Best AI tools for< System Architect >
Infographic
20 - AI tool Sites
Nokia API Hub
Nokia API Hub, previously known as Rapid, is a platform that offers a comprehensive catalog of APIs for enterprises. It allows users to discover and utilize various APIs or publish their own to generate new revenue streams. With features like a vast API library, developer community, and testing resources, Nokia API Hub aims to facilitate seamless API integration for businesses.
Dev Radar
Dev Radar is an open-source, AI-powered news aggregator that helps users stay up to date with the latest trends in software development. It provides curated articles on various topics such as JavaScript, Python, React, TypeScript, Rust, Go, Node.js, Deno, Ruby, and more. The platform leverages AI technology to deliver relevant and insightful content to developers, making it a valuable resource for staying informed in the rapidly evolving tech industry.
Tabnine
Tabnine is an AI code assistant that accelerates and simplifies software development while keeping your code private, secure, and compliant. It offers industry-leading AI code assistance, personalized to fit your team's needs, ensuring total code privacy, and providing complete protection from intellectual property issues. Tabnine's AI agents cover various aspects of the software development lifecycle, from code generation and explanations to testing, documentation, and bug fixes.

Intervu
Intervu is an AI-powered interview platform that helps users prepare for system design interviews. It offers unlimited True-to-Life system design interviews with AI, enriched with comprehensive feedback, to help users conquer system design challenges.
Hailo
Hailo is a leading provider of top-performing edge AI processors for various edge devices, offering generative AI accelerators, AI vision processors, and AI accelerators. The company's technology enables high-performance deep learning applications on edge devices, catering to industries such as automotive, security, industrial automation, retail, and personal computing.
Diagramix
Diagramix is an AI-powered tool that allows users to generate various types of diagrams, such as sequence diagrams, flowcharts, state diagrams, ER diagrams, user journey diagrams, class diagrams, mind maps, and use case diagrams. Users can create these diagrams easily and efficiently with the help of Diagramix and ChatGPT. The tool provides a user-friendly interface for creating visual representations of complex systems and processes, making it ideal for professionals, students, and anyone who needs to visualize information.
Interview Monkey
Interview Monkey is an AI tool designed to help software engineering candidates ace technical interviews. It offers real-time problem-solving capabilities for coding and system design questions, supporting over 10 coding languages. The tool operates discreetly during screenshare sessions, provides solutions without typing, and is tailored for various interview types. Interview Monkey aims to boost candidates' confidence, increase hiring chances, and upgrade their roles and salaries in the competitive job market.
Astra
Astra is a universal API for LLM function calling that supercharges LLMs with integrations using a single line of code. It allows users to conveniently leverage function calling in LLMs with over 2,200 integrations, manage authentication profiles, import tools easily, and enable function calling with any LLM. Astra replaces JSON with a type-safe UI, making integration management simpler. The application extends the capabilities of LLMs without altering their core structure, offering a seamless layer of integrations and function execution.
Vilosia
Vilosia is an AI-powered platform that helps medium and large enterprises with internal development teams to visualize their software architecture, simplify migration, and improve system modularity. The platform uses Gen AI to automatically add event triggers to the codebase, enabling users to understand data flow, system dependencies, domain boundaries, and external APIs. Vilosia also offers AI workflow analysis to extract workflows from function call chains and identify database usage. Users can scan their codebase using CLI client & CI/CD integration and stay updated with new features through the newsletter.

Langflow
Langflow is a low-code app builder for RAG and multi-agent AI applications. It is Python-based and agnostic to any model, API, or database. Langflow offers a visual IDE for building and testing workflows, multi-agent orchestration, free cloud service, observability features, and ecosystem integrations. Users can customize workflows using Python and publish them as APIs or export as Python applications.
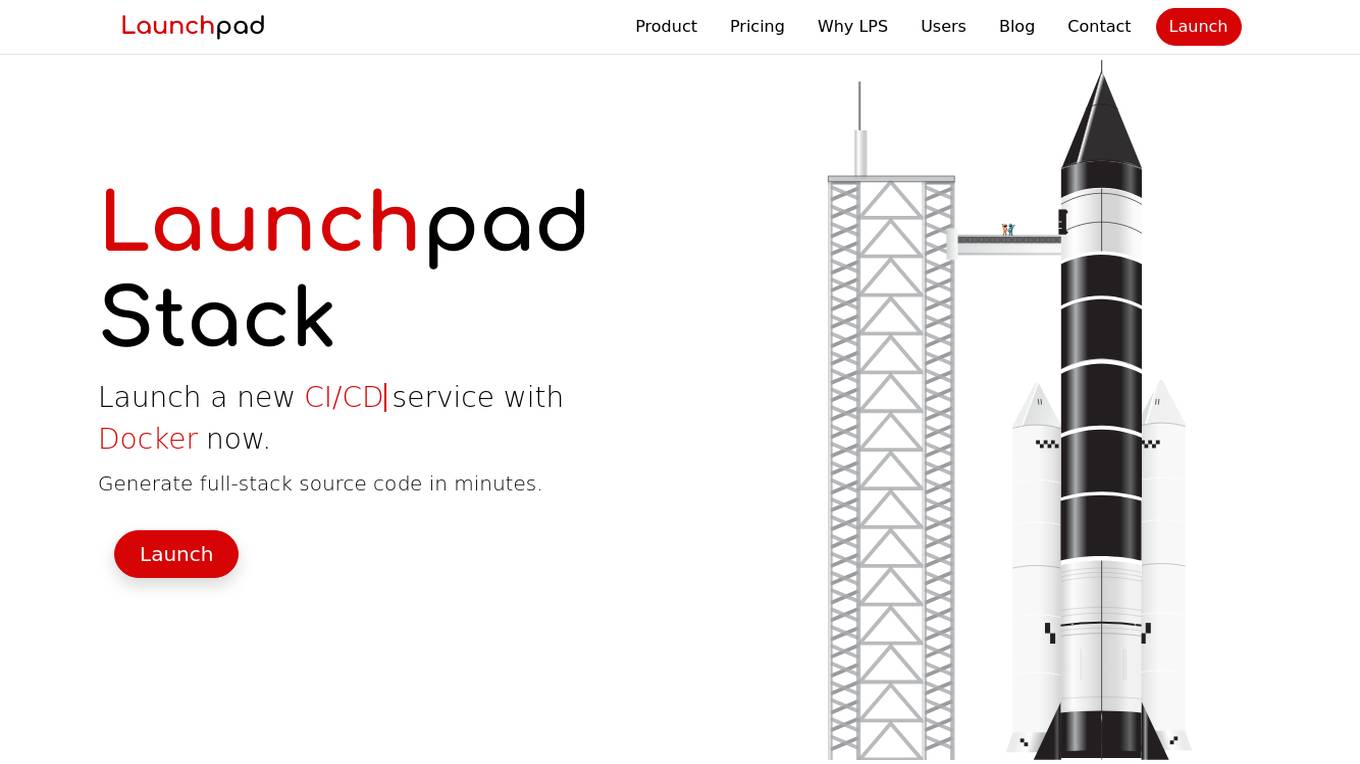
Launchpad Stack
Launchpad Stack is an AI-powered platform that allows users to quickly launch new Rails services with AWS. It generates full-stack source code in minutes, covering infrastructure, application, CI/CD pipeline, monitoring, security, and more. The platform offers a suite of inter-operable code packages tailored to the user's project requirements, with no restrictive licenses. Users can launch enterprise-grade stacks in minutes, pay once for the components they need, and enjoy ongoing support for their projects.

Outspeed
Outspeed is a platform for Realtime Voice and Video AI applications, providing networking and inference infrastructure to build fast, real-time voice and video AI apps. It offers tools for intelligence across industries, including Voice AI, Streaming Avatars, Visual Intelligence, Meeting Copilot, and the ability to build custom multimodal AI solutions. Outspeed is designed by engineers from Google and MIT, offering robust streaming infrastructure, low-latency inference, instant deployment, and enterprise-ready compliance with regulations such as SOC2, GDPR, and HIPAA.
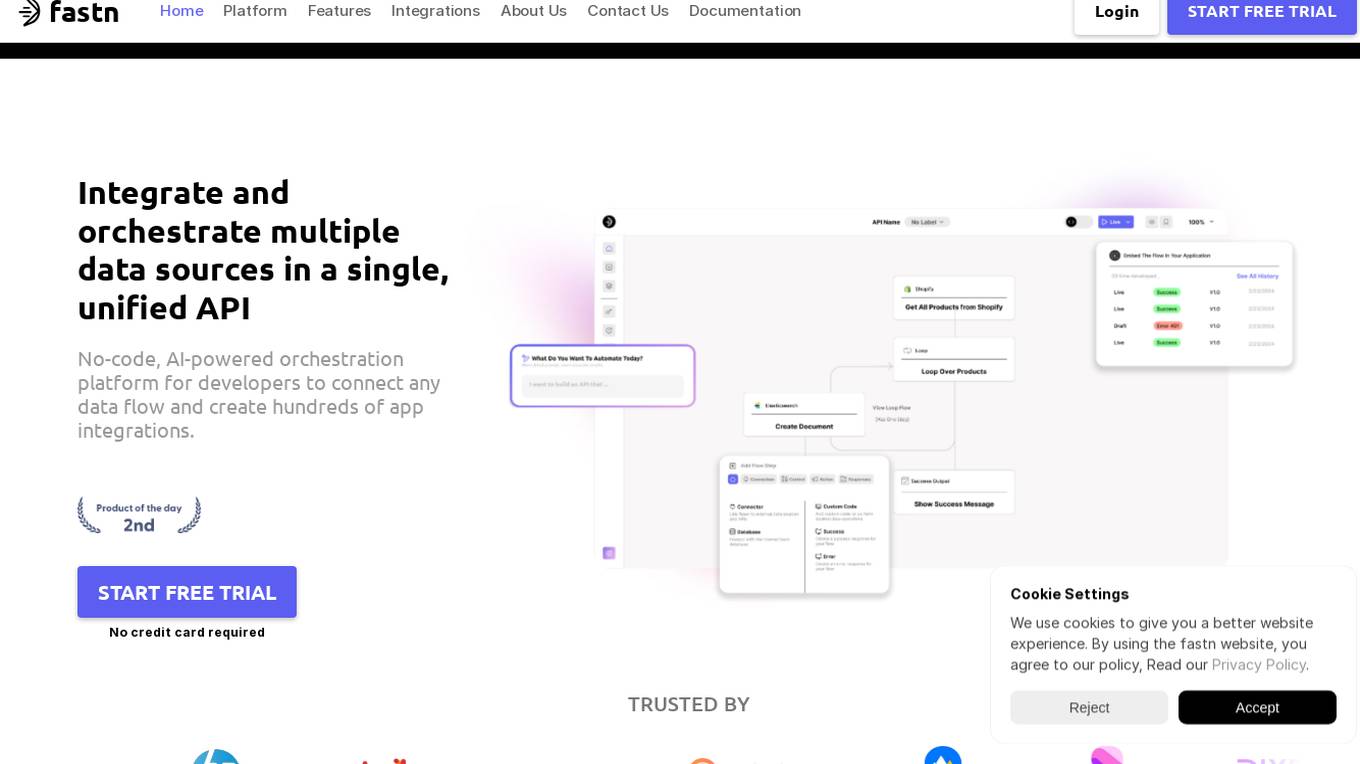
Fastn
Fastn is a no-code, AI-powered orchestration platform for developers to integrate and orchestrate multiple data sources in a single, unified API. It allows users to connect any data flow and create hundreds of app integrations efficiently. Fastn simplifies API integration, ensures API security, and handles data from multiple sources with features like real-time data orchestration, instant API composition, and infrastructure management on autopilot.
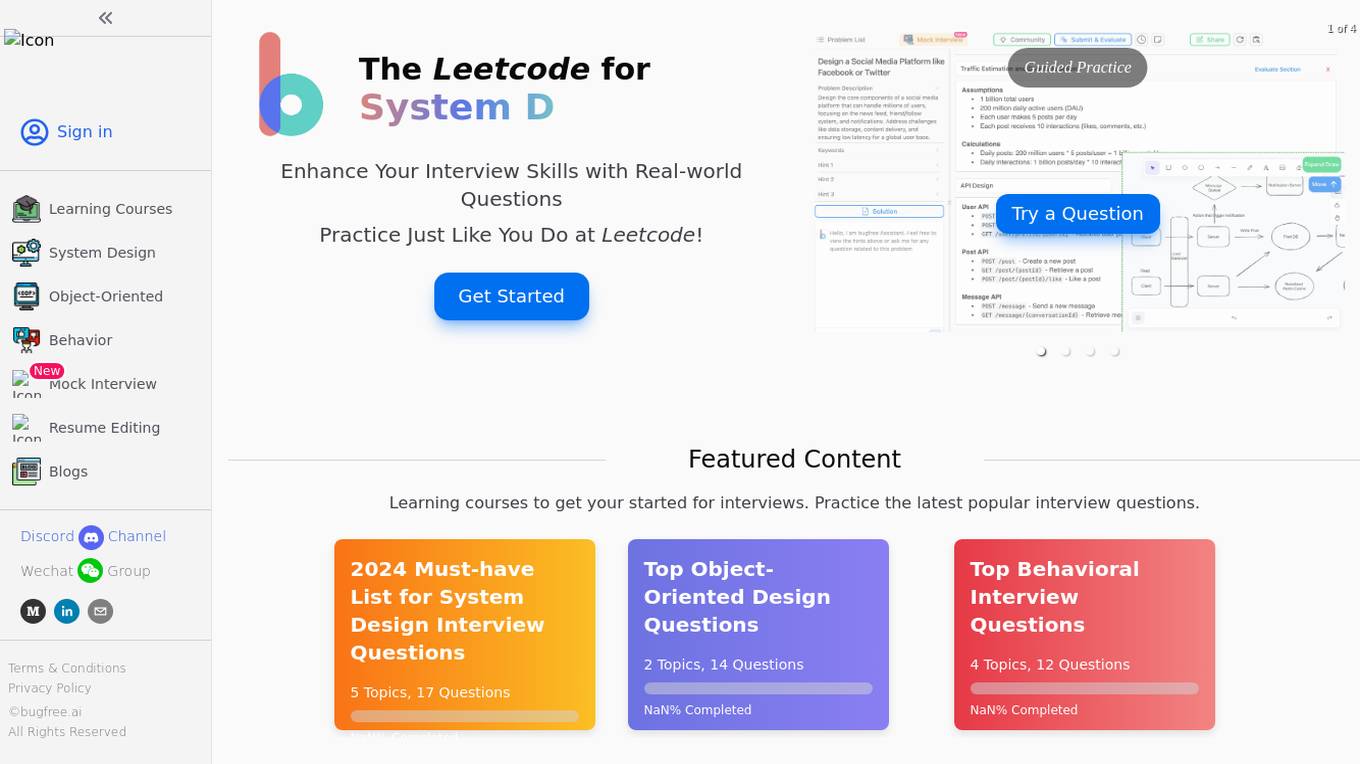
BugFree.ai
BugFree.ai is an AI-powered platform designed to help users practice system design and behavior interviews, similar to Leetcode. The platform offers a range of features to assist users in preparing for technical interviews, including mock interviews, real-time feedback, and personalized study plans. With BugFree.ai, users can improve their problem-solving skills and gain confidence in tackling complex interview questions.
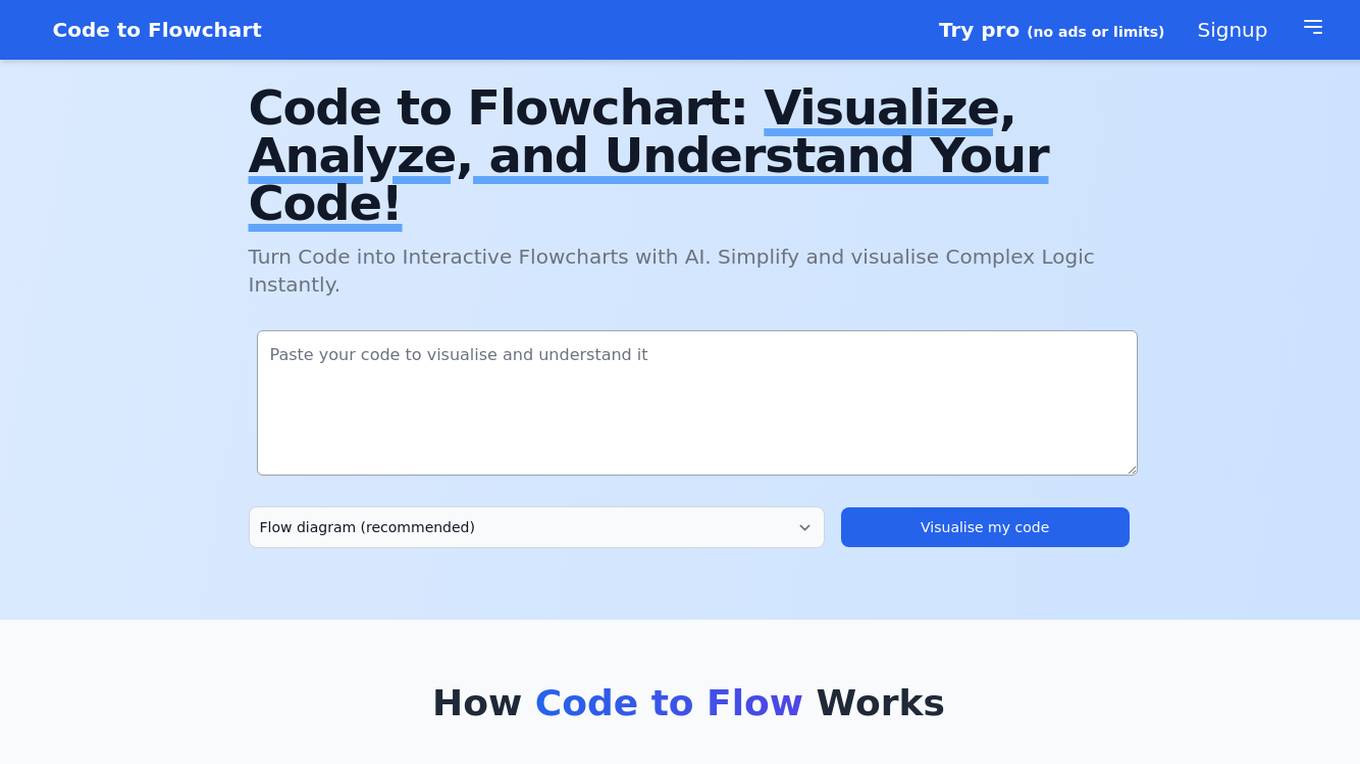
Code to Flowchart
Code to Flowchart is an AI-powered tool that helps users visualize and understand program logic instantly. It allows users to convert code into interactive flowcharts with the help of AI analysis. The tool supports all major programming languages, identifies code paths and logic flows, and offers multiple visualization options like flowcharts, sequence diagrams, and class diagrams. Users can export diagrams in various formats and customize color schemes and themes. Code to Flowchart aims to simplify complex code structures and enhance collaboration among developers.

Gorilla
Gorilla is an AI tool that integrates a large language model (LLM) with massive APIs to enable users to interact with a wide range of services. It offers features such as training the model to support parallel functions, benchmarking LLMs on function-calling capabilities, and providing a runtime for executing LLM-generated actions like code and API calls. Gorilla is open-source and focuses on enhancing interaction between apps and services with human-out-of-loop functionality.
Asaria Industries
Asaria Industries is an AI application that focuses on building intelligent systems to transform industries. They offer system architecture and AI integration services to help modernize enterprise infrastructure and implement intelligent decision systems. With expertise in engineering scalable foundations for complex systems, Asaria Industries aims to turn visions into reality through innovative solutions.

Emergence AI Platform
Emergence is an AI platform that offers an Orchestrator for coordinating interactions between AI agents across enterprise systems. It aims to help businesses overcome common hurdles, adapt to changing environments, and unlock their full potential by providing tools for building and orchestrating AI agents. The platform is designed for enterprise scalability, reliability, and predictability, allowing for intelligent routing, advanced agent capabilities, and no vendor lock-in.
AMD AI Solutions
AMD AI Solutions is a leading AI innovation platform with a broad portfolio, open ecosystem, and cutting-edge technology for data centers, edge computing, and clients. The platform offers end-to-end solutions powered by CPUs, GPUs, accelerators, networking, and open software, delivering unmatched flexibility and performance. AMD enables accelerated AI outcomes, sustained AI success, and is recognized as a trusted AI partner. With a commitment to minimizing costs, prioritizing security, and staying flexible, AMD empowers businesses and consumers to scale AI deployments effectively and efficiently.
Synopsys.ai
Synopsys is an AI-enabled EDA (Electronic Design Automation) tool that offers design, automation, insights, optimization, analytics, and expert workflows for chip development. It provides a comprehensive suite of solutions for chip design, verification, test, and production, catering to various industries such as automotive, aerospace, AI chip development, and more. Synopsys.ai focuses on fast heterogeneous integration and industry-leading AI-powered workflow optimization to help users achieve first-pass silicon success and accelerate innovation.
81 - Open Source Tools
FlowTest
FlowTestAI is the world’s first GenAI powered OpenSource Integrated Development Environment (IDE) designed for crafting, visualizing, and managing API-first workflows. It operates as a desktop app, interacting with the local file system, ensuring privacy and enabling collaboration via version control systems. The platform offers platform-specific binaries for macOS, with versions for Windows and Linux in development. It also features a CLI for running API workflows from the command line interface, facilitating automation and CI/CD processes.
oneAPI-samples
The oneAPI-samples repository contains a collection of samples for the Intel oneAPI Toolkits. These samples cover various topics such as AI and analytics, end-to-end workloads, features and functionality, getting started samples, Jupyter notebooks, direct programming, C++, Fortran, libraries, publications, rendering toolkit, and tools. Users can find samples based on expertise, programming language, and target device. The repository structure is organized by high-level categories, and platform validation includes Ubuntu 22.04, Windows 11, and macOS. The repository provides instructions for getting samples, including cloning the repository or downloading specific tagged versions. Users can also use integrated development environments (IDEs) like Visual Studio Code. The code samples are licensed under the MIT license.
airlift
Airlift is a framework for building REST services in Java. It provides a simple, light-weight package that includes built-in support for configuration, metrics, logging, dependency injection, and more. Airlift allows you to focus on building production-quality web services quickly by leveraging stable, mature libraries from the Java ecosystem. It aims to streamline the development process without imposing a large, proprietary framework.
param
PARAM Benchmarks is a repository of communication and compute micro-benchmarks as well as full workloads for evaluating training and inference platforms. It complements commonly used benchmarks by focusing on AI training with PyTorch based collective benchmarks, GEMM, embedding lookup, linear layer, and DLRM communication patterns. The tool bridges the gap between stand-alone C++ benchmarks and PyTorch/Tensorflow based application benchmarks, providing deep insights into system architecture and framework-level overheads.

dash-infer
DashInfer is a C++ runtime tool designed to deliver production-level implementations highly optimized for various hardware architectures, including x86 and ARMv9. It supports Continuous Batching and NUMA-Aware capabilities for CPU, and can fully utilize modern server-grade CPUs to host large language models (LLMs) up to 14B in size. With lightweight architecture, high precision, support for mainstream open-source LLMs, post-training quantization, optimized computation kernels, NUMA-aware design, and multi-language API interfaces, DashInfer provides a versatile solution for efficient inference tasks. It supports x86 CPUs with AVX2 instruction set and ARMv9 CPUs with SVE instruction set, along with various data types like FP32, BF16, and InstantQuant. DashInfer also offers single-NUMA and multi-NUMA architectures for model inference, with detailed performance tests and inference accuracy evaluations available. The tool is supported on mainstream Linux server operating systems and provides documentation and examples for easy integration and usage.
bee
Bee is an easy and high efficiency ORM framework that simplifies database operations by providing a simple interface and eliminating the need to write separate DAO code. It supports various features such as automatic filtering of properties, partial field queries, native statement pagination, JSON format results, sharding, multiple database support, and more. Bee also offers powerful functionalities like dynamic query conditions, transactions, complex queries, MongoDB ORM, cache management, and additional tools for generating distributed primary keys, reading Excel files, and more. The newest versions introduce enhancements like placeholder precompilation, default date sharding, ElasticSearch ORM support, and improved query capabilities.

LLM-Viewer
LLM-Viewer is a tool for visualizing Language and Learning Models (LLMs) and analyzing performance on different hardware platforms. It enables network-wise analysis, considering factors such as peak memory consumption and total inference time cost. With LLM-Viewer, users can gain valuable insights into LLM inference and performance optimization. The tool can be used in a web browser or as a command line interface (CLI) for easy configuration and visualization. The ongoing project aims to enhance features like showing tensor shapes, expanding hardware platform compatibility, and supporting more LLMs with manual model graph configuration.
flowgen
FlowGen is a tool built for AutoGen, a great agent framework from Microsoft and a lot of contributors. It provides intuitive visual tools that streamline the construction and oversight of complex agent-based workflows, simplifying the process for creators and developers. Users can create Autoflows, chat with agents, and share flow templates. The tool is fully dockerized and supports deployment on Railway.app. Contributions to the project are welcome, and the platform uses semantic-release for versioning and releases.
T-MAC
T-MAC is a kernel library that directly supports mixed-precision matrix multiplication without the need for dequantization by utilizing lookup tables. It aims to boost low-bit LLM inference on CPUs by offering support for various low-bit models. T-MAC achieves significant speedup compared to SOTA CPU low-bit framework (llama.cpp) and can even perform well on lower-end devices like Raspberry Pi 5. The tool demonstrates superior performance over existing low-bit GEMM kernels on CPU, reduces power consumption, and provides energy savings. It achieves comparable performance to CUDA GPU on certain tasks while delivering considerable power and energy savings. T-MAC's method involves using lookup tables to support mpGEMM and employs key techniques like precomputing partial sums, shift and accumulate operations, and utilizing tbl/pshuf instructions for fast table lookup.
ruoyi-vue-pro
The ruoyi-vue-pro repository is an open-source project that provides a comprehensive development platform with various functionalities such as system features, infrastructure, member center, data reports, workflow, payment system, mall system, ERP system, CRM system, and AI big model. It is built using Java backend with Spring Boot framework and Vue frontend with different versions like Vue3 with element-plus, Vue3 with vben(ant-design-vue), and Vue2 with element-ui. The project aims to offer a fast development platform for developers and enterprises, supporting features like dynamic menu loading, button-level access control, SaaS multi-tenancy, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and cloud services, and more.
yudao-cloud
Yudao-cloud is an open-source project designed to provide a fast development platform for developers in China. It includes various system functions, infrastructure, member center, data reports, workflow, mall system, WeChat public account, CRM, ERP, etc. The project is based on Java backend with Spring Boot and Spring Cloud Alibaba microservices architecture. It supports multiple databases, message queues, authentication systems, dynamic menu loading, SaaS multi-tenant system, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and more. The project is well-documented and follows the Alibaba Java development guidelines, ensuring clean code and architecture.
llumnix
Llumnix is a cross-instance request scheduling layer built on top of LLM inference engines such as vLLM, providing optimized multi-instance serving performance with low latency, reduced time-to-first-token (TTFT) and queuing delays, reduced time-between-tokens (TBT) and preemption stalls, and high throughput. It achieves this through dynamic, fine-grained, KV-cache-aware scheduling, continuous rescheduling across instances, KV cache migration mechanism, and seamless integration with existing multi-instance deployment platforms. Llumnix is easy to use, fault-tolerant, elastic, and extensible to more inference engines and scheduling policies.
glake
GLake is an acceleration library and utilities designed to optimize GPU memory management and IO transmission for AI large model training and inference. It addresses challenges such as GPU memory bottleneck and IO transmission bottleneck by providing efficient memory pooling, sharing, and tiering, as well as multi-path acceleration for CPU-GPU transmission. GLake is easy to use, open for extension, and focuses on improving training throughput, saving inference memory, and accelerating IO transmission. It offers features like memory fragmentation reduction, memory deduplication, and built-in security mechanisms for troubleshooting GPU memory issues.
iree-amd-aie
This repository contains an early-phase IREE compiler and runtime plugin for interfacing the AMD AIE accelerator to IREE. It provides architectural overview, developer setup instructions, building guidelines, and runtime driver setup details. The repository focuses on enabling the integration of the AMD AIE accelerator with IREE, offering developers the tools and resources needed to build and run applications leveraging this technology.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.
cool-admin-java
Cool-admin-java is an open-source backend permission management system with features like Ai coding, flow arrangement, modularity, and plugin support. It is used to quickly build backend applications. The system offers a modern development experience by providing functionalities such as one-click generation of API interfaces to frontend pages, drag-and-drop flow arrangement, modularized code for easy maintenance, and extensibility through plugin installation for features like payments, SMS, and emails.

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.

guidellm
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.
fastagency
FastAgency is a powerful tool that leverages the AutoGen framework to quickly build applications with multi-agent workflows. It supports various interfaces like ConsoleUI and MesopUI, allowing users to create interactive applications. The tool enables defining workflows between agents, such as students and teachers, and summarizing conversations. FastAgency aims to expand its capabilities by integrating with additional agentic frameworks like CrewAI, providing more options for workflow definition and AI tool integration.
Nanoflow
NanoFlow is a throughput-oriented high-performance serving framework for Large Language Models (LLMs) that consistently delivers superior throughput compared to other frameworks by utilizing key techniques such as intra-device parallelism, asynchronous CPU scheduling, and SSD offloading. The framework proposes nano-batching to schedule compute-, memory-, and network-bound operations for simultaneous execution, leading to increased resource utilization. NanoFlow also adopts an asynchronous control flow to optimize CPU overhead and eagerly offloads KV-Cache to SSDs for multi-round conversations. The open-source codebase integrates state-of-the-art kernel libraries and provides necessary scripts for environment setup and experiment reproduction.
spring-ai-examples
This repository contains various examples of using Spring AI. Users can clone the entire project or use SpringCLI to select individual projects and create them locally. It includes a project-catalog.yml for adding as a project catalog to Spring CLI. Users can create projects locally using 'spring boot new' or mix a project's functionality into an existing project using 'spring boot add'. Be cautious about building against newer versions of Spring Boot than your project, as it may lead to build or test errors.
llama_deploy
llama_deploy is an async-first framework for deploying, scaling, and productionizing agentic multi-service systems based on workflows from llama_index. It allows building workflows in llama_index and deploying them seamlessly with minimal changes to code. The system includes services endlessly processing tasks, a control plane managing state and services, an orchestrator deciding task handling, and fault tolerance mechanisms. It is designed for high-concurrency scenarios, enabling real-time and high-throughput applications.
bonsai
Bonsai is a Rust implementation of Behavior Trees, a data structure for setting rules on how behaviors occur and execute in a modular and reactive way. It is crucial in applications like AI and Robotics. Bonsai provides efficient ways to create complex systems using Behavior Trees, allowing users to define processes, conditions, and actions to build intelligent and adaptive systems.
AimRT
AimRT is a basic runtime framework for modern robotics, developed in modern C++ with lightweight and easy deployment. It integrates research and development for robot applications in various deployment scenarios, providing debugging tools and observability support. AimRT offers a plug-in development interface compatible with ROS2, HTTP, Grpc, and other ecosystems for progressive system upgrades.
screeps-starter-rust
screeps-starter-rust is a Rust AI starter kit for Screeps: World, a JavaScript-based MMO game. It utilizes the screeps-game-api bindings from the rustyscreeps organization and wasm-pack for building Rust code to WebAssembly. The example includes Rollup for bundling javascript, Babel for transpiling code, and screeps-api Node.js package for deployment. Users can refer to the Rust version of game APIs documentation at https://docs.rs/screeps-game-api/. The tool supports most crates on crates.io, except those interacting with OS APIs.
arch
Arch is an intelligent Layer 7 gateway designed to protect, observe, and personalize LLM applications with APIs. It handles tasks like detecting and rejecting jailbreak attempts, calling backend APIs, disaster recovery, and observability. Built on Envoy Proxy, it offers features like function calling, prompt guardrails, traffic management, and standards-based observability. Arch aims to improve the speed, security, and personalization of generative AI applications.
twelvet
Twelvet is a permission management system based on Spring Cloud Alibaba that serves as a framework for rapid development. It is a scaffolding framework based on microservices architecture, aiming to reduce duplication of business code and provide a common core business code for both microservices and monoliths. It is designed for learning microservices concepts and development, suitable for website management, CMS, CRM, OA, and other system development. The system is intended to quickly meet business needs, improve user experience, and save time by incubating practical functional points in lightweight, highly portable functional plugins.
swarmauri-sdk
Swarmauri SDK is a repository containing core interfaces, standard ABCs, and standard concrete references of the SwarmaURI Framework. It provides a set of tools and functionalities for developers to work with the SwarmaURI ecosystem. The SDK aims to streamline the development process and enhance the interoperability of applications within the framework. Developers can easily integrate SwarmaURI features into their projects by leveraging the resources available in this repository.
gitdiagram
GitDiagram is a tool that turns any GitHub repository into an interactive diagram for visualization in seconds. It offers instant visualization, interactivity, fast generation, customization, and API access. The tool utilizes a tech stack including Next.js, FastAPI, PostgreSQL, Claude 3.5 Sonnet, Vercel, EC2, GitHub Actions, PostHog, and Api-Analytics. Users can self-host the tool for local development and contribute to its development. GitDiagram is inspired by Gitingest and has future plans to use larger context models, allow user API key input, implement RAG with Mermaid.js docs, and include font-awesome icons in diagrams.
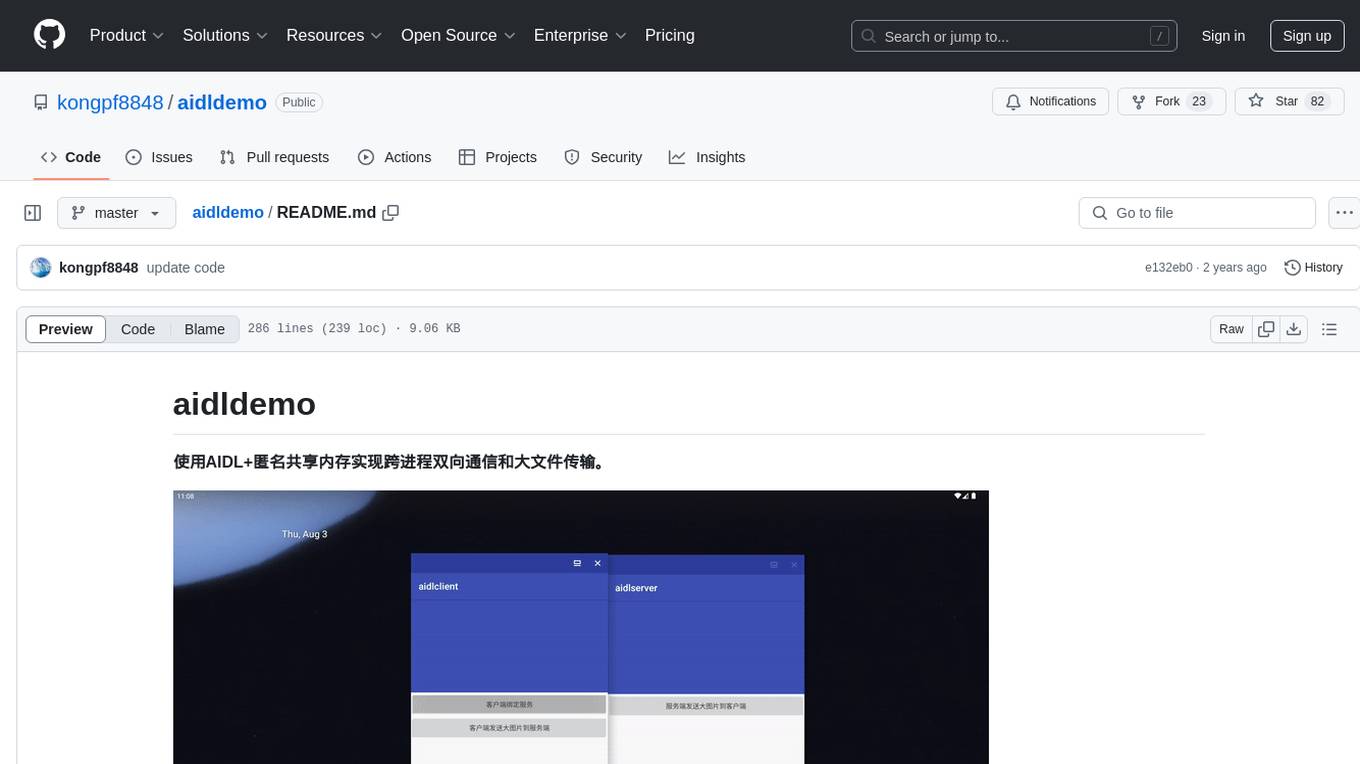
aidldemo
This repository demonstrates how to achieve cross-process bidirectional communication and large file transfer using AIDL and anonymous shared memory. AIDL is a way to implement Inter-Process Communication in Android, based on Binder. To overcome the data size limit of Binder, anonymous shared memory is used for large file transfer. Shared memory allows processes to share memory by mapping a common memory area into their respective process spaces. While efficient for transferring large data between processes, shared memory lacks synchronization mechanisms, requiring additional mechanisms like semaphores. Android's anonymous shared memory (Ashmem) is based on Linux shared memory and facilitates shared memory transfer using Binder and FileDescriptor. The repository provides practical examples of bidirectional communication and large file transfer between client and server using AIDL interfaces and MemoryFile in Android.
arc
The Arc project aims to leverage Kotlin DSL and Kotlin Scripting to create a language optimized for developing LLM powered solutions. It provides a framework for building projects using Kotlin and offers documentation and examples for implementation. The project follows the Contributor Covenant code of conduct and is licensed under Apache License 2.0 by Deutsche Telekom AG, adhering to the REUSE standard for software licensing.
inngest
Inngest is a platform that offers durable functions to replace queues, state management, and scheduling for developers. It allows writing reliable step functions faster without dealing with infrastructure. Developers can create durable functions using various language SDKs, run a local development server, deploy functions to their infrastructure, sync functions with the Inngest Platform, and securely trigger functions via HTTPS. Inngest Functions support retrying, scheduling, and coordinating operations through triggers, flow control, and steps, enabling developers to build reliable workflows with robust support for various operations.
StepWise
StepWise is a code-first, event-driven workflow framework for .NET designed to help users build complex workflows in a simple and efficient way. It allows users to define workflows using C# code, visualize and execute workflows from a browser, execute steps in parallel, and resolve dependencies automatically. StepWise also features an AI assistant called `Geeno` in its WebUI to help users run and analyze workflows with ease.
AgentNetworkProtocol
AgentNetworkProtocol (ANP) aims to define how agents connect with each other, building an open, secure, and efficient collaboration network for billions of intelligent agents. It addresses challenges in interconnectivity, native interfaces, and efficient collaboration by providing protocol layers for identity and encrypted communication, meta-protocol negotiation, and application protocol management. The project is developing an open-source implementation available on GitHub, with a vision to become the HTTP of the Intelligent Agent Internet era and establish ANP as an industry standard through a standardization committee. Contact the author Gaowei Chang via email, Discord, website, or GitHub for contributions or inquiries.

aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.
goodsKill
The 'goodsKill' project aims to build a complete project framework integrating good technologies and development techniques, mainly focusing on backend technologies. It provides a simulated flash sale project with unified flash sale simulation request interface. The project uses SpringMVC + Mybatis for the overall technology stack, Dubbo3.x for service intercommunication, Nacos for service registration and discovery, and Spring State Machine for data state transitions. It also integrates Spring AI service for simulating flash sale actions.
logicstudio.ai
LogicStudio.ai is a powerful visual canvas-based tool for building, managing, and visualizing complex logic flows involving AI agents, data inputs, and outputs. It provides an intuitive interface to streamline development processes by offering features like drag-and-drop canvas design, dynamic components, real-time connections, import/export capabilities, zoom & pan controls, file management, AI integration, editable views, and various output formats. Users can easily add, connect, configure, and manage components to create interactive systems and workflows.
mcp-framework
MCP-Framework is a TypeScript framework for building Model Context Protocol (MCP) servers with automatic directory-based discovery for tools, resources, and prompts. It provides powerful abstractions, simple server setup, and a CLI for rapid development and project scaffolding.
LLMcalc
LLM Calculator is a script that estimates the memory requirements and performance of Hugging Face models based on quantization levels. It fetches model parameters, calculates required memory, and analyzes performance with different RAM/VRAM configurations. The tool supports Windows and Linux, AMD, Intel, and Nvidia GPUs. Users can input a Hugging Face model ID to get its parameter count and analyze memory requirements for various quantization schemes. The tool provides estimates for GPU offload percentage and throughput in tk/s. It requires dependencies like python, uv, pciutils for AMD + Linux, and drivers for Nvidia. The tool is designed for rough estimates and may not work with MultiGPU setups.

nx
Nx is a build system optimized for monorepos, featuring AI-powered architectural awareness and advanced CI capabilities. It provides faster task scheduling, caching, and more for existing workspaces. Nx Cloud enhances CI by offering remote caching, task distribution, automated e2e test splitting, and task flakiness detection. The tool aims to scale monorepos efficiently and improve developer productivity.
mcpdotnet
mcpdotnet is a .NET implementation of the Model Context Protocol (MCP), facilitating connections and interactions between .NET applications and MCP clients and servers. It aims to provide a clean, specification-compliant implementation with support for various MCP capabilities and transport types. The library includes features such as async/await pattern, logging support, and compatibility with .NET 8.0 and later. Users can create clients to use tools from configured servers and also create servers to register tools and interact with clients. The project roadmap includes expanding documentation, increasing test coverage, adding samples, performance optimization, SSE server support, and authentication.
orra
Orra is a tool for building production-ready multi-agent applications that handle complex real-world interactions. It coordinates tasks across existing stack, agents, and tools run as services using intelligent reasoning. With features like smart pre-evaluated execution plans, domain grounding, durable execution, and automatic service health monitoring, Orra enables users to go fast with tools as services and revert state to handle failures. It provides real-time status tracking and webhook result delivery, making it ideal for developers looking to move beyond simple crews and agents.
interaqt
Interaqt is a project that aims to separate application business logic from its specific implementation by providing a structured data model and tools to automatically decide and implement software architecture. It liberates individuals and teams from implementation specifics, performance requirements, and cost demands, allowing them to focus on articulating business logic. The approach is considered optimal in the era of large language models (LLMs) as it eliminates uncertainty in generated systems and enables independence from engineering involvement unless specific capabilities are required.

1backend
1Backend is a flexible and scalable platform designed for running AI models on private servers and handling high-concurrency workloads. It provides a ChatGPT-like interface for users and a network-accessible API for machines, serving as a general-purpose backend framework. The platform offers on-premise ChatGPT alternatives, a microservices-first web framework, out-of-the-box services like file uploads and user management, infrastructure simplification acting as a container orchestrator, reverse proxy, multi-database support with its own ORM, and AI integration with platforms like LlamaCpp and StableDiffusion.
llm-inference-calculator
A web-based calculator to estimate hardware requirements for running Large Language Models (LLMs) in inference mode. This tool helps determine VRAM and system RAM needed for different LLM configurations. It calculates VRAM requirements based on model size, quantization method, context length, and KV cache settings. It provides estimates for required VRAM, minimum system RAM, on-disk model size, and number of GPUs needed. The project uses React, TypeScript, and Vite. Docker support is available with instructions provided. The tool provides approximations for calculations, includes overhead for KV cache, and assumes certain percentages for unified memory and discrete GPU calculations.
AgentIQ
AgentIQ is a flexible library designed to seamlessly integrate enterprise agents with various data sources and tools. It enables true composability by treating agents, tools, and workflows as simple function calls. With features like framework agnosticism, reusability, rapid development, profiling, observability, evaluation system, user interface, and MCP compatibility, AgentIQ empowers developers to move quickly, experiment freely, and ensure reliability across agent-driven projects.

maiar-ai
MAIAR is a composable, plugin-based AI agent framework designed to abstract data ingestion, decision-making, and action execution into modular plugins. It enables developers to define triggers and actions as standalone plugins, while the core runtime handles decision-making dynamically. This framework offers extensibility, composability, and model-driven behavior, allowing seamless addition of new functionality. MAIAR's architecture is influenced by Unix pipes, ensuring highly composable plugins, dynamic execution pipelines, and transparent debugging. It remains declarative and extensible, allowing developers to build complex AI workflows without rigid architectures.

dbhub
DBHub is a universal database gateway that implements the Model Context Protocol (MCP) server interface. It allows MCP-compatible clients to connect to and explore different databases. The gateway supports various database resources and tools, providing capabilities such as executing queries, listing connectors, generating SQL, and explaining database elements. Users can easily configure their database connections and choose between different transport modes like stdio and sse. DBHub also offers a demo mode with a sample employee database for testing purposes.

chat
deco.chat is an open-source foundation for building AI-native software, providing developers, engineers, and AI enthusiasts with robust tools to rapidly prototype, develop, and deploy AI-powered applications. It empowers Vibecoders to prototype ideas and Agentic engineers to deploy scalable, secure, and sustainable production systems. The core capabilities include an open-source runtime for composing tools and workflows, MCP Mesh for secure integration of models and APIs, a unified TypeScript stack for backend logic and custom frontends, global modular infrastructure built on Cloudflare, and a visual workspace for building agents and orchestrating everything in code.
mcp-for-beginners
The Model Context Protocol (MCP) Curriculum for Beginners is an open-source framework designed to standardize interactions between AI models and client applications. It offers a structured learning path with practical coding examples and real-world use cases in popular programming languages like C#, Java, JavaScript, Rust, Python, and TypeScript. Whether you're an AI developer, system architect, or software engineer, this guide provides comprehensive resources for mastering MCP fundamentals and implementation strategies.
FastDeploy
FastDeploy is an inference and deployment toolkit for large language models and visual language models based on PaddlePaddle. It provides production-ready deployment solutions with core acceleration technologies such as load-balanced PD disaggregation, unified KV cache transmission, OpenAI API server compatibility, comprehensive quantization format support, advanced acceleration techniques, and multi-hardware support. The toolkit supports various hardware platforms like NVIDIA GPUs, Kunlunxin XPUs, Iluvatar GPUs, Enflame GCUs, and Hygon DCUs, with plans for expanding support to Ascend NPU and MetaX GPU. FastDeploy aims to optimize resource utilization, throughput, and performance for inference and deployment tasks.
evalica
Evalica is a powerful tool for evaluating code quality and performance in software projects. It provides detailed insights and metrics to help developers identify areas for improvement and optimize their code. With support for multiple programming languages and frameworks, Evalica offers a comprehensive solution for code analysis and optimization. Whether you are a beginner looking to learn best practices or an experienced developer aiming to enhance your code quality, Evalica is the perfect tool for you.
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering key topics such as system overview, AI computing clusters, communication and storage, cluster containers and cloud-native technologies, distributed training, distributed inference, large model algorithms and data, and applications of large models.
gpt-load
GPT-Load is a high-performance, enterprise-grade AI API transparent proxy service designed for enterprises and developers needing to integrate multiple AI services. Built with Go, it features intelligent key management, load balancing, and comprehensive monitoring capabilities for high-concurrency production environments. The tool serves as a transparent proxy service, preserving native API formats of various AI service providers like OpenAI, Google Gemini, and Anthropic Claude. It supports dynamic configuration, distributed leader-follower deployment, and a Vue 3-based web management interface. GPT-Load is production-ready with features like dual authentication, graceful shutdown, and error recovery.
private-ml-sdk
Private ML SDK is a secure solution for running Large Language Models (LLMs) in Trusted Execution Environments (TEEs) using NVIDIA GPU TEE and Intel TDX technologies. It provides a tamper-proof data processing environment with secure execution, open-source builds, and nearly native speed performance. The system includes components like Secure Compute Environment, Remote Attestation, Secure Communication, and Key Management Service (KMS). Users can build TDX guest images, run Local KMS, and TDX guest images on TDX host machines with Nvidia GPUs. The SDK offers verifiable execution results and high performance for LLM workloads.
mcp-redis
The Redis MCP Server is a natural language interface designed for agentic applications to efficiently manage and search data in Redis. It integrates seamlessly with MCP (Model Content Protocol) clients, enabling AI-driven workflows to interact with structured and unstructured data in Redis. The server supports natural language queries, seamless MCP integration, full Redis support for various data types, search and filtering capabilities, scalability, and lightweight design. It provides tools for managing data stored in Redis, such as string, hash, list, set, sorted set, pub/sub, streams, JSON, query engine, and server management. Installation can be done from PyPI or GitHub, with options for testing, development, and Docker deployment. Configuration can be via command line arguments or environment variables. Integrations include OpenAI Agents SDK, Augment, Claude Desktop, and VS Code with GitHub Copilot. Use cases include AI assistants, chatbots, data search & analytics, and event processing. Contributions are welcome under the MIT License.

guidellm
GuideLLM is a platform for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM enables users to assess the performance, resource requirements, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. The tool provides features for performance evaluation, resource optimization, cost estimation, and scalability testing.
AI-fundermentals
AI Fundamentals is a comprehensive AI infrastructure learning resource collection, covering a complete technical stack from hardware basics to advanced applications. It includes GPU architecture and programming, CUDA development, large language models, AI system design, performance optimization, enterprise deployment, and more. The repository aims to provide a systematic learning path and practical guidance for AI engineers, architects, GPU programming developers, large model application developers, and technical researchers.
llm-d-kv-cache-manager
Efficiently caching Key & Value (KV) tensors is crucial for optimizing LLM inference. Reusing the KV-Cache significantly improves Time To First Token (TTFT) and overall throughput, maximizing system resource-utilization. `llm-d-kv-cache-manager` is a pluggable service enabling KV-Cache Aware Routing for vLLM-based serving platforms, with a high-performance KV-Cache Indexer component tracking KV-Block locality across vLLM pods. It provides intelligent routing for optimal KV-cache-aware placement decisions.

flow-like
Flow-Like is an enterprise-grade workflow operating system built upon Rust for uncompromising performance, efficiency, and code safety. It offers a modular frontend for apps, a rich set of events, a node catalog, a powerful no-code workflow IDE, and tools to manage teams, templates, and projects within organizations. With typed workflows, users can create complex, large-scale workflows with clear data origins, transformations, and contracts. Flow-Like is designed to automate any process through seamless integration of LLM, ML-based, and deterministic decision-making instances.

angular-node-java-ai
This repository contains a project that integrates Angular frontend, Node.js backend, Java services, and AI capabilities. The project aims to demonstrate a full-stack application with modern technologies and AI features. It showcases how to build a scalable and efficient system using Angular for the frontend, Node.js for the backend, Java for services, and AI for advanced functionalities.
solon
Solon is a Java enterprise application development framework that is restrained, efficient, and open. It offers better cost performance for computing resources with 700% higher concurrency and 50% memory savings. It enables faster development productivity with less code and easy startup, 10 times faster than traditional methods. Solon provides a better production and deployment experience by packing applications 90% smaller. It supports a greater range of compatibility with non-Java-EE architecture and compatibility with Java 8 to Java 24, including GraalVM native image support. Solon is built from scratch with flexible interface specifications and an open ecosystem.
kvcached
kvcached is a new KV cache management system that supports on-demand KV cache allocation. It implements the concept of GPU virtual memory, allowing applications to reserve virtual address space without immediately committing physical memory. Physical memory is then automatically allocated and mapped as needed at runtime. This capability allows multiple LLMs to run concurrently on a single GPU or a group of GPUs (TP) and flexibly share the GPU memory, significantly improving GPU utilization and reducing memory fragmentation. kvcached is compatible with popular LLM serving engines, including SGLang and vLLM.
mcp-ts-template
The MCP TypeScript Server Template is a production-grade framework for building powerful and scalable Model Context Protocol servers with TypeScript. It features built-in observability, declarative tooling, robust error handling, and a modular, DI-driven architecture. The template is designed to be AI-agent-friendly, providing detailed rules and guidance for developers to adhere to best practices. It enforces architectural principles like 'Logic Throws, Handler Catches' pattern, full-stack observability, declarative components, and dependency injection for decoupling. The project structure includes directories for configuration, container setup, server resources, services, storage, utilities, tests, and more. Configuration is done via environment variables, and key scripts are available for development, testing, and publishing to the MCP Registry.
ISEK
ISEK is a decentralized agent network framework that enables building intelligent, collaborative agent-to-agent systems. It integrates the Google A2A protocol and ERC-8004 contracts for identity registration, reputation building, and cooperative task-solving, creating a self-organizing, decentralized society of agents. The platform addresses challenges in the agent ecosystem by providing an incentive system for users to pay for agent services, motivating developers to build high-quality agents and fostering innovation and quality in the ecosystem. ISEK focuses on decentralized agent collaboration and coordination, allowing agents to find each other, reason together, and act as a decentralized system without central control. The platform utilizes ERC-8004 for decentralized identity, reputation, and validation registries, establishing trustless verification and reputation management.
Awesome-Repo-Level-Code-Generation
This repository contains a collection of tools and scripts for generating code at the repository level. It provides a set of utilities to automate the process of creating and managing code across multiple files and directories. The tools included in this repository aim to improve code generation efficiency and maintainability by streamlining the development workflow. With a focus on enhancing productivity and reducing manual effort, this collection offers a variety of code generation options and customization features to suit different project requirements.
Sage
Sage is a production-ready, modular, and intelligent multi-agent orchestration framework for complex problem solving. It intelligently breaks down complex tasks into manageable subtasks through seamless agent collaboration. Sage provides Deep Research Mode for comprehensive analysis and Rapid Execution Mode for quick task completion. It offers features like intelligent task decomposition, agent orchestration, extensible tool system, dual execution modes, interactive web interface, advanced token tracking, rich configuration, developer-friendly APIs, and robust error recovery mechanisms. Sage supports custom workflows, multi-agent collaboration, custom agent development, agent flow orchestration, rule preferences system, message manager for smart token optimization, task manager for comprehensive state management, advanced file system operations, advanced tool system with plugin architecture, token usage & cost monitoring, and rich configuration system. It also includes real-time streaming & monitoring, advanced tool development, error handling & reliability, performance monitoring, MCP server integration, and security features.

a2a-java
A2A Java SDK is a Java library that helps run agentic applications as A2AServers following the Agent2Agent (A2A) Protocol. It provides a Java server implementation of the A2A Protocol, allowing users to create A2A server agents and execute tasks. The SDK also includes a Java client implementation for communication with A2A servers using various transports like JSON-RPC 2.0, gRPC, and HTTP+JSON/REST. Users can configure different transport protocols, handle messages, tasks, push notifications, and interact with server agents. The SDK supports streaming and non-streaming responses, error handling, and task management functionalities.
innoshop
InnoShop is an innovative open-source e-commerce system based on Laravel 12. It supports multiple languages, multiple currencies, and is integrated with OpenAI. The system features plugin mechanisms and theme template development for enhanced user experience and system extensibility. It is globally oriented, user-friendly, and based on the latest technology with deep AI integration.

SpecForge
SpecForge is a powerful tool for generating API specifications from code. It helps developers to easily create and maintain accurate API documentation by extracting information directly from the codebase. With SpecForge, users can streamline the process of documenting APIs, ensuring consistency and reducing manual effort. The tool supports various programming languages and frameworks, making it versatile and adaptable to different development environments. By automating the generation of API specifications, SpecForge enhances collaboration between developers and stakeholders, improving overall project efficiency and quality.
Roo-Code
Roo Code is an AI-powered development tool that integrates with your code editor to help you generate code from natural language descriptions and specifications, refactor and debug existing code, write and update documentation, answer questions about your codebase, automate repetitive tasks, and utilize MCP servers. It offers different modes such as Code, Architect, Ask, Debug, and Custom Modes to adapt to various tasks and workflows. Roo Code provides tutorial and feature videos, documentation, a YouTube channel, a Discord server, a Reddit community, GitHub issues tracking, and a feature request platform. Users can set up and develop Roo Code locally by cloning the repository, installing dependencies, and running the extension in development mode or by automated/manual VSIX installation. The tool uses changesets for versioning and publishing. Please note that Roo Code, Inc. does not make any representations or warranties regarding the tools provided, and users assume all risks associated with their use.

unified-cache-management
Unified Cache Manager (UCM) is a tool designed to persist the LLM KVCache and replace redundant computations through various retrieval mechanisms. It supports prefix caching and offers training-free sparse attention retrieval methods, enhancing performance for long sequence inference tasks. UCM also provides a PD disaggregation solution based on a storage-compute separation architecture, enabling easier management of heterogeneous computing resources. When integrated with vLLM, UCM significantly reduces inference latency in scenarios like multi-turn dialogue and long-context reasoning tasks.
parallax
Parallax is a fully decentralized inference engine developed by Gradient. It allows users to build their own AI cluster for model inference across distributed nodes with varying configurations and physical locations. Core features include hosting local LLM on personal devices, cross-platform support, pipeline parallel model sharding, paged KV cache management, continuous batching for Mac, dynamic request scheduling, and routing for high performance. The backend architecture includes P2P communication powered by Lattica, GPU backend powered by SGLang and vLLM, and MAC backend powered by MLX LM.

caracal
Caracal is a pre-execution authority enforcement system for AI agents and automated software operating in production environments. It enforces a single rule: no action executes unless there is explicit, valid authority for that action at that moment. Caracal offers two interfaces: Caracal Flow for operators, FinOps, and monitoring teams, and Caracal Core for developers, CI/CD engineers, and system architects. Core capabilities include dynamic identity & access, budget enforcement, secure ledger, and agent-native data model. The infrastructure is designed to scale with environments for local and production setups.
llmos
LLMos is an operating system designed for physical AI agents, providing a hybrid runtime environment where AI agents can perceive, reason, act on hardware, and evolve over time locally without cloud dependency. It allows natural language programming, dual-brain architecture for fast instinct and deep planner brains, markdown-as-code for defining agents and skills, and supports swarm intelligence and cognitive world models. The tool is built on a tech stack including Next.js, Electron, Python, and WebAssembly, and is structured around a dual-brain cognitive architecture, volume system, HAL for hardware abstraction, applet system for dynamic UI, and dreaming & evolution for robot improvement. The project is in Phase 1 (Foundation) and aims to move into Phase 2 (Dual-Brain & Local Intelligence), with contributions welcomed under the Apache 2.0 license by Evolving Agents Labs.
llm-d-kv-cache
Efficiently caching Key & Value (KV) tensors is crucial for optimizing LLM inference. Reusing the KV-Cache significantly improves Time To First Token (TTFT) and overall throughput, maximizing system resource utilization. `llm-d-kv-cache` is a pluggable service for KV-Cache Aware Routing in vLLM-based serving platforms, providing comprehensive KV-Cache management capabilities. The repository includes the KV-Cache Indexer, a high-performance library for global KV-Cache block locality view across vLLM pods, powered by KVEvents for intelligent routing and optimal cache-aware placement decisions.

xllm-service
xLLM-service is a service-layer framework developed based on the xLLM inference engine, providing efficient, fault-tolerant, and flexible LLM inference services for clustered deployment. It addresses challenges in enterprise-level service scenarios such as ensuring SLA of online services, improving resource utilization, reacting to changing request loads, resolving performance bottlenecks, and ensuring high reliability of computing instances. With features like unified scheduling, adaptive dynamic allocation, EPD three-stage disaggregation, and fault-tolerant architecture, xLLM-service offers efficient and reliable LLM inference services.
eventcatalog
EventCatalog is an architecture catalog for distributed systems that allows users to document events, services, domains, and flows with AI-powered discovery. It provides features such as AI-native discovery, visual documentation, multi-platform support, enterprise readiness, and customization. The tool is organized as a Turborepo monorepo with different modules for the main catalog application, Node.js SDK, and CLI scaffolding tool. EventCatalog is purpose-built for distributed systems and event-driven architectures, offering advantages over generic documentation tools, vendor-specific tools, and service catalogs.
agentpool
AgentPool is a unified agent orchestration hub that allows users to configure and manage heterogeneous AI agents via YAML and expose them through standardized protocols. It acts as a protocol bridge, enabling users to define all agents in one YAML file and expose them through ACP or AG-UI protocols. Users can coordinate, delegate, and communicate with different agents through a unified interface. The tool supports multi-agent coordination, rich YAML configuration, server protocols like ACP and OpenCode, and additional capabilities such as structured output, storage & analytics, file abstraction, triggers, and streaming TTS. It offers CLI and programmatic usage patterns for running agents and interacting with the tool.
llm-checker
LLM Checker is an AI-powered CLI tool that analyzes your hardware to recommend optimal LLM models. It features deterministic scoring across 35+ curated models with hardware-calibrated memory estimation. The tool helps users understand memory bandwidth, VRAM limits, and performance characteristics to choose the right LLM for their hardware. It provides actionable recommendations in seconds by scoring compatible models across four dimensions: Quality, Speed, Fit, and Context. LLM Checker is designed to work on any Node.js 16+ system, with optional SQLite search features for advanced functionality.
20 - OpenAI Gpts
System Design Tutor
A System Architect Coach guiding you through system design principles and best practices. Explains CAP theorem like no one else
Software Architect
Expert in software architecture, ensuring integrity and scalability through best practices.

Diagrams: Show Me | charts, presentations, code
Diagram creation: flowcharts, mindmaps, UML, chart, PlotUML, workflow, sequence, ERD, database & architecture visualization for code, presentations and documentation. [New] Add a logo or any image to graph diagrams. Easy Download & Edit
Diagramas: Muéstrame
Cree diagramas, visualizaciones de arquitectura, diagramas de flujo, mapas mentales, esquemas y más. Ideal para codificación, presentaciones y documentación de códigos. ¡Exporta y edita tu diagrama gratis!

Octorate Code Companion
I help developers understand and use APIs, referencing a YAML model.

Software Architecture Visualiser
A tool that automatically generates interactive, real-time diagrams like PlantUML from codebases, aiding in the understanding and design of software systems

IoT Architect Advisor
Versatile IoT expertise for advice, explanations, and troubleshooting


🌟Technical diagrams pro🌟
Create UML for flowcharts, Class, Sequence, Use Case, and Activity diagrams using PlantUML. System design and cloud infrastructure diagrams for AWS, Azue and GCP. No login required.
