
bugbug
Platform for Machine Learning projects on Software Engineering
Stars: 547
Bugbug is a tool developed by Mozilla that leverages machine learning techniques to assist with bug and quality management, as well as other software engineering tasks like test selection and defect prediction. It provides various classifiers to suggest assignees, detect patches likely to be backed-out, classify bugs, assign product/components, distinguish between bugs and feature requests, detect bugs needing documentation, identify invalid issues, verify bugs needing QA, detect regressions, select relevant tests, track bugs, and more. Bugbug can be trained and tested using Python scripts, and it offers the ability to run model training tasks on Taskcluster. The project structure includes modules for data mining, bug/commit feature extraction, model implementations, NLP utilities, label handling, bug history playback, and GitHub issue retrieval.
README:
Bugbug aims at leveraging machine learning techniques to help with bug and quality management, and other software engineering tasks (such as test selection and defect prediction).
Chat with us in the bugbug Matrix room.
More information on the Mozilla Hacks blog:
- https://hacks.mozilla.org/2020/07/testing-firefox-more-efficiently-with-machine-learning/
- https://hacks.mozilla.org/2019/04/teaching-machines-to-triage-firefox-bugs/
Data generated by BugBug to train the models can be used independently from BugBug. See the docs for details.
-
assignee - The aim of this classifier is to suggest an appropriate assignee for a bug.
-
backout - The aim of this classifier is to detect patches that might be more likely to be backed-out (because of build or test failures). It could be used for test prioritization/scheduling purposes.
-
bugtype - The aim of this classifier is to classify bugs according to their type. The labels are gathered automatically from bugs: right now they are "crash/memory/performance/security". The plan is to add more types after manual labeling.
-
component - The aim of this classifier is to assign product/component to (untriaged) bugs.
-
defect vs enhancement vs task - Extension of the defect classifier to detect differences also between feature requests and development tasks.
-
defect - Bugs on Bugzilla aren't always bugs. Sometimes they are feature requests, refactorings, and so on. The aim of this classifier is to distinguish between bugs that are actually bugs and bugs that aren't. The dataset currently contains 2110 bugs, the accuracy of the current classifier is ~93% (precision ~95%, recall ~94%).
-
devdocneeded - The aim of this classifier is to detect bugs that should be documented for developers.
-
needsdiagnosis - The aim of this classifier is to detect issues that are likely invalid and don't need to be diagnosed for webcompat use case.
-
qaneeded - The aim of this classifier is to detect bugs that would need QA verification.
-
regression vs non-regression - Bugzilla has a
regressionkeyword to identify bugs that are regressions. Unfortunately it isn't used consistently. The aim of this classifier is to detect bugs that are regressions. -
regressionrange - The aim of this classifier is to detect regression bugs that have a regression range vs those that don't.
-
regressor - The aim of this classifier is to detect patches which are more likely to cause regressions. It could be used to make riskier patches undergo more scrutiny.
-
spam - The aim of this classifier is to detect bugs which are spam.
-
stepstoreproduce - The aim of this classifier is to detect bugs that have steps to reproduce vs those that don't.
-
testfailure - The aim of this classifier is to detect patches that might be more likely to cause test failures.
-
testselect - The aim of this classifier is to select relevant tests to run for a given patch.
-
tracking - The aim of this classifier is to detect bugs to track.
-
uplift - The aim of this classifier is to detect bugs for which uplift should be approved and bugs for which uplift should not be approved.
Install the Python dependencies:
pip3 install -r requirements.txt
You may also need pip install -r test-requirements.txt. Depending on the parts of bugbug you want to run, you might need to install dependencies from other requirement files (find them with find . -name "*requirements*").
Currently, Python 3.10+ is required. You can double check the version we use by looking at setup.py.
Also, libgit2 (needs v1.0.0, only in experimental on Debian), might be required (if you can't install it, skip this step).
sudo apt-get -t experimental install libgit2-dev
This project is using pre-commit. Please run pre-commit install to install the git pre-commit hooks on your clone.
Every time you will try to commit, pre-commit will run checks on your files to make sure they follow our style standards and they aren't affected by some simple issues. If the checks fail, pre-commit won't let you commit.
Run the trainer.py script with the command python -m scripts.trainer (with --help to see the required and optional arguments of the command) to perform training (warning this takes 30min+).
To use a model to classify a given bug, you can run python -m scripts.bug_classifier MODEL_NAME --bug-id ID_OF_A_BUG_FROM_BUGZILLA. N.B.: If you run the classifier script without training a model first, it will automatically download an already trained model.
training To train the model for mode defect:
python3 -m scripts.trainer defect
testing To use the model to classify a given bug, you can run python -m scripts.bug_classifier defect --bug-id ID_OF_A_BUG_FROM_BUGZILLA.
You could run the model training task on the CI. To do this, simply include Train on Taskcluster: <model name> in the pull request description.
To train the spambug model on Taskcluster, you need to add the following line in the pull request description, ideally at the bottom:
Train on Taskcluster: spambug
There are a few things to consider when training a model on Taskcluster:
- This is currently only supported in GitHub pull requests.
- The training task will be re-run every time you push to the branch linked to the pull request. Limiting the number of times you push is wise to avoid unnecessary training and resource wastage. Alternatively, you could temporarily remove the "Train on Taskcluster" keyword from the pull request description.
- Currently, the training task extracts only the model's name and does not consider arguments.
Note: This section is only necessary if you want to perform changes to the repository mining script. Otherwise, you can simply use the commits data we generate automatically.
- Clone https://hg.mozilla.org/mozilla-central/.
- Run
./mach vcs-setupin the directory where you have cloned mozilla-central. - Enable the extensions mentioned in infra/hgrc. For example, if you are on Linux, you can add
firefoxtreeto the extensions section of the~/.hgrcfile as:firefoxtree = ~/.mozbuild/version-control-tools/hgext/firefoxtree - Run the
repository.pyscript, with the only argument being the path to the mozilla-central repository.
Note: If you run into problems, it's possible the version of Mercurial you are using is not supported. Check the Docker definition at infra/dockerfile.commit_retrieval to see what we are using in production.
Note: the script will take a long time to run (on my laptop more than 7 hours). If you want to test a simple change and you don't intend to actually mine the data, you can modify the repository.py script to limit the number of analyzed commits. Simply add limit=1024 to the call to the log command.
-
bugbug/labelscontains manually collected labels; -
bugbug/db.pyis an implementation of a really simple JSON database; -
bugbug/bugzilla.pycontains the functions to retrieve bugs from the Bugzilla tracking system; -
bugbug/repository.pycontains the functions to mine data from the mozilla-central (Firefox) repository; -
bugbug/bug_features.pycontains functions to extract features from bug/commit data; -
bugbug/model.pycontains the base class that all models derive from; -
bugbug/modelscontains implementations of specific models; -
bugbug/nn.pycontains utility functions to include Keras models into a scikit-learn pipeline; -
bugbug/utils.pycontains misc utility functions; -
bugbug/nlpcontains utility functions for NLP; -
bugbug/labels.pycontains utility functions for handling labels; -
bugbug/bug_snapshot.pycontains a module to play back the history of a bug; -
bugbug/github.pycontains functions to retrieve issues from GitHub for a specified owner/repository.
Bugbug is focussing on Mozilla use-cases for Firefox, Bugzilla and GitHub. However, we will be happy to accept pull requests adding support for other projects or bug trackers.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for bugbug
Similar Open Source Tools
bugbug
Bugbug is a tool developed by Mozilla that leverages machine learning techniques to assist with bug and quality management, as well as other software engineering tasks like test selection and defect prediction. It provides various classifiers to suggest assignees, detect patches likely to be backed-out, classify bugs, assign product/components, distinguish between bugs and feature requests, detect bugs needing documentation, identify invalid issues, verify bugs needing QA, detect regressions, select relevant tests, track bugs, and more. Bugbug can be trained and tested using Python scripts, and it offers the ability to run model training tasks on Taskcluster. The project structure includes modules for data mining, bug/commit feature extraction, model implementations, NLP utilities, label handling, bug history playback, and GitHub issue retrieval.

airnode
Airnode is a fully-serverless oracle node that is designed specifically for API providers to operate their own oracles.
gpt-pilot
GPT Pilot is a core technology for the Pythagora VS Code extension, aiming to provide the first real AI developer companion. It goes beyond autocomplete, helping with writing full features, debugging, issue discussions, and reviews. The tool utilizes LLMs to generate production-ready apps, with developers overseeing the implementation. GPT Pilot works step by step like a developer, debugging issues as they arise. It can work at any scale, filtering out code to show only relevant parts to the AI during tasks. Contributions are welcome, with debugging and telemetry being key areas of focus for improvement.

wdoc
wdoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It aims to handle large volumes of diverse document types, making it ideal for researchers, students, and professionals dealing with extensive information sources. wdoc uses LangChain to process and analyze documents, supporting tens of thousands of documents simultaneously. The system includes features like high recall and specificity, support for various Language Model Models (LLMs), advanced RAG capabilities, advanced document summaries, and support for multiple tasks. It offers markdown-formatted answers and summaries, customizable embeddings, extensive documentation, scriptability, and runtime type checking. wdoc is suitable for power users seeking document querying capabilities and AI-powered document summaries.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
feedgen
FeedGen is an open-source tool that uses Google Cloud's state-of-the-art Large Language Models (LLMs) to improve product titles, generate more comprehensive descriptions, and fill missing attributes in product feeds. It helps merchants and advertisers surface and fix quality issues in their feeds using Generative AI in a simple and configurable way. The tool relies on GCP's Vertex AI API to provide both zero-shot and few-shot inference capabilities on GCP's foundational LLMs. With few-shot prompting, users can customize the model's responses towards their own data, achieving higher quality and more consistent output. FeedGen is an Apps Script based application that runs as an HTML sidebar in Google Sheets, allowing users to optimize their feeds with ease.
WDoc
WDoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It supports querying tens of thousands of documents simultaneously, offers tailored summaries to efficiently manage large amounts of information, and includes features like supporting multiple file types, various LLMs, local and private LLMs, advanced RAG capabilities, advanced summaries, trust verification, markdown formatted answers, sophisticated embeddings, extensive documentation, scriptability, type checking, lazy imports, caching, fast processing, shell autocompletion, notification callbacks, and more. WDoc is ideal for researchers, students, and professionals dealing with extensive information sources.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.

raggenie
RAGGENIE is a low-code RAG builder tool designed to simplify the creation of conversational AI applications. It offers out-of-the-box plugins for connecting to various data sources and building conversational AI on top of them, including integration with pre-built agents for actions. The tool is open-source under the MIT license, with a current focus on making it easy to build RAG applications and future plans for maintenance, monitoring, and transitioning applications from pilots to production.

crawlee-python
Crawlee-python is a web scraping and browser automation library that covers crawling and scraping end-to-end, helping users build reliable scrapers fast. It allows users to crawl the web for links, scrape data, and store it in machine-readable formats without worrying about technical details. With rich configuration options, users can customize almost any aspect of Crawlee to suit their project's needs.
aiCoder
aiCoder is an AI-powered tool designed to streamline the coding process by automating repetitive tasks, providing intelligent code suggestions, and facilitating the integration of new features into existing codebases. It offers a chat interface for natural language interactions, methods and stubs lists for code modification, and settings customization for project-specific prompts. Users can leverage aiCoder to enhance code quality, focus on higher-level design, and save time during development.

HackBot
HackBot is an AI-powered cybersecurity chatbot designed to provide accurate answers to cybersecurity-related queries, conduct code analysis, and scan analysis. It utilizes the Meta-LLama2 AI model through the 'LlamaCpp' library to respond coherently. The chatbot offers features like local AI/Runpod deployment support, cybersecurity chat assistance, interactive interface, clear output presentation, static code analysis, and vulnerability analysis. Users can interact with HackBot through a command-line interface and utilize it for various cybersecurity tasks.
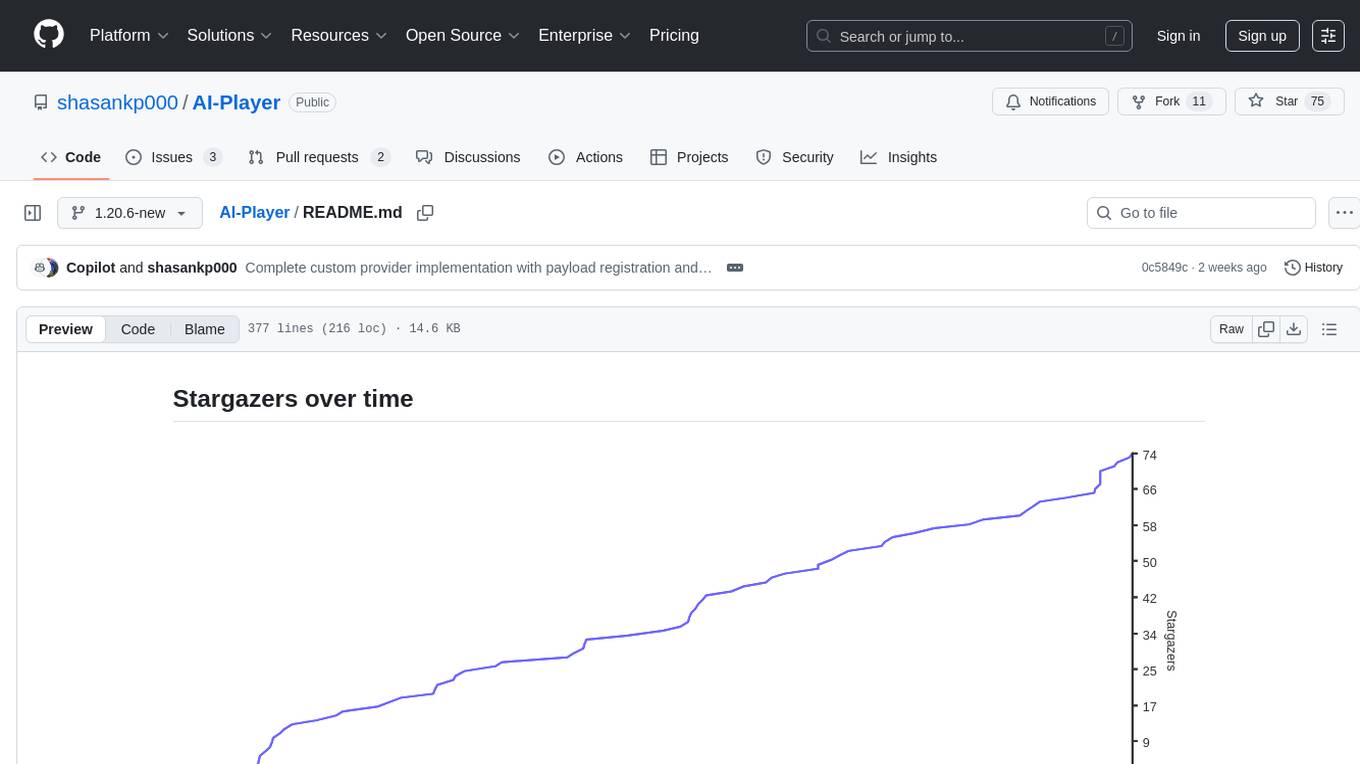
AI-Player
AI-Player is a Minecraft mod that adds an 'intelligent' second player to the game to combat loneliness while playing solo. It aims to enhance gameplay by providing companionship and interactive features. The mod leverages advanced AI algorithms and integrates with external tools to enhance the player experience. Developed with a focus on addressing the social aspect of gaming, AI-Player is a community-driven project that continues to evolve with user feedback and contributions.

TinyTroupe
TinyTroupe is an experimental Python library that leverages Large Language Models (LLMs) to simulate artificial agents called TinyPersons with specific personalities, interests, and goals in simulated environments. The focus is on understanding human behavior through convincing interactions and customizable personas for various applications like advertisement evaluation, software testing, data generation, project management, and brainstorming. The tool aims to enhance human imagination and provide insights for better decision-making in business and productivity scenarios.
For similar tasks
bugbug
Bugbug is a tool developed by Mozilla that leverages machine learning techniques to assist with bug and quality management, as well as other software engineering tasks like test selection and defect prediction. It provides various classifiers to suggest assignees, detect patches likely to be backed-out, classify bugs, assign product/components, distinguish between bugs and feature requests, detect bugs needing documentation, identify invalid issues, verify bugs needing QA, detect regressions, select relevant tests, track bugs, and more. Bugbug can be trained and tested using Python scripts, and it offers the ability to run model training tasks on Taskcluster. The project structure includes modules for data mining, bug/commit feature extraction, model implementations, NLP utilities, label handling, bug history playback, and GitHub issue retrieval.
athina-evals
Athina is an open-source library designed to help engineers improve the reliability and performance of Large Language Models (LLMs) through eval-driven development. It offers plug-and-play preset evals for catching and preventing bad outputs, measuring model performance, running experiments, A/B testing models, detecting regressions, and monitoring production data. Athina provides a solution to the flaws in current LLM developer workflows by offering rapid experimentation, customizable evaluators, integrated dashboard, consistent metrics, historical record tracking, and easy setup. It includes preset evaluators for RAG applications and summarization accuracy, as well as the ability to write custom evals. Athina's evals can run on both development and production environments, providing consistent metrics and removing the need for manual infrastructure setup.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.