
aphrodite-engine
Large-scale LLM inference engine
Stars: 1366

Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.
README:

Aphrodite is an inference engine that optimizes the serving of HuggingFace-compatible models at scale. Built on vLLM's Paged Attention technology, it delivers high-performance model inference for multiple concurrent users. Developed through a collaboration between PygmalionAI and Ruliad, Aphrodite serves as the backend engine powering both organizations' chat platforms and API infrastructure.
Aphrodite builds upon and integrates the exceptional work from various projects, primarily vLLM.
[!CAUTION] This project is not, and will never be, associated with any cryptocurrencies. Please do not fall for scams.
(09/2024) v0.6.1 is here. You can now load FP16 models in FP2 to FP7 quant formats, to achieve extremely high throughput and save on memory.
(09/2024) v0.6.0 is released, with huge throughput improvements, many new quant formats (including fp8 and llm-compressor), asymmetric tensor parallel, pipeline parallel and more! Please check out the exhaustive documentation for the User and Developer guides.
- Continuous Batching
- Efficient K/V management with PagedAttention from vLLM
- Optimized CUDA kernels for improved inference
- Quantization support via AQLM, AWQ, Bitsandbytes, GGUF, GPTQ, QuIP#, Smoothquant+, SqueezeLLM, Marlin, FP2-FP12, and more
- Distributed inference
- 8-bit KV Cache for higher context lengths and throughput, at both FP8 E5M3 and E4M3 formats
- Support for modern samplers such as DRY, XTC, and more
Install the engine:
pip install -U aphrodite-engine --extra-index-url https://downloads.pygmalion.chat/whlThen launch a model:
aphrodite run meta-llama/Meta-Llama-3.1-8B-InstructThis will create a OpenAI-compatible API server that can be accessed at port 2242 of the localhost. You can plug in the API into a UI that supports OpenAI, such as SillyTavern.
Please refer to the documentation for the full list of arguments and flags you can pass to the engine.
You can play around with the engine in the demo here:
Additionally, we provide a Docker image for easy deployment. Here's a basic command to get you started:
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
#--env "CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7" \
-p 2242:2242 \
--ipc=host \
alpindale/aphrodite-openai:latest \
--model NousResearch/Meta-Llama-3.1-8B-Instruct \
--tensor-parallel-size 8 \
--api-keys "sk-empty"This will pull the Aphrodite Engine image (~8GiB download), and launch the engine with the Llama-3.1-8B-Instruct model at port 2242.
- Operating System: Linux, Windows (Needs building from source)
- Python: 3.8 to 3.12
- CUDA >= 11
For supported devices, see here. Generally speaking, all semi-modern GPUs are supported - down to Pascal (GTX 10xx, P40, etc.) We also support AMD GPUs, Intel CPUs and GPUs, Google TPU, and AWS Inferentia.
-
By design, Aphrodite takes up 90% of your GPU's VRAM. If you're not serving an LLM at scale, you may want to limit the amount of memory it takes up. You can do this in the API example by launching the server with the
--gpu-memory-utilization 0.6(0.6 means 60%), or--single-user-modeto only allocate as much memory as needed for a single sequence. -
You can view the full list of commands by running
aphrodite run --help.
Aphrodite Engine would have not been possible without the phenomenal work of other open-source projects. Credits go to:
- vLLM (CacheFlow)
- TensorRT-LLM
- xFormers
- Flash Attention
- llama.cpp
- AutoAWQ
- AutoGPTQ
- SqueezeLLM
- Exllamav2
- TabbyAPI
- AQLM
- KoboldAI
- Text Generation WebUI
- Megatron-LM
- Ray
Everyone is welcome to contribute. You can support the project by opening Pull Requests for new features, fixes, or general UX improvements.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aphrodite-engine
Similar Open Source Tools
aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.

NeMo
NVIDIA NeMo Framework is a scalable and cloud-native generative AI framework built for researchers and PyTorch developers working on Large Language Models (LLMs), Multimodal Models (MMs), Automatic Speech Recognition (ASR), Text to Speech (TTS), and Computer Vision (CV) domains. It is designed to help you efficiently create, customize, and deploy new generative AI models by leveraging existing code and pre-trained model checkpoints.

NeMo
NeMo Framework is a generative AI framework built for researchers and pytorch developers working on large language models (LLMs), multimodal models (MM), automatic speech recognition (ASR), and text-to-speech synthesis (TTS). The primary objective of NeMo is to provide a scalable framework for researchers and developers from industry and academia to more easily implement and design new generative AI models by being able to leverage existing code and pretrained models.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.

pathway
Pathway is a Python data processing framework for analytics and AI pipelines over data streams. It's the ideal solution for real-time processing use cases like streaming ETL or RAG pipelines for unstructured data. Pathway comes with an **easy-to-use Python API** , allowing you to seamlessly integrate your favorite Python ML libraries. Pathway code is versatile and robust: **you can use it in both development and production environments, handling both batch and streaming data effectively**. The same code can be used for local development, CI/CD tests, running batch jobs, handling stream replays, and processing data streams. Pathway is powered by a **scalable Rust engine** based on Differential Dataflow and performs incremental computation. Your Pathway code, despite being written in Python, is run by the Rust engine, enabling multithreading, multiprocessing, and distributed computations. All the pipeline is kept in memory and can be easily deployed with **Docker and Kubernetes**. You can install Pathway with pip: `pip install -U pathway` For any questions, you will find the community and team behind the project on Discord.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
DistServe
DistServe improves the performance of large language models serving by disaggregating the prefill and decoding computation. It allows setting parallelism configs and scheduling strategies for the two phases independently, handling KV-Cache communication and memory management automatically. Utilizes a high-performance C++ Transformer inference library SwiftTransformer with features like model/pipeline parallelism, FlashAttention, Continuous Batching, and PagedAttention. Supports GPT-2, OPT, and LLaMA2 models.
OM1
OpenMind's OM1 is a modular AI runtime empowering developers to create and deploy multimodal AI agents across digital environments and physical robots. OM1 agents process diverse inputs like web data, social media, camera feeds, and LIDAR, enabling actions including motion, autonomous navigation, and natural conversations. The goal is to create highly capable human-focused robots that are easy to upgrade and reconfigure for different physical form factors. OM1 features a modular architecture, supports new hardware via plugins, offers web-based debugging display, and pre-configured endpoints for various services.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.

AntSK
AntSK is an AI knowledge base/agent built with .Net8+Blazor+SemanticKernel. It features a semantic kernel for accurate natural language processing, a memory kernel for continuous learning and knowledge storage, a knowledge base for importing and querying knowledge from various document formats, a text-to-image generator integrated with StableDiffusion, GPTs generation for creating personalized GPT models, API interfaces for integrating AntSK into other applications, an open API plugin system for extending functionality, a .Net plugin system for integrating business functions, real-time information retrieval from the internet, model management for adapting and managing different models from different vendors, support for domestic models and databases for operation in a trusted environment, and planned model fine-tuning based on llamafactory.

ServerlessLLM
ServerlessLLM is a fast, affordable, and easy-to-use library designed for multi-LLM serving, optimized for environments with limited GPU resources. It supports loading various leading LLM inference libraries, achieving fast load times, and reducing model switching overhead. The library facilitates easy deployment via Ray Cluster and Kubernetes, integrates with the OpenAI Query API, and is actively maintained by contributors.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.
miyagi
Project Miyagi showcases Microsoft's Copilot Stack in an envisioning workshop aimed at designing, developing, and deploying enterprise-grade intelligent apps. By exploring both generative and traditional ML use cases, Miyagi offers an experiential approach to developing AI-infused product experiences that enhance productivity and enable hyper-personalization. Additionally, the workshop introduces traditional software engineers to emerging design patterns in prompt engineering, such as chain-of-thought and retrieval-augmentation, as well as to techniques like vectorization for long-term memory, fine-tuning of OSS models, agent-like orchestration, and plugins or tools for augmenting and grounding LLMs.
video-search-and-summarization
The NVIDIA AI Blueprint for Video Search and Summarization is a repository showcasing video search and summarization agent with NVIDIA NIM microservices. It enables industries to make better decisions faster by providing insightful, accurate, and interactive video analytics AI agents. These agents can perform tasks like video summarization and visual question-answering, unlocking new application possibilities. The repository includes software components like NIM microservices, ingestion pipeline, and CA-RAG module, offering a comprehensive solution for analyzing and summarizing large volumes of video data. The target audience includes video analysts, IT engineers, and GenAI developers who can benefit from the blueprint's 1-click deployment steps, easy-to-manage configurations, and customization options. The repository structure overview includes directories for deployment, source code, and training notebooks, along with documentation for detailed instructions. Hardware requirements vary based on deployment topology and dependencies like VLM and LLM, with different deployment methods such as Launchable Deployment, Docker Compose Deployment, and Helm Chart Deployment provided for various use cases.
For similar tasks

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

ChaKt-KMP
ChaKt is a multiplatform app built using Kotlin and Compose Multiplatform to demonstrate the use of Generative AI SDK for Kotlin Multiplatform to generate content using Google's Generative AI models. It features a simple chat based user interface and experience to interact with AI. The app supports mobile, desktop, and web platforms, and is built with Kotlin Multiplatform, Kotlin Coroutines, Compose Multiplatform, Generative AI SDK, Calf - File picker, and BuildKonfig. Users can contribute to the project by following the guidelines in CONTRIBUTING.md. The app is licensed under the MIT License.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
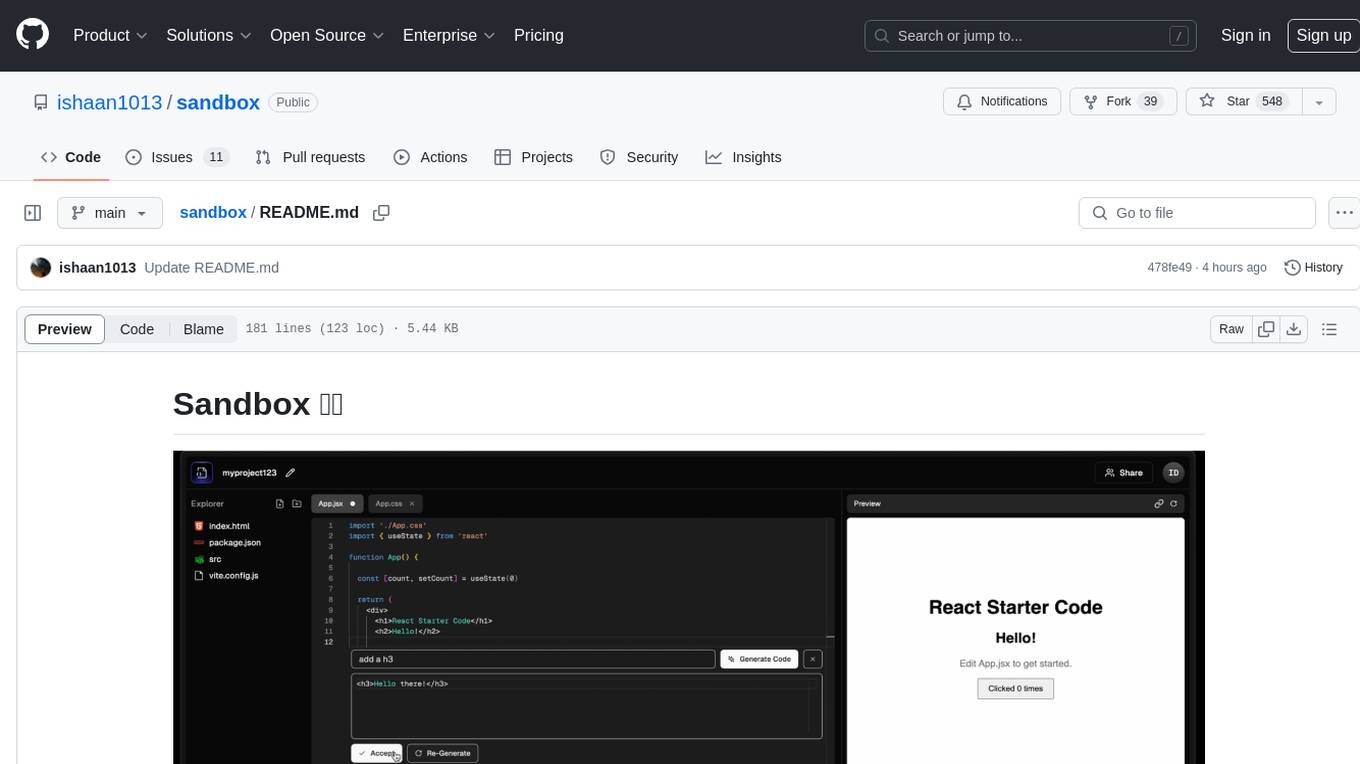
sandbox
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
void
Void is an open-source Cursor alternative, providing a full source code for users to build and develop. It is a fork of the vscode repository, offering a waitlist for the official release. Users can contribute by checking the Project board and following the guidelines in CONTRIBUTING.md. Support is available through Discord or email.
aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.
cua
Cua is a tool for creating and running high-performance macOS and Linux virtual machines on Apple Silicon, with built-in support for AI agents. It provides libraries like Lume for running VMs with near-native performance, Computer for interacting with sandboxes, and Agent for running agentic workflows. Users can refer to the documentation for onboarding, explore demos showcasing AI-Gradio and GitHub issue fixing, and utilize accessory libraries like Core, PyLume, Computer Server, and SOM. Contributions are welcome, and the tool is open-sourced under the MIT License.
GeneratedOnBoardings
GeneratedOnBoardings is a repository containing automatically generated onboarding diagrams for over 800+ Python projects using CodeBoarding, an open-source tool for creating interactive visual documentation. The tool helps developers explore unfamiliar codebases through visual documentation, making it easier to understand and contribute to open-source projects. Users can provide feedback to improve the tool, and can also generate onboarding diagrams for their own projects by running CodeBoarding locally or trying the online demo at CodeBoarding.org/demo.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.