
obs-localvocal
OBS plugin for local speech recognition and captioning using AI
Stars: 472
LocalVocal is a Speech AI assistant OBS Plugin that enables users to transcribe speech into text and translate it into any language locally on their machine. The plugin runs OpenAI's Whisper for real-time speech processing and prediction. It supports features like transcribing audio in real-time, displaying captions on screen, sending captions to files, syncing captions with recordings, and translating captions to major languages. Users can bring their own Whisper model, filter or replace captions, and experience partial transcriptions for streaming. The plugin is privacy-focused, requiring no GPU, cloud costs, network, or downtime.
README:





Download:
LocalVocal lets you transcribe, locally on your machine, speech into text and simultaneously translate to any language. ✅ No GPU required, ✅ no cloud costs, ✅ no network and ✅ no downtime! Privacy first - all data stays on your machine.
If this free plugin has been valuable consider adding a ⭐ to this GH repo, rating it on OBS, subscribing to my YouTube channel where I post updates, and supporting my work on GitHub, Patreon or OpenCollective 🙏
Internally the plugin is running OpenAI's Whisper to process real-time the speech and predict a transcription. It's using the Whisper.cpp project from ggerganov to run the Whisper network efficiently on CPUs and GPUs. Translation is done with CTranslate2.
https://youtu.be/ns4cP9HFTxQ
https://youtu.be/4llyfNi9FGs
https://youtu.be/R04w02qG26o
Do more with LocalVocal:
- Translate Caption any Application
- Real-time Translation with DeepL
- Real-time Translation with OpenAI
- ChatGPT + Text-to-speech
- POST Captions to YouTube
- Local LLM Real-time Translation
- Usage Tutorial
Current Features:
- Transcribe audio to text in real time in 100 languages
- Display captions on screen using text sources
- Send captions to a .txt or .srt file (to read by external sources or video playback) with and without aggregation option
- Sync'ed captions with OBS recording timestamps
- Send captions on a RTMP stream to e.g. YouTube, Twitch
- Bring your own Whisper model (any GGML)
- Translate captions in real time to major languages (both Whisper built-in translation as well as NMT models)
- CUDA, hipBLAS (AMD ROCm), Apple Arm64, AVX & SSE acceleration support
- Filter out or replace any part of the produced captions
- Partial transcriptions for a streaming-captions experience
- 100s of fine-tuned Whisper models for dozens of languages from HuggingFace
Roadmap:
- More robust built-in translation options
- Additional output options: .vtt, .ssa, .sub, etc.
- Speaker diarization (detecting speakers in a multi-person audio stream)
Check out our other plugins:
- Background Removal removes background from webcam without a green screen.
- Detect will detect and track >80 types of objects in real-time inside OBS
- CleanStream for real-time filler word (uh,um) and profanity removal from a live audio stream
- URL/API Source that allows fetching live data from an API and displaying it in OBS.
- Squawk adds lifelike local text-to-speech capabilities built-in OBS
Check out the latest releases for downloads and install instructions.
The plugin ships with the Tiny.en model, and will autonomously download other Whisper models through a dropdown. There's also an option to select an external GGML Whisper model file if you have it on disk.
Get more models from https://ggml.ggerganov.com/ and HuggingFace, follow the instructions on whisper.cpp to create your own models or download others such as distilled models.
The plugin was built and tested on Mac OSX (Intel & Apple silicon), Windows (with and without Nvidia CUDA) and Linux.
Start by cloning this repo to a directory of your choice.
Using the CI pipeline scripts, locally you would just call the zsh script, which builds for the architecture specified in $MACOS_ARCH (either x86_64 or arm64).
$ MACOS_ARCH="x86_64" ./.github/scripts/build-macos -c ReleaseThe above script should succeed and the plugin files (e.g. obs-localvocal.plugin) will reside in the ./release/Release folder off of the root. Copy the .plugin file to the OBS directory e.g. ~/Library/Application Support/obs-studio/plugins.
To get .pkg installer file, run for example
$ ./.github/scripts/package-macos -c Release(Note that maybe the outputs will be in the Release folder and not the install folder like pakage-macos expects, so you will need to rename the folder from build_x86_64/Release to build_x86_64/install)
For successfully building on Ubuntu, first clone the repo, then from the repo directory:
$ sudo apt install -y libssl-dev
$ ./.github/scripts/build-linuxCopy the results to the standard OBS folders on Ubuntu
$ sudo cp -R release/RelWithDebInfo/lib/* /usr/lib/
$ sudo cp -R release/RelWithDebInfo/share/* /usr/share/Note: The official OBS plugins guide recommends adding plugins to the ~/.config/obs-studio/plugins folder. This has to do with the way you installed OBS.
In case the above doesn't work, attempt to copy the files to the ~/.config folder:
$ mkdir -p ~/.config/obs-studio/plugins/obs-localvocal/bin/64bit
$ cp -R release/RelWithDebInfo/lib/x86_64-linux-gnu/obs-plugins/* ~/.config/obs-studio/plugins/obs-localvocal/bin/64bit/
$ mkdir -p ~/.config/obs-studio/plugins/obs-localvocal/data
$ cp -R release/RelWithDebInfo/share/obs/obs-plugins/obs-localvocal/* ~/.config/obs-studio/plugins/obs-localvocal/data/For other distros where you can't use the CI build script, you can build the plugin as follows
-
Clone the repository and install these dependencies using your distribution's package manager:
- libssl (with development headers)
-
Generate the CMake build scripts (adjust folders if necessary)
cmake -B build-dir --preset linux-x86_64 -DUSE_SYSTEM_CURL=ON -DCMAKE_INSTALL_PREFIX=./output_dir
-
Build the plugin and copy the files to the output directory
cmake --build build-dir --target install
-
Copy plugin to OBS plugins folder
mkdir -p ~/.config/obs-studio/plugins/bin/64bit cp -R ./output_dir/lib/obs-plugins/* ~/.config/obs-studio/plugins/bin/64bit/
N.B. Depending on your system, the plugin might be in
./output_dir/lib64/obs-pluginsinstead. -
Copy plugin data to OBS plugins folder - Possibly only needed on first install
mkdir -p ~/.config/obs-studio/plugins/data cp -R ./output_dir/share/obs/obs-plugins/obs-localvocal/* ~/.config/obs-studio/plugins/data/
Use the CI scripts again, for example:
> .github/scripts/Build-Windows.ps1 -Configuration ReleaseThe build should exist in the ./release folder off the root. You can manually install the files in the OBS directory.
> Copy-Item -Recurse -Force "release\Release\*" -Destination "C:\Program Files\obs-studio\"LocalVocal will now build with CUDA support automatically through a prebuilt binary of Whisper.cpp from https://github.com/locaal-ai/locaal-ai-dep-whispercpp. The CMake scripts will download all necessary files.
To build with cuda add ACCELERATION as an environment variable (with cpu, hipblas, or cuda) and build regularly
> $env:ACCELERATION="cuda"
> .github/scripts/Build-Windows.ps1 -Configuration ReleaseFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for obs-localvocal
Similar Open Source Tools
obs-localvocal
LocalVocal is a Speech AI assistant OBS Plugin that enables users to transcribe speech into text and translate it into any language locally on their machine. The plugin runs OpenAI's Whisper for real-time speech processing and prediction. It supports features like transcribing audio in real-time, displaying captions on screen, sending captions to files, syncing captions with recordings, and translating captions to major languages. Users can bring their own Whisper model, filter or replace captions, and experience partial transcriptions for streaming. The plugin is privacy-focused, requiring no GPU, cloud costs, network, or downtime.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.
obs-urlsource
The URL/API Source is a plugin for OBS Studio that allows users to add a media source fetching data from a URL or API endpoint and displaying it as text. It supports input and output templating, various request types, output parsing (JSON, XML/HTML, Regex, CSS selectors), live data updating, output styling, and formatting. Future features include authentication, websocket support, more parsing options, request types, and output formats. The plugin is cross-platform compatible and actively maintained by the developer. Users can support the project on GitHub.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.
elyra
Elyra is a set of AI-centric extensions to JupyterLab Notebooks that includes features like Visual Pipeline Editor, running notebooks/scripts as batch jobs, reusable code snippets, hybrid runtime support, script editors with execution capabilities, debugger, version control using Git, and more. It provides a comprehensive environment for data scientists and AI practitioners to develop, test, and deploy machine learning models and workflows efficiently.
pianotrans
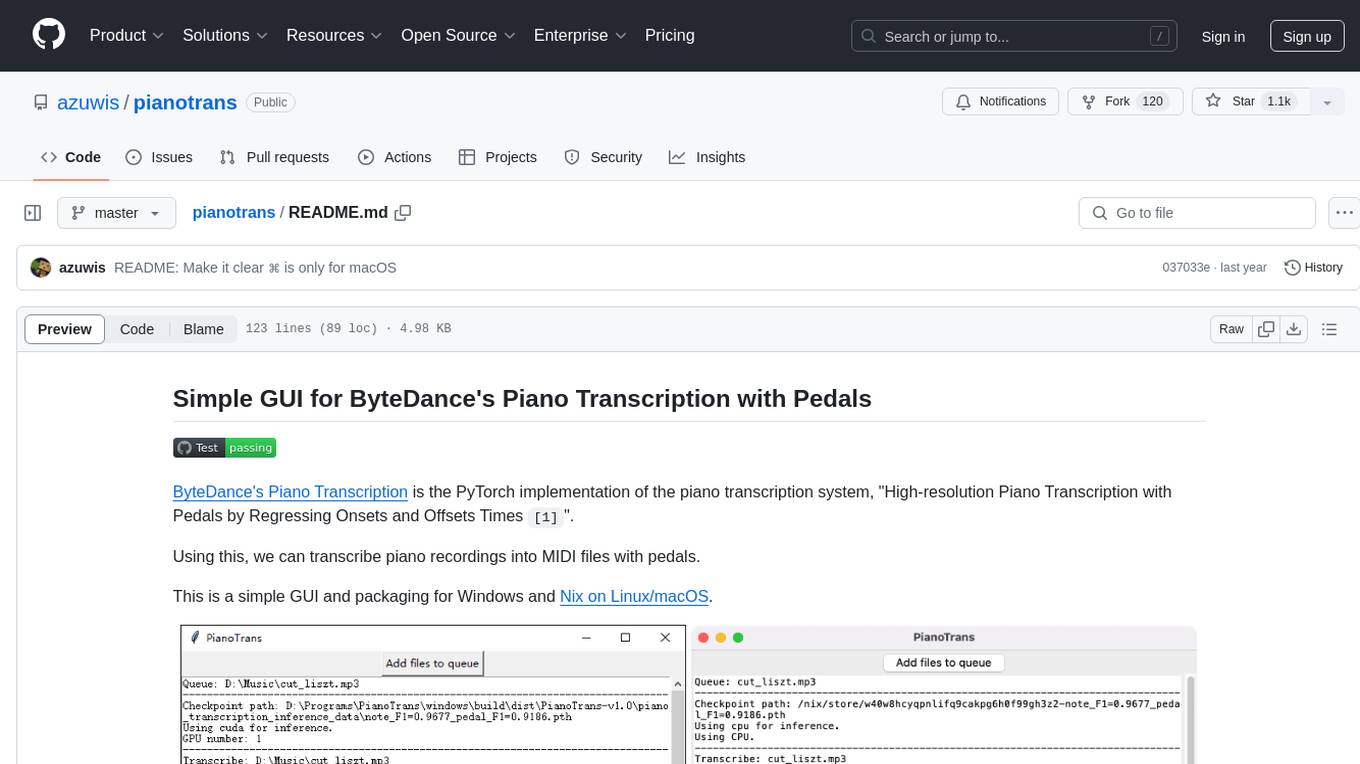
ByteDance's Piano Transcription is a PyTorch implementation for transcribing piano recordings into MIDI files with pedals. This repository provides a simple GUI and packaging for Windows and Nix on Linux/macOS. It supports using GPU for inference and includes CLI usage. Users can upgrade the tool and report issues to the upstream project. The tool focuses on providing MIDI files, and any other improvements to transcription results should be directed to the original project.
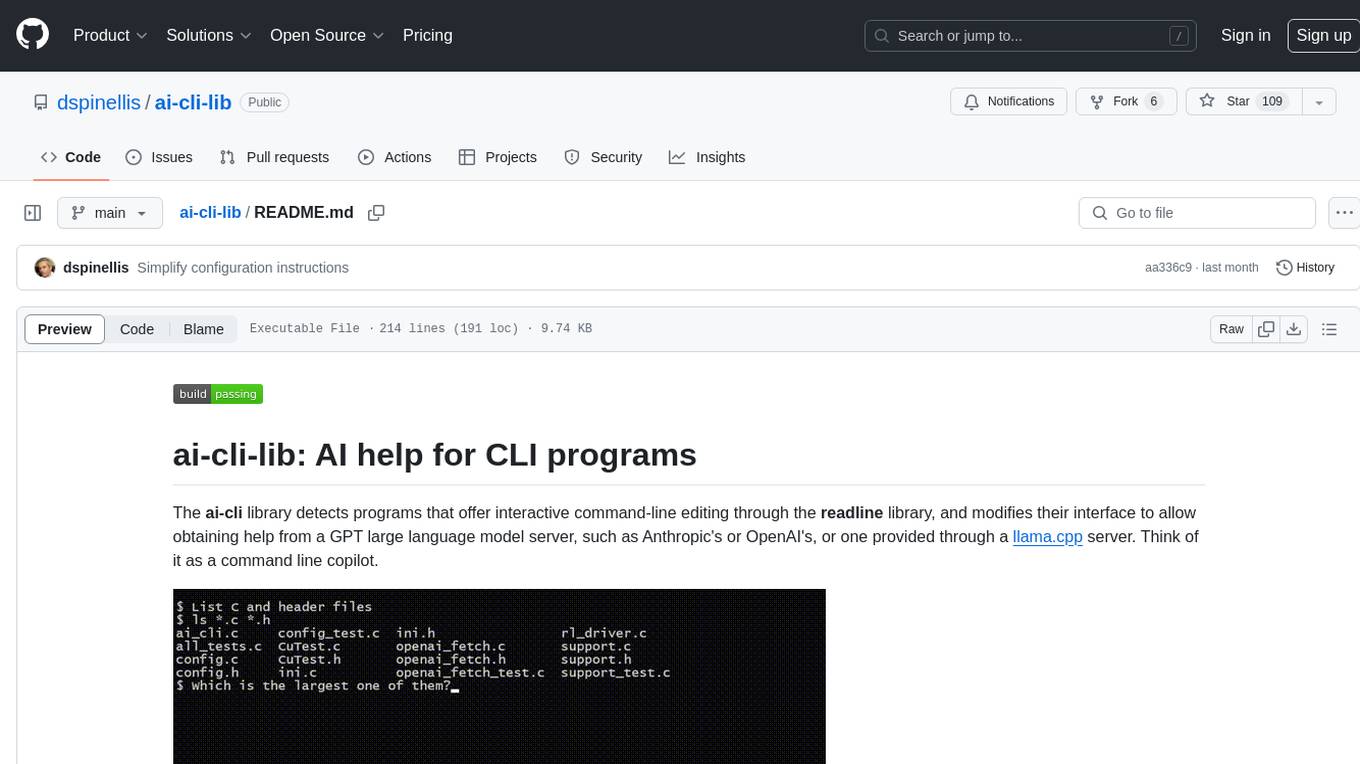
ai-cli-lib
The ai-cli-lib is a library designed to enhance interactive command-line editing programs by integrating with GPT large language model servers. It allows users to obtain AI help from servers like Anthropic's or OpenAI's, or a llama.cpp server. The library acts as a command line copilot, providing natural language prompts and responses to enhance user experience and productivity. It supports various platforms such as Debian GNU/Linux, macOS, and Cygwin, and requires specific packages for installation and operation. Users can configure the library to activate during shell startup and interact with command-line programs like bash, mysql, psql, gdb, sqlite3, and bc. Additionally, the library provides options for configuring API keys, setting up llama.cpp servers, and ensuring data privacy by managing context settings.
browser
Lightpanda Browser is an open-source headless browser designed for fast web automation, AI agents, LLM training, scraping, and testing. It features ultra-low memory footprint, exceptionally fast execution, and compatibility with Playwright and Puppeteer through CDP. Built for performance, Lightpanda offers Javascript execution, support for Web APIs, and is optimized for minimal memory usage. It is a modern solution for web scraping and automation tasks, providing a lightweight alternative to traditional browsers like Chrome.
SciPIP
SciPIP is a scientific paper idea generation tool powered by a large language model (LLM) designed to assist researchers in quickly generating novel research ideas. It conducts a literature review based on user-provided background information and generates fresh ideas for potential studies. The tool is designed to help researchers in various fields by providing a GUI environment for idea generation, supporting NLP, multimodal, and CV fields, and allowing users to interact with the tool through a web app or terminal. SciPIP uses Neo4j as its database and provides functionalities for generating new ideas, fetching papers, and constructing the database.
aio-switch-updater
AIO-Switch-Updater is a Nintendo Switch homebrew app that allows users to download and update custom firmware, firmware files, cheat codes, and more. It supports Atmosphère, ReiNX, and SXOS on both unpatched and patched Switches. The app provides features like updating CFW with custom RCM payload, updating Hekate/payload, custom downloads, downloading firmwares and cheats, and various tools like rebooting to specific payload, changing color schemes, consulting cheat codes, and more. Users can contribute by submitting PRs and suggestions, and the app supports localization. It does not host or distribute any files and gives special thanks to contributors and supporters.
anyquery
Anyquery is a SQL query engine built on SQLite that allows users to run SQL queries on various data sources like files, databases, and apps. It can connect to LLMs to access data and act as a MySQL server for running queries. The tool is extensible through plugins and supports various installation methods like Homebrew, APT, YUM/DNF, Scoop, Winget, and Chocolatey.
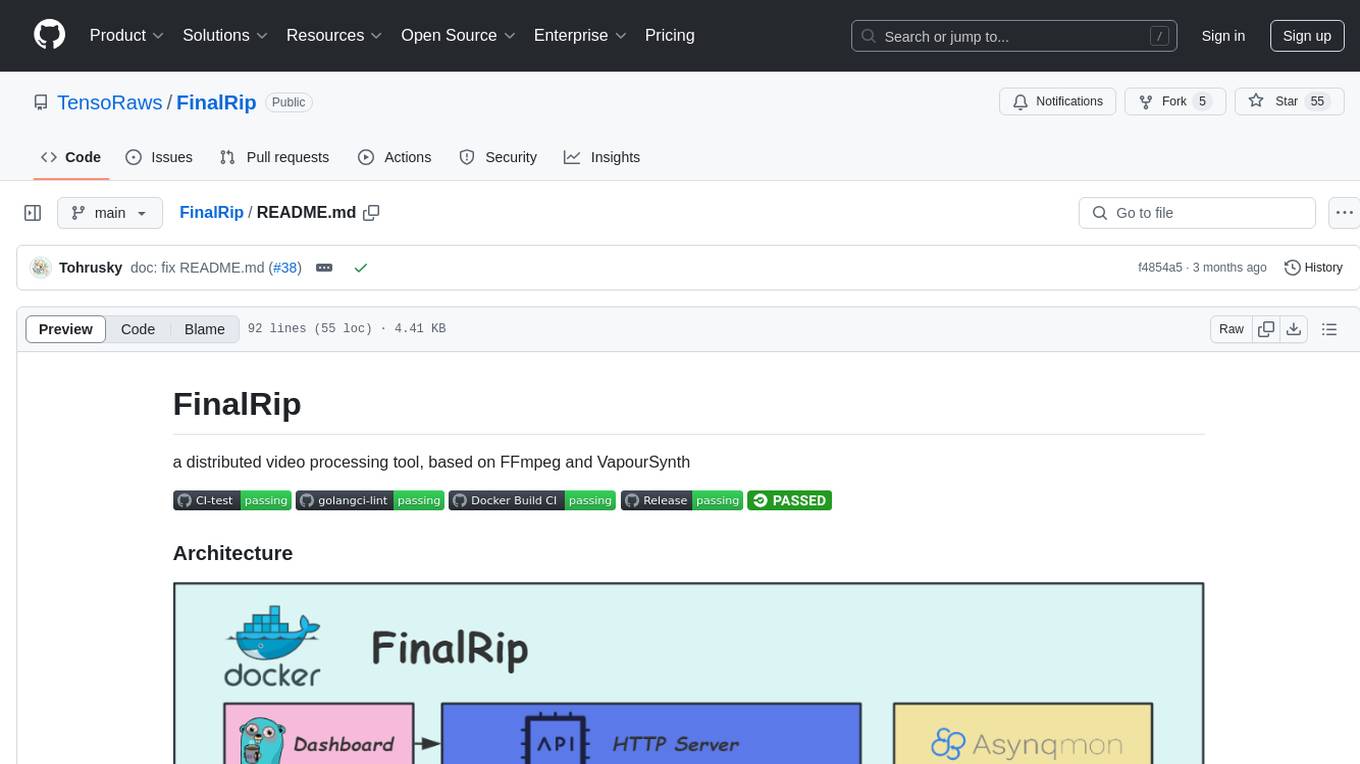
FinalRip
FinalRip is a distributed video processing tool based on FFmpeg and VapourSynth. It cuts the original video into multiple clips, processes each clip in parallel, and merges them into the final video. Users can deploy the system in a distributed way, configure settings via environment variables or remote config files, and develop/test scripts in the vs-playground environment. It supports Nvidia GPU, AMD GPU with ROCm support, and provides a dashboard for selecting compatible scripts to process videos.

raglite
RAGLite is a Python toolkit for Retrieval-Augmented Generation (RAG) with PostgreSQL or SQLite. It offers configurable options for choosing LLM providers, database types, and rerankers. The toolkit is fast and permissive, utilizing lightweight dependencies and hardware acceleration. RAGLite provides features like PDF to Markdown conversion, multi-vector chunk embedding, optimal semantic chunking, hybrid search capabilities, adaptive retrieval, and improved output quality. It is extensible with a built-in Model Context Protocol server, customizable ChatGPT-like frontend, document conversion to Markdown, and evaluation tools. Users can configure RAGLite for various tasks like configuring, inserting documents, running RAG pipelines, computing query adapters, evaluating performance, running MCP servers, and serving frontends.
Airshipper
Airshipper is a cross-platform Veloren launcher that allows users to update/download and start nightly builds of the game. It features a fancy UI with self-updating capabilities on Windows. Users can compile it from source and also have the option to install Airshipper-Server for advanced configurations. Note that Airshipper is still in development and may not be stable for all users.
tgpt
tgpt is a cross-platform command-line interface (CLI) tool that allows users to interact with AI chatbots in the Terminal without needing API keys. It supports various AI providers such as KoboldAI, Phind, Llama2, Blackbox AI, and OpenAI. Users can generate text, code, and images using different flags and options. The tool can be installed on GNU/Linux, MacOS, FreeBSD, and Windows systems. It also supports proxy configurations and provides options for updating and uninstalling the tool.
openmeter
OpenMeter is a real-time and scalable usage metering tool for AI, usage-based billing, infrastructure, and IoT use cases. It provides a REST API for integrations and offers client SDKs in Node.js, Python, Go, and Web. OpenMeter is licensed under the Apache 2.0 License.
For similar tasks
obs-localvocal
LocalVocal is a Speech AI assistant OBS Plugin that enables users to transcribe speech into text and translate it into any language locally on their machine. The plugin runs OpenAI's Whisper for real-time speech processing and prediction. It supports features like transcribing audio in real-time, displaying captions on screen, sending captions to files, syncing captions with recordings, and translating captions to major languages. Users can bring their own Whisper model, filter or replace captions, and experience partial transcriptions for streaming. The plugin is privacy-focused, requiring no GPU, cloud costs, network, or downtime.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

deepgram-js-sdk
Deepgram JavaScript SDK. Power your apps with world-class speech and Language AI models.
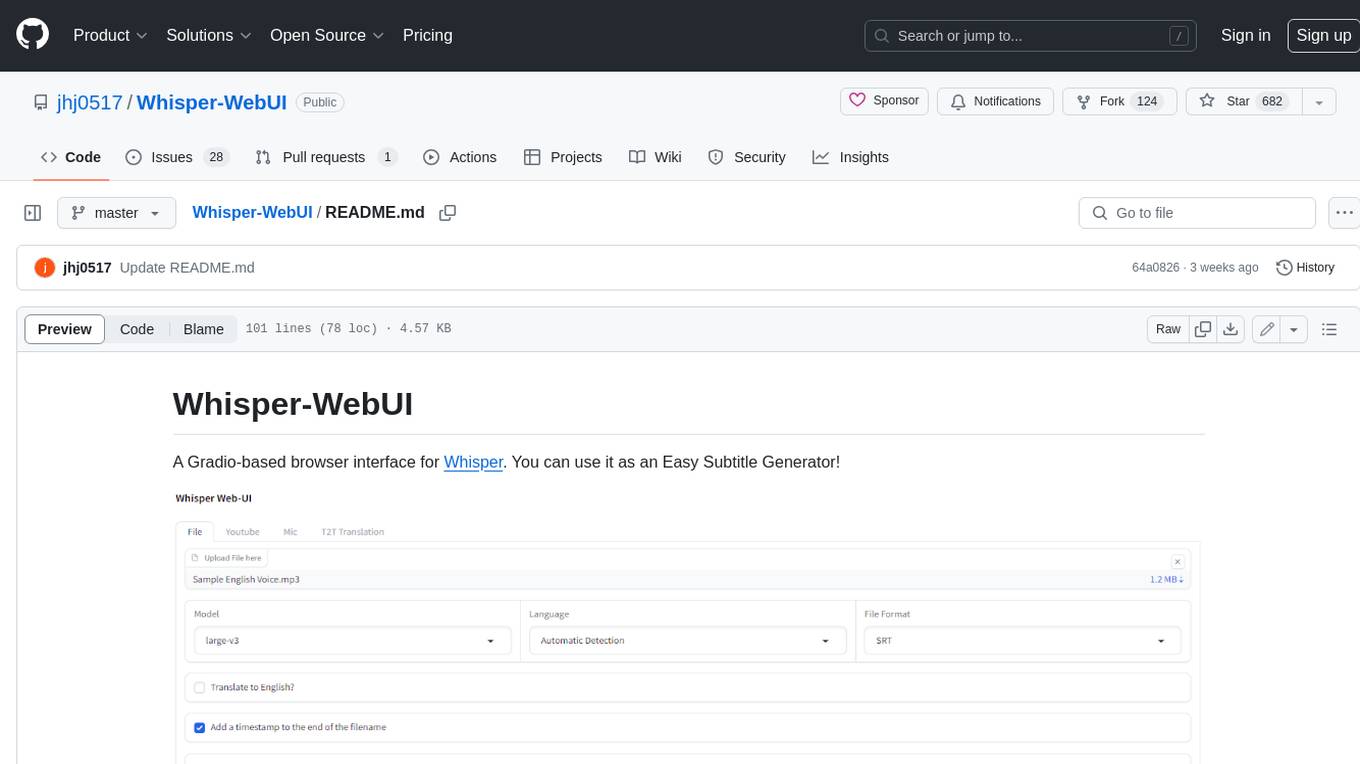
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
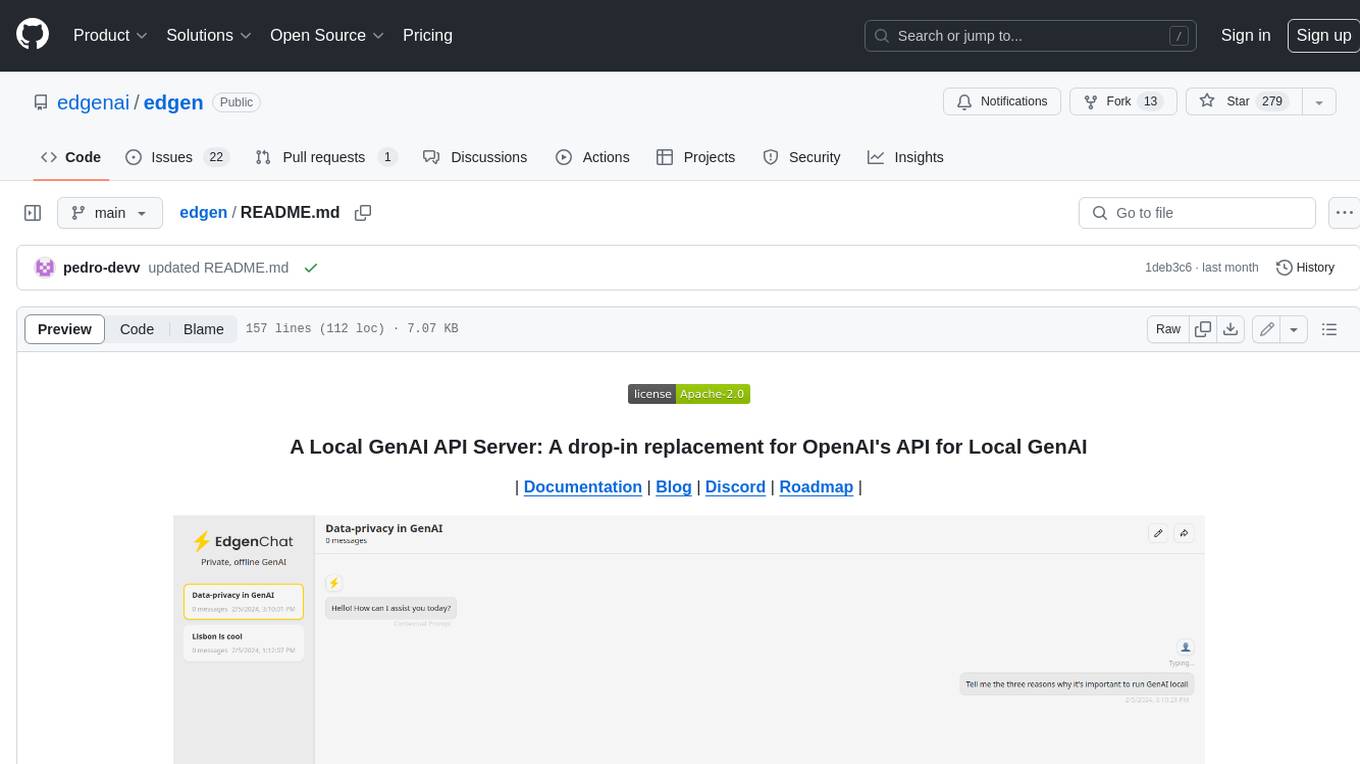
edgen
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.