
athina-evals
Python SDK for running evaluations on LLM generated responses
Stars: 276
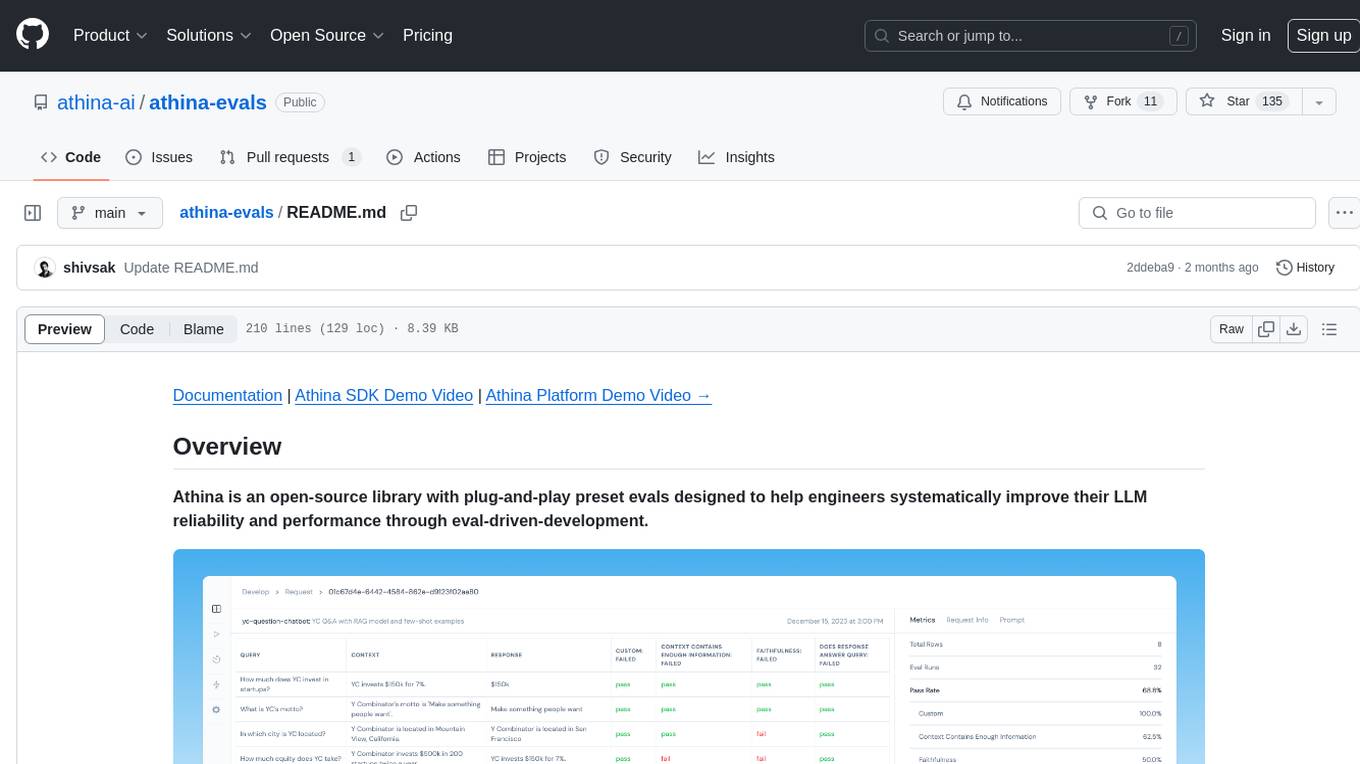
Athina is an open-source library designed to help engineers improve the reliability and performance of Large Language Models (LLMs) through eval-driven development. It offers plug-and-play preset evals for catching and preventing bad outputs, measuring model performance, running experiments, A/B testing models, detecting regressions, and monitoring production data. Athina provides a solution to the flaws in current LLM developer workflows by offering rapid experimentation, customizable evaluators, integrated dashboard, consistent metrics, historical record tracking, and easy setup. It includes preset evaluators for RAG applications and summarization accuracy, as well as the ability to write custom evals. Athina's evals can run on both development and production environments, providing consistent metrics and removing the need for manual infrastructure setup.
README:
Athina is an Observability and Experimentation platform for AI teams.
This SDK is an open-source repository of 50+ preset evals. You can also use custom evals.
This SDK also serves as a companion to Athina IDE where you can prototype pipelines, run experiments and evaluations, and compare datasets.
Follow this notebook for a quick start guide.
To get an Athina API key, sign up at https://app.athina.ai
These evals can be run programmatically, or via the UI on Athina IDE.
Compare datasets side-by-side (Docs)
Once a dataset is logged to Athina IDE, you can also compare it against another dataset.
Once you run evals using Athina, they will be visible in Athina IDE where you can run experiments, evals, and compare datasets side-by-side.
To use CodeExecutionV2, you need to install e2b.
pip install e2b-code-interpreterFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for athina-evals
Similar Open Source Tools
athina-evals
Athina is an open-source library designed to help engineers improve the reliability and performance of Large Language Models (LLMs) through eval-driven development. It offers plug-and-play preset evals for catching and preventing bad outputs, measuring model performance, running experiments, A/B testing models, detecting regressions, and monitoring production data. Athina provides a solution to the flaws in current LLM developer workflows by offering rapid experimentation, customizable evaluators, integrated dashboard, consistent metrics, historical record tracking, and easy setup. It includes preset evaluators for RAG applications and summarization accuracy, as well as the ability to write custom evals. Athina's evals can run on both development and production environments, providing consistent metrics and removing the need for manual infrastructure setup.

Genkit
Genkit is an open-source framework for building full-stack AI-powered applications, used in production by Google's Firebase. It provides SDKs for JavaScript/TypeScript (Stable), Go (Beta), and Python (Alpha) with unified interface for integrating AI models from providers like Google, OpenAI, Anthropic, Ollama. Rapidly build chatbots, automations, and recommendation systems using streamlined APIs for multimodal content, structured outputs, tool calling, and agentic workflows. Genkit simplifies AI integration with open-source SDK, unified APIs, and offers text and image generation, structured data generation, tool calling, prompt templating, persisted chat interfaces, AI workflows, and AI-powered data retrieval (RAG).

genkit
Firebase Genkit (beta) is a framework with powerful tooling to help app developers build, test, deploy, and monitor AI-powered features with confidence. Genkit is cloud optimized and code-centric, integrating with many services that have free tiers to get started. It provides unified API for generation, context-aware AI features, evaluation of AI workflow, extensibility with plugins, easy deployment to Firebase or Google Cloud, observability and monitoring with OpenTelemetry, and a developer UI for prototyping and testing AI features locally. Genkit works seamlessly with Firebase or Google Cloud projects through official plugins and templates.

pathway
Pathway is a Python data processing framework for analytics and AI pipelines over data streams. It's the ideal solution for real-time processing use cases like streaming ETL or RAG pipelines for unstructured data. Pathway comes with an **easy-to-use Python API** , allowing you to seamlessly integrate your favorite Python ML libraries. Pathway code is versatile and robust: **you can use it in both development and production environments, handling both batch and streaming data effectively**. The same code can be used for local development, CI/CD tests, running batch jobs, handling stream replays, and processing data streams. Pathway is powered by a **scalable Rust engine** based on Differential Dataflow and performs incremental computation. Your Pathway code, despite being written in Python, is run by the Rust engine, enabling multithreading, multiprocessing, and distributed computations. All the pipeline is kept in memory and can be easily deployed with **Docker and Kubernetes**. You can install Pathway with pip: `pip install -U pathway` For any questions, you will find the community and team behind the project on Discord.

aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.

latitude-llm
Latitude is an open-source prompt engineering platform that helps developers and product teams build AI features with confidence. It simplifies prompt management, aids in testing AI responses, and provides detailed analytics on request performance. Latitude offers collaborative prompt management, support for advanced features, version control, API and SDKs for integration, observability, evaluations in batch or real-time, and is community-driven. It can be deployed on Latitude Cloud for a managed solution or self-hosted for control and customization.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.

gradient-cli
Gradient CLI is a tool designed to facilitate the end-to-end MLOps process, allowing individuals and organizations to develop, train, and deploy Deep Learning models efficiently. It supports various ML/DL frameworks and provides features such as 1-click Jupyter Notebooks, scalable model training workflows, and model deployment as API endpoints. The tool can run on different infrastructures like AWS, GCP, on-premise, and Paperspace GPUs, offering automatic versioning, distributed training, hyperparameter search, and more.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.

agno
Agno is a lightweight library for building multi-modal Agents. It is designed with core principles of simplicity, uncompromising performance, and agnosticism, allowing users to create blazing fast agents with minimal memory footprint. Agno supports any model, any provider, and any modality, making it a versatile container for AGI. Users can build agents with lightning-fast agent creation, model agnostic capabilities, native support for text, image, audio, and video inputs and outputs, memory management, knowledge stores, structured outputs, and real-time monitoring. The library enables users to create autonomous programs that use language models to solve problems, improve responses, and achieve tasks with varying levels of agency and autonomy.

radicalbit-ai-monitoring
The Radicalbit AI Monitoring Platform provides a comprehensive solution for monitoring Machine Learning and Large Language models in production. It helps proactively identify and address potential performance issues by analyzing data quality, model quality, and model drift. The repository contains files and projects for running the platform, including UI, API, SDK, and Spark components. Installation using Docker compose is provided, allowing deployment with a K3s cluster and interaction with a k9s container. The platform documentation includes a step-by-step guide for installation and creating dashboards. Community engagement is encouraged through a Discord server. The roadmap includes adding functionalities for batch and real-time workloads, covering various model types and tasks.

ReaLHF
ReaLHF is a distributed system designed for efficient RLHF training with Large Language Models (LLMs). It introduces a novel approach called parameter reallocation to dynamically redistribute LLM parameters across the cluster, optimizing allocations and parallelism for each computation workload. ReaL minimizes redundant communication while maximizing GPU utilization, achieving significantly higher Proximal Policy Optimization (PPO) training throughput compared to other systems. It supports large-scale training with various parallelism strategies and enables memory-efficient training with parameter and optimizer offloading. The system seamlessly integrates with HuggingFace checkpoints and inference frameworks, allowing for easy launching of local or distributed experiments. ReaLHF offers flexibility through versatile configuration customization and supports various RLHF algorithms, including DPO, PPO, RAFT, and more, while allowing the addition of custom algorithms for high efficiency.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.
For similar tasks
athina-evals
Athina is an open-source library designed to help engineers improve the reliability and performance of Large Language Models (LLMs) through eval-driven development. It offers plug-and-play preset evals for catching and preventing bad outputs, measuring model performance, running experiments, A/B testing models, detecting regressions, and monitoring production data. Athina provides a solution to the flaws in current LLM developer workflows by offering rapid experimentation, customizable evaluators, integrated dashboard, consistent metrics, historical record tracking, and easy setup. It includes preset evaluators for RAG applications and summarization accuracy, as well as the ability to write custom evals. Athina's evals can run on both development and production environments, providing consistent metrics and removing the need for manual infrastructure setup.
bugbug
Bugbug is a tool developed by Mozilla that leverages machine learning techniques to assist with bug and quality management, as well as other software engineering tasks like test selection and defect prediction. It provides various classifiers to suggest assignees, detect patches likely to be backed-out, classify bugs, assign product/components, distinguish between bugs and feature requests, detect bugs needing documentation, identify invalid issues, verify bugs needing QA, detect regressions, select relevant tests, track bugs, and more. Bugbug can be trained and tested using Python scripts, and it offers the ability to run model training tasks on Taskcluster. The project structure includes modules for data mining, bug/commit feature extraction, model implementations, NLP utilities, label handling, bug history playback, and GitHub issue retrieval.
alignment-handbook
The Alignment Handbook provides robust training recipes for continuing pretraining and aligning language models with human and AI preferences. It includes techniques such as continued pretraining, supervised fine-tuning, reward modeling, rejection sampling, and direct preference optimization (DPO). The handbook aims to fill the gap in public resources on training these models, collecting data, and measuring metrics for optimal downstream performance.
llm-random
This repository contains code for research conducted by the LLM-Random research group at IDEAS NCBR in Warsaw, Poland. The group focuses on developing and using this repository to conduct research. For more information about the group and its research, refer to their blog, llm-random.github.io.
AI4U
AI4U is a tool that provides a framework for modeling virtual reality and game environments. It offers an alternative approach to modeling Non-Player Characters (NPCs) in Godot Game Engine. AI4U defines an agent living in an environment and interacting with it through sensors and actuators. Sensors provide data to the agent's brain, while actuators send actions from the agent to the environment. The brain processes the sensor data and makes decisions (selects an action by time). AI4U can also be used in other situations, such as modeling environments for artificial intelligence experiments.

OSWorld
OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.

GPTSwarm
GPTSwarm is a graph-based framework for LLM-based agents that enables the creation of LLM-based agents from graphs and facilitates the customized and automatic self-organization of agent swarms with self-improvement capabilities. The library includes components for domain-specific operations, graph-related functions, LLM backend selection, memory management, and optimization algorithms to enhance agent performance and swarm efficiency. Users can quickly run predefined swarms or utilize tools like the file analyzer. GPTSwarm supports local LM inference via LM Studio, allowing users to run with a local LLM model. The framework has been accepted by ICML2024 and offers advanced features for experimentation and customization.

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.