Best AI tools for< Support Low-bit Models >
20 - AI tool Sites
Seeing AI
Seeing AI is a free app designed for the blind and low vision community. It utilizes AI technology to narrate the world around users, assisting with tasks such as reading, describing photos, and identifying products. The app is an ongoing research project that evolves based on feedback from the community and advancements in AI research.
Be My Eyes
Be My Eyes is an AI-powered visual assistance application that connects blind and low-vision users with volunteers and companies worldwide. Users can request live video support, receive assistance through artificial intelligence, and access professional support from partners. The app aims to improve accessibility for individuals with visual impairments by providing a platform for real-time assistance and support.
Be My Eyes
Be My Eyes is a free mobile app that connects blind and low-vision people with sighted volunteers and AI-powered assistance. With Be My Eyes, blind and low-vision people can access visual information, get help with everyday tasks, and connect with others in the community. Be My Eyes is available in over 180 languages and has over 6 million volunteers worldwide.
Millis AI
Millis AI is an advanced AI tool that enables users to effortlessly create next-gen voice agents with ultra-low latency, providing a seamless and natural conversational experience. It offers affordable pricing, integration with various services through webhooks, and the ability to connect phone numbers to AI voice agents for inbound/outbound calls in over 100 countries. With Millis AI, users can build and deploy voice agents in minutes, from no-code to low-code developers, and transform voice interactions across industries.

ContractWorks
ContractWorks is a contract management software that helps businesses organize, track, and manage their contracts. It offers a centralized repository for storing contracts, automated alerts and notifications, custom reporting, and electronic signature capabilities. ContractWorks also uses AI to power its search and review機能, allowing users to quickly find any contract, clause, or key term. With ContractWorks, businesses can improve contract visibility, reduce risk, and save time and money.
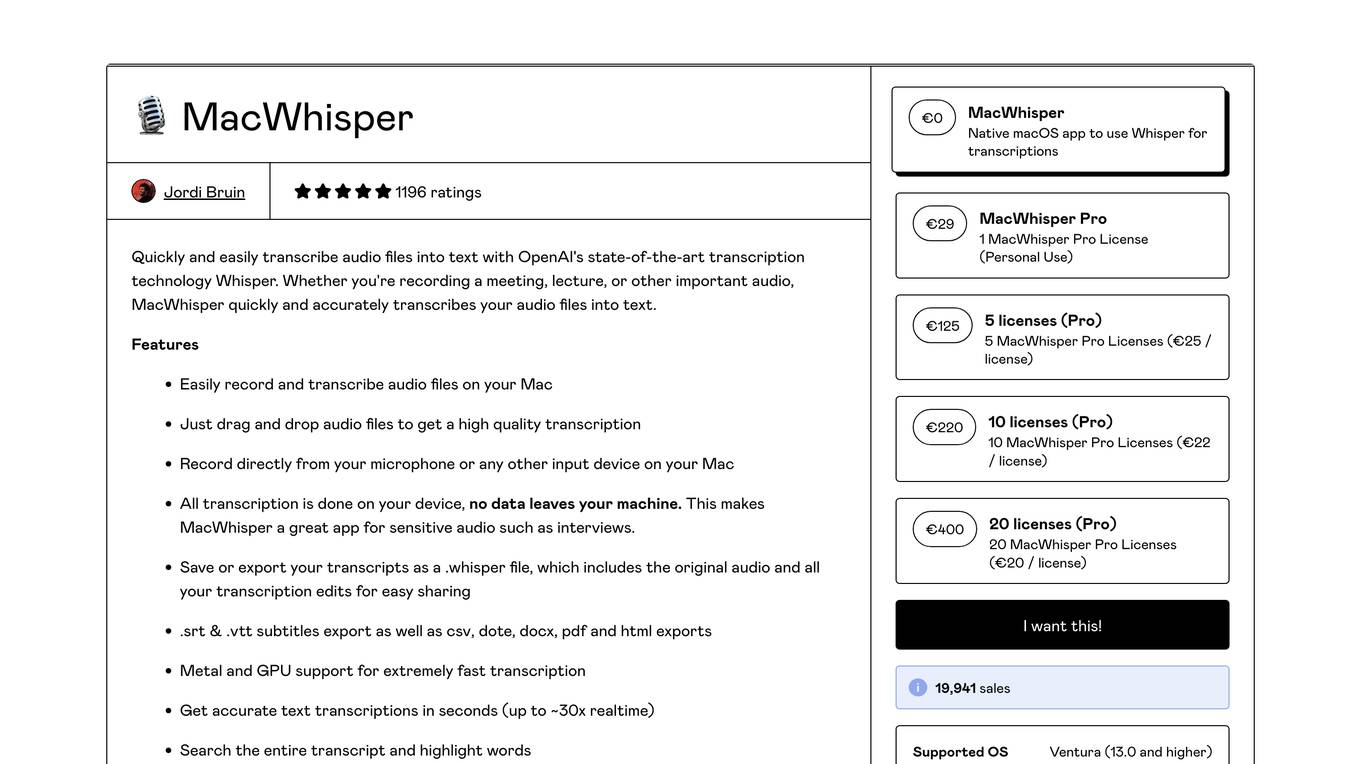
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
Dynaboard
Dynaboard is a collaborative low-code IDE for developers that allows users to build web apps in minutes using a drag-and-drop builder, a flexible code-first UI framework, and the power of generative AI. With Dynaboard, users can connect to popular databases, SaaS apps, or any API with GraphQL or REST endpoints, and secure their apps using any existing OIDC compliant provider. Dynaboard also offers unlimited editors for team collaboration, multi-environment deployment support, automatic versioning, and easy roll-backs for production-grade confidence.
LMNT
LMNT is an ultrafast lifelike AI speech pricing API that offers low latency streaming for conversational apps, agents, and games. It provides lifelike voices through studio-quality voice clones and instant voice clones. Engineered by an ex-Google team, LMNT ensures reliable performance under pressure with consistent low latency and high availability. The platform enables real-time conversation, content creation at scale, and product marketing through captivating voiceovers. With a user-friendly interface and developer API, LMNT simplifies voice cloning and synthesis for both beginners and professionals.
Read Easy.ai
Read Easy.ai is an AI tool designed to make text easy to read for individuals with low literacy skills. It offers powerful tools for editors, readers, and developers to enhance readability and inclusivity. With features like Microsoft Office Add-ins, Chrome Extension, and Developer API, Read Easy.ai aims to improve text comprehension and accessibility for diverse audiences across multiple languages.
GDPR Local
GDPR Local is an AI tool that provides comprehensive compliance solutions for data protection and AI law. The platform offers services such as compliance hub, AI law compliance, data protection consultancy, GDPR Art.27 EU/UK and Art.14 FADP Swiss Representative services, and Data Protection Officer support. With experienced consultants and a range of tools, GDPRLocal helps businesses achieve global data privacy and AI law compliance efficiently.
FlutterFlow
FlutterFlow is a low-code development platform that enables users to build cross-platform mobile and web applications without writing code. It provides a visual interface for designing user interfaces, connecting data, and implementing complex logic. FlutterFlow is trusted by users at leading companies around the world and has been used to build a wide range of applications, from simple prototypes to complex enterprise solutions.
Haptik
Haptik is a Conversational CRM platform powered by Generative AI, offering a suite of AI-powered solutions for customer experience, sales assistance, and self-serve support. It seamlessly integrates Generative AI into marketing, support, and operations to drive business efficiency at scale. Trusted by 500+ leading brands, Haptik provides bespoke AI solutions tailored to unique enterprise requirements across various industries. The platform leverages Generative AI to offer intelligent analytics, user behavior insights, and low code builder tools for creating conversational experiences across multiple channels like WhatsApp, Instagram, Messenger, Google Business Messages, and more.
FutureWorkForce
FutureWorkForce is an AI-driven platform that specializes in digital consulting, implementation, and support services. The platform leverages artificial intelligence, low code platforms, process mining, and automation to help organizations innovate, transform operations, enhance customer experiences, and drive new revenue streams. FutureWorkForce offers expertise in enterprise discovery, citizen development, enterprise automation, process excellence, application modernization, CoE augmentation, and managed services. The platform is trusted by leading companies for delivering savings, efficiencies, and service improvements through intelligent technologies.
Namecheap
Namecheap is a domain registrar and web hosting company. It offers a wide range of services, including domain registration, web hosting, email hosting, and security services. Namecheap is known for its low prices and its commitment to customer service. The company has been in business since 2000 and has over 10 million customers worldwide.
AIMLAPI.com
AIMLAPI.com is an AI tool that provides access to over 200 AI models through a single AI API. It offers a wide range of AI features for tasks such as chat, code, image generation, music generation, video, voice embedding, language, genomic models, and 3D generation. The platform ensures fast inference, top-tier serverless infrastructure, high data security, 99% uptime, and 24/7 support. Users can integrate AI features easily into their products and test API models in a sandbox environment before deployment.
PixieBrix
PixieBrix is an AI engagement platform that allows users to build, deploy, and manage internal AI tools to enhance team productivity. It unifies the AI landscape with oversight and governance for enterprise-scale operations, increasing speed, accuracy, compliance, and satisfaction. The platform leverages AI and automation to streamline workflows, improve user experience, and unlock untapped potential. With a focus on enterprise readiness and customization, PixieBrix offers extensibility, iterative innovation, scalability for teams, and an engaged community for idea exchange and support.

LatenceTech
LatenceTech is a tech startup that specializes in network latency monitoring and analysis. The platform offers real-time monitoring, prediction, and in-depth analysis of network latency using AI software. It provides cloud-based network analytics, versatile network applications, and data science-driven network acceleration. LatenceTech focuses on customer satisfaction by providing full customer experience service and expert support. The platform helps businesses optimize network performance, minimize latency issues, and achieve faster network speed and better connectivity.

RingConnect
RingConnect is an enterprise-grade Voice AI tool designed for businesses to automate and enhance their calling operations. It offers AI Voice Calls that drive more revenue by managing end-to-end calling processes, from qualifying prospects to booking meetings and supporting retention. With RingConnect, businesses can break free from time-consuming manual calls and scale their operations with AI voice technology that sounds just like a real human. The tool engages prospects around the clock, filters out low-intent leads, books appointments, revives old contacts, handles customer queries, and nurtures customer relationships at scale. Setting up AI voice calls is quick and easy, allowing users to create human-like AI voice agents in minutes.
RIMBASLOT
RIMBASLOT is an online slot website that allows users to deposit as low as 10 thousand rupiahs. It offers features like high RTP slots, easy maxwin opportunities, and a variety of slot games. Users can enjoy a seamless gaming experience with high winning chances and convenient transactions. The website provides a platform for users to play slots and win big prizes with minimal deposit requirements.

pgslotc4
pgslotc4 is a leading online slot website offering a wide range of slot games and casino options. With a focus on direct access and professional service, pgslotc4 ensures a safe and enjoyable gaming experience. The website features a variety of popular slot games, easy deposit and withdrawal options, and a user-friendly interface. Players can enjoy bonuses, automatic spinning, and low-stakes betting. pgslotc4 is licensed and regulated, providing a secure platform for players to explore and win real money rewards.
1 - Open Source AI Tools
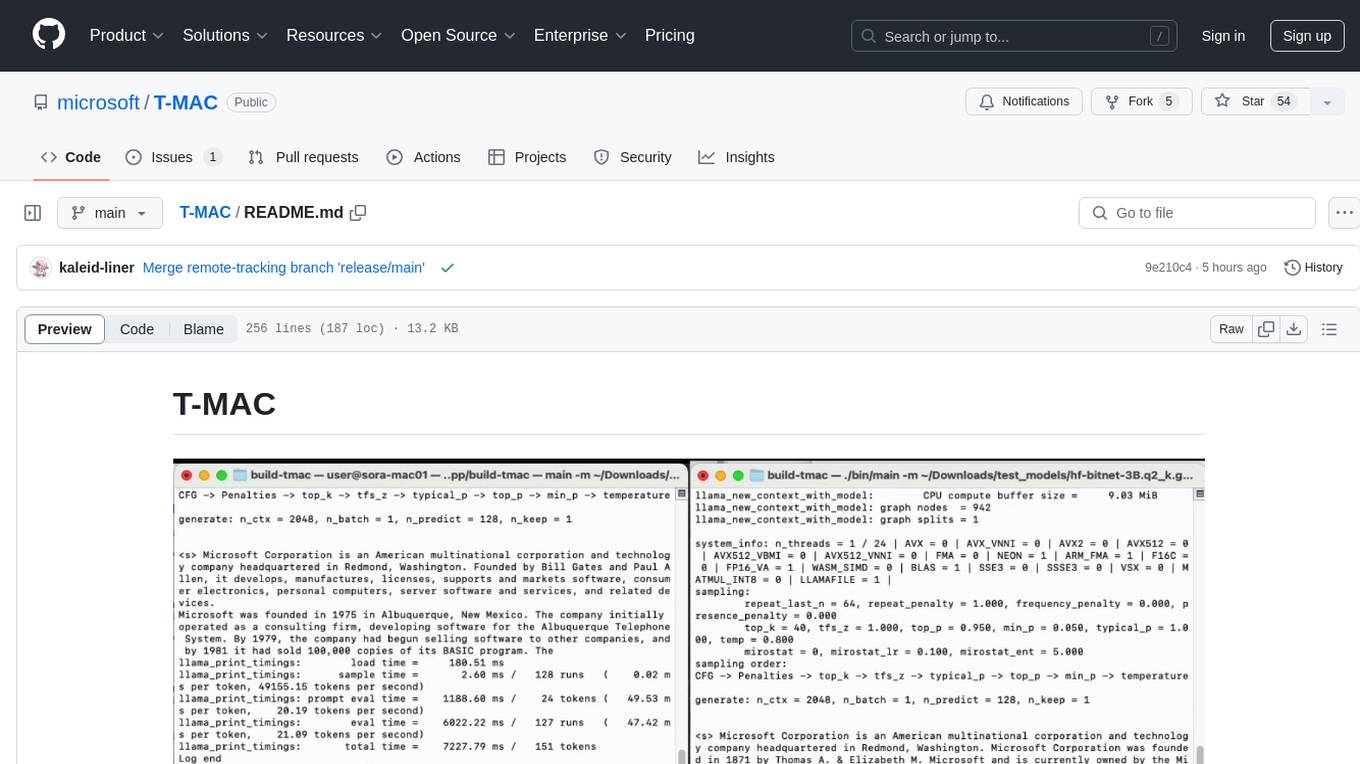
T-MAC
T-MAC is a kernel library that directly supports mixed-precision matrix multiplication without the need for dequantization by utilizing lookup tables. It aims to boost low-bit LLM inference on CPUs by offering support for various low-bit models. T-MAC achieves significant speedup compared to SOTA CPU low-bit framework (llama.cpp) and can even perform well on lower-end devices like Raspberry Pi 5. The tool demonstrates superior performance over existing low-bit GEMM kernels on CPU, reduces power consumption, and provides energy savings. It achieves comparable performance to CUDA GPU on certain tasks while delivering considerable power and energy savings. T-MAC's method involves using lookup tables to support mpGEMM and employs key techniques like precomputing partial sums, shift and accumulate operations, and utilizing tbl/pshuf instructions for fast table lookup.
20 - OpenAI Gpts
Power Automate Tutor
Learn at your own pace and empower your organization with self-service automation.
Ekko Support Specialist
How to be a master of surprise plays and unconventional strategies in the bot lane as a support role.
Backloger.ai -Support Log Analyzer and Summary
Drop your Support Log Here, Allowing it to automatically generate concise summaries reporting to the tech team.
Tech Support Advisor
From setting up a printer to troubleshooting a device, I’m here to help you step-by-step.

Z Support
Expert in Nissan 370Z & 350Z modifications, offering tailored vehicle upgrade advice.

Emotional Support Copywriter
A creative copywriter you can hang out with and who won't do their timesheets either.
PCT 365 Support Bot
Microsoft 365 support agent, redirects admin-level requests to PCT Support.
Technischer Support Bot
Ein Bot, der grundlegende technische Unterstützung und Fehlerbehebung für gängige Software und Hardware bietet.

Military Support
Supportive and informative guide on military, veterans, and military assistance.
Dror Globerman's GPT Tech Support
Your go-to assistant for everyday tech support and guidance.