build any number of workflows in llama_index and then run them as services, accessible
through a HTTP API by a user interface or other services part of your system.
The goal of LlamaDeploy is to easily transition something that you built in a notebook to something running on the cloud with the minimum amount of changes to the original code, possibly zero. In order to make this transition a pleasant one, you can interact with LlamaDeploy in two ways:
- Using the
llamactlCLI from a shell. - Through the LlamaDeploy SDK from a Python application or script.
Both the SDK and the CLI are part of the LlamaDeploy Python package. To install, just run:
pip install llama_deploy[!TIP] For a comprehensive guide to LlamaDeploy's architecture and detailed descriptions of its components, visit our official documentation.
-
Seamless Deployment: It bridges the gap between development and production, allowing you to deploy
llama_indexworkflows with minimal changes to your code. - Scalability: The microservices architecture enables easy scaling of individual components as your system grows.
- Flexibility: By using a hub-and-spoke architecture, you can easily swap out components (like message queues) or add new services without disrupting the entire system.
- Fault Tolerance: With built-in retry mechanisms and failure handling, LlamaDeploy adds robustness in production environments.
- State Management: The control plane manages state across services, simplifying complex multi-step processes.
- Async-First: Designed for high-concurrency scenarios, making it suitable for real-time and high-throughput applications.
[!NOTE] This project was initially released under the name
llama-agents, but the introduction of Workflows inllama_indexturned out to be the most intuitive way for our users to develop agentic applications. We then decided to add new agentic features inllama_indexdirectly, and focus LlamaDeploy on closing the gap between local development and remote execution of agents as services.
The fastest way to start using LlamaDeploy is playing with a practical example. This repository contains a few applications you can use as a reference:
We recommend to start from the Quick start example and move to Use a deployment from a web-based user interface immediately after. Each folder contains a README file that will guide you through the process.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llama_deploy
Similar Open Source Tools
llama_deploy
llama_deploy is an async-first framework for deploying, scaling, and productionizing agentic multi-service systems based on workflows from llama_index. It allows building workflows in llama_index and deploying them seamlessly with minimal changes to code. The system includes services endlessly processing tasks, a control plane managing state and services, an orchestrator deciding task handling, and fault tolerance mechanisms. It is designed for high-concurrency scenarios, enabling real-time and high-throughput applications.

agentok
Agentok Studio is a visual tool built for AutoGen, a cutting-edge agent framework from Microsoft and various contributors. It offers intuitive visual tools to simplify the construction and management of complex agent-based workflows. Users can create workflows visually as graphs, chat with agents, and share flow templates. The tool is designed to streamline the development process for creators and developers working on next-generation Multi-Agent Applications.
InfiniStore
InfiniStore is an open-source high-performance KV store designed to support LLM Inference clusters. It provides high-performance and low-latency KV cache transfer and reuse among inference nodes. In addition to inference clusters, it can be used as a standalone KV store for integration with LLM training or inference services. InfiniStore is currently integrated with vLLM via LMCache and is in progress for integration with SGLang and other inference engines.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.

promptmage
PromptMage simplifies the process of creating and managing LLM workflows as a self-hosted solution. It offers an intuitive interface for prompt testing and comparison, incorporates version control features, and aims to improve productivity in both small teams and large enterprises. The tool bridges the gap in LLM workflow management, empowering developers, researchers, and organizations to make LLM technology more accessible and manageable for the next wave of AI innovations.
LabelLLM
LabelLLM is an open-source data annotation platform designed to optimize the data annotation process for LLM development. It offers flexible configuration, multimodal data support, comprehensive task management, and AI-assisted annotation. Users can access a suite of annotation tools, enjoy a user-friendly experience, and enhance efficiency. The platform allows real-time monitoring of annotation progress and quality control, ensuring data integrity and timeliness.

project_alice
Alice is an agentic workflow framework that integrates task execution and intelligent chat capabilities. It provides a flexible environment for creating, managing, and deploying AI agents for various purposes, leveraging a microservices architecture with MongoDB for data persistence. The framework consists of components like APIs, agents, tasks, and chats that interact to produce outputs through files, messages, task results, and URL references. Users can create, test, and deploy agentic solutions in a human-language framework, making it easy to engage with by both users and agents. The tool offers an open-source option, user management, flexible model deployment, and programmatic access to tasks and chats.
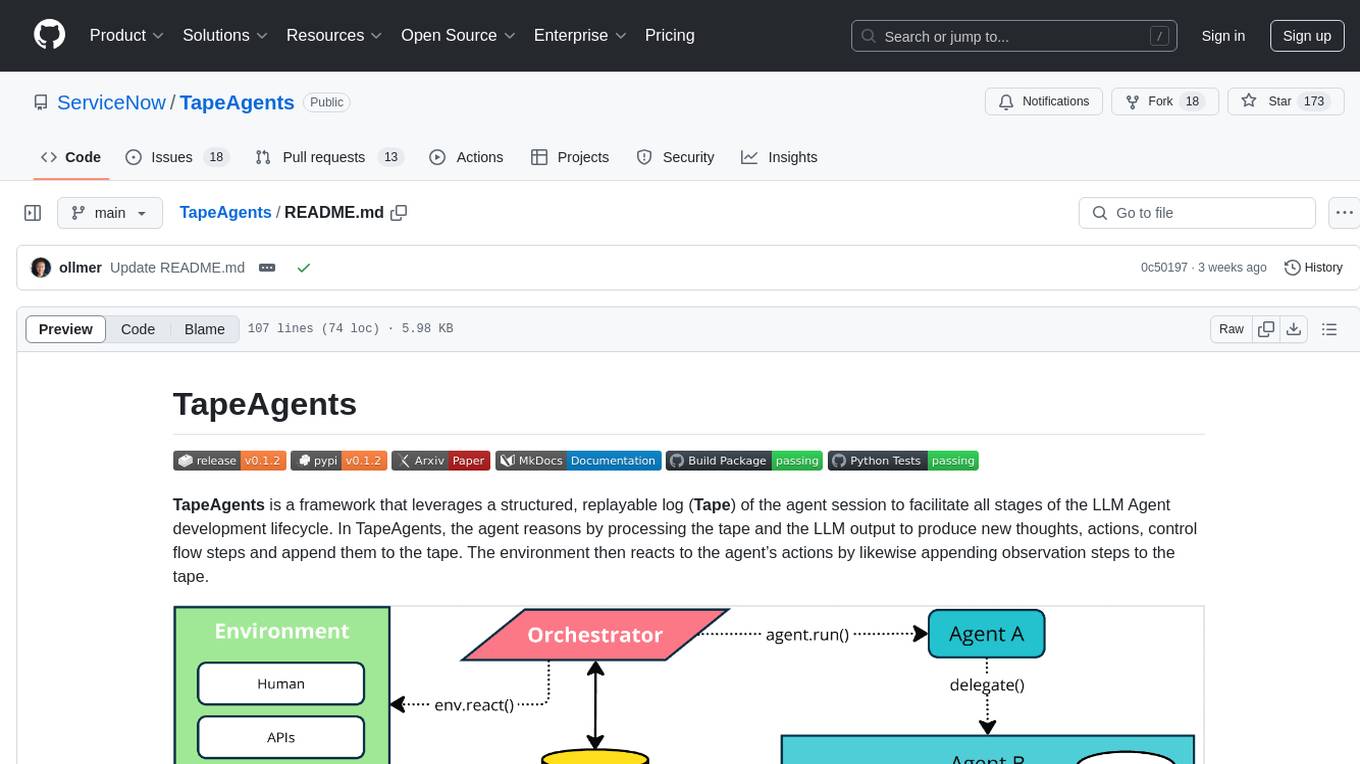
TapeAgents
TapeAgents is a framework that leverages a structured, replayable log of the agent session to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thoughts, actions, control flow steps, and append them to the tape. Key features include building agents as low-level state machines or high-level multi-agent team configurations, debugging agents with TapeAgent studio or TapeBrowser apps, serving agents with response streaming, and optimizing agent configurations using successful tapes. The Tape-centric design of TapeAgents provides ultimate flexibility in project development, allowing access to tapes for making prompts, generating next steps, and controlling agent behavior.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

floki
Floki is an open-source framework for researchers and developers to experiment with LLM-based autonomous agents. It provides tools to create, orchestrate, and manage agents while seamlessly connecting to LLM inference APIs. Built on Dapr, Floki leverages a unified programming model that simplifies microservices and supports both deterministic workflows and event-driven interactions. By bringing together these features, Floki provides a powerful way to explore agentic workflows and the components that enable multi-agent systems to collaborate and scale, all powered by Dapr.

council
Council is an open-source platform designed for the rapid development and deployment of customized generative AI applications using teams of agents. It extends the LLM tool ecosystem by providing advanced control flow and scalable oversight for AI agents. Users can create sophisticated agents with predictable behavior by leveraging Council's powerful approach to control flow using Controllers, Filters, Evaluators, and Budgets. The framework allows for automated routing between agents, comparing, evaluating, and selecting the best results for a task. Council aims to facilitate packaging and deploying agents at scale on multiple platforms while enabling enterprise-grade monitoring and quality control.

modus
Modus is an open-source, serverless framework for building APIs powered by WebAssembly. It simplifies integrating AI models, data, and business logic with sandboxed execution. Modus extracts metadata, compiles code with optimizations, caches compiled modules, prepares invocation plans, generates API schema, and activates endpoints. Users query the endpoint, and Modus loads compiled code into a sandboxed environment, runs code securely, queries data and AI models, and responds via API. It provides a production-ready scalable endpoint for AI-enabled apps, optimized for sub-second response times. Modus supports programming languages like AssemblyScript and Go, and can be hosted on Hypermode or any platform. Developed by Hypermode as an open-source project, Modus welcomes external contributions.

Robyn
Robyn is an experimental, semi-automated and open-sourced Marketing Mix Modeling (MMM) package from Meta Marketing Science. It uses various machine learning techniques to define media channel efficiency and effectivity, explore adstock rates and saturation curves. Built for granular datasets with many independent variables, especially suitable for digital and direct response advertisers with rich data sources. Aiming to democratize MMM, make it accessible for advertisers of all sizes, and contribute to the measurement landscape.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.

PulsarRPA
PulsarRPA is a high-performance, distributed, open-source Robotic Process Automation (RPA) framework designed to handle large-scale RPA tasks with ease. It provides a comprehensive solution for browser automation, web content understanding, and data extraction. PulsarRPA addresses challenges of browser automation and accurate web data extraction from complex and evolving websites. It incorporates innovative technologies like browser rendering, RPA, intelligent scraping, advanced DOM parsing, and distributed architecture to ensure efficient, accurate, and scalable web data extraction. The tool is open-source, customizable, and supports cutting-edge information extraction technology, making it a preferred solution for large-scale web data extraction.
For similar tasks
llama_deploy
llama_deploy is an async-first framework for deploying, scaling, and productionizing agentic multi-service systems based on workflows from llama_index. It allows building workflows in llama_index and deploying them seamlessly with minimal changes to code. The system includes services endlessly processing tasks, a control plane managing state and services, an orchestrator deciding task handling, and fault tolerance mechanisms. It is designed for high-concurrency scenarios, enabling real-time and high-throughput applications.
fastagency
FastAgency is an open-source framework designed to accelerate the transition from prototype to production for multi-agent AI workflows. It provides a unified programming interface for deploying agentic workflows written in AG2 agentic framework in both development and productional settings. With features like seamless external API integration, a Tester Class for continuous integration, and a Command-Line Interface (CLI) for orchestration, FastAgency streamlines the deployment process, saving time and effort while maintaining flexibility and performance. Whether orchestrating complex AI agents or integrating external APIs, FastAgency helps users quickly transition from concept to production, reducing development cycles and optimizing multi-agent systems.
model-compose
model-compose is an open-source, declarative workflow orchestrator inspired by docker-compose. It lets you define and run AI model pipelines using simple YAML files. Effortlessly connect external AI services or run local AI models within powerful, composable workflows. Features include declarative design, multi-workflow support, modular components, flexible I/O routing, streaming mode support, and more. It supports running workflows locally or serving them remotely, Docker deployment, environment variable support, and provides a CLI interface for managing AI workflows.

exospherehost
Exosphere is an open source infrastructure designed to run AI agents at scale for large data and long running flows. It allows developers to define plug and playable nodes that can be run on a reliable backbone in the form of a workflow, with features like dynamic state creation at runtime, infinite parallel agents, persistent state management, and failure handling. This enables the deployment of production agents that can scale beautifully to build robust autonomous AI workflows.
burr
Burr is a Python library and UI that makes it easy to develop applications that make decisions based on state (chatbots, agents, simulations, etc...). Burr includes a UI that can track/monitor those decisions in real time.
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.
agentscript
AgentScript is an open-source framework for building AI agents that think in code. It prompts a language model to generate JavaScript code, which is then executed in a dedicated runtime with resumability, state persistence, and interactivity. The framework allows for abstract task execution without needing to know all the data beforehand, making it flexible and efficient. AgentScript supports tools, deterministic functions, and LLM-enabled functions, enabling dynamic data processing and decision-making. It also provides state management and human-in-the-loop capabilities, allowing for pausing, serialization, and resumption of execution.
agents
Cloudflare Agents is a framework for building intelligent, stateful agents that persist, think, and evolve at the edge of the network. It allows for maintaining persistent state and memory, real-time communication, processing and learning from interactions, autonomous operation at global scale, and hibernating when idle. The project is actively evolving with focus on core agent framework, WebSocket communication, HTTP endpoints, React integration, and basic AI chat capabilities. Future developments include advanced memory systems, WebRTC for audio/video, email integration, evaluation framework, enhanced observability, and self-hosting guide.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.