
T-MAC
Low-bit LLM inference on CPU with lookup table
Stars: 482
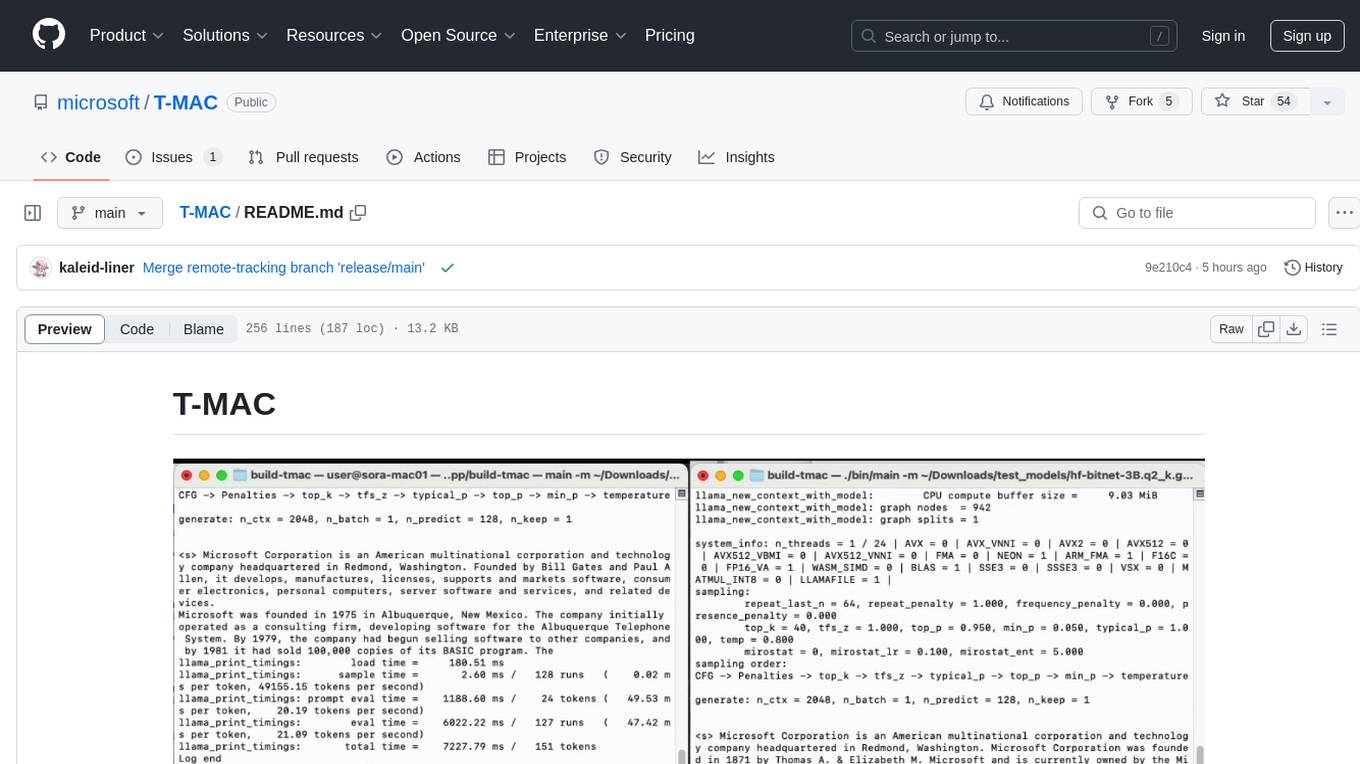
T-MAC is a kernel library that directly supports mixed-precision matrix multiplication without the need for dequantization by utilizing lookup tables. It aims to boost low-bit LLM inference on CPUs by offering support for various low-bit models. T-MAC achieves significant speedup compared to SOTA CPU low-bit framework (llama.cpp) and can even perform well on lower-end devices like Raspberry Pi 5. The tool demonstrates superior performance over existing low-bit GEMM kernels on CPU, reduces power consumption, and provides energy savings. It achieves comparable performance to CUDA GPU on certain tasks while delivering considerable power and energy savings. T-MAC's method involves using lookup tables to support mpGEMM and employs key techniques like precomputing partial sums, shift and accumulate operations, and utilizing tbl/pshuf instructions for fast table lookup.
README:

BitNet on M2-Ultra with T-MAC (LUT-based) vs llama.cpp (dequantization-based)

BitNet and Phi-3.5 tokens/s with # of CPU cores on Surface Laptop 7
-
10/10/2024 🚀🚀: By updating and rebasing our llama.cpp version, T-MAC now support more models (e.g., qwen2) and the end-to-end performance is further improved by 10~15%! Try qwen2 using the Official GPTQ model.
-
08/21/2024 🎉🎉: T-MAC paper is accepted by EuroSys 2025.
-
08/17/2024 🚀: T-MAC now supports 1/2/4-bit quantized models of (almost) any architecture in GPTQ format.
-
08/14/2024 🚀: The T-MAC GEMM (N>1) kernels are now integrated into llama.cpp to accelerate prefill. Check Prefill speedup for speedup.
-
07/27/2024 ✨: We've noted that T-MAC is even faster than the NPU in token generation speed on the latest Snapdragon X Elite chipset! Check Compared to NPU for more details.
-
07/23/2024 🚀🚀: We've enabled the execution of any 2-bit quantized Llama model in GPTQ format via T-MAC! Test it using the pretrained models released by EfficientQAT.
-
07/22/2024 🚀🚀: We've added native deployment support for Windows on ARM. T-MAC demonstrates a substantial 5x speedup on the Surface Laptop 7.
T-MAC is a kernel library to directly support mixed-precision matrix multiplication (int1/2/3/4 x int8/fp16/fp32) without the need for dequantization by utilizing lookup tables. T-MAC aims to boost low-bit LLM inference on CPUs. T-MAC already offers support for various low-bit models, including W4A16 from GPTQ/gguf, W2A16 from BitDistiller/EfficientQAT and W1(.58)A8 from BitNet on OSX/Linux/Windows equipped with ARM/Intel CPUs.
T-MAC achieves a token generation throughput of 20 tokens/sec with a single core and 48 tokens/sec with four cores on Surface Laptop 7 for 3B BitNet, which is a 4~5x speedup compared to SOTA CPU low-bit framework (llama.cpp). T-MAC can even reach 11 tokens/sec on lower-end devices like Raspberry Pi 5.
All of the following data is profiled based on llama.cpp b2794 (May 2024). The latest T-MAC and baseline, after updating the llama.cpp version, is further optimized by 10~15%.
We evaluate the token generation performance of different models on five different devices: Surface Laptop 7, Apple M2-Ultra, Jetson AGX Orin, Raspberry Pi 5 and Surface Book 3. Check datasheet for more details.
We evaluate BitNet-3B and Llama-2-7B (W2) with T-MAC 2-bit and llama.cpp Q2_K, and evaluate Llama-2-7B (W4) with T-MAC 4-bit and llama.cpp Q4_0.
In addition to providing a significant speedup, T-MAC can also match the same performance using fewer CPU cores. For instance, to reach 40 tokens/sec, a throughput that greatly surpasses human reading speed, T-MAC only requires 2 cores, while llama.cpp requires 8 cores. On Jetson AGX Orin, to achieve 10 tokens/sec, a throughput that already meets human reading speed, T-MAC only requires 2 cores, while llama.cpp uses all 12 cores. T-MAC can meet real-time requirements on less powerful devices equipped with fewer CPU cores like Raspberry Pi 5. By using fewer cores, T-MAC can reserve computational resources for other applications and significantly reduce power and energy consumption, both of which are crucial for edge devices.

T-MAC achieves significant speedup at single-threads and consumes much less CPU cores to reach the same throughput
The throughputs of T-MAC are obtained without fast-aggregation. Users can toggle on fast-aggregation through
-fato achieve an additional speedup of 10%~20% with.
The figure above shows that when the model size is increased to 7B-4bit, the multi-threading throughput of llama.cpp on Surface Laptop 7 becomes highly unstable due to the thermal threshold under Better Performance mode. This instability is not observed with T-MAC, as LUT is more energy-efficient compared to multiply-add operations. To establish a more solid baseline, we re-profile the performance under the Best Performance mode:

The throughput of T-MAC and llama.cpp both increase by maximizing CPU frequency
However, under real-world situations, CPUs can't maintain maximum frequency consistently on edge devices. The performance of llama.cpp will degrade as indicated by the results under the Better Performance mode.
TODO: add more results
We have compared the prefill throughput (input_len=256) for Llama-2-7b (W2) on Surface Laptop 7 with two baselines:
- llama.cpp: llama.cpp optimized dequant-based low-bit kernels
- llama.cpp (OpenBLAS): llama.cpp OpenBLAS backend
| Model | NUM_THREADS | Batch Size | T-MAC (tokens/sec) | llama.cpp (OpenBLAS) | llama.cpp |
|---|---|---|---|---|---|
| llama-2-7b (W2) | 4 | 256 | 50.1 | 21.5 | 12.0 |
| llama-2-7b (W2) | 8 | 256 | 94.4 | 37.7 | 21.3 |
Our GEMM kernels demonstrate superior performance over SOTA low-bit GEMM on CPU. The following figure shows the speedup compared to llama.cpp for llama-7b kernels during token generation (NUM_THREADS=1):

llama.cpp doesn't provide 1-bit kernel implementation, but we can deduce it from the 2-bit, as it won't bring additional speedup according to the 2/3/4-bit results.
Surface stands for Surface Book 3 in this section.
T-MAC can achieve significant speedup for multi-batch (N>1) GEMM due to reduced computaional cost, which ensures superior performance on prompt evaluation and multi-batch token generation. The following figures shows the speedup compared to llama.cpp using OpenBLAS backend (NUM_THREADS=1):

M2-Ultra is an exception as it is equipped with a specially designed AMX coprocessor to accelerate multi-batch GEMM. However, T-MAC can still achieve comparable performance at 2-bit.
By replacing heavy fused-multiply-add instructions with table lookup instructions, T-MAC significantly reduces power consumption. Combined with the speedup, T-MAC ultimately results in a substantial decrease in total energy consumption.

Multi-threading power/energy consumption on M2-Ultra for three models, M1: Llama-2-7B (W4), M2: Llama-2-7B (W2) and M3: BitNet-3B
Data sampled with powermetrics.
On the latest Snapdragon X Elite chipset, CPU through T-MAC achieves better performance compared to NPU through Qualcomm Snapdragon Neural Processing Engine (NPE).
When deploying the llama-2-7b-4bit model on it, the NPU can only generate 10.4 tokens/sec (according to the data released here), while the CPU using T-MAC can reach 12.6 tokens/sec with two cores, and even up to 22 tokens/sec. Considering that T-MAC's computing performance can linearly improve with the number of bits decreases (which is not observable on GPUs and NPUs based on dequantization), T-MAC can even match the NPU with a single-core CPU at 2 bits.
| Framework | Model | NUM_THREADS | Throughput (tokens/sec) |
|---|---|---|---|
| T-MAC (CPU) | llama-2-7b (W4) | 2 | 12.6 |
| T-MAC (CPU) | llama-2-7b (W4) | 4 | 18.7 |
| T-MAC (CPU) | llama-2-7b (W2) | 1 | 9.3 |
| T-MAC (CPU) | llama-2-7b (W2) | 4 | 28.4 |
| NPE (NPU) | llama-2-7b (W4) | - | 10.4 |
For fair comparison, we have aligned our settings with those of the NPU, including a input length of 1024 and an output length of 1024. Although Qualcomms deploy a model of 3.6GB, we deploy a slightly larger model of 3.7GB, due to our token-embed remaining un-quantized.
By maximizing CPU frequency, T-MAC (CPU) can even get better results. Refer to the discussion in End-2-End speedup.
T-MAC achieves comparable 2-bit mpGEMM performance compared to CUDA GPU on Jetson AGX Orin. While the CUDA GPU outperforms the CPU in executing kernels other than mpGEMM, making the end-to-end performance of T-MAC (CPU) slightly slower, T-MAC can deliver considerable savings in power and energy consumption.
| Framework | Throughput (tokens/sec) | Power (W) | Energy (J/token) |
|---|---|---|---|
| llama.cpp (CPU) | 7.08 | 15.0 | 2.12 |
| llama.cpp (GPU) | 20.03 | 30.8 | 1.54 |
| T-MAC (CPU) | 15.62 | 10.4 | 0.66 |
Throughput/power/energy comparison for Llama-2-7B (W2) on NVIDIA Jetson AGX Orin (NUM_THREADS=12 for CPU)
Data sampled with jetson-stats under power mode MAXN.
- Python (3.8 required for TVM)
- virtualenv
- cmake>=3.22
First, install cmake, zstd (dependency of llvm) and libomp (dependency of tvm). Homebrew is recommended:
brew install cmake zlib libompIf
zstdis installed through homebrew, thancmakeshould also be installed through homebrew to ensure thatzstdcan be found bycmake.
Install t_mac from the source (please run in a virtualenv):
git clone --recursive https://github.com/microsoft/T-MAC.git
# in virtualenv
pip install -e . -v
source build/t-mac-envs.shThe command will download clang+llvm and build tvm from source. So it might take a bit of time.
Install cmake>=3.22 from Official Page.
Then install TVM build dependencies:
sudo apt install build-essential libtinfo-dev zlib1g-dev libzstd-dev libxml2-devInstall t_mac from the source (please run in a virtualenv):
git clone --recursive https://github.com/microsoft/T-MAC.git
# in virtualenv
pip install -e . -v
source build/t-mac-envs.shThe command will download clang+llvm and build tvm from source. So it might take a bit of time.
Note: We have noticed many users attempting to evaluate T-MAC on old-gen x86 platforms. However, x86 CPUs vary dramatically, and due to unawareness of AI workloads, most of these platforms have extremely low memory bandwidth (even lower than Raspberry Pi 5). Our current tests do not encompass all x86 platforms, particularly older generations. As a result, we cannot guarantee significant speedup (especially for 4-bit token generation) on all x86 platforms. We recommend Surface Book 3 or ARM devices to evaluate T-MAC.
Due to lack of stable clang+llvm prebuilt on Windows, Conda + Visual Studio is recommended to install dependencies.
First, install Visual Studio 2019 and toggle on Desk development with C++ and C++ Clang tools for Windows. Then, create conda environment within Developer PowerShell for VS 2019:
git clone --recursive https://github.com/microsoft/T-MAC.git
cd T-MAC
conda env create --file conda\tvm-build-environment.yaml
conda activate tvm-buildIf you are using Visual Studio 2022, replace
llvmdev =14.0.6withllvmdev =17.0.6in the yaml file.
After that, build TVM with:
cd 3rdparty\tvm
mkdir build
cp cmake\config.cmake buildAppend set(USE_LLVM llvm-config) to build\config.cmake.
cd build
cmake .. -A x64
cmake --build . --config Release -- /mInstall t_mac from the source:
cd ..\..\..\ # back to project root directory
$env:MANUAL_BUILD = "1"
$env:PYTHONPATH = "$pwd\3rdparty\tvm\python"
pip install -e . -vThe following process could be more complicated. However, if your deployment scenerio doesn't require a native build, you can use WSL/docker and follow the Ubuntu guide.
First, install Visual Studio 2022(/2019) and toggle on Desk development with C++. Then, create conda environment within Developer PowerShell for VS 20XX.
git clone --recursive https://github.com/microsoft/T-MAC.git
cd T-MAC
conda env create --file conda\tvm-build-environment.yaml
conda activate tvm-buildRemember to replace llvmdev =14.0.6 with llvmdev =17.0.6 in the yaml file if you are using Visual Studio 2022 (which is recommended on ARM64 for better performance).
After that, build TVM with:
cd 3rdparty\tvm
mkdir build
cp cmake\config.cmake buildAppend set(USE_LLVM llvm-config) to build\config.cmake.
cd build
cmake .. -A x64 # Build TVM in x64, as Python and dependencies are x64
cmake --build . --config Release -- /mIf you encounter errors like
string sub-command regex, mode replace: regex "$" matched an empty string.during runningcmake .. -A x64while building TVM, don't worry, and just runcmake .. -A x64again. Check this issue of LLVM for more details.
As clang tools in Visual Studio are in fact emulated x64 tools, please install the native arm64 tools manually.
- Install CMake from Offical Windows ARM installer.
- Download Ninja from Release Page and add to Path.
- Install Clang from Release Page.
Run the following commands outside of Developer Command Prompt/Powershell for VS to ensure our native clang tools are used.
Install t_mac from the source:
conda activate tvm-build
conda uninstall cmake # To prevent potential conflict with the native ARM64 cmake
cd ..\..\..\ # back to project root directory
$env:MANUAL_BUILD = "1"
$env:PYTHONPATH = "$pwd\3rdparty\tvm\python"
pip install wmi # To detect the native ARM64 CPU within x86_64 python
pip install -e . -vFirst, follow the normal workflow to install T-MAC on your PC (OSX/Ubuntu recommended).
Then, refer to Android Cross Compilation Guidance.
After that, you can verify the installation through: python -c "import t_mac; print(t_mac.__version__); from tvm.contrib.clang import find_clang; print(find_clang())".
Currently, we supports end-to-end inference through llama.cpp integration.
We have provided an all-in-one script. Invoke it with:
pip install 3rdparty/llama.cpp/gguf-py
huggingface-cli download 1bitLLM/bitnet_b1_58-3B --local-dir ${model_dir}
python tools/run_pipeline.py -o ${model_dir}We have also supported models in GTPQ format from GPTQModel/EfficientQAT. Try it out with officially released EfficientQAT (of GPTQ format) Llama-3-8b-instruct-w2-g128:
huggingface-cli download ChenMnZ/Llama-3-8b-instruct-EfficientQAT-w2g128-GPTQ --local-dir ${model_dir}
python tools/run_pipeline.py -o ${model_dir} -m llama-3-8b-2bit
Use
-por-sargument to select the steps you want to run.Use
-uargument to use our prebuilt kernels for ARM.Use
-m gptq-autofor GPTQ models not in preset. The kernel shapes and quantization configurations will be automatically detected and validated.We have supported mainstream LLM models in GPTQ format (e.g., Llama-2, Llama-3, Mistral, Phi-3-mini, etc). Some models are unsupported by convert script. We welcome contributions from community.
An example output:
Running STEP.0: Compile kernels
Running command in /Users/user/jianyu/T-MAC/deploy:
python compile.py -o tuned -da -nt 4 -tb -gc -gs 128 -ags 64 -t -m hf-bitnet-3b -r
Running STEP.1: Build T-MAC C++ CMakeFiles
Running command in /Users/user/jianyu/T-MAC/build:
cmake -DCMAKE_INSTALL_PREFIX=/Users/user/jianyu/T-MAC/install ..
Running STEP.2: Install T-MAC C++
Running command in /Users/user/jianyu/T-MAC/build:
cmake --build . --target install --config Release
Running STEP.3: Convert HF to GGUF
Running command in /Users/user/jianyu/T-MAC/3rdparty/llama.cpp:
python convert-hf-to-gguf-t-mac.py /Users/user/Downloads/test_models/hf-bitnet-3B --outtype i2 --outfile /Users/user/Downloads/test_models/hf-bitnet-3B/ggml-model.i2.gguf --kcfg /Users/user/jianyu/T-MAC/install/lib/kcfg.ini
Running STEP.4: Build llama.cpp CMakeFiles
Running command in /Users/user/jianyu/T-MAC/3rdparty/llama.cpp/build:
cmake .. -DLLAMA_TMAC=ON -DCMAKE_PREFIX_PATH=/Users/user/jianyu/T-MAC/install/lib/cmake/t-mac -DCMAKE_BUILD_TYPE=Release -DLLAMA_LLAMAFILE_DEFAULT=OFF -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++
Running STEP.5: Build llama.cpp
Running command in /Users/user/jianyu/T-MAC/3rdparty/llama.cpp/build:
cmake --build . --target main --config Release
Running STEP.6: Run inference
Running command in /Users/user/jianyu/T-MAC/3rdparty/llama.cpp/build:
/Users/user/jianyu/T-MAC/3rdparty/llama.cpp/build/bin/main -m /Users/user/Downloads/test_models/hf-bitnet-3B/ggml-model.i2.gguf -n 128 -t 4 -p Microsoft Corporation is an American multinational corporation and technology company headquartered in Redmond, Washington. -b 1 -ngl 0 -c 2048
Check logs/2024-07-15-17-10-11.log for inference output
Please note that main is used here do demo token generation output. Use 3rdparty/llama.cpp/build/bin/llama-bench to benchmark performance. A benchmark script is also provided at tools/bench_e2e.py.
Check T-MAC v1.0.0 release plan for upcoming features.
LLM inference incurs significant computational cost. Low-bit quantization, a widely adopted technique, introduces the challenge of mixed-precision GEMM (mpGEMM), which is not directly supported by hardware and requires convert/dequant operations.
We propose the use of a lookup table (LUT) to support mpGEMM. Our method involves the following key technniques:
- Given the low precision of weights, we group one-bit weights (e.g., into groups of 4), precompute all possible partial sums, and then use a LUT to store them.
- We employ shift and accumulate operations to support scalable bits from 1 to 4.
- On a CPU, we utilize tbl/pshuf instructions for fast table lookup.
- We reduce the table size from $2^n$ to $2^{n-1}$, incorporating a sign bit to accelerate LUT precomputation.
Our method exhibits several notable characteristics:
- T-MAC shows a linear scaling ratio of FLOPs and inference latency relative to the number of bits. This contrasts with traditional convert-based methods, which fail to achieve additional speedup when reducing from 4 bits to lower bits.
- T-MAC inherently supports bit-wise computation for int1/2/3/4, eliminating the need for dequantization. Furthermore, it accommodates all types of activations (e.g., fp8, fp16, int8) using fast table lookup and add instructions, bypassing the need for poorly supported fused-multiply-add instructions.
If you find this repository useful, please use the following BibTeX entry for citation.
@misc{wei2024tmaccpurenaissancetable,
title={T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge},
author={Jianyu Wei and Shijie Cao and Ting Cao and Lingxiao Ma and Lei Wang and Yanyong Zhang and Mao Yang},
year={2024},
eprint={2407.00088},
archivePrefix={arXiv},
primaryClass={cs.DC},
url={https://arxiv.org/abs/2407.00088},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for T-MAC
Similar Open Source Tools
T-MAC
T-MAC is a kernel library that directly supports mixed-precision matrix multiplication without the need for dequantization by utilizing lookup tables. It aims to boost low-bit LLM inference on CPUs by offering support for various low-bit models. T-MAC achieves significant speedup compared to SOTA CPU low-bit framework (llama.cpp) and can even perform well on lower-end devices like Raspberry Pi 5. The tool demonstrates superior performance over existing low-bit GEMM kernels on CPU, reduces power consumption, and provides energy savings. It achieves comparable performance to CUDA GPU on certain tasks while delivering considerable power and energy savings. T-MAC's method involves using lookup tables to support mpGEMM and employs key techniques like precomputing partial sums, shift and accumulate operations, and utilizing tbl/pshuf instructions for fast table lookup.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.
open-chatgpt
Open-ChatGPT is an open-source library that enables users to train a hyper-personalized ChatGPT-like AI model using their own data with minimal computational resources. It provides an end-to-end training framework for ChatGPT-like models, supporting distributed training and offloading for extremely large models. The project implements RLHF (Reinforcement Learning with Human Feedback) powered by transformer library and DeepSpeed, allowing users to create high-quality ChatGPT-style models. Open-ChatGPT is designed to be user-friendly and efficient, aiming to empower users to develop their own conversational AI models easily.
llmfit
llmfit is a terminal tool designed to optimize LLM models for your system's RAM, CPU, and GPU. It detects your hardware, scores models based on quality, speed, fit, and context, and recommends models that will run well on your machine. It supports multi-GPU setups, MoE architectures, dynamic quantization selection, and speed estimation. The tool provides an interactive TUI and a classic CLI mode for ease of use. It includes a database of 94 models from 30 providers sourced from the HuggingFace API, with memory requirements computed from parameter counts across a quantization hierarchy. llmfit uses multi-dimensional scoring to rank models and estimates speed based on backend-specific constants. It also offers dynamic quantization selection to fit models to available memory efficiently.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.

ichigo
Ichigo is a local real-time voice AI tool that uses an early fusion technique to extend a text-based LLM to have native 'listening' ability. It is an open research experiment with improved multiturn capabilities and the ability to refuse processing inaudible queries. The tool is designed for open data, open weight, on-device Siri-like functionality, inspired by Meta's Chameleon paper. Ichigo offers a web UI demo and Gradio web UI for users to interact with the tool. It has achieved enhanced MMLU scores, stronger context handling, advanced noise management, and improved multi-turn capabilities for a robust user experience.

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.
AirConnect-Synology
AirConnect-Synology is a minimal Synology package that allows users to use AirPlay to stream to UPnP/Sonos & Chromecast devices that do not natively support AirPlay. It is compatible with DSM 7.0 and DSM 7.1, and provides detailed information on installation, configuration, supported devices, troubleshooting, and more. The package automates the installation and usage of AirConnect on Synology devices, ensuring compatibility with various architectures and firmware versions. Users can customize the configuration using the airconnect.conf file and adjust settings for specific speakers like Sonos, Bose SoundTouch, and Pioneer/Phorus/Play-Fi.
For similar tasks
T-MAC
T-MAC is a kernel library that directly supports mixed-precision matrix multiplication without the need for dequantization by utilizing lookup tables. It aims to boost low-bit LLM inference on CPUs by offering support for various low-bit models. T-MAC achieves significant speedup compared to SOTA CPU low-bit framework (llama.cpp) and can even perform well on lower-end devices like Raspberry Pi 5. The tool demonstrates superior performance over existing low-bit GEMM kernels on CPU, reduces power consumption, and provides energy savings. It achieves comparable performance to CUDA GPU on certain tasks while delivering considerable power and energy savings. T-MAC's method involves using lookup tables to support mpGEMM and employs key techniques like precomputing partial sums, shift and accumulate operations, and utilizing tbl/pshuf instructions for fast table lookup.
FDE.AI-docs
FDE.AI-docs is a repository containing various texts related to FeraDroid Engine (FDE), an All-in-One ultimate optimizer for Android devices. FDE.AI optimizes performance and power consumption by configuring settings based on individual device hardware and software characteristics. It is compatible with a wide range of devices and Android OS versions, applying systemless changes for customization without touching the system partition.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.